Why Linear Recurrent Memory Works in Partially Observable Reinforcement Learning
Pith reviewed 2026-06-28 23:25 UTC · model grok-4.3
The pith
A linear recurrent filter exactly reproduces the belief vector logits of a hidden Markov model when transitions are deterministic, serving as a sufficient statistic for optimal policy learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
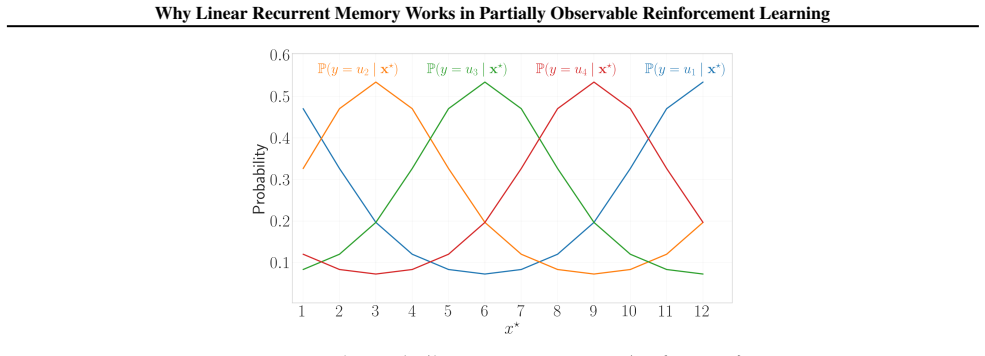
The first linear filter exactly reproduces the pre-softmax logits of the belief vector in a hidden Markov model under a deterministic transition matrix, thereby serving as a sufficient statistic for optimal policy learning. The second linear filter achieves vanishing state-decoding error under a nearly deterministic transition matrix. The results extend to action-controlled HMMs, where the corresponding linear filters become time-varying with action-dependent dynamics.
What carries the argument
Two linear filters, the first reproducing pre-softmax belief logits exactly under deterministic transitions and the second driving state-decoding error to zero under near-determinism; both become time-varying and action-dependent in controlled settings.
If this is right
- Optimal policies can be learned directly from the linear filter output without separate belief-state computation.
- The filter output is a sufficient statistic, so no decision-relevant information is lost under the determinism condition.
- The same linear construction applies to action-controlled HMMs by making the filter dynamics depend on the chosen action.
- Linear recurrent units can serve as feature extractors that support policy learning in small POMDP environments.
Where Pith is reading between the lines
- The linear structure may continue to provide useful approximations even when transitions deviate moderately from determinism.
- Trained linear recurrent networks on POMDP tasks might implicitly learn filters close to these constructions.
- One could measure how quickly decoding error grows as transition stochasticity increases to map the boundary of the exact regime.
Load-bearing premise
The hidden Markov model's transition matrix must be deterministic or nearly deterministic for exact reproduction or vanishing error to hold.
What would settle it
Apply the linear filter to an HMM whose transition matrix has substantial stochasticity and check whether the output still matches the belief logits exactly or the decoding error stays near zero; sustained mismatch or error would disprove the claim.
Figures






read the original abstract
The family of linear recurrent neural networks has shown strong performance as recurrent memory units in partially observable reinforcement learning. We provide a theoretical justification for their empirical effectiveness by constructing and studying two linear filters: (i) the first exactly reproduces the pre-softmax logits of the belief vector in a hidden Markov model (HMM) under a deterministic transition matrix, thereby serving as a sufficient statistic for optimal policy learning, (ii) the second achieves vanishing state-decoding error under a nearly deterministic transition matrix, thus reducing state ambiguity to near zero. The results extend to action-controlled HMMs, where the corresponding linear filters become time-varying with action-dependent dynamics. We illustrate our main results through numerical experiments and further show that the constructed linear filter serves as a strong feature extractor in a small reinforcement learning game.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript constructs two linear filters for hidden Markov models (HMMs) to explain the effectiveness of linear recurrent networks as memory in partially observable RL. The first filter exactly reproduces the pre-softmax logits of the belief vector under a deterministic transition matrix, serving as a sufficient statistic for optimal policy learning. The second achieves vanishing state-decoding error under a nearly deterministic transition matrix. Results extend to action-controlled HMMs (with time-varying, action-dependent filters) and are illustrated via numerical experiments plus a small RL game demonstrating the filter as a feature extractor.
Significance. If the constructions and proofs hold, the work supplies a concrete theoretical account of why linear recurrences can function as (near-)exact belief-state representations in POMDPs, under clearly stated conditions on the transition dynamics. This is a positive contribution that links architectural choices directly to HMM filtering properties and could guide memory-module design; the numerical validation in an RL setting adds empirical grounding.
major comments (2)
- [§3] §3 (first linear filter construction): the exact logit reproduction and sufficiency claim are derived only for deterministic transition matrices (the Bayes update reduces to a single predecessor term whose normalization cancels). The paper must state explicitly whether this premise is required for the central sufficiency result or whether the filter remains useful more broadly; without that clarification the title and introduction risk overstating generality for typical stochastic-transition POMDPs.
- [§4] §4 (action-controlled extension): the time-varying filter is obtained by making the recurrence action-dependent, yet the sufficiency argument still rests on the same determinism premise. It is unclear whether the optimal-policy guarantee survives when the action also modulates the (still deterministic) transition; a short counter-example or additional derivation step would strengthen the claim.
minor comments (2)
- Notation for the pre-softmax logits and the normalization constants in the belief update should be introduced once and used consistently; several equations reuse the same symbols for distinct quantities.
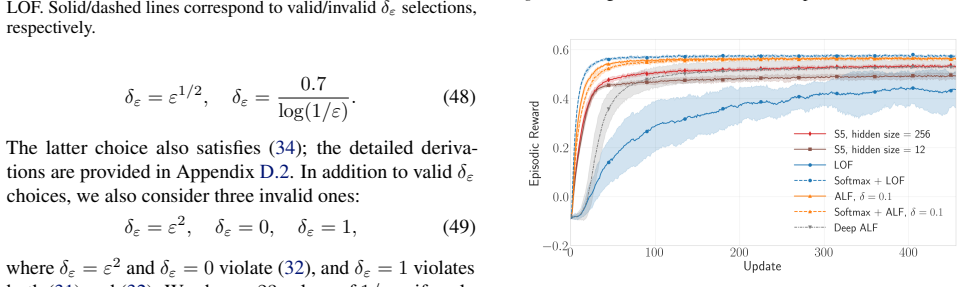
- Figure 2 (numerical experiment) would benefit from an additional panel showing the decoding error as a function of the deviation from determinism, to quantify the “nearly deterministic” regime.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate clarifications into the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (first linear filter construction): the exact logit reproduction and sufficiency claim are derived only for deterministic transition matrices (the Bayes update reduces to a single predecessor term whose normalization cancels). The paper must state explicitly whether this premise is required for the central sufficiency result or whether the filter remains useful more broadly; without that clarification the title and introduction risk overstating generality for typical stochastic-transition POMDPs.
Authors: We agree that the exact reproduction of pre-softmax belief logits and the resulting sufficiency for optimal policy learning are derived specifically under deterministic transition matrices, where the Bayes update collapses to a single predecessor. The manuscript already states this assumption in the abstract and Section 3, but we will add an explicit sentence in both the introduction and Section 3 clarifying that the central sufficiency result requires deterministic transitions and that the second filter addresses the nearly-deterministic regime. This revision will remove any risk of overstating generality. revision: yes
-
Referee: [§4] §4 (action-controlled extension): the time-varying filter is obtained by making the recurrence action-dependent, yet the sufficiency argument still rests on the same determinism premise. It is unclear whether the optimal-policy guarantee survives when the action also modulates the (still deterministic) transition; a short counter-example or additional derivation step would strengthen the claim.
Authors: Under action-controlled deterministic transitions the same single-predecessor argument applies, with the transition matrix now selected by the current action; the linear filter therefore continues to reproduce the exact belief logits and remains a sufficient statistic. We will insert a short additional derivation paragraph in Section 4 that writes out the action-dependent Bayes update and confirms the sufficiency claim carries over directly. revision: yes
Circularity Check
No circularity; explicit construction under stated deterministic-transition assumption
full rationale
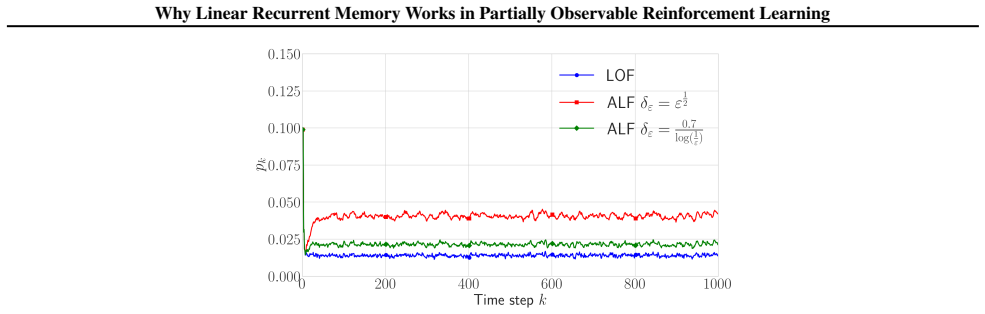
The paper constructs linear filters mathematically to match HMM belief logits exactly when the transition matrix is deterministic, and to achieve vanishing error when nearly deterministic. This is presented as a direct derivation from the model equations rather than a fit to data or a redefinition of the target quantity. No load-bearing self-citations, fitted-input predictions, or ansatzes smuggled via prior work are indicated in the abstract or context; the central claim is an explicit equivalence under an openly stated premise, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The environment is modeled as a hidden Markov model with deterministic (or nearly deterministic) transition matrix.
Reference graph
Works this paper leans on
-
[1]
Grazzi, R., Siems, J., Zela, A., Franke, J. K., Hutter, F., and Pontil, M. Unlocking state-tracking in linear RNNs through negative eigenvalues.arXiv:2411.12537,
-
[2]
Efficiently Modeling Long Sequences with Structured State Spaces
9 Why Linear Recurrent Memory Works in Partially Observable Reinforcement Learning Gu, A., Goel, K., and R´e, C. Efficiently modeling long se- quences with structured state spaces.arXiv:2111.00396,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
POPGym: Benchmarking partially observable reinforcement learning.arXiv:2303.01859,
Morad, S., Kortvelesy, R., Bettini, M., Liwicki, S., and Prorok, A. POPGym: Benchmarking partially observable reinforcement learning.arXiv:2303.01859,
-
[4]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Simplified State Space Layers for Sequence Modeling
Smith, J. T., Warrington, A., and Linderman, S. W. Simplified state space layers for sequence modeling. arXiv:2208.04933,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Additional Discussion A.1
10 Why Linear Recurrent Memory Works in Partially Observable Reinforcement Learning A. Additional Discussion A.1. Observability Assumption When r= 0 and P=I , we have eE=E and eEs reduces to E since M= 1 . In this case, Assumptions 5.6a and 5.6b coincide with those of Khammassi et al. (2025, Assumptions 1 and 3). For r≥1 or M >1 , however, they are weaker...
2025
-
[7]
Nevertheless,ALFstill achieves good state decoding
First, although the overall trends are similar, there is a clear discrepancy between the dynamics ofALFandLOF. Nevertheless,ALFstill achieves good state decoding. Second, since δ1 < δ 2, the dynamics under δ1 appear smoother than those under δ2, as the smaller value reduces sensitivity to instantaneous (and noisy) observations. However, this smoother beha...
2023
-
[8]
Lemma D.3.Consider a nearly-deterministic transition matrixTunder Assumptions 5.3 and 5.6
Now, if we set α≥α 1(x) = log( X n∈Γ(x) 1 M dn(x) + 2W)−log(− 1 2 Z − 1 M 0 X n∈Γ(x) Λn(τ;x) τ dτ),(122) and substitute it back into (110), we obtain: lim ε→0 Aε(x)≤ 1 2 Z − 1 M 0 X n∈Γ(x) Λn(τ;x) τ dτ <0.(123) 22 Why Linear Recurrent Memory Works in Partially Observable Reinforcement Learning Now lettingα≥max x∈X \{x1} α1(x), we conclude the proof: lim ε...
1996
-
[9]
= · · O(ε) D2 22 +O(ε) .(153) Similarly, forT ℓ we can get: T ℓ = · · O(ε) Dℓ 22 +O(ε) (a) = · · O(ε) O(ε) .(154) where(a)follows from the fact thatD 22 is a nilpotent matrix with indexℓ. Fork≥ℓ, we always have: T k = · · O(ε) O(ε) .(155) Therefore, in conclusion, fork≥ℓand∀x∈ X \ eX, we have: P[x ⋆ k =x] =π k(x) = (T) kπ0 x =O(ε).(156) Lemma D.5.Under a ...
2016
-
[10]
The total episodic reward therefore lies in PK k=1 r(x⋆ k)∈[−1,1]
The reward function is defined as r(x⋆ k) = 1 K 1{x ⋆ k is a goal state} −1{x ⋆ k is a trap state} ,(196) whereKis the episode length. The total episodic reward therefore lies in PK k=1 r(x⋆ k)∈[−1,1]. Our PPO implementations, including the encoder, S5, actor, and critic, follow Lu et al. (2023). The general hyperparameters used forLOF,ALF, andS5-based me...
2023
-
[11]
33 Why Linear Recurrent Memory Works in Partially Observable Reinforcement Learning E.2.2. ALF-INSPIREDDEEPLEARNINGMEMORY In our experiment, all permutation matricesP(CW1) , P(CW2) , P(CCW1) , and P(CCW2) are circulant, meaning each row is a cyclic right shift of the previous one. According to Gray (2006, Theorem 3.1), any circulant matrix can be diagonal...
2006
-
[12]
Next, we keepΛ(·),E,V, andδlearnable, but vary their initialization schemes: • Random E: Λ(·) and V are initialized with their true values, and δ= 0.1
From Figure 9, we observe that making all parameters learnable allowsDeep ALFto slightly outperformALF, reaching performance levels close to the softmax-processedLOF. Next, we keepΛ(·),E,V, andδlearnable, but vary their initialization schemes: • Random E: Λ(·) and V are initialized with their true values, and δ= 0.1 . For E, we first draw κ∈R S×N from a s...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.