Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO
Pith reviewed 2026-06-28 23:52 UTC · model grok-4.3
The pith
Smaller models supply policy-level diversity that improves GRPO training of larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
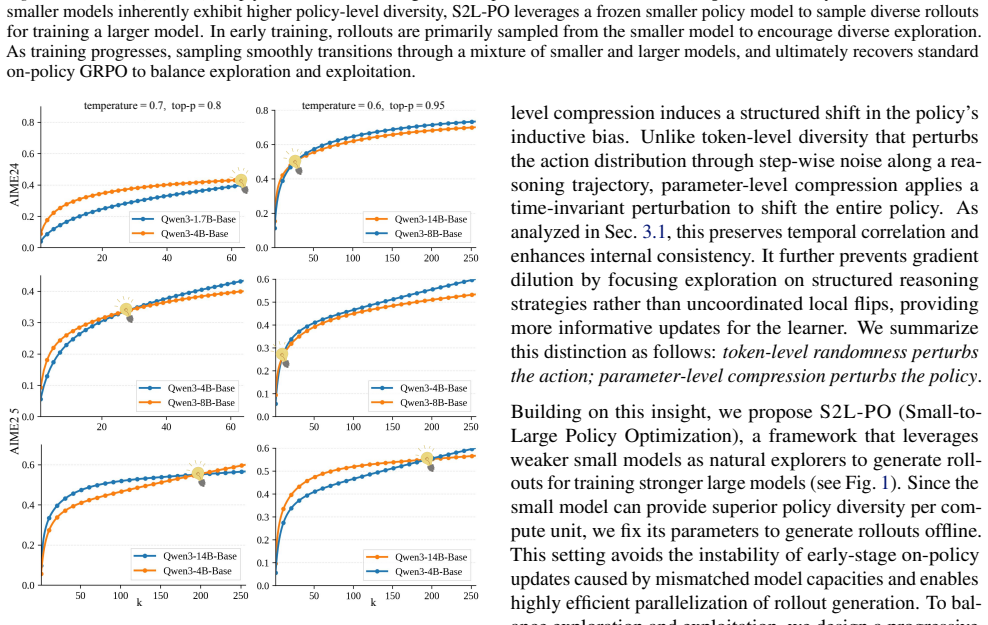
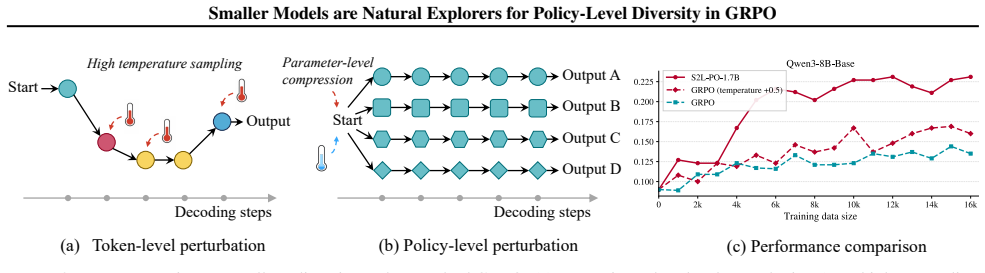
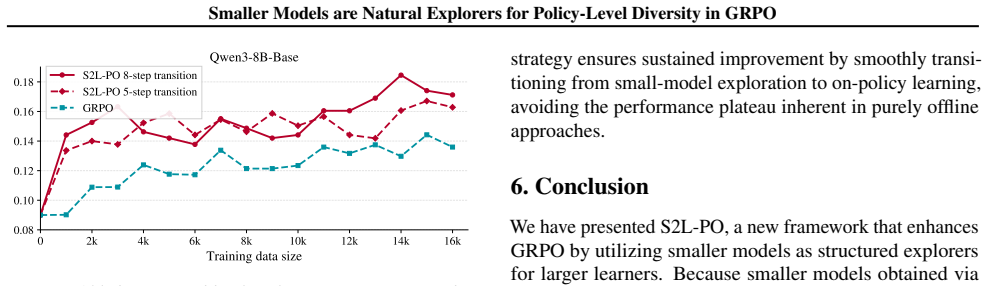
Smaller models within the same family inherently exhibit higher policy-level diversity than larger counterparts, indicated by their superior pass@k relative to larger models as sample counts increase. This diversity is temporally correlated, preserves logical consistency, and supplies structured exploration signals for gradient estimation in GRPO. S2L-PO leverages fixed small models as natural explorers with a progressive annealing strategy that shifts from offline small-model rollouts to the large learner's own sampling, avoiding mid-training drops and achieving faster convergence plus a higher performance ceiling.
What carries the argument
S2L-PO framework with progressive annealing from fixed small-model rollouts to large-model sampling
If this is right
- Accuracy improves on mathematical reasoning benchmarks such as +8.8 percent on AIME 24 when a 1.7B explorer guides an 8B model.
- Rollout compute decreases while training proceeds.
- Training avoids performance drops during the transition to the large model's sampling.
- Convergence speeds up and the final performance ceiling for the large model rises.
Where Pith is reading between the lines
- The finding suggests that policy optimization may benefit from deliberately pairing models of different sizes for exploration and exploitation phases.
- The annealing schedule could be adapted to other reinforcement learning setups that rely on multiple rollouts for gradient estimates.
- If the diversity advantage holds across families, it would imply a new scaling consideration where smaller companions are retained rather than discarded after pretraining.
Load-bearing premise
The observed pass@k advantage of smaller models reflects temporally correlated policy-level diversity that supplies superior gradient signals rather than an artifact of capacity limits or evaluation metrics.
What would settle it
A direct comparison on the same benchmarks where rollouts from the small explorer produce no accuracy gain for the large model beyond what standard token-level diversity already achieves.
Figures




read the original abstract
We identify a new dimension for enhancing rollout diversity in Group Relative Policy Optimization (GRPO) for LLMs. While GRPO relies on diverse rollouts, prevailing strategies primarily increase diversity by injecting more token-level randomness, which may introduce step-wise noise and lead to incoherent trajectories. We uncover that smaller models within the same model family inherently exhibit higher policy-level diversity, indicated by their superior pass@k relative to larger counterparts as sample counts increase. Unlike token-level noise, this diversity is temporally correlated, preserves logical consistency, and provides structured exploration signals for gradient estimation. We thus propose S2L-PO (Small-to-Large Policy Optimization), a framework that leverages fixed small models as natural explorers to train larger models. To balance exploration and exploitation, we design a progressive annealing strategy that transitions from offline small-model rollouts to the large learner's own sampling. This shift elegantly avoids mid-training performance drops caused by the small model's capacity limits, achieving faster convergence and unlocking a higher performance ceiling. S2L-PO improves accuracy on diverse mathematical reasoning benchmarks (e.g., +8.8% on AIME 24 using a 1.7B explorer to guide the 8B model) while reducing rollout compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that smaller models in the same family inherently provide higher policy-level diversity for GRPO training of LLMs, as indicated by superior pass@k at increasing sample counts; this diversity is argued to be temporally correlated and logically consistent (unlike token-level noise). It proposes the S2L-PO framework using fixed small models (e.g., 1.7B) as explorers for larger models (e.g., 8B) with a progressive annealing schedule from offline small-model rollouts to the learner's own sampling, reporting gains such as +8.8% on AIME 24 while reducing rollout compute.
Significance. If the central claim holds and the observed pass@k advantage indeed supplies structured, temporally correlated exploration signals that improve GRPO gradients, the work would offer a practical, compute-efficient alternative to token-level randomness for enhancing rollout diversity in LLM policy optimization, with direct applicability to mathematical reasoning benchmarks.
major comments (3)
- [Abstract] Abstract: The claim that smaller models' pass@k advantage reflects 'temporally correlated, preserves logical consistency' policy-level diversity that supplies superior gradient signals is load-bearing for the S2L-PO motivation, yet the text provides no direct measurements (e.g., trajectory coherence scores, token-level correlation statistics, or gradient variance comparisons) to distinguish this from capacity-driven coverage or higher-variance error patterns.
- [Abstract] Abstract: No ablations are described that would isolate the diversity mechanism, such as replacing small-model samples with matched-diversity large-model samples or comparing against the annealing schedule alone; without these, it is unclear whether the reported +8.8% AIME 24 gain (or reduced rollout compute) stems from the proposed policy-level diversity or from other factors like the training schedule.
- [Abstract] Abstract: The paper states that smaller models exhibit 'superior pass@k relative to larger counterparts as sample counts increase' but provides no details on controls for model-family effects, exact diversity metrics beyond pass@k, statistical significance, or baseline comparisons, which are required to substantiate the 'inherently exhibit higher policy-level diversity' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the empirical support for our claims. We agree that additional measurements, ablations, and controls will improve the manuscript and will incorporate revisions to address each point. Our responses below are organized point-by-point.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that smaller models' pass@k advantage reflects 'temporally correlated, preserves logical consistency' policy-level diversity that supplies superior gradient signals is load-bearing for the S2L-PO motivation, yet the text provides no direct measurements (e.g., trajectory coherence scores, token-level correlation statistics, or gradient variance comparisons) to distinguish this from capacity-driven coverage or higher-variance error patterns.
Authors: We acknowledge that the current version relies primarily on pass@k trends as an indicator. To directly substantiate the temporally correlated and logically consistent properties, the revised manuscript will add trajectory coherence scores, token-level correlation statistics across rollouts, and gradient variance comparisons between small-model and token-noise baselines. These will appear in a new diversity analysis subsection. revision: yes
-
Referee: [Abstract] Abstract: No ablations are described that would isolate the diversity mechanism, such as replacing small-model samples with matched-diversity large-model samples or comparing against the annealing schedule alone; without these, it is unclear whether the reported +8.8% AIME 24 gain (or reduced rollout compute) stems from the proposed policy-level diversity or from other factors like the training schedule.
Authors: We agree that isolating the diversity source is necessary. The revision will include two new ablations: (1) replacing small-model rollouts with large-model samples matched for pass@k diversity, and (2) an annealing-schedule-only baseline without small-model explorers. These will quantify the contribution of policy-level diversity versus schedule effects. revision: yes
-
Referee: [Abstract] Abstract: The paper states that smaller models exhibit 'superior pass@k relative to larger counterparts as sample counts increase' but provides no details on controls for model-family effects, exact diversity metrics beyond pass@k, statistical significance, or baseline comparisons, which are required to substantiate the 'inherently exhibit higher policy-level diversity' claim.
Authors: We will expand the experimental section with explicit controls for model-family effects (e.g., cross-family comparisons), additional diversity metrics (e.g., trajectory edit distance), statistical significance tests (p-values across seeds), and further baselines. These details will be added to support the inherent diversity claim. revision: yes
Circularity Check
No circularity: empirical observation plus proposed schedule
full rationale
The paper's central claim is an empirical observation that smaller models show higher pass@k as k increases, presented as a measured fact rather than a derived quantity. From this they motivate S2L-PO and an annealing schedule. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The derivation chain is observation → method design, which remains self-contained against external benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Smaller models within the same family exhibit higher policy-level diversity than larger ones, visible in pass@k scaling.
invented entities (1)
-
S2L-PO framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
H., Gendler, A., Baruch, E
Anschel, O., Shoshan, A., Botach, A., Hakimi, S. H., Gendler, A., Baruch, E. B., Bhonker, N., Kviatkovsky, I., Aggarwal, M., and Medioni, G. Group-aware rein- forcement learning for output diversity in large language models. InProceedings of the 2025 Conference on Em- pirical Methods in Natural Language Processing, pp. 32382–32403,
2025
-
[2]
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
Balunovi´c, M., Dekoninck, J., Petrov, I., Jovanovi ´c, N., and Vechev, M. Matharena: Evaluating llms on uncontaminated math competitions.arXiv preprint arXiv:2505.23281,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
XRPO: Pushing the limits of GRPO with Targeted Exploration and Exploitation
9 Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO Bamba, U., Fang, M., Yu, Y ., Zheng, H., and Lai, F. Xrpo: Pushing the limits of grpo with targeted exploration and exploitation.arXiv preprint arXiv:2510.06672,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Bansal, H., Hosseini, A., Agarwal, R., Tran, V . Q., and Kazemi, M. Smaller, weaker, yet better: Training llm reasoners via compute-optimal sampling.arXiv preprint arXiv:2408.16737,
-
[5]
Cai, Z., Cao, M., Chen, H., Chen, K., Chen, K., Chen, X., Chen, X., et al. Internlm2 technical report.arXiv preprint arXiv:2403.17297,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Chen, X., Zhu, W., Qiu, P., Dong, X., Wang, H., Wu, H., Li, H., Sotiras, A., Wang, Y ., and Razi, A. Dra-grpo: Exploring diversity-aware reward adjustment for r1-zero- like training of large language models.arXiv preprint arXiv:2505.09655,
-
[7]
Dragoi, M., Pintilie, I., Gogianu, F., and Brad, F
URLhttps://arxiv.org/abs/2602.06107. Dragoi, M., Pintilie, I., Gogianu, F., and Brad, F. Beyond pass@ k: Breadth-depth metrics for reasoning boundaries. arXiv preprint arXiv:2510.08325,
-
[8]
Soft Adaptive Policy Optimization
Gao, C., Zheng, C., Chen, X.-H., Dang, K., Liu, S., Yu, B., Yang, A., Bai, S., Zhou, J., and Lin, J. Soft adaptive policy optimization.arXiv preprint arXiv:2511.20347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Minillm: Knowl- edge distillation of large language models
Gu, Y ., Dong, L., Wei, F., and Huang, M. Minillm: Knowl- edge distillation of large language models. InInterna- tional Conference on Learning Representations, volume 2024, pp. 32694–32717,
2024
-
[10]
Gu, Z., Chen, X., Shi, X., Wang, T., Zheng, S., Li, T., Feng, H., and Xiao, Y . Gapo: Learning preferential prompt through generative adversarial policy optimization.arXiv preprint arXiv:2503.20194,
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective
Hao, Z., Wang, H., Liu, H., Luo, J., Yu, J., Dong, H., Lin, Q., Wang, C., and Chen, J. Rethinking entropy interventions in rlvr: An entropy change perspective.arXiv preprint arXiv:2510.10150,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
He, C., Luo, R., Bai, Y ., Hu, S., Thai, Z. L., Shen, J., Hu, J., Han, X., Huang, Y ., Zhang, Y ., et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad- level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
ORPO: Monolithic Preference Optimization without Reference Model
Hong, J., Lee, N., and Thorne, J. Orpo: Monolithic pref- erence optimization without reference model.arXiv preprint arXiv:2403.07691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Huang, W., Ge, Y ., Yang, S., Xiao, Y ., Mao, H., Lin, Y ., Ye, H., Liu, S., Cheung, K. C., Yin, H., et al. Qerl: Beyond efficiency–quantization-enhanced reinforcement learning for llms.arXiv preprint arXiv:2510.11696,
-
[18]
Revisiting Entropy in Reinforcement Learning for Large Reasoning Models
Jin, R., Gao, P., Ren, Y ., Han, Z., Zhang, T., Huang, W., Liu, W., Luan, J., and Xiong, D. Revisiting entropy in reinforcement learning for large reasoning models.arXiv preprint arXiv:2511.05993,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
A survey of reinforcement learning from human feedback
Kaufmann, T., Weng, P., Bengs, V ., and H¨ullermeier, E. A survey of reinforcement learning from human feedback. arXiv preprint arXiv:2312.14925,
- [20]
-
[21]
Lin, Z., Liang, T., Xu, J., Lin, Q., Wang, X., Luo, R., Shi, C., Li, S., Yang, Y ., and Tu, Z. Critical tokens matter: Token-level contrastive estimation enhances llm’s reason- ing capability.arXiv preprint arXiv:2411.19943,
-
[22]
Mroueh, Y ., Dupuis, N., Belgodere, B., Nitsure, A., Rigotti, M., Greenewald, K., Navratil, J., Ross, J., and Rios, J. Revisiting group relative policy optimization: Insights into on-policy and off-policy training.arXiv preprint arXiv:2505.22257,
-
[23]
arXiv preprint arXiv:2407.01082 , year =
Nguyen, M. N., Baker, A., Neo, C., Roush, A., Kirsch, A., and Shwartz-Ziv, R. Turning up the heat: Min-p sampling for creative and coherent llm outputs.arXiv preprint arXiv:2407.01082,
-
[24]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., and Wu, C. Hybridflow: A flexi- ble and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Unchosen experts can contribute too: Unleashing moe models’ power by self-contrast
Shi, C., Yang, C., Zhu, X., Wang, J., Wu, T., Li, S., Cai, D., Yang, Y ., and Meng, Y . Unchosen experts can contribute too: Unleashing moe models’ power by self-contrast. Advances in Neural Information Processing Systems, 37: 136897–136921, 2024a. Shi, C., Yang, H., Cai, D., Zhang, Z., Wang, Y ., Yang, Y ., and Lam, W. A thorough examination of decoding ...
2024
-
[28]
SCOPE-RL: Stable and Quantitative Control of Policy Entropy in RL Post-Training
Wang, C., Li, Z., Bai, J., Zhang, Y ., Cui, S., Zhao, Z., and Wang, Y . Arbitrary entropy policy optimization breaks the exploration bottleneck of reinforcement learning.arXiv preprint arXiv:2510.08141, 2025a. Wang, H., Hao, S., Dong, H., Zhang, S., Bao, Y ., Yang, Z., and Wu, Y . Offline reinforcement learning for llm multi-step reasoning. InFindings of ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yue, Y ., Chen, Z., Lu, R., Zhao, A., Wang, Z., Song, S., and Huang, G. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Zhang, H., Zheng, R., Yi, Z., Peng, H., Wang, H., and Yu, Y . Group expectation policy optimization for stable heterogeneous reinforcement learning in llms.arXiv e- prints, pp. arXiv–2508, 2025a. Zhang, J. and Zuo, C. Grpo-lead: A difficulty-aware re- inforcement learning approach for concise mathemat- ical reasoning in language models.arXiv preprint arXi...
-
[31]
Zhang, X., Wen, S., Wu, W., and Huang, L. Edge-grpo: Entropy-driven grpo with guided error correction for advantage diversity.arXiv preprint arXiv:2507.21848, 2025b. Zhang, X., Wu, S., Zhu, Y ., Tan, H., Yu, S., He, Z., and Jia, J. Scaf-grpo: Scaffolded group relative policy op- timization for enhancing llm reasoning.arXiv preprint arXiv:2510.19807, 2025c...
-
[32]
Group Sequence Policy Optimization
Zheng, C., Liu, S., Li, M., Chen, X.-H., Yu, B., Gao, C., Dang, K., Liu, Y ., Men, R., Yang, A., et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
work page internal anchor Pith review Pith/arXiv arXiv
- [33]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.