Vector Linking via Cross-Model Local Isometric Consistency
Pith reviewed 2026-06-28 22:34 UTC · model grok-4.3
The pith
Independently trained contrastive encoders preserve short-range distances up to a scale factor, enabling recovery of cross-model object correspondences from a tiny seed set of paired anchors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
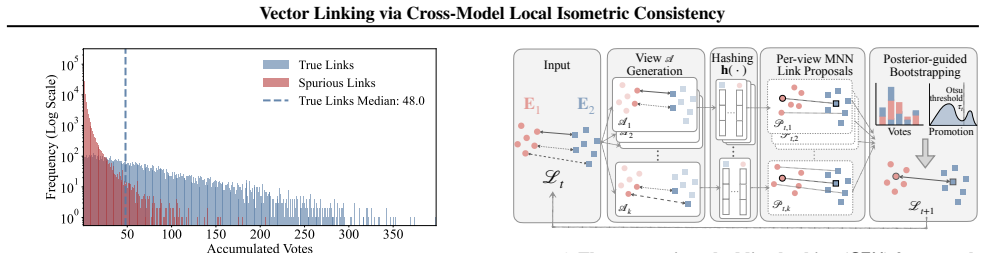
Independently trained contrastive encoders exhibit local geometric consistency: short-range distances are approximately preserved up to a scale factor, while long-range distances are not due to model-specific distortion. This enables an iterative, reference-based geometric embedding hashing procedure that recovers cross-model object correspondences from a tiny seed set of paired anchors by representing each vector through distances to sampled anchors, proposing candidates via hash-space matching, and aggregating evidence in a Beta-Bernoulli posterior to bootstrap additional high-confidence links.
What carries the argument
Iterative reference-based geometric embedding hashing that represents vectors by distances to sampled paired anchors, matches via hash-space collisions, and aggregates via Beta-Bernoulli posterior to promote new anchors.
If this is right
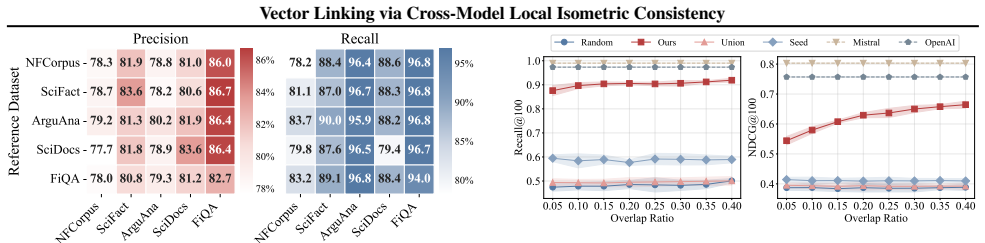
- Accurate and robust cross-model linking holds across benchmarks with varying dataset overlap and seed budgets.
- The procedure remains effective even when anchors come from out-of-domain sources.
- Vector database integration becomes feasible without access to original training data or model internals.
- Cross-model clustering can proceed directly from the recovered correspondences.
Where Pith is reading between the lines
- The local consistency property might be checked first on new encoder pairs to decide whether the linking procedure is likely to succeed before investing in seed collection.
- Chaining the procedure across more than two models could allow transitive alignment of multiple embedding spaces.
- The bootstrapping step could be made more stable by incorporating additional geometric invariants beyond distance-to-anchor profiles.
Load-bearing premise
A usable seed set of paired anchors exists and the partial overlap between embedding clouds is sufficient for the Beta-Bernoulli aggregation to bootstrap additional links without excessive error propagation.
What would settle it
Measuring recovered link accuracy that drops to levels indistinguishable from random guessing when the seed set is reduced below a small threshold or when direct checks show absence of local distance preservation in the tested model pair.
Figures






read the original abstract
We study Vector Linking: given two embedding clouds produced by different black-box encoders over partially overlapping datasets, recover cross-model object correspondences using only vectors. Empirically and theoretically, we show that independently trained contrastive encoders exhibit local geometric consistency: short-range distances are approximately preserved up to a scale factor, while long-range distances are not due to model-specific distortion. Building on this, we propose an iterative, reference-based geometric embedding hashing that recovers vector links from a tiny seed set of paired anchors. It represents each vector by distances to sampled paired anchors, proposes candidate links via hash-space matching, and aggregates evidence across views in a Beta-Bernoulli posterior to bootstrap high-confidence links as new anchors. Experiments across multiple benchmarks and embedding model pairs demonstrate accurate and robust linking under varying overlap, seed budgets, and out-of-domain anchors, with applications to vector database integration and cross-model clustering. Code is available at https://github.com/DBgroup-Edinburgh/VecLinking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that independently trained contrastive encoders exhibit local geometric consistency (short-range distances preserved up to a scale factor, long-range distances distorted in a model-specific way). Building on this, it introduces an iterative reference-based geometric embedding hashing procedure that starts from a tiny seed set of paired anchors, represents vectors by distances to anchors, proposes links via hash matching, and aggregates evidence with a Beta-Bernoulli posterior to bootstrap additional high-confidence links. Experiments across benchmarks, model pairs, overlap levels, and seed budgets are reported, with public code provided.
Significance. If the local-consistency observation holds, the method offers a practical route to cross-model vector linking and database integration without joint training or full dataset overlap. The availability of public code together with multi-benchmark experiments supplies reproducible empirical support and allows direct falsification of the robustness claims under varying seed budgets and out-of-domain anchors.
minor comments (3)
- [Abstract / Introduction] The abstract states both empirical and theoretical support for local consistency; the theoretical argument should be expanded with an explicit statement of the assumptions under which short-range isometry holds (e.g., properties of the contrastive loss or embedding dimension).
- [Method / Experiments] The Beta-Bernoulli prior parameters are listed among the free parameters; a sensitivity plot or table showing linking accuracy as a function of these hyperparameters would strengthen the robustness claims.
- [Figures] Figure captions and axis labels should explicitly state the overlap fraction and seed size used in each panel so that the reported accuracy numbers can be interpreted without cross-referencing the text.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The description of the method and claims is accurate.
Circularity Check
No significant circularity detected
full rationale
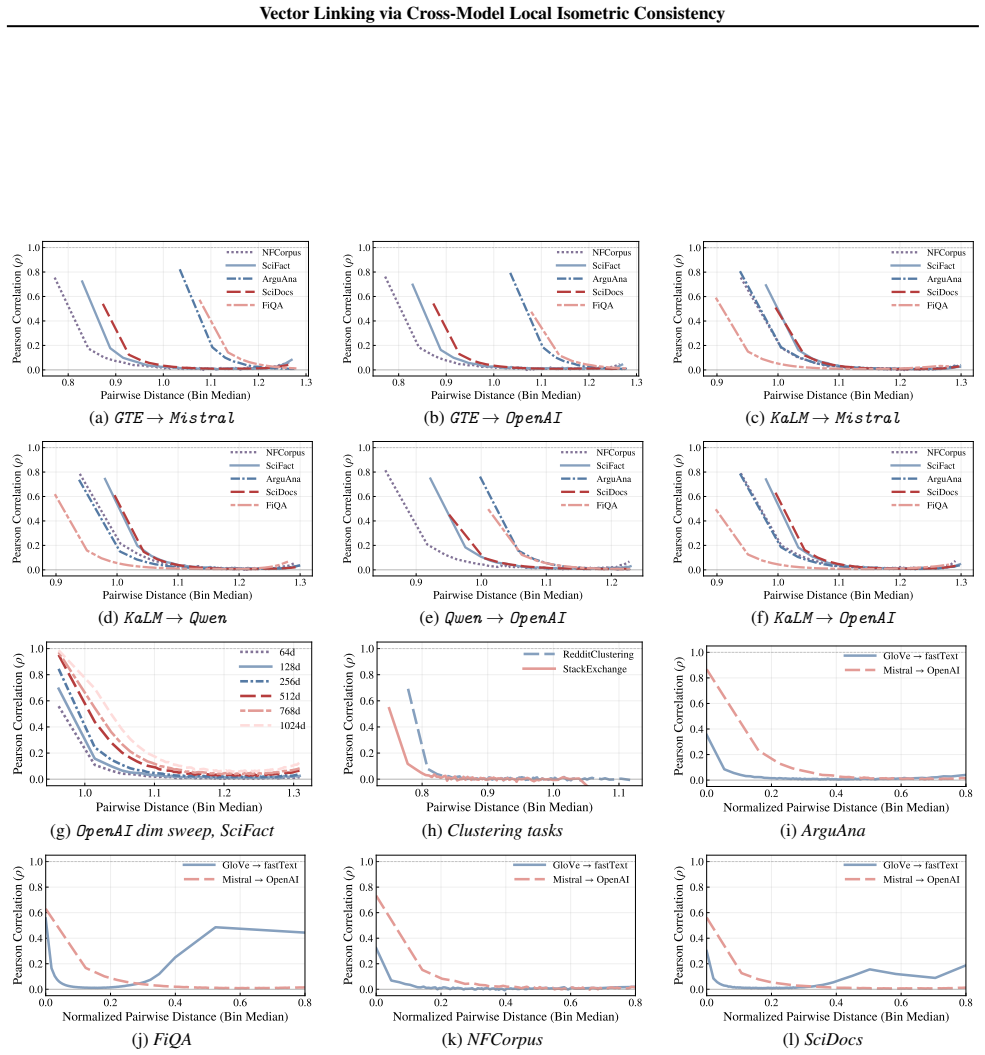
The paper's core claim rests on an empirical observation of local geometric consistency (short-range distances preserved up to scale) across independently trained contrastive encoders, demonstrated via multi-benchmark experiments rather than any derivation that reduces to fitted parameters or self-referential definitions. The iterative geometric embedding hashing and Beta-Bernoulli aggregation constitute a statistical bootstrapping procedure from an external seed set; this does not equate the output to its inputs by construction, nor does it rely on load-bearing self-citations, uniqueness theorems imported from the authors, or ansatzes smuggled via prior work. The seed/overlap requirement is treated explicitly as an empirical parameter. No quoted equations or steps in the provided material exhibit the enumerated circular patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of sampled paired anchors
- Beta-Bernoulli prior parameters
axioms (1)
- domain assumption Short-range distances in independently trained contrastive embeddings are approximately preserved up to a global scale factor.
Reference graph
Works this paper leans on
-
[1]
URL http://dx.doi.org/ 10.18653/v1/P18-1073
doi: 10.18653/v1/p18-1073. URL http://dx.doi.org/ 10.18653/v1/P18-1073. Besl, P. and McKay, N. D. A method for registration of 3-d shapes.IEEE Transactions on Pattern Analysis and Machine Intelligence, 14(2):239–256,
-
[2]
Enriching Word Vectors with Subword Information
doi: 10.1109/34.121791. Bojanowski, P., Grave, E., Joulin, A., and Mikolov, T. En- riching word vectors with subword information.arXiv preprint arXiv:1607.04606,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/34.121791
-
[3]
A full-text learning to rank dataset for medical information retrieval
Boteva, V ., Gholipour, D., Sokolov, A., and Riezler, S. A full-text learning to rank dataset for medical information retrieval. InAdvances in Information Retrieval: 38th European Conference on IR Research, ECIR 2016, Padua, Italy, March 20–23,
2016
-
[4]
Cohan, A., Feldman, S., Beltagy, I., Downey, D., and Weld, D
URL https: //arxiv.org/abs/2303.00721. Cohan, A., Feldman, S., Beltagy, I., Downey, D., and Weld, D. S. Specter: Document-level representation learning using citation-informed transformers.arXiv preprint arXiv:2004.07180,
-
[5]
Enevoldsen, K., Chung, I., Kerboua, I., Kardos, M., Mathur, A., Stap, D., Gala, J., Siblini, W., Krzemi´nski, D., Winata, G. I., Sturua, S., Utpala, S., Ciancone, M., Schaeffer, M., Sequeira, G., Misra, D., Dhakal, S., Rystrøm, J., Solo- matin, R., ¨Omer C ¸a˘gatan, Kundu, A., Bernstorff, M., Xiao, S., Sukhlecha, A., Pahwa, B., Po ´swiata, R., GV , K. K.,...
-
[6]
doi: 10.48550/arXiv.2502.13595. URL https://arxiv. org/abs/2502.13595. Fischler, M. A. and Bolles, R. C. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Commun. ACM, 24(6):381–395, June
-
[7]
1145/358669.358692. URL https://doi.org/10. 1145/358669.358692. Ganin, Y ., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., Marchand, M., and Lempitsky, V . Domain-adversarial training of neural networks,
-
[8]
Domain-Adversarial Training of Neural Networks
URLhttps://arxiv.org/abs/1505.07818. Geigle, G., Reimers, N., R¨uckl´e, A., and Gurevych, I. Tweac: Transformer with extendable qa agent classifiers,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
URLhttps://arxiv.org/abs/2104.07081. Gonzalez, T. F. Clustering to minimize the maximum intercluster distance.Theoretical Computer Sci- ence, 38:293–306,
-
[10]
doi: https://doi.org/10.1016/0304-3975(85)90224-5
ISSN 0304-3975. doi: https://doi.org/10.1016/0304-3975(85)90224-5. URL https://www.sciencedirect.com/ science/article/pii/0304397585902245. Grave, E., Joulin, A., and Berthet, Q. Unsupervised align- ment of embeddings with wasserstein procrustes. In Chaudhuri, K. and Sugiyama, M. (eds.),Proceedings of the Twenty-Second International Conference on Artifici...
-
[11]
CyCADA: Cycle-Consistent Adversarial Domain Adaptation
URL https:// arxiv.org/abs/1711.03213. Hu, W., Bansal, R., Cao, K., Rao, N., Subbian, K., and Leskovec, J. Learning backward compatible embeddings. InKDD,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.- A., Stock, P., Le Scao, T., Lavril, T., Wang, T., Lacroix, T., and El Sayed, W. Mistral 7b.arXiv preprint arXiv:2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
doi: 10.48550/arXiv.2310. 06825. URL https://arxiv.org/abs/2310. 06825. Joulin, A., Bojanowski, P., Mikolov, T., J´egou, H., and Grave, E. Loss in translation: Learning bilingual word mapping with a retrieval criterion. In Riloff, E., Chiang, D., Hock- enmaier, J., and Tsujii, J. (eds.),Proceedings of the 2018 Conference on Empirical Methods in Natural La...
-
[14]
doi: 10.18653/V1/D18-1330. Lamdan, Y . and Wolfson, H. Geometric hashing: A general and efficient model-based recognition scheme. In[1988 Proceedings] Second International Conference on Com- puter Vision, pp. 238–249,
-
[15]
doi: 10.1109/CCV .1988. 589995. Lample, G., Conneau, A., Ranzato, M., Denoyer, L., and J´egou, H. Word translation without parallel data. In ICLR,
work page doi:10.1109/ccv 1988
-
[16]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Li, Z., Zhang, X., Zhang, Y ., Long, D., Xie, P., and Zhang, M. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Deep multilingual correlation for improved word embed- dings
Lu, A., Wang, W., Bansal, M., Gimpel, K., and Livescu, K. Deep multilingual correlation for improved word embed- dings. In Mihalcea, R., Chai, J., and Sarkar, A. (eds.), Proceedings of the 2015 Conference of the North Amer- ican Chapter of the Association for Computational Lin- guistics: Human Language Technologies, pp. 250–256, Denver, Colorado, May–June
2015
-
[18]
Association for Com- putational Linguistics. doi: 10.3115/v1/N15-1028. URL https://aclanthology.org/N15-1028/. Maia, M., Handschuh, S., Freitas, A., Davis, B., McDermott, R., Zarrouk, M., and Balahur, A. Www’18 open chal- lenge: financial opinion mining and question answering. InCompanion proceedings of the the web conference 2018, pp. 1941–1942,
-
[19]
Exploiting Similarities among Languages for Machine Translation
Mikolov, T., Le, Q. V ., and Sutskever, I. Exploiting simi- larities among languages for machine translation.CoRR, abs/1309.4168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
text-embedding-3-small (model documenta- tion)
OpenAI. text-embedding-3-small (model documenta- tion). https://platform.openai.com/docs/ models/text-embedding-3-small . Accessed: 2026-01-26. Otsu, N. A threshold selection method from gray-level histograms.IEEE Transactions on Systems, Man, and Cybernetics, 9(1):62–66,
2026
-
[21]
doi: 10.1109/TSMC.1979. 4310076. Pennington, J., Socher, R., and Manning, C. GloVe: Global vectors for word representation. In Moschitti, A., Pang, B., and Daelemans, W. (eds.),Proceedings of the 2014 Conference on Empirical Methods in Natural Lan- guage Processing (EMNLP), pp. 1532–1543, Doha, Qatar, October
-
[22]
Association for Computational Linguis- tics. doi: 10.3115/v1/D14-1162. URL https:// aclanthology.org/D14-1162/. Petersen, K. B., Pedersen, M. S., et al. The matrix cookbook. Technical University of Denmark, 7(15):510,
-
[23]
URLhttps://arxiv.org/abs/2003.11942. Smith, S. L., Turban, D. H. P., Hamblin, S., and Hammerla, N. Y . Offline bilingual word vectors, orthogonal transfor- mations and the inverted softmax. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Pro- ceedings. OpenReview.net,
-
[24]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Thakur, N., Reimers, N., R ¨uckl´e, A., Srivastava, A., and Gurevych, I. Beir: A heterogenous benchmark for zero- shot evaluation of information retrieval models.arXiv preprint arXiv:2104.08663,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
FEVER: a large-scale dataset for Fact Extraction and VERification
URL https://arxiv.org/ abs/1803.05355. van den Oord, A., Li, Y ., and Vinyals, O. Repre- sentation learning with contrastive predictive coding. arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
L., van Zuylen, M., Cohan, A., and Hajishirzi, H
Wadden, D., Lin, S., Lo, K., Wang, L. L., van Zuylen, M., Cohan, A., and Hajishirzi, H. Fact or fiction: Verifying scientific claims. InProceedings of the 2020 Conference on Empirical Methods in Natu- ral Language Processing (EMNLP), pp. 7534–7550, Online, November
2020
-
[27]
doi: 10.18653/v1/2020.emnlp-main
Association for Computa- tional Linguistics. doi: 10.18653/v1/2020.emnlp-main
-
[28]
emnlp-main.609/
URL https://aclanthology.org/2020. emnlp-main.609/. Wang, C. and Mahadevan, S. Heterogeneous domain adap- tation using manifold alignment. InProceedings of the Twenty-Second International Joint Conference on Arti- ficial Intelligence - Volume Volume Two, IJCAI’11, pp. 1541–1546. AAAI Press,
2020
-
[29]
Visual Domain Adaptation with Manifold Embedded Distribution Alignment
URL https://arxiv. org/abs/1807.07258. Wang, T. and Isola, P. Understanding contrastive represen- tation learning through alignment and uniformity on the hypersphere. InICML,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Normalized word embedding and orthogonal transform for bilingual word translation
Xing, C., Wang, D., Liu, C., and Lin, Y . Normalized word embedding and orthogonal transform for bilingual word translation. In Mihalcea, R., Chai, J., and Sarkar, A. (eds.), Proceedings of the 2015 Conference of the North Amer- ican Chapter of the Association for Computational Lin- guistics: Human Language Technologies, pp. 1006–1011, Denver, Colorado, May–June
2015
-
[31]
Association for Com- putational Linguistics. doi: 10.3115/v1/N15-1104. URL https://aclanthology.org/N15-1104/. Yang, B., Cao, Y ., and Ren, Y . Integrating vector databases across embedding models. InSIGMOD,
-
[32]
URL https://arxiv. org/abs/2001.07715. Yang, J., Li, H., Campbell, D., and Jia, Y . Go-icp: A globally optimal solution to 3d icp point-set reg- istration.IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(11):2241–2254, Novem- ber
-
[33]
ISSN 2160-9292. doi: 10.1109/tpami.2015. 2513405. URL http://dx.doi.org/10.1109/ TPAMI.2015.2513405. Zhang, Y ., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., Xie, P., Yang, A., Liu, D., Lin, J., Huang, F., and Zhou, J. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176,
-
[34]
URL https: //arxiv.org/abs/2506.20923. Zimmermann, R. S., Sharma, Y ., Schneider, S., Bethge, M., and Brendel, W. Contrastive learning inverts the data generating process. InICML,
-
[35]
Since D(expx)(0) = Id TxM (e.g.,(Lee, 2003)), we have Dg(0) = Df(x)
By the chain rule, Dg(0) =Df(x)◦D(exp x)(0). Since D(expx)(0) = Id TxM (e.g.,(Lee, 2003)), we have Dg(0) = Df(x) . In an orthonormal basis of TxM, Df(x) is represented by Jf(x) and Gf(x) =J f(x)⊤Jf(x). Let v=v(x, x +) and assume ∥v∥ ≤r
2003
-
[36]
The leading term is governed by the Jacobian Jf(x), hence by the induced metric Gf(x) =J f(x)⊤Jf(x)
The intuition of the proof is that, for a nearby point y around x, the encoder admits a first-order Taylor approximation along the unique short geodesic from x to y. The leading term is governed by the Jacobian Jf(x), hence by the induced metric Gf(x) =J f(x)⊤Jf(x). Local encoder optimality forces Gf(x) to be a scalar multiple of the identity, which makes...
2003
-
[37]
The number of partitions is mt =⌈|L t−1|/dmax⌉, where dmax = max(dE1 , dE2), which ensures each view has sufficient anchors for a dimensionally well-posed local neighborhood
Otherwise, at iterationt, we replace FPS with a k-means partition of Lt−1 in E1 to ensure diversity of views. The number of partitions is mt =⌈|L t−1|/dmax⌉, where dmax = max(dE1 , dE2), which ensures each view has sufficient anchors for a dimensionally well-posed local neighborhood. Each anchor in Lt−1 is included in its ρ nearest clusters ( ρ=2 in our e...
2021
-
[38]
The queries are short factual claims, and the corpus introductory sections of Wikipedia pages
is a fact-verification dataset. The queries are short factual claims, and the corpus introductory sections of Wikipedia pages. Table 5 provides dataset statistics, including query counts, corpus sizes, and the average number of relevant documents per query. C.1.2. EMBEDDINGMODELS We generate embeddings using a mix of proprietary API services and open-weig...
2023
-
[39]
We optimizeWwith Adam (learning rate10 −3) for 100 epochs. Canonical Correlation Analysis (CCA).We standardize each space independently, fit CCA on the seed pairs to learn one linear projection per space that maximizes correlation between projected seed embeddings. Multi-Layer Perceptron (MLP).We train a single-hidden-layer MLP mapping from the source emb...
2018
-
[40]
by sweeping the seed budget n∈ {15,20,30} and the target overlap ratio α∈ {0.15,0.2,0.3} . Overall, most reference–target pairs preserve strong precision and recall under OOD seeding; the few degraded cases align with our Theorem 1, which predicts that links supported primarily by long-range anchors are less reliable. D. Details of Section 6 D.1. Implemen...
2025
-
[41]
2048 50 65.49 18 / 299 StackExchangeClustering.v2 (Geigle et al.,
2048
-
[42]
2048 121 57.51 19 / 148 return the integrated database T(D 1)∪D
2048
-
[43]
We use a FAISS GPU index with inner-product search overℓ2-normalized embeddings (equivalently cosine similarity)
, whererel i is the graded relevance of the item at rankiandIDCG@kis the DCG of the ideal ranking. We use a FAISS GPU index with inner-product search overℓ2-normalized embeddings (equivalently cosine similarity). D.1.2. GLOBALCROSS-MODELCLUSTERING We evaluate cross-model clustering using two clustering benchmarks from MTEB (Enevoldsen et al., 2025). Both ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.