BilliardPhys-Bench: Benchmarking Physical Reasoning and Visual Dynamics of Multimodal LLMs
Pith reviewed 2026-06-28 22:16 UTC · model grok-4.3
The pith
BilliardPhys-Bench reveals that multimodal LLMs default to predicting no interaction when physical outcomes grow harder to infer from images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
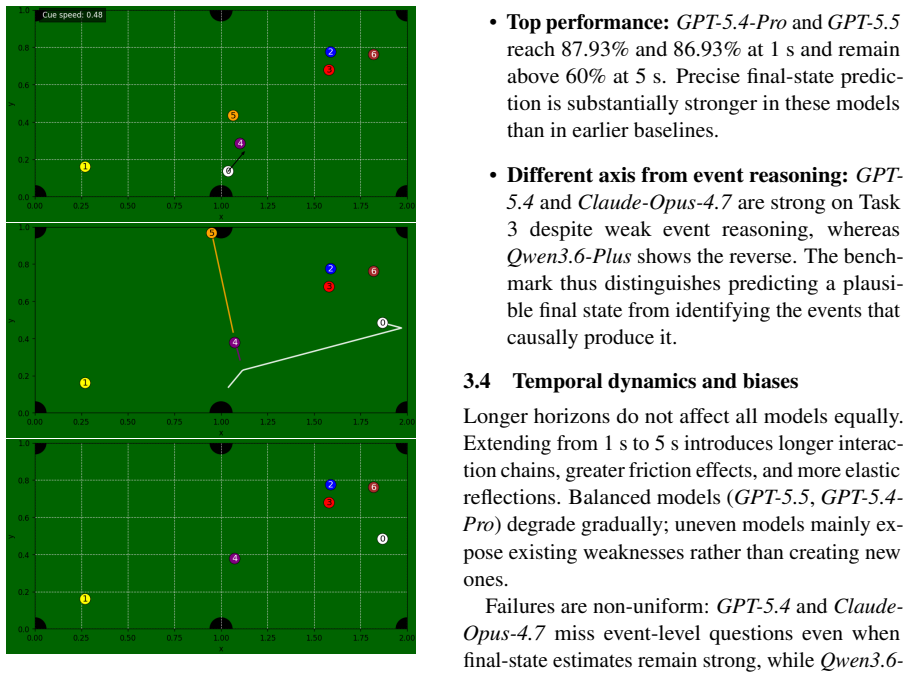
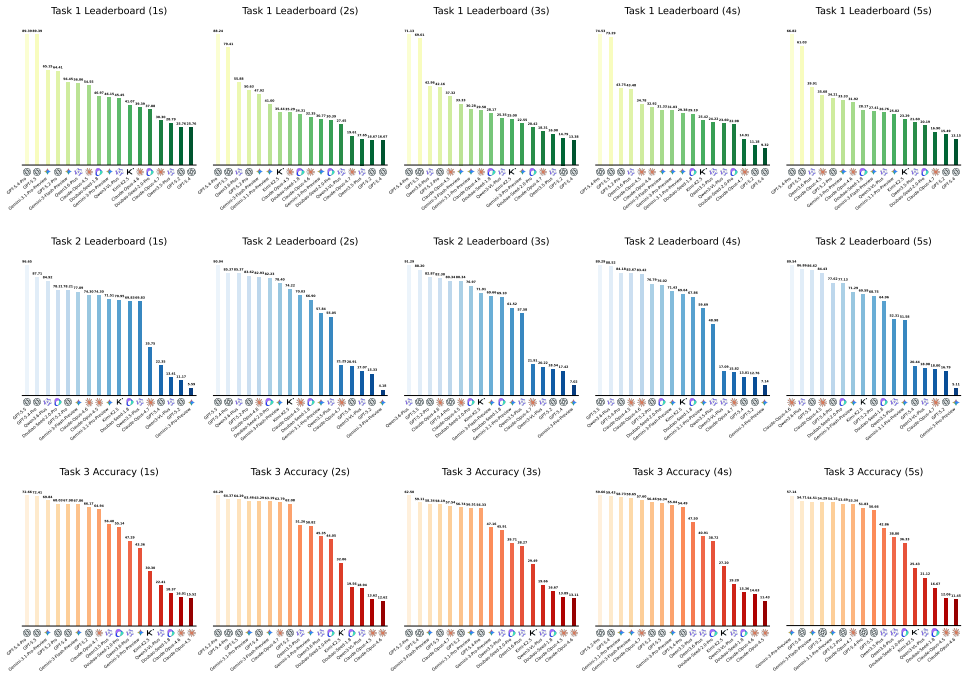
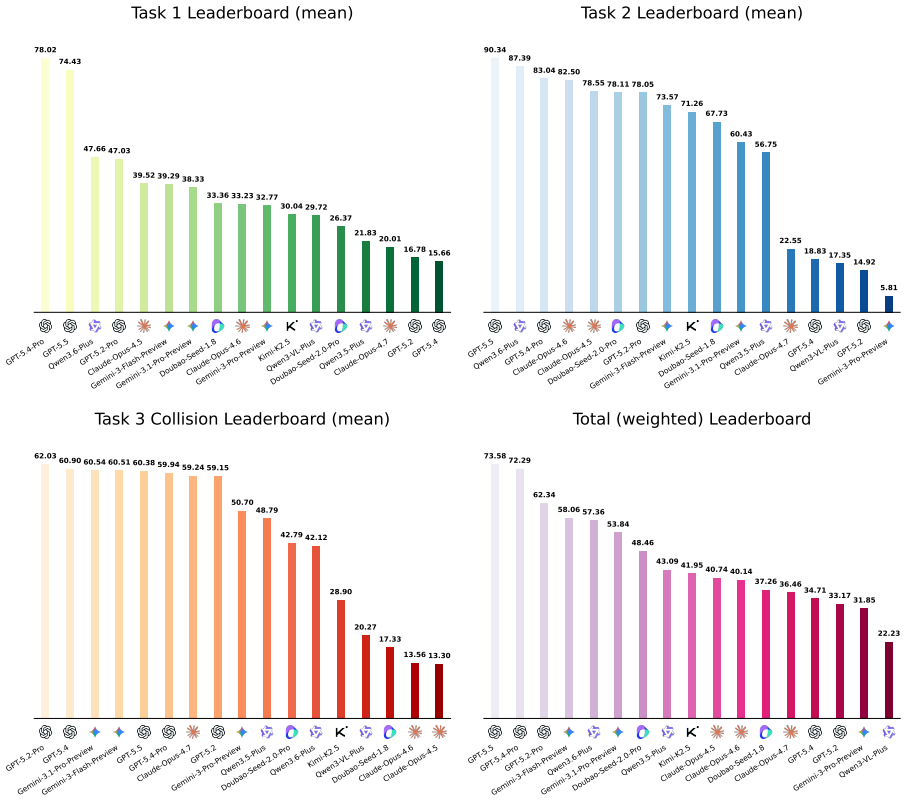
BilliardPhys-Bench demonstrates that multimodal LLMs exhibit a consistent stasis bias on physical reasoning tasks: when the correct outcome of friction and elastic collisions is harder to deduce from a single image, the models reliably predict that no interaction occurs. Performance on collision prediction, wall bounce reasoning, and final position estimation falls as simulation duration increases and scene complexity rises, across GPT, Claude, Gemini, and Qwen families.
What carries the argument
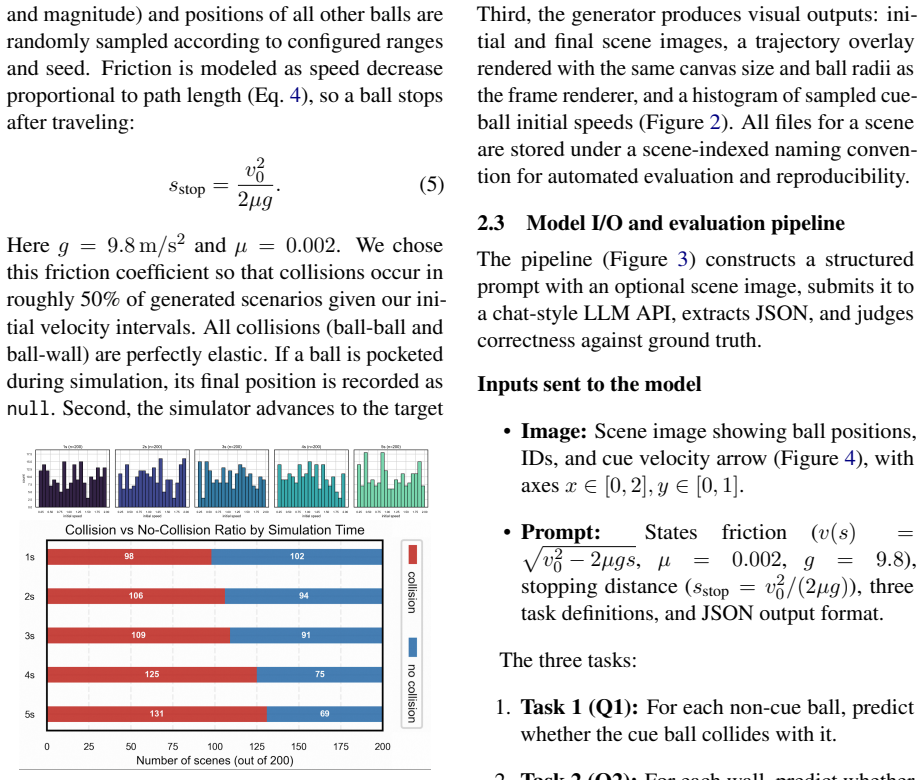
BilliardPhys-Bench procedural engine, which generates randomized billiard scenarios incorporating friction and elastic collisions to probe three abilities: ball-to-ball collision prediction, wall bounce reasoning, and final resting position estimation.
If this is right
- Accuracy on all three tested abilities decreases as simulation time increases.
- More complex scene geometry produces lower performance across evaluated models.
- Stasis bias emerges reliably when the correct physical outcome is harder to infer.
- Current multimodal architectures require stronger physical inductive biases to handle visual dynamics.
Where Pith is reading between the lines
- The benchmark could be adapted to test whether the same stasis bias appears in other domains such as object stacking or fluid motion.
- Training regimes that explicitly reward accurate prediction of elastic collisions might reduce the observed default to no-interaction outputs.
- If stasis bias scales with model size, architectural changes rather than scale alone would be needed to address it.
Load-bearing premise
The randomized synthetic billiard scenes generated by the procedural engine with friction and collisions provide a valid test of the intuitive physical reasoning that multimodal models would need for real visual dynamics.
What would settle it
Running the same models on video sequences of actual billiard play and checking whether the stasis bias disappears or persists at comparable rates.
Figures


read the original abstract
Current multimodal models handle static image recognition well, but intuitive physical reasoning remains a weakness. Predicting how objects will move and interact from a single image is still difficult for these systems. We present BilliardPhys-Bench, a benchmark for physical reasoning in synthetic billiards environments. Its procedural engine generates randomized scenarios with friction and elastic collisions. The benchmark tests three abilities: (1) predicting ball-to-ball collisions, (2) reasoning about wall bounces, and (3) estimating final ball positions after motion stops. We evaluate recent MLLMs from the GPT, Claude, Gemini, and Qwen families. Performance drops as simulation time increases and scene geometry grows more complex. We also observe a consistent failure mode we call "stasis bias": when the correct physical outcome is harder to infer, models tend to predict no interaction. These findings show where current MLLMs break down on visual dynamics and point toward the need for better physical inductive biases in multimodal architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BilliardPhys-Bench, a benchmark for physical reasoning in multimodal LLMs using a procedural engine that generates randomized synthetic billiards scenes with friction and elastic collisions. It evaluates models from GPT, Claude, Gemini, and Qwen families on three tasks—predicting ball-to-ball collisions, wall bounces, and final positions after motion stops—reporting performance degradation with longer simulation times and greater scene complexity, plus a consistent 'stasis bias' failure mode in which models default to predicting no interaction when the outcome is harder to infer.
Significance. If the benchmark scenarios are shown to require genuine forward simulation of dynamics rather than static heuristics or language priors, the work would usefully document current MLLM limitations on intuitive physics and motivate architectural improvements. The 'stasis bias' observation, if reproducible, could serve as a concrete diagnostic for future models. At present the lack of any quantitative results, error bars, dataset statistics, or engine validation details prevents assessment of whether these findings hold.
major comments (2)
- [Abstract] Abstract: the central claim that MLLMs exhibit 'stasis bias' and break down on visual dynamics rests on the assumption that the randomized billiards scenarios constitute valid probes of physical reasoning. The manuscript supplies no details on ground-truth computation (exact integration method, friction model parameters, collision resolution), human validation of difficulty, or controls that rule out solutions via static visual heuristics or default 'no change' answers.
- [Abstract] Abstract: the paper states that performance drops as simulation time increases and scene geometry grows more complex, yet reports no quantitative results, error bars, dataset statistics, or evaluation protocols, so the support for these observations cannot be verified from the given text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where the manuscript requires additional technical detail and quantitative support. We will revise the paper to incorporate the requested information on the simulation engine, validation procedures, and experimental results while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that MLLMs exhibit 'stasis bias' and break down on visual dynamics rests on the assumption that the randomized billiards scenarios constitute valid probes of physical reasoning. The manuscript supplies no details on ground-truth computation (exact integration method, friction model parameters, collision resolution), human validation of difficulty, or controls that rule out solutions via static visual heuristics or default 'no change' answers.
Authors: We agree that the manuscript must supply these details to substantiate the benchmark's validity. In the revision we will add a new section describing the procedural engine, including the numerical integration method (e.g., Euler or Verlet), friction coefficients, elastic collision resolution, and parameter ranges. We will also report human validation results on a subset of scenes to confirm perceived difficulty and include control experiments (e.g., static-image baselines and 'no-interaction' default probes) demonstrating that the tasks cannot be solved reliably by visual heuristics or language priors alone. revision: yes
-
Referee: [Abstract] Abstract: the paper states that performance drops as simulation time increases and scene geometry grows more complex, yet reports no quantitative results, error bars, dataset statistics, or evaluation protocols, so the support for these observations cannot be verified from the given text.
Authors: We acknowledge that the current manuscript text lacks the quantitative results, error bars, dataset statistics, and full evaluation protocols referenced in the abstract. The revision will include tables reporting accuracy and error rates across time horizons and complexity levels (with standard deviations from multiple seeds), dataset size and generation statistics, and a complete description of the evaluation protocol (prompt templates, scoring, and model versions). revision: yes
Circularity Check
Empirical benchmark evaluation with no derivations or self-referential predictions
full rationale
The paper presents BilliardPhys-Bench as a procedural benchmark for testing MLLM physical reasoning via generated billiards scenes with friction and collisions. It reports empirical performance metrics, complexity trends, and the observed 'stasis bias' failure mode. No equations, fitted parameters, uniqueness theorems, or ansatzes appear; the central claims rest on direct evaluation of external models against the generated test cases rather than any internal derivation chain. This is a standard self-contained benchmark study with no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic billiards scenarios with friction and elastic collisions serve as a valid proxy for testing intuitive physical reasoning in multimodal LLMs.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Cosmos World Foundation Model Platform for Physical AI.arXiv e-prints, arXiv:2501.03575. Li Puyin, Tiange Xiang, Ella Mao, Shirley Wei, Xinye Chen, Adnan Masood, Li Fei-fei, and Ehsan Adeli. 2025. QuantiPhy: A Quantitative Benchmark Evaluating Physical Reasoning Abili- ties of Vision-Language Models.arXiv e-prints, arXiv:2512.19526. Hui Shen, Taiqiang Wu,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
MiniCPM-V: A GPT-4V Level MLLM on Your Phone.arXiv e-prints, arXiv:2408.01800. Christine Ye, Sihan Yuan, Suchetha Cooray, Steven Dillmann, Ian L. V . Roque, Dalya Baron, Philipp Frank, Sergio Martin-Alvarez, Nolan Koblischke, Frank J Qu, Diyi Yang, Risa Wechsler, and Ioana Ciuca. 2025. ReplicationBench: Can AI Agents Replicate Astrophysics Research Papers...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.