Hide-and-Seek in Trajectories: Discovering Failure Signals for VLA Runtime Monitoring
Pith reviewed 2026-06-28 22:37 UTC · model grok-4.3
The pith
Hide-and-Seek detects failures in Vision-Language-Action robot policies by inducing localized signals from whole-trajectory labels alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
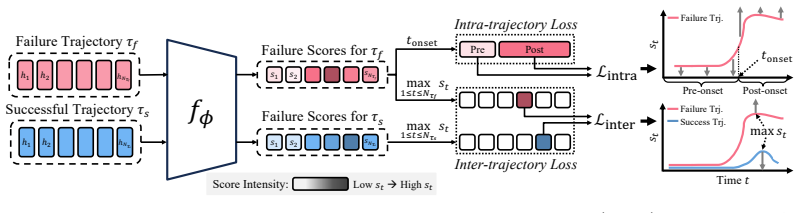
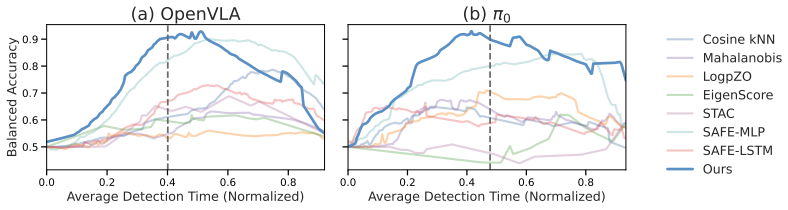
Hide-and-Seek formulates VLA failure detection as a coarsely supervised learning problem. By combining inter-trajectory and intra-trajectory contrastive objectives, it localizes failure-indicative actions and induces temporally structured failure signals from trajectory-level supervision alone, without any step-level annotation. On LIBERO, VLABench, and a real-world platform with OpenVLA, π0, and π0.5 policies, the method reaches state-of-the-art multi-task failure detection with a practical accuracy-timeliness trade-off under conformal prediction and generalizes to both seen and unseen tasks.
What carries the argument
Hide-and-Seek, a framework that applies inter-trajectory and intra-trajectory contrastive objectives to localize failure signals in VLA trajectories from coarse supervision.
If this is right
- Failure detection becomes possible without action resampling or external models at runtime.
- Temporally structured signals arise directly from trajectory-level labels via the contrastive objectives.
- Conformal prediction yields controllable accuracy-timeliness trade-offs across multiple VLA policies.
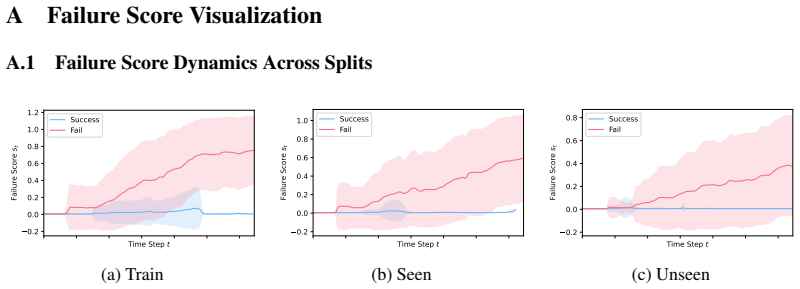
- Detection performance holds for both seen tasks and tasks not encountered during training.
Where Pith is reading between the lines
- The same coarse-supervision pattern could apply to other embodied monitoring tasks that currently require dense labels.
- Runtime monitors built this way might allow a single model to handle safety checks for expanding task sets without retraining.
- Integration with existing VLA policies could be tested by measuring how early the localized signals allow corrective interventions.
Load-bearing premise
Inter-trajectory and intra-trajectory contrastive objectives can reliably produce time-localized failure signals when trained only on whole-trajectory success or failure labels.
What would settle it
A test set of trajectories containing both successful and failing segments where the method's localized predictions perform no better than uniform label propagation on failure detection metrics.
Figures

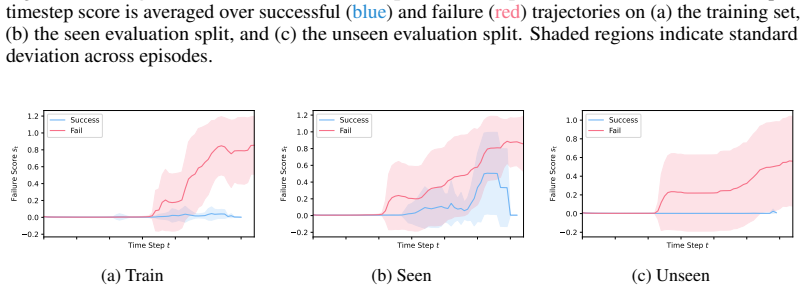
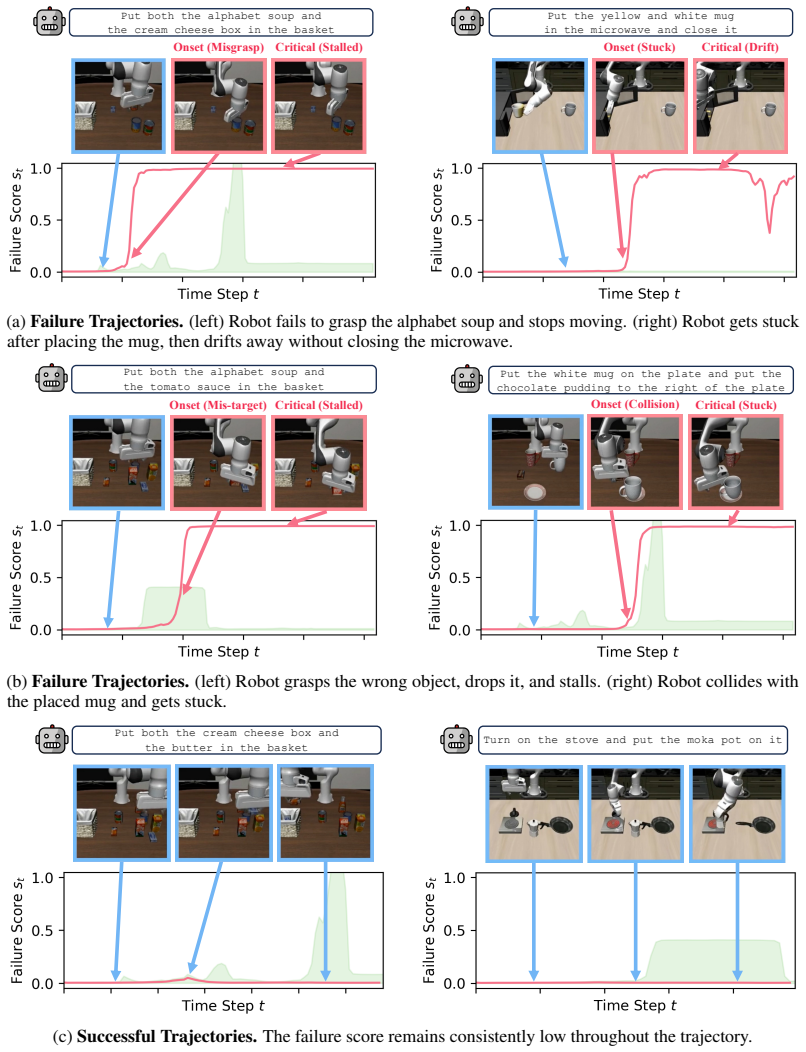


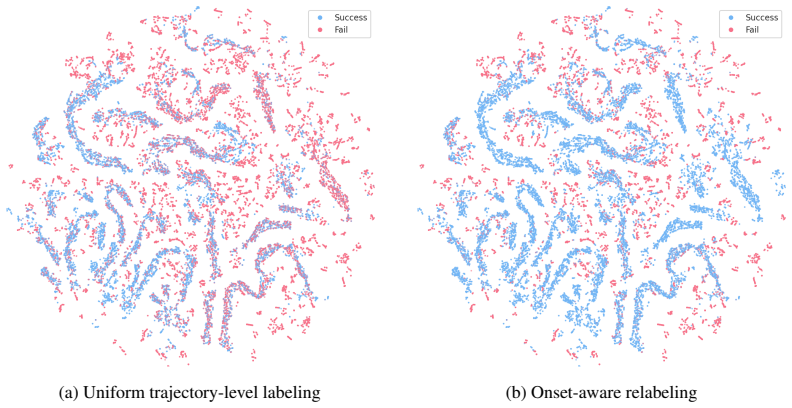
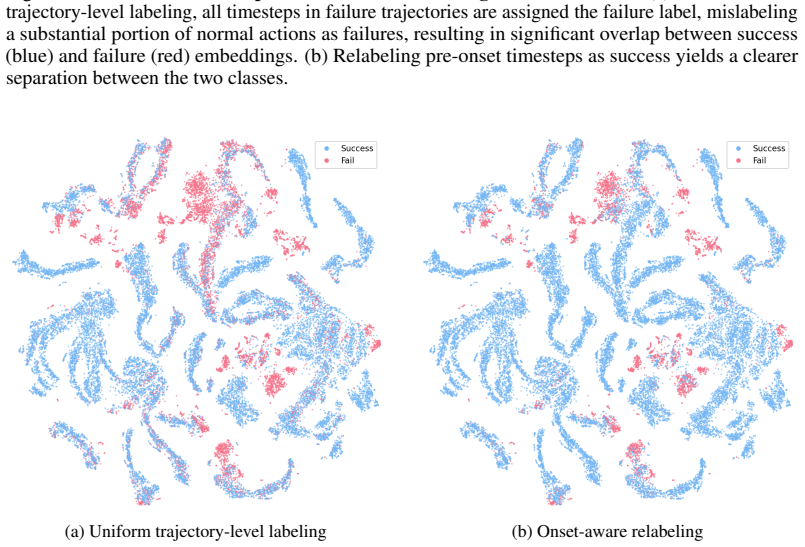
read the original abstract
Vision-Language-Action (VLA) models enable robots to follow natural language instructions and generalize across diverse tasks, but they remain vulnerable to execution failures that compromise reliability in real-world deployment. Detecting such failures during execution is therefore critical for the robust deployment of embodied systems. Existing failure detection methods either rely on expensive action resampling or external models, while alternatives propagate trajectory-level labels uniformly across every timestep, obscuring localized failure signals. In this paper, we propose \textbf{Hide-and-Seek}, a framework that formulates VLA failure detection as a coarsely supervised learning problem. By combining inter-trajectory and intra-trajectory contrastive objectives, Hide-and-Seek localizes failure-indicative actions and induces temporally structured failure signals from trajectory-level supervision alone, without any step-level annotation. We evaluate Hide-and-Seek on LIBERO, VLABench, and a real-world robotic platform across three representative VLA policies: OpenVLA, $\pi_0$, and $\pi_{0.5}$.Our method achieves state-of-the-art multi-task failure detection performance with a practical accuracy--timeliness trade-off under conformal prediction, and generalizes well to both seen and unseen tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hide-and-Seek, a framework that treats VLA failure detection as a coarsely supervised problem. It combines inter-trajectory and intra-trajectory contrastive objectives to localize failure-indicative actions and produce temporally structured signals using only trajectory-level success/failure labels, without step-level annotations or external models. The method is evaluated on LIBERO, VLABench, and a real robotic platform using OpenVLA, π₀, and π₀.₅ policies, claiming state-of-the-art multi-task failure detection performance with a practical accuracy-timeliness trade-off under conformal prediction and good generalization to seen and unseen tasks.
Significance. If the central claim holds, the work would advance runtime monitoring for embodied VLAs by reducing reliance on expensive resampling or external models while using only coarse labels. The multi-policy evaluation (OpenVLA, π₀, π₀.₅), inclusion of real-robot experiments, and use of conformal prediction for calibrated detection are strengths that increase practical relevance. The result would be significant for reliable deployment if the contrastive objectives demonstrably extract temporally localized causal signals rather than spurious correlations.
major comments (3)
- [Abstract and Method (contrastive objectives)] The central claim that inter-trajectory and intra-trajectory contrastive objectives induce temporally structured failure signals from trajectory-level labels alone (Abstract) rests on an unverified assumption: that the learned representations localize failure actions rather than exploit action-distribution shifts between success and failure trajectories. No step-level ground truth is available during training, so it is unclear whether the induced signals are causal or merely correlational; this directly affects whether the reported SOTA detection performance under conformal prediction reflects genuine failure localization.
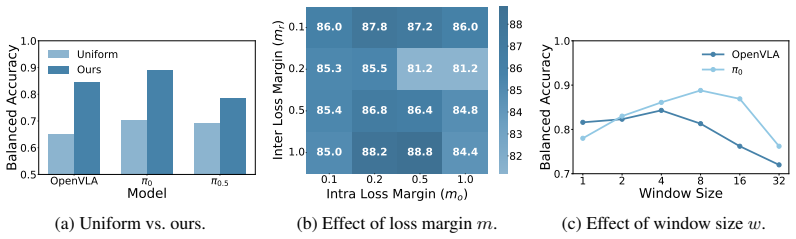
- [Abstract and Experiments] Evaluation claims of SOTA multi-task performance and generalization to unseen tasks (Abstract) are presented without quantitative numbers, ablation studies on the two contrastive terms, or error analysis of false-positive timing. This makes it impossible to verify the accuracy-timeliness trade-off or to rule out that performance gains arise from dataset biases rather than the proposed localization mechanism.
- [Conformal prediction integration] The conformal-prediction wrapper is presented as providing calibrated, practical detection, yet the manuscript does not report how the nonconformity scores are constructed from the contrastive embeddings or whether the temporal structure of the signals is preserved after calibration. This is load-bearing for the claimed timeliness property.
minor comments (2)
- [Abstract] The abstract contains a missing space after the period in 'π₀.₅.Our method'.
- [Method] Notation for the two contrastive losses should be introduced with explicit equations and variable definitions in the method section to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of our claims regarding the contrastive objectives, evaluation details, and conformal prediction integration. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and Method (contrastive objectives)] The central claim that inter-trajectory and intra-trajectory contrastive objectives induce temporally structured failure signals from trajectory-level labels alone (Abstract) rests on an unverified assumption: that the learned representations localize failure actions rather than exploit action-distribution shifts between success and failure trajectories. No step-level ground truth is available during training, so it is unclear whether the induced signals are causal or merely correlational; this directly affects whether the reported SOTA detection performance under conformal prediction reflects genuine failure localization.
Authors: We recognize this as a valid point. Without step-level supervision, proving strict causality is inherently limited. The intra-trajectory contrastive objective is specifically intended to promote temporal localization by contrasting segments within trajectories, while the inter-trajectory term separates success and failure distributions. In revision, we will add a limitations subsection discussing the correlational nature and potential for distribution shifts, along with more extensive qualitative results showing signal alignment with failure events. revision: partial
-
Referee: [Abstract and Experiments] Evaluation claims of SOTA multi-task performance and generalization to unseen tasks (Abstract) are presented without quantitative numbers, ablation studies on the two contrastive terms, or error analysis of false-positive timing. This makes it impossible to verify the accuracy-timeliness trade-off or to rule out that performance gains arise from dataset biases rather than the proposed localization mechanism.
Authors: The full paper contains quantitative results in tables for multi-task performance on LIBERO, VLABench, and real robot, including comparisons to baselines. However, to better support the abstract claims, we will incorporate key quantitative figures into the abstract where appropriate. We will also add explicit ablation studies isolating the contribution of each contrastive term and include an error analysis section focusing on false positive timing and its impact on the trade-off. revision: yes
-
Referee: [Conformal prediction integration] The conformal-prediction wrapper is presented as providing calibrated, practical detection, yet the manuscript does not report how the nonconformity scores are constructed from the contrastive embeddings or whether the temporal structure of the signals is preserved after calibration. This is load-bearing for the claimed timeliness property.
Authors: We will expand the conformal prediction section to explicitly describe the nonconformity score construction, which uses the per-timestep failure signal derived from the contrastive embeddings as the score. Additionally, we will include analysis showing that the temporal ordering and structure of the signals remain intact post-calibration, supported by before-and-after timeliness metrics. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description introduce Hide-and-Seek as a new framework using inter-trajectory and intra-trajectory contrastive objectives to induce temporally structured signals from coarse trajectory labels alone. No equations, parameter-fitting steps, self-citations, or uniqueness theorems are quoted that would reduce any claimed prediction or localization result to an input by construction. The central claim is presented as an independent methodological contribution evaluated on external benchmarks (LIBERO, VLABench, real-robot data), satisfying the default expectation that the derivation chain remains self-contained without circular reduction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Neglected Free Lunch from Post-training: Progress Advantage for LLM Agents
The log-probability ratio from RL post-training recovers the optimal advantage function, providing an effective free signal for test-time scaling, uncertainty estimation, and failure attribution in LLM agents.
Reference graph
Works this paper leans on
-
[1]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model. InCoRL, 2025
2025
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al. π0.6: a vla that learns from experience. arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
VLANeXt: Recipes for Building Strong VLA Models
Xiao-Ming Wu, Bin Fan, Kang Liao, Jian-Jian Jiang, Runze Yang, Yihang Luo, Zhonghua Wu, Wei- Shi Zheng, and Chen Change Loy. Vlanext: Recipes for building strong vla models.arXiv preprint arXiv:2602.18532, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
VLM4VLA: Revisiting vision-language-models in vision-language-action models
Jianke Zhang, Xiaoyu Chen, Yanjiang Guo, Yucheng Hu, and Jianyu Chen. VLM4VLA: Revisiting vision-language-models in vision-language-action models. InICLR, 2026
2026
-
[7]
Marcel Torne, Karl Pertsch, Homer Walke, Kyle Vedder, Suraj Nair, Brian Ichter, Allen Z Ren, Haohuan Wang, Jiaming Tang, Kyle Stachowicz, et al. Mem: Multi-scale embodied memory for vision language action models.arXiv preprint arXiv:2603.03596, 2026
-
[8]
Memer: Scaling up memory for robot control via experience retrieval
Ajay Sridhar, Jennifer Pan, Satvik Sharma, and Chelsea Finn. Memer: Scaling up memory for robot control via experience retrieval. InICLR, 2026
2026
-
[9]
Chao Xu, Suyu Zhang, Yang Liu, Baigui Sun, Weihong Chen, Bo Xu, Qi Liu, Juncheng Wang, Shujun Wang, Shan Luo, et al. An anatomy of vision-language-action models: From modules to milestones and challenges.arXiv preprint arXiv:2512.11362, 2025
-
[10]
Robotic fault detection and fault tolerance: A survey.Reliability Engineering & System Safety, 1994
Monica L Visinsky, Joseph R Cavallaro, and Ian D Walker. Robotic fault detection and fault tolerance: A survey.Reliability Engineering & System Safety, 1994
1994
-
[11]
Run-time monitoring of machine learning for robotic perception: A survey of emerging trends.IEEE Access, 2021
Quazi Marufur Rahman, Peter Corke, and Feras Dayoub. Run-time monitoring of machine learning for robotic perception: A survey of emerging trends.IEEE Access, 2021
2021
-
[12]
Can we detect failures without failure data? uncertainty-aware runtime failure detection for imitation learning policies
Chen Xu, Tony Khuong Nguyen, Emma Dixon, Christopher Rodriguez, Patrick Miller, Robert Lee, Paarth Shah, Rares Ambrus, Haruki Nishimura, and Masha Itkina. Can we detect failures without failure data? uncertainty-aware runtime failure detection for imitation learning policies. InRSS, 2025
2025
-
[13]
EVE: A Generator-Verifier System for Generative Policies
Yusuf Ali, Gryphon Patlin, Karthik Kothuri, Muhammad Zubair Irshad, Wuwei Liang, and Zsolt Kira. Eve: A generator-verifier system for generative policies.arXiv preprint arXiv:2512.21430, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Ram Ramrakhya, Matthew Chang, Xavier Puig, Ruta Desai, Zsolt Kira, and Roozbeh Mottaghi. Grounding multimodal llms to embodied agents that ask for help with reinforcement learning.arXiv preprint arXiv:2504.00907, 2025
-
[15]
Safe: Multitask failure detection for vision-language-action models
Qiao Gu, Yuanliang Ju, Shengxiang Sun, Igor Gilitschenski, Haruki Nishimura, Masha Itkina, and Florian Shkurti. Safe: Multitask failure detection for vision-language-action models. InNeurIPS, 2025. 10
2025
-
[16]
Failure prediction at runtime for generative robot policies
Ralf Römer, Adrian Kobras, Luca Worbis, and Angela P Schoellig. Failure prediction at runtime for generative robot policies. InNeurIPS, 2025
2025
-
[17]
Unpacking failure modes of generative policies: Runtime monitoring of consistency and progress
Christopher Agia, Rohan Sinha, Jingyun Yang, Zi-ang Cao, Rika Antonova, Marco Pavone, and Jeannette Bohg. Unpacking failure modes of generative policies: Runtime monitoring of consistency and progress. InCoRL, 2024
2024
-
[18]
Verifier-free test-time sampling for vision language action models
Suhyeok Jang, Dongyoung Kim, Changyeon Kim, Youngsuk Kim, and Jinwoo Shin. Verifier-free test-time sampling for vision language action models. InICLR, 2026
2026
-
[19]
When to Act, Ask, or Learn: Uncertainty-Aware Policy Steering
Jessie Yuan, Yilin Wu, and Andrea Bajcsy. When to act, ask, or learn: Uncertainty-aware policy steering. arXiv preprint arXiv:2602.22474, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Aha: A vision-language-model for detecting and reasoning over failures in robotic manipulation
Jiafei Duan, Wilbert Pumacay, Nishanth Kumar, Yi Ru Wang, Shulin Tian, Wentao Yuan, Ranjay Krishna, Dieter Fox, Ajay Mandlekar, and Yijie Guo. Aha: A vision-language-model for detecting and reasoning over failures in robotic manipulation. InICLR, 2025
2025
-
[21]
Self-refining vision language model for robotic failure detection and reasoning
Carl Qi, Xiaojie Wang, Silong Yong, Stephen Sheng, Huitan Mao, Sriram Srinivasan, Manikantan Nambi, Amy Zhang, and Yesh Dattatreya. Self-refining vision language model for robotic failure detection and reasoning. InICLR, 2026
2026
-
[22]
Failure prediction with statistical guarantees for vision-based robot control
Alec Farid, David Snyder, Allen Z Ren, and Anirudha Majumdar. Failure prediction with statistical guarantees for vision-based robot control. InRSS, 2022
2022
-
[23]
Model-based runtime monitoring with interactive imitation learning
Huihan Liu, Shivin Dass, Roberto Martín-Martín, and Yuke Zhu. Model-based runtime monitoring with interactive imitation learning. InICRA, 2024
2024
-
[24]
Uncertainty-aware latent safety filters for avoiding out-of-distribution failures
Junwon Seo, Kensuke Nakamura, and Andrea Bajcsy. Uncertainty-aware latent safety filters for avoiding out-of-distribution failures. InCoRL, 2025
2025
-
[25]
Libero: Benchmarking knowledge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning. InNeurIPS, 2023
2023
-
[26]
Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, et al. Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks. InICCV, 2025
2025
-
[27]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
TraceVLA: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. TraceVLA: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InICLR, 2025
2025
-
[29]
Spatialvla: Exploring spatial representations for visual-language-action model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model. In RSS, 2025
2025
-
[30]
RynnVLA-002: A Unified Vision-Language-Action and World Model
Jun Cen, Siteng Huang, Yuqian Yuan, Kehan Li, Hangjie Yuan, Chaohui Yu, Yuming Jiang, Jiayan Guo, Xin Li, Hao Luo, et al. Rynnvla-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
FASTer: Toward powerful and efficient autoregressive vision–language–action models with learnable action tokenizer and block-wise decoding
Yicheng Liu, Shiduo Zhang, Zibin Dong, Baijun Ye, Tianyuan Yuan, Xiaopeng Yu, Linqi Yin, Chenhao Lu, Junhao Shi, Luca Jiang-Tao Yu, Liangtao Zheng, Jingjing Gong, Tao Jiang, Xipeng Qiu, and Hang Zhao. FASTer: Toward powerful and efficient autoregressive vision–language–action models with learnable action tokenizer and block-wise decoding. InICLR, 2026
2026
-
[33]
Unified vision-language-action model
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, and Zhaoxiang Zhang. Unified vision-language-action model. InICLR, 2026
2026
-
[34]
Language models are unsupervised multitask learners.OpenAI blog, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 2019
2019
-
[35]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023. 11
2023
-
[36]
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
Jose Barreiros, Andrew Beaulieu, Aditya Bhat, Rick Cory, Eric Cousineau, Hongkai Dai, Ching-Hsin Fang, Kunimatsu Hashimoto, Muhammad Zubair Irshad, Masha Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.arXiv preprint arXiv:2507.05331, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Monitoring of perception systems: Deterministic, probabilistic, and learning-based fault detection and identification.Artificial Intelligence, 2023
Pasquale Antonante, Heath G Nilsen, and Luca Carlone. Monitoring of perception systems: Deterministic, probabilistic, and learning-based fault detection and identification.Artificial Intelligence, 2023
2023
-
[39]
Multi-task interactive robot fleet learning with visual world models
Huihan Liu, Yu Zhang, Vaarij Betala, Evan Zhang, James Liu, Crystal Ding, and Yuke Zhu. Multi-task interactive robot fleet learning with visual world models. InCoRL, 2024
2024
-
[40]
Rc-nf: Robot- conditioned normalizing flow for real-time anomaly detection in robotic manipulation
Shijie Zhou, Bin Zhu, Jiarui Yang, Xiangyu Zhao, Jingjing Chen, and Yu-Gang Jiang. Rc-nf: Robot- conditioned normalizing flow for real-time anomaly detection in robotic manipulation. InCVPR, 2026
2026
-
[41]
Real-time anomaly detection and reactive planning with large language models
Rohan Sinha, Amine Elhafsi, Christopher Agia, Matthew Foutter, Edward Schmerling, and Marco Pavone. Real-time anomaly detection and reactive planning with large language models. InRSS, 2024
2024
-
[42]
Rediffuser: Reliable decision-making using a diffuser with confidence estimation
Nantian He, Shaohui Li, Zhi Li, Yu LIU, and You He. Rediffuser: Reliable decision-making using a diffuser with confidence estimation. InICML, 2024
2024
-
[43]
Weakly supervised anomaly detection: A survey.arXiv preprint arXiv:2302.04549, 2023
Minqi Jiang, Chaochuan Hou, Ao Zheng, Xiyang Hu, Songqiao Han, Hailiang Huang, Xiangnan He, Philip S Yu, and Yue Zhao. Weakly supervised anomaly detection: A survey.arXiv preprint arXiv:2302.04549, 2023
-
[44]
Weakly supervised object localization and detection: A survey.IEEE transactions on pattern analysis and machine intelligence, 2021
Dingwen Zhang, Junwei Han, Gong Cheng, and Ming-Hsuan Yang. Weakly supervised object localization and detection: A survey.IEEE transactions on pattern analysis and machine intelligence, 2021
2021
-
[45]
Multiple instance detection network with online instance classifier refinement
Peng Tang, Xinggang Wang, Xiang Bai, and Wenyu Liu. Multiple instance detection network with online instance classifier refinement. InCVPR, 2017
2017
-
[46]
C-mil: Continuation multiple instance learning for weakly supervised object detection
Fang Wan, Chang Liu, Wei Ke, Xiangyang Ji, Jianbin Jiao, and Qixiang Ye. C-mil: Continuation multiple instance learning for weakly supervised object detection. InCVPR, 2019
2019
-
[47]
Weakly-supervised temporal action localization by uncertainty modeling
Pilhyeon Lee, Jinglu Wang, Yan Lu, and Hyeran Byun. Weakly-supervised temporal action localization by uncertainty modeling. InAAAI, 2021
2021
-
[48]
Ddg-net: Discriminability-driven graph network for weakly-supervised temporal action localization
Xiaojun Tang, Junsong Fan, Chuanchen Luo, Zhaoxiang Zhang, Man Zhang, and Zongyuan Yang. Ddg-net: Discriminability-driven graph network for weakly-supervised temporal action localization. InICCV, 2023
2023
-
[49]
Real-world anomaly detection in surveillance videos
Waqas Sultani, Chen Chen, and Mubarak Shah. Real-world anomaly detection in surveillance videos. In CVPR, 2018
2018
-
[50]
Deep weakly-supervised anomaly detection
Guansong Pang, Chunhua Shen, Huidong Jin, and Anton Van Den Hengel. Deep weakly-supervised anomaly detection. InKDD, 2023
2023
-
[51]
Normality guided multiple instance learning for weakly supervised video anomaly detection
Seongheon Park, Hanjae Kim, Minsu Kim, Dahye Kim, and Kwanghoon Sohn. Normality guided multiple instance learning for weakly supervised video anomaly detection. InWACV, 2023
2023
-
[52]
Multiple instance learning: A survey of problem characteristics and applications.Pattern recognition, 2018
Marc-André Carbonneau, Veronika Cheplygina, Eric Granger, and Ghyslain Gagnon. Multiple instance learning: A survey of problem characteristics and applications.Pattern recognition, 2018
2018
-
[53]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InAISTATS, 2011
2011
-
[54]
Jacopo Diquigiovanni, Matteo Fontana, and Simone Vantini. The importance of being a band: Finite-sample exact distribution-free prediction sets for functional data.arXiv preprint arXiv:2102.06746, 2021
-
[55]
Learning fine-grained bimanual manipula- tion with low-cost hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipula- tion with low-cost hardware. InRSS, 2023
2023
-
[56]
A simple unified framework for detecting out-of-distribution samples and adversarial attacks
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. InNeurIPS, 2018
2018
-
[57]
Out-of-distribution detection with deep nearest neighbors
Yiyou Sun, Yifei Ming, Xiaojin Zhu, and Yixuan Li. Out-of-distribution detection with deep nearest neighbors. InICML, 2022. 12
2022
-
[58]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InICLR, 2023
2023
-
[59]
Inside: Llms’ internal states retain the power of hallucination detection
Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. Inside: Llms’ internal states retain the power of hallucination detection. InICLR, 2024
2024
-
[60]
Uncertainty estimation in autoregressive structured prediction
Andrey Malinin and Mark Gales. Uncertainty estimation in autoregressive structured prediction. InICLR, 2021
2021
-
[61]
Out-of-distribution detection and selective generation for conditional language models
Jie Ren, Jiaming Luo, Yao Zhao, Kundan Krishna, Mohammad Saleh, Balaji Lakshminarayanan, and Peter J Liu. Out-of-distribution detection and selective generation for conditional language models. In ICLR, 2023
2023
-
[62]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Long short-term memory.Supervised sequence labelling with recurrent neural networks, 2012
Alex Graves. Long short-term memory.Supervised sequence labelling with recurrent neural networks, 2012
2012
-
[64]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling.arXiv preprint arXiv:1412.3555, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[65]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, 2017
2017
-
[66]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. InNeurIPS, 2019
2019
-
[68]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019
2019
-
[69]
Conformal prediction: A gentle introduction.Foundations and Trends in Machine Learning, 2023
Anastasios N Angelopoulos and Stephen Bates. Conformal prediction: A gentle introduction.Foundations and Trends in Machine Learning, 2023
2023
-
[70]
Layer by layer: Uncovering hidden representations in language models
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models. InICML, 2025
2025
-
[71]
Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens
Zhangqi Jiang, Junkai Chen, Beier Zhu, Tingjin Luo, Yankun Shen, and Xu Yang. Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens. InCVPR, 2025
2025
-
[72]
Visualizing data using t-sne.Journal of machine learning research, 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 2008
2008
-
[73]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. InICLR, 2022
2022
-
[74]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. In NeurIPS, 2023
2023
-
[75]
Survey of hallucination in natural language generation.ACM computing surveys, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM computing surveys, 2023
2023
-
[76]
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. A survey on hallucination in large vision-language models.arXiv preprint arXiv:2402.00253, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
Analyzing and mitigating object hallucination in large vision-language models
Yiyang Zhou, Chenhang Cui, Jaehong Yoon, Linjun Zhang, Zhun Deng, Chelsea Finn, Mohit Bansal, and Huaxiu Yao. Analyzing and mitigating object hallucination in large vision-language models. InICLR, 2024
2024
-
[78]
Halluentity: Benchmarking and understanding entity-level hallucination detection
Min-Hsuan Yeh, Max Kamachee, Seongheon Park, and Yixuan Li. Halluentity: Benchmarking and understanding entity-level hallucination detection. InTMLR, 2025. 13
2025
-
[79]
Vauq: Vision-aware uncertainty quantification for lvlm self-evaluation
Seongheon Park, Changdae Oh, Hyeong Kyu Choi, Xuefeng Du, and Sharon Li. Vauq: Vision-aware uncertainty quantification for lvlm self-evaluation. InACL Findings, 2026
2026
-
[80]
Teaching models to express their uncertainty in words
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words. In TMLR, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.