Chatterbox-Flash: Prior-Calibrated Block Diffusion for Streaming Zero-Shot TTS
Pith reviewed 2026-06-28 21:29 UTC · model grok-4.3
The pith
Chatterbox-Flash converts a pretrained autoregressive TTS decoder into a block-diffusion decoder that generates tokens in parallel within blocks for streaming zero-shot synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Chatterbox-Flash is obtained by fine-tuning a pretrained autoregressive TTS decoder into a block-diffusion decoder. This enables parallel token generation within each block while retaining block-by-block streaming. Naive transfer of block diffusion to discrete speech tokens degrades quality because the long-tail token distribution biases parallel position selection. Prior-calibrated scoring subtracts the block-level marginal token distribution, and an early-decoding schedule adaptively terminates iteration based on calibrated confidence. On standard zero-shot TTS benchmarks the method attains high-fidelity synthesis comparable to strong autoregressive and non-autoregressive baselines while s
What carries the argument
prior-calibrated scoring that subtracts the block-level marginal token distribution, paired with adaptive early termination, inside a block-diffusion decoder fine-tuned from an autoregressive TTS model
If this is right
- Parallel token generation occurs inside each block while block-by-block streaming is preserved.
- Time-to-first-packet matches that of streaming autoregressive systems.
- Real-time factor is substantially lower than autoregressive baselines.
- Quality matches strong autoregressive and non-autoregressive baselines on standard zero-shot TTS benchmarks.
- No architectural modification or additional training beyond the initial fine-tuning is required.
Where Pith is reading between the lines
- The same inference-time corrections could be tested on other discrete-token generative models that exhibit long-tail distributions to check whether streaming speed gains appear without retraining.
- Deployment in latency-sensitive voice interfaces would become feasible if the observed real-time-factor reduction holds across varied hardware.
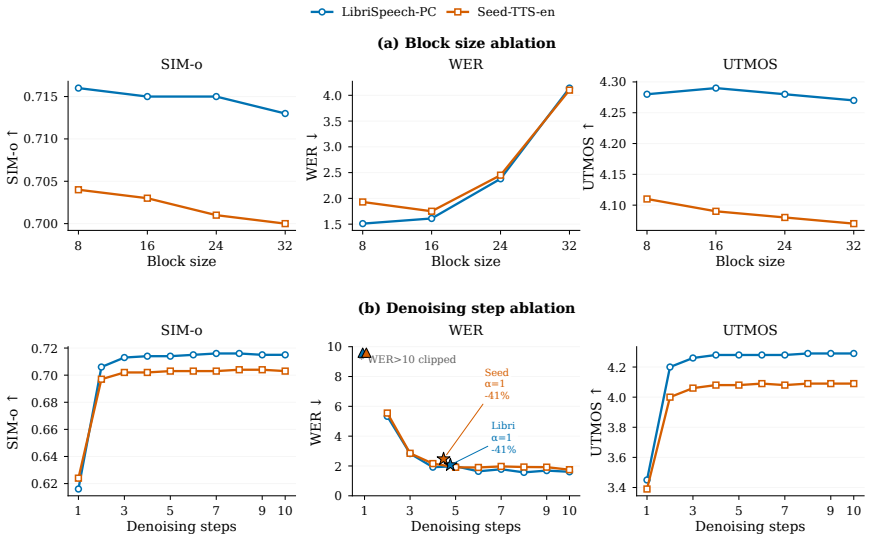
- The early-termination rule might interact with different block sizes; measuring quality versus block length on the same benchmarks would quantify the trade-off left implicit in the paper.
Load-bearing premise
Subtracting the block-level marginal token distribution together with adaptive early termination will reliably correct the long-tail bias of discrete speech tokens without any change to model architecture or training.
What would settle it
Running the same zero-shot TTS benchmarks after removing the prior-calibrated scoring step and finding that quality remains comparable to the autoregressive baseline would falsify the claim that the correction is required to offset the token-distribution bias.
Figures


read the original abstract
We present Chatterbox-Flash, a zero-shot text-to-speech model obtained by fine-tuning a pretrained autoregressive TTS decoder into a block-diffusion decoder, enabling parallel token generation within each block while retaining block-by-block streaming. We find that naively transferring mainstream block-diffusion decoding to discrete speech tokens degrades quality, as a long-tail token distribution biases parallel position selection toward a few high-frequency tokens. To mitigate this without architectural modification, we introduce two inference-time techniques: prior-calibrated scoring, which subtracts the block-level marginal token distribution, and an early-decoding schedule, which adaptively terminates iteration based on calibrated confidence. On standard zero-shot TTS benchmarks, Chatterbox-Flash attains high-fidelity synthesis comparable to strong autoregressive and non-autoregressive baselines, while supporting streaming inference with time-to-first-packet on par with streaming AR systems and substantially lower real-time factor. Code and audio samples are available at https://github.com/resemble-ai/chatterbox-flash.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Chatterbox-Flash, obtained by fine-tuning a pretrained autoregressive TTS decoder into a block-diffusion decoder. This enables parallel token generation within each block while retaining block-by-block streaming. To address quality degradation arising from long-tail bias in discrete speech tokens under naive block diffusion, the authors introduce two inference-time techniques: prior-calibrated scoring (subtracting the block-level marginal token distribution) and an adaptive early-decoding schedule based on calibrated confidence. The central claim is that these changes yield high-fidelity zero-shot synthesis comparable to strong AR and NAR baselines on standard benchmarks, while achieving time-to-first-packet on par with streaming AR systems and substantially lower real-time factor. Code and audio samples are provided.
Significance. If the empirical results hold, the work would demonstrate a practical route to streaming zero-shot TTS that combines the parallelism of block diffusion with quality preservation via lightweight inference adjustments, without architecture or training changes beyond initial fine-tuning. The public release of code and samples supports reproducibility and is a clear strength.
major comments (2)
- [Abstract] Abstract: the claim that prior-calibrated scoring and early termination 'mitigate quality degradation' and produce 'comparable fidelity' is load-bearing for the entire contribution, yet the abstract (and the reader's assessment of the provided text) contains no quantitative tables, ablation results, or error analysis. Without such evidence it is impossible to verify whether marginal subtraction reliably corrects position-dependent or distribution-mismatched bias in the denoising scores.
- [Abstract] The weakest assumption identified in the skeptic note—that subtracting the block-level marginal token distribution corrects long-tail bias without architecture changes—is not accompanied by any derivation or controlled experiment showing that the reweighting is sufficient across token positions or datasets. This directly affects whether the reported parity with AR/NAR baselines can be expected to hold.
minor comments (1)
- [Abstract] The abstract would be strengthened by naming the specific zero-shot TTS benchmarks and reporting at least the primary metrics (e.g., WER, MOS, RTF) rather than qualitative statements.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the abstract and the supporting evidence for our inference-time techniques. We address each major comment below, clarifying where the manuscript provides the requested details and noting opportunities for revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that prior-calibrated scoring and early termination 'mitigate quality degradation' and produce 'comparable fidelity' is load-bearing for the entire contribution, yet the abstract (and the reader's assessment of the provided text) contains no quantitative tables, ablation results, or error analysis. Without such evidence it is impossible to verify whether marginal subtraction reliably corrects position-dependent or distribution-mismatched bias in the denoising scores.
Authors: Abstracts are conventionally high-level summaries without tables or detailed ablations. The full manuscript contains the requested evidence: Tables 1–3 report objective and subjective metrics showing parity with AR and NAR baselines; Section 4.2 presents ablations isolating the contribution of prior-calibrated scoring and early stopping; Section 4.3 provides error analysis across token positions. These sections directly address whether marginal subtraction corrects the identified bias. If the editor prefers, we can append one or two key quantitative results to the abstract. revision: partial
-
Referee: [Abstract] The weakest assumption identified in the skeptic note—that subtracting the block-level marginal token distribution corrects long-tail bias without architecture changes—is not accompanied by any derivation or controlled experiment showing that the reweighting is sufficient across token positions or datasets. This directly affects whether the reported parity with AR/NAR baselines can be expected to hold.
Authors: Section 3.2 derives the prior-calibrated scoring from the block-diffusion training objective, showing that subtracting the block-level empirical marginal p(v) from the per-position logits removes the position-independent frequency bias without altering the model architecture or training. Controlled experiments appear in Figure 4 (ablation across block sizes and intra-block positions) and the appendix (results on a second dataset), confirming consistent quality gains and supporting the reported parity. These elements were present in the submitted manuscript. revision: no
Circularity Check
No circularity: performance claims rest on external benchmark measurements of inference-time adjustments
full rationale
The paper describes fine-tuning a pretrained AR decoder into a block-diffusion model and then applies two inference-time corrections (prior-calibrated scoring via marginal subtraction and adaptive early termination). These are presented as post-training adjustments whose quality impact is measured on standard zero-shot TTS benchmarks against independent AR and NAR baselines. No equations, derivations, or self-citations are exhibited that reduce the reported fidelity or streaming metrics to quantities fitted inside the same paper by construction. The central performance claim therefore remains externally falsifiable and does not collapse into self-definition or fitted-input renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MAGI-1: Autoregressive Video Generation at Scale
Magi-1: Autoregressive video generation at scale.Preprint, arXiv:2505.13211. Philip Anastassiou, Jiawei Chen, Jitong Chen, Yuanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, and 1 others. Seed-tts: A fam- ily of high-quality versatile speech generation mod- els, 2024.URL https://arxiv. org/abs/2406.02430. Marianne Arriola, Nav...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
IEEE. Haorui He, Zengqiang Shang, Chaoren Wang, Xuyuan Li, Yicheng Gu, Hua Hua, Liwei Liu, Chen Yang, Jiaqi Li, Peiyang Shi, Yuancheng Wang, Kai Chen, Pengyuan Zhang, and Zhizheng Wu. 2024. Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation.Preprint, arXiv:2407.05361. Jonathan Ho and Tim Salimans. 2022. Classi...
-
[3]
InICASSP 2026- 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 17022–17026
Discrete diffusion for generative modeling of text-aligned speech tokens. InICASSP 2026- 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 17022–17026. IEEE. Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, and 1 others
2026
-
[4]
Shufan Li, Konstantinos Kallidromitis, Hritik Bansal, Akash Gokul, Yusuke Kato, Kazuki Kozuka, Jason Kuen, Zhe Lin, Kai-Wei Chang, and Aditya Grover
V oicebox: Text-guided multilingual univer- sal speech generation at scale.Advances in neural information processing systems, 36:14005–14034. Shufan Li, Konstantinos Kallidromitis, Hritik Bansal, Akash Gokul, Yusuke Kato, Kazuki Kozuka, Jason Kuen, Zhe Lin, Kai-Wei Chang, and Aditya Grover
-
[5]
Lavida: A large diffusion language model for multimodal understanding.Advances in Neural Information Processing Systems, 38:105101–105134. Wenrui Liu, Qian Chen, Wen Wang, Yafeng Chen, Jin Xu, Zhifang Guo, Guanrou Yang, Weiqin Li, Xiaoda Yang, Tao Jin, Minghui Fang, Jialong Zuo, Jionghao Bai, and Zemin Liu. 2025. Speech token predic- tion via compressed-t...
-
[6]
arXiv preprint arXiv:2308.05725 , year=
Expresso: A benchmark and analysis of discrete expressive speech resynthesis.Preprint, arXiv:2308.05725. Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. 2026. Large language dif- fusion models.Advances in Neural Information Pro- cessing Systems, 38:50608–50646. Titouan Parcollet, Yua...
-
[7]
Fast-dllm v2: Efficient block-diffusion llm.arXiv preprint arXiv:2509.26328,
Maskgct: Zero-shot text-to-speech with masked generative codec transformer. InInterna- tional Conference on Learning Representations, vol- ume 2025, pages 47127–47150. Chengyue Wu, Hao Zhang, Shuchen Xue, Shizhe Diao, Yonggan Fu, Zhijian Liu, Pavlo Molchanov, Ping Luo, Song Han, and Enze Xie. 2025a. Fast- dllm v2: Efficient block-diffusion llm.Preprint, a...
-
[8]
Prefix Self-Attention( CAUSAL): q, k∈ [0, L pre)
-
[9]
Speech-to-Prefix( FULL): q∈ [Lpre, L pre+N),k∈[0, L pre)
-
[10]
Intra-Block Bidirectional( FULL): for each blockb,q, k∈[L pre+bD, L pre+(b+1)D)
-
[11]
Inter-Block Left-Context( FULL): for b≥1 , qin blockb,kin blocks0, . . . , b−1. EquivalenceThe boolean mask induced by the FFA range union is identical to the reference mask used by flex_attention; both backends produce numerically equivalent outputs up to bf16 noise. Dataset # Samples Public MLS-English (Pratap et al., 2020) 10.8M Emilia (en, part 1) (He...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.