Industrializing Prediction-Powered Inference: The GLIDE Library for Reliable GenAI and Agentic Systems Evaluation
Pith reviewed 2026-06-28 22:25 UTC · model grok-4.3
The pith
GLIDE unifies scattered prediction-powered inference methods into a single scipy-style library for mean estimation with valid confidence intervals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GLIDE unifies state-of-the-art PPI estimators (PPI++, Stratified PPI, Predict-Then-Debias and its stratified variants, Active Statistical Inference) and samplers (uniform, stratified, active, cost-optimal) under a scipy-style API specialized to mean estimation, ships with a reproducible Monte Carlo validation suite, an empirically grounded decision tree for method selection, and demonstrates substantial annotation savings at equivalent precision in an agentic evaluation case study.
What carries the argument
The unified scipy-style API that exposes multiple PPI estimators and samplers for mean estimation while preserving their original statistical properties.
If this is right
- Researchers obtain debiased mean estimates with valid intervals by labeling only a small fraction of the data while using LLM predictions on the rest.
- A single decision tree based on empirical performance guides selection among the available PPI variants for a given evaluation task.
- The reproducible Monte Carlo suite allows any user to verify that the implemented estimators match the theoretical guarantees on synthetic data.
- Annotation budgets for agentic system evaluation can be reduced while maintaining the same statistical precision as full human labeling.
Where Pith is reading between the lines
- The same API pattern could be applied to other estimation targets such as quantiles or regression coefficients if the underlying PPI theory extends.
- Adoption would increase if the library added direct support for common LLM evaluation benchmarks beyond the single agentic case study.
- The cost-optimal sampler might interact with downstream agent training loops in ways the current validation does not yet test.
Load-bearing premise
The various PPI methods from prior papers can be correctly re-implemented and exposed through a single unified API without introducing implementation bugs or altering their statistical guarantees, and the Monte Carlo validation suite plus the single case study are sufficient to establish practical reliability for real agentic systems.
What would settle it
Running the library's estimators on the exact datasets and prediction models from the original PPI papers and observing that the produced point estimates or confidence intervals differ from the published results beyond numerical precision.
Figures
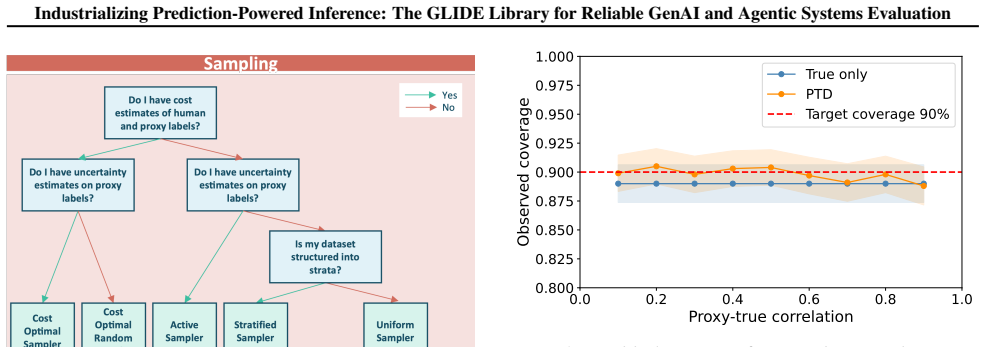
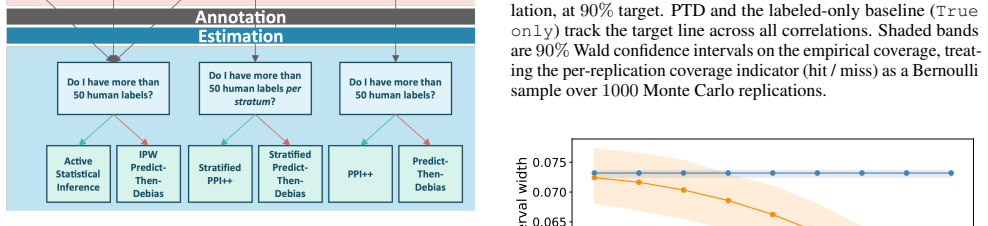

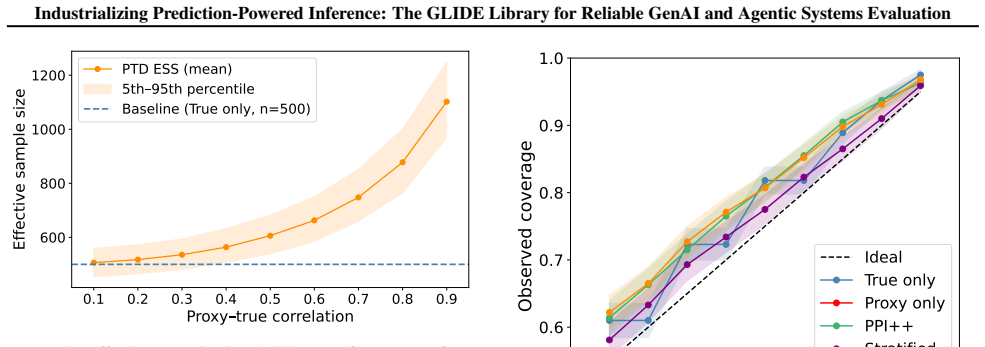
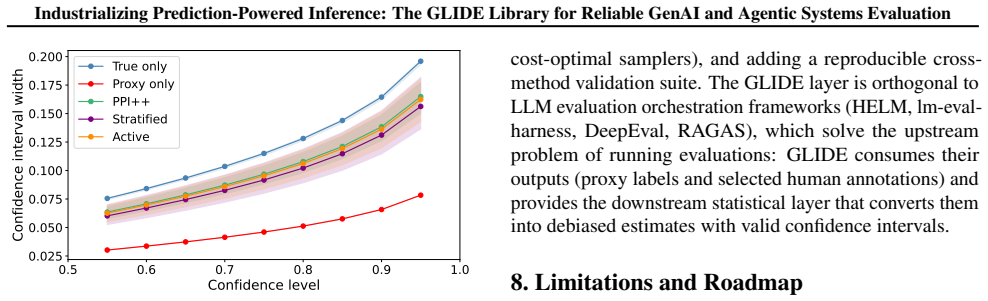
read the original abstract
Reliable evaluation of agentic systems requires unbiased estimates with valid uncertainty, but standard practice navigates between costly human annotation and biased LLM-as-judge proxies. Prediction-powered inference (PPI) combines both into debiased estimates with valid confidence intervals, yet its various methods remain scattered across papers under partial implementations. We introduce GLIDE, an open-source Python library that unifies state-of-the-art PPI estimators (PPI++, Stratified PPI, Predict-Then-Debias and its stratified variants, Active Statistical Inference) and samplers (uniform, stratified, active, cost-optimal) under a scipy-style API specialized to mean estimation. GLIDE ships with a reproducible Monte Carlo validation suite, an empirically grounded decision tree for method selection, and an agentic evaluation case study showing substantial annotation savings at equivalent precision. The GLIDE package is available at this URL: https://github.com/EmertonData/glide
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GLIDE, an open-source Python library that unifies PPI estimators (PPI++, Stratified PPI, Predict-Then-Debias and variants, Active Statistical Inference) and samplers (uniform, stratified, active, cost-optimal) under a scipy-style API for mean estimation. It includes a reproducible Monte Carlo validation suite, an empirically grounded decision tree for method selection, and an agentic evaluation case study claiming substantial annotation savings at equivalent precision.
Significance. If the re-implementations preserve the original statistical properties and the validation is robust, GLIDE would provide a practical, standardized tool for reliable evaluation of GenAI and agentic systems, lowering annotation costs while maintaining valid confidence intervals. The unification and tooling contribution is the primary value, as the underlying methods originate from prior work.
major comments (2)
- [Monte Carlo validation suite] The Monte Carlo validation suite (described in the abstract and presumably detailed in the methods or experiments section) tests internal consistency on synthetic data but does not report comparisons of outputs, variance estimates, or coverage rates against the original authors' reference implementations or closed-form derivations for PPI++, Stratified PPI, or Predict-Then-Debias. This is load-bearing for the central claim that the unified API preserves statistical guarantees without introducing bugs.
- [agentic evaluation case study] The agentic evaluation case study claims 'substantial annotation savings at equivalent precision,' but without explicit reporting of the exact PPI variant used, the stratification or active sampling parameters, and direct comparison to non-PPI baselines on the same data, it is difficult to assess whether the savings are robust or method-specific.
minor comments (2)
- The abstract mentions 'an empirically grounded decision tree' but provides no details on its construction, training data, or validation metrics; this should be clarified or moved to a dedicated subsection.
- The GitHub URL is given but the manuscript should include a permanent archive link (e.g., Zenodo DOI) for the specific version used in the validation and case study to ensure reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and commit to revisions that directly strengthen the validation and reproducibility claims.
read point-by-point responses
-
Referee: [Monte Carlo validation suite] The Monte Carlo validation suite (described in the abstract and presumably detailed in the methods or experiments section) tests internal consistency on synthetic data but does not report comparisons of outputs, variance estimates, or coverage rates against the original authors' reference implementations or closed-form derivations for PPI++, Stratified PPI, or Predict-Then-Debias. This is load-bearing for the central claim that the unified API preserves statistical guarantees without introducing bugs.
Authors: We agree that direct comparisons to reference implementations are necessary to substantiate that the unified API preserves statistical properties. The current suite emphasizes internal consistency and reproducibility on synthetic data, but we will expand the validation section in the revision to include side-by-side comparisons of point estimates, variance estimates, and empirical coverage rates against the original authors' reference code (where publicly available) and closed-form derivations for PPI++, Stratified PPI, and Predict-Then-Debias. These additions will be presented in new tables and figures. revision: yes
-
Referee: [agentic evaluation case study] The agentic evaluation case study claims 'substantial annotation savings at equivalent precision,' but without explicit reporting of the exact PPI variant used, the stratification or active sampling parameters, and direct comparison to non-PPI baselines on the same data, it is difficult to assess whether the savings are robust or method-specific.
Authors: We acknowledge the need for greater transparency in the case study. The revised manuscript will explicitly identify the PPI variant (including any stratified or active components), report the exact sampling parameters and cost model, and add a direct comparison table against non-PPI baselines (uniform sampling without debiasing) on the identical agentic evaluation dataset. This will clarify the source of the reported savings and allow assessment of robustness. revision: yes
Circularity Check
No circularity: library unifies prior methods without new derivations
full rationale
The paper presents a software library (GLIDE) that re-implements and unifies existing PPI estimators from prior literature under a common API. No new mathematical derivations, predictions, or uniqueness claims are introduced within the paper itself. The central claims concern implementation, API design, Monte Carlo validation, and a case study; these do not reduce to self-defined parameters or load-bearing self-citations. External citations to original PPI papers are independent support for the methods being wrapped, not circular. This matches the default expectation of a non-circular tooling paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The statistical validity of the cited PPI estimators holds under the conditions used in the library.
Reference graph
Works this paper leans on
-
[1]
PPI++: Efficient Prediction-Powered Inference
Angelopoulos, A. N., Bates, S., Fannjiang, C., Jordan, M. I., and Zrnic, T. Prediction-powered inference.Science, 382 (6671):669–674, 2023a. Angelopoulos, A. N., Duchi, J. C., and Zrnic, T. Ppi++: Efficient prediction-powered inference.arXiv preprint arXiv:2311.01453, 2023b. Angelopoulos, A. N., Eisenstein, J., Berant, J., Agarwal, A., and Fisch, A. Cost-...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
AutoEval Done Right: Using Synthetic Data for Model Evaluation
Boyeau, P., Angelopoulos, A. N., Yosef, N., Malik, J., and Jordan, M. I. Autoeval done right: Using synthetic data for model evaluation.arXiv preprint arXiv:2403.07008,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Surrogate-powered inference: Regularization and adap- tivity.arXiv preprint arXiv:2512.21826,
Chen, J., Wang, H., Lumley, T., Dai, X., and Chen, Y . Surrogate-powered inference: Regularization and adap- tivity.arXiv preprint arXiv:2512.21826,
-
[4]
W., Eisenstein, J., Globerson, A., and Fisch, A
Cowen-Breen, C., Agarwal, A., Bates, S., Cohen, W. W., Eisenstein, J., Globerson, A., and Fisch, A. Multiple-prediction-powered inference.arXiv preprint arXiv:2603.27414,
-
[5]
Csillag, D., Struchiner, C. J., and Goedert, G. T. Prediction- powered e-values.arXiv preprint arXiv:2502.04294,
-
[6]
De Bartolomeis, P., Abad, J., Wang, G., Donhauser, K., Duch, R. M., Yang, F., and Dahabreh, I. J. Efficient randomized experiments using foundation models.arXiv preprint arXiv:2502.04262,
-
[7]
Gligori´c, K., Zrnic, T., Lee, C., Candes, E., and Jurafsky, D. Can unconfident llm annotations be used for confident conclusions? InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Associa- tion for Computational Linguistics: Human Language 8 Industrializing Prediction-Powered Inference: The GLIDE Library for Reliable GenA...
2025
-
[8]
Predictions as Surrogates: Revisiting Surrogate Outcomes in the Age of AI
Ji, W., Lei, L., and Zrnic, T. Predictions as surrogates: Revisiting surrogate outcomes in the age of ai.arXiv preprint arXiv:2501.09731,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
M., Lu, K., Zrnic, T., Wang, S., and Bates, S
Kluger, D. M., Lu, K., Zrnic, T., Wang, S., and Bates, S. Prediction-powered inference with imputed co- variates and nonuniform sampling.arXiv preprint arXiv:2501.18577,
-
[10]
SADA: Safe and Adaptive Aggregation of Multiple Black-Box Predictions in Semi-Supervised Learning
Shan, J., Chen, Z., Dong, Y ., Wang, Y ., and Zhao, J. Sada: Safe and adaptive aggregation of multiple black-box pre- dictions in semi-supervised learning.arXiv preprint arXiv:2509.21707,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Demystifying prediction powered inference
Song, Y ., Kluger, D. M., Parikh, H., and Gu, T. Demys- tifying prediction powered inference.arXiv preprint arXiv:2601.20819,
-
[12]
R-judge: Benchmark- ing safety risk awareness for llm agents
Yuan, T., He, Z., Dong, L., Wang, Y ., Zhao, R., Xia, T., Xu, L., Zhou, B., Li, F., Zhang, Z., et al. R-judge: Benchmark- ing safety risk awareness for llm agents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 1467–1490,
2024
-
[13]
Zrnic, T. and Cand`es, E. J. Active statistical inference.arXiv preprint arXiv:2403.03208,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.