DecMem: Towards Minute-Long Consistent World Generation with Decoupled Memory
Pith reviewed 2026-06-28 22:36 UTC · model grok-4.3
The pith
A decoupled memory split into sparse global and anchored local parts lets video models keep fine details consistent across minute-long sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
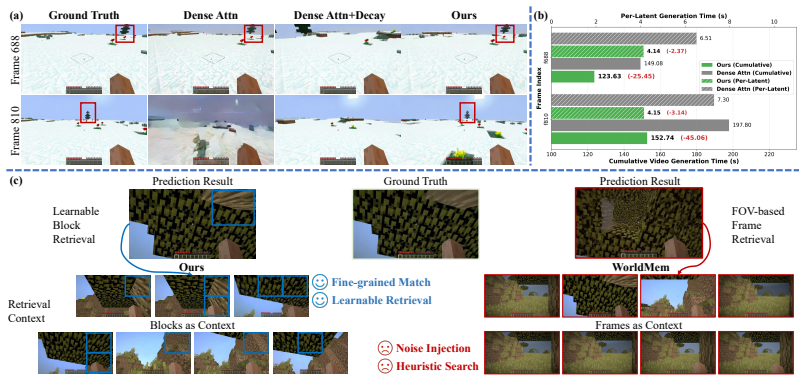
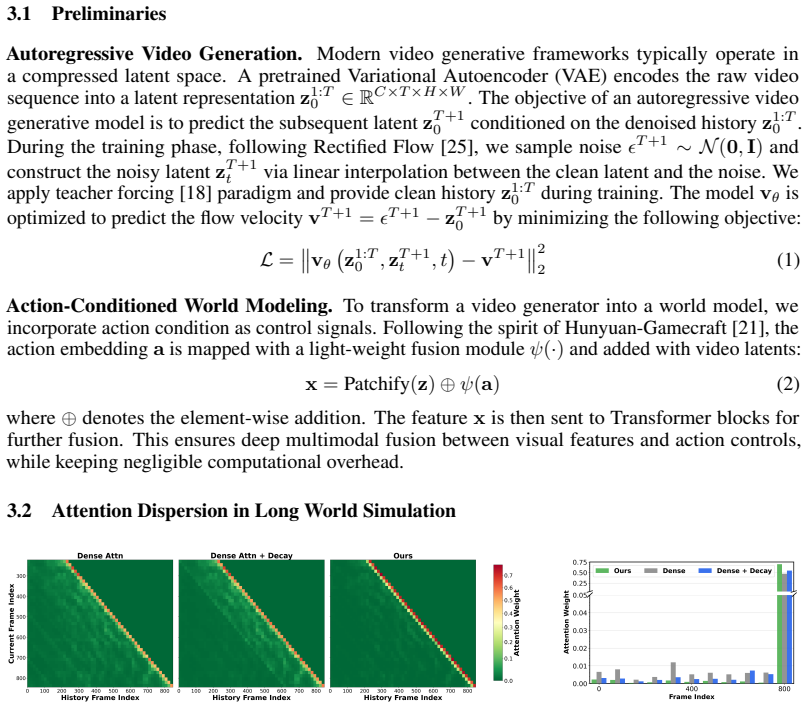
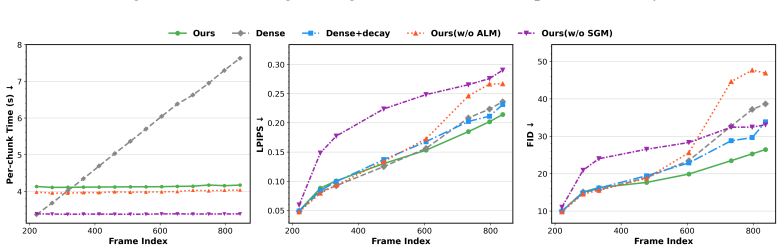
By separating memory into Sparse Global Memory for efficient fine-grained access to the entire history and Anchored Local Memory for stable high-quality next-frame extrapolation, DecMem removes the computational and dispersion bottlenecks of naive learnable memories, enabling minute-level controllable video generation with high fidelity and long-term consistency.
What carries the argument
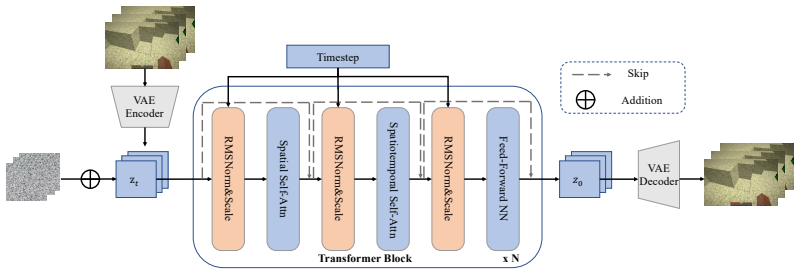
Decoupled memory architecture that pairs Sparse Global Memory for efficient access to global history with Anchored Local Memory for stable local extrapolation.
If this is right
- Minute-level controllable long video generation becomes feasible without explicit 3D memory.
- Long-horizon extrapolation quality exceeds that of prior state-of-the-art methods.
- Precise and efficient long-term memory access is maintained while preserving high fidelity.
- The same architecture supports controllable generation tasks that require extended temporal reasoning.
Where Pith is reading between the lines
- The same split-memory pattern could be tested on audio or text sequences to check whether the inefficiency and dispersion problems appear in other modalities.
- If the design scales, world models might shift away from heavy 3D representations toward purely learned 2D memory structures.
- Combining the decoupled memory with different backbone generators would reveal whether the gains are architecture-specific or general.
Load-bearing premise
The two limitations of computational inefficiency and attention dispersion are the main barriers to long-horizon consistency, and separating memory into global and local streams fixes both at scale.
What would settle it
Run the model on sequences exceeding one minute and check whether quantitative consistency metrics or human raters detect growing drift in object identity, position, or appearance; sustained drift would falsify the central claim.
Figures









read the original abstract
Recent advances in video generative models have promoted rapid progress in controllable world models. However, maintaining fine-grained spatio-temporal consistency under long-horizon reasoning remains a key challenge. In this work, we move beyond explicit 3D memory and coarse frame-level implicit modeling, and propose a fine-grained, learnable, and scalable memory for consistent world generation. We first identify two fundamental limitations of na\"ive learnable memory architectures in long-horizon extrapolation, namely computational inefficiency and attention dispersion. Through a systematic analysis of attention dispersion, we propose DecMem, a decoupled memory architecture that employs Sparse Global Memory for efficient fine-grained access to global history and Anchored Local Memory for stable and high-quality extrapolation. Extensive experiments demonstrate that DecMem significantly outperforms current state-of-the-art methods. By ensuring precise and efficient long-term memory and achieving superior extrapolation capabilities, DecMem enables minute-level controllable long video generation with high fidelity and consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DecMem, a decoupled memory architecture for consistent long-horizon video generation in controllable world models. It identifies computational inefficiency and attention dispersion as fundamental limitations of naive learnable memory architectures, then introduces Sparse Global Memory for efficient fine-grained access to global history and Anchored Local Memory for stable extrapolation. The work claims that extensive experiments show DecMem significantly outperforms current state-of-the-art methods, enabling minute-level controllable long video generation with high fidelity and consistency.
Significance. If the experimental results hold, the contribution would be significant for advancing scalable long-term memory mechanisms in video generative models, directly targeting spatio-temporal consistency over extended horizons beyond explicit 3D or coarse implicit approaches. The systematic analysis of attention dispersion and the specific decoupled design offer a technically grounded path to minute-scale extrapolation.
major comments (1)
- [Abstract] Abstract: The assertion that 'extensive experiments demonstrate that DecMem significantly outperforms current state-of-the-art methods' is presented without any metrics, baselines, dataset details, ablation studies, or quantitative results. This absence is load-bearing for the central claim of superiority in extrapolation, fidelity, and consistency, as no evidence is supplied to support it.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'extensive experiments demonstrate that DecMem significantly outperforms current state-of-the-art methods' is presented without any metrics, baselines, dataset details, ablation studies, or quantitative results. This absence is load-bearing for the central claim of superiority in extrapolation, fidelity, and consistency, as no evidence is supplied to support it.
Authors: We agree that the abstract, as a concise summary, does not include specific quantitative details. The full manuscript presents these in Section 4 (Experiments), including comparisons against state-of-the-art baselines on standard datasets, quantitative metrics for fidelity and consistency, and ablation studies. To address the concern, we will revise the abstract to incorporate key quantitative highlights supporting the superiority claims. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central narrative identifies two limitations of naive learnable memory (computational inefficiency and attention dispersion) via analysis, then proposes a decoupled architecture (Sparse Global Memory + Anchored Local Memory) as a remedy. No equations, parameter-fitting steps, predictions of fitted quantities, or self-citation chains appear in the provided text. The claim of superior extrapolation is presented as an empirical outcome to be validated externally rather than derived by construction from the inputs. The derivation chain is therefore self-contained and does not reduce to its own definitions or fitted values.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Philip J. Ball, Jakob Bauer, Frank Belletti, Bethanie Brownfield, Ariel Ephrat, Shlomi Fruchter, Agrim Gupta, Kristian Holsheimer, Aleksander Holynski, Jiri Hron, Christos Kaplanis, Marjorie Limont, Matt McGill, Yanko Oliveira, Jack Parker-Holder, Frank Perbet, Guy Scully, Jeremy Shar, Stephen Spencer, Omer Tov, Ruben Villegas, Emma Wang, Jessica Yung, Ci...
2025
-
[2]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
2024
-
[3]
SkyReels-V2: Infinite-length Film Generative Model
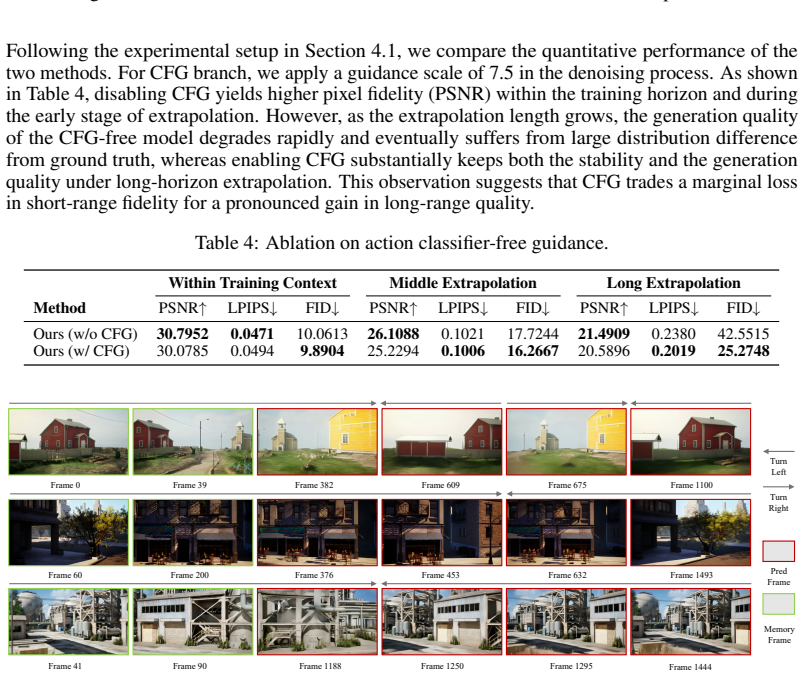
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Kaijin Chen, Dingkang Liang, Xin Zhou, Yikang Ding, Xiaoqiang Liu, Pengfei Wan, and Xiang Bai. Out of sight but not out of mind: Hybrid memory for dynamic video world models.arXiv preprint arXiv:2603.25716, 2026
-
[5]
VRAG: Learning World Models for Interactive Video Generation
Taiye Chen, Xun Hu, Zihan Ding, and Chi Jin. Learning world models for interactive video generation.arXiv preprint arXiv:2505.21996, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Lol: Longer than longer, scaling video generation to hour.arXiv preprint arXiv:2601.16914, 2026
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Lol: Longer than longer, scaling video generation to hour.arXiv preprint arXiv:2601.16914, 2026
-
[7]
Oasis: A universe in a transformer
Decart, Julian Quevedo, Quinn McIntyre, Spruce Campbell, Xinlei Chen, and Robert Wachen. Oasis: A universe in a transformer. 2024. URL https://oasis-model.github.io/. Project website
2024
-
[8]
Zicheng Duan, Jiatong Xia, Zeyu Zhang, Wenbo Zhang, Gengze Zhou, Chenhui Gou, Yefei He, Feng Chen, Xinyu Zhang, and Lingqiao Liu. Liveworld: Simulating out-of-sight dynamics in generative video world models.arXiv preprint arXiv:2603.07145, 2026
-
[9]
Ruili Feng, Han Zhang, Zhantao Yang, Jie Xiao, Zhilei Shu, Zhiheng Liu, Andy Zheng, Yukun Huang, Yu Liu, and Hongyang Zhang. The matrix: Infinite-horizon world generation with real-time moving control.arXiv preprint arXiv:2412.03568, 2024
-
[10]
Junliang Guo, Yang Ye, Tianyu He, Haoyu Wu, Yushu Jiang, Tim Pearce, and Jiang Bian. Mineworld: a real-time and open-source interactive world model on minecraft.arXiv preprint arXiv:2504.08388, 2025
-
[11]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Streamingt2v: Consistent, dynamic, and extendable long video generation from text
Roberto Henschel, Levon Khachatryan, Hayk Poghosyan, Daniil Hayrapetyan, Vahram Tade- vosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Streamingt2v: Consistent, dynamic, and extendable long video generation from text. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2568–2577, 2025
2025
-
[13]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017. 10
2017
-
[14]
Relic: Interactive video world model with long-horizon memory
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, et al. Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
-
[15]
Junchao Huang, Xinting Hu, Boyao Han, Shaoshuai Shi, Zhuotao Tian, Tianyu He, and Li Jiang. Memory forcing: Spatio-temporal memory for consistent scene generation on minecraft.arXiv preprint arXiv:2510.03198, 2025
-
[16]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Fifo-diffusion: Generating infinite videos from text without training.Advances in Neural Information Processing Systems, 37: 89834–89868, 2024
Jihwan Kim, Junoh Kang, Jinyoung Choi, and Bohyung Han. Fifo-diffusion: Generating infinite videos from text without training.Advances in Neural Information Processing Systems, 37: 89834–89868, 2024
2024
-
[18]
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vighnesh Birodkar, Jimmy Yan, Ming-Chang Chiu, et al. Videopoet: A large language model for zero-shot video generation.arXiv preprint arXiv:2312.14125, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Haodong Li, Shaoteng Liu, Zhe Lin, and Manmohan Chandraker. Rolling sink: Bridging limited-horizon training and open-ended testing in autoregressive video diffusion.arXiv preprint arXiv:2602.07775, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Jiaqi Li, Junshu Tang, Zhiyong Xu, Longhuang Wu, Yuan Zhou, Shuai Shao, Tianbao Yu, Zhiguo Cao, and Qinglin Lu. Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition.arXiv preprint arXiv:2506.17201, 2025
-
[22]
Cameras as relative positional encoding.arXiv preprint arXiv:2507.10496, 2025
Ruilong Li, Brent Yi, Junchen Liu, Hang Gao, Yi Ma, and Angjoo Kanazawa. Cameras as relative positional encoding.arXiv preprint arXiv:2507.10496, 2025
-
[23]
Runjia Li, Philip Torr, Andrea Vedaldi, and Tomas Jakab. Vmem: Consistent interactive video scene generation with surfel-indexed view memory.arXiv preprint arXiv:2506.18903, 2025
-
[24]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Freelong: Training-free long video generation with spectralblend temporal attention.Advances in Neural Information Processing Systems, 37: 131434–131455, 2024
Yu Lu, Yuanzhi Liang, Linchao Zhu, and Yi Yang. Freelong: Training-free long video generation with spectralblend temporal attention.Advances in Neural Information Processing Systems, 37: 131434–131455, 2024
2024
-
[27]
Yume-1.5: A text-controlled interactive world generation model
Xiaofeng Mao, Zhen Li, Chuanhao Li, Xiaojie Xu, Kaining Ying, Tong He, Jiangmiao Pang, Yu Qiao, and Kaipeng Zhang. Yume-1.5: A text-controlled interactive world generation model. arXiv preprint arXiv:2512.22096, 2025
-
[28]
Takeru Miyato, Bernhard Jaeger, Max Welling, and Andreas Geiger. Gta: A geometry-aware attention mechanism for multi-view transformers.arXiv preprint arXiv:2310.10375, 2023
-
[29]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[30]
Haonan Qiu, Menghan Xia, Yong Zhang, Yingqing He, Xintao Wang, Ying Shan, and Ziwei Liu. Freenoise: Tuning-free longer video diffusion via noise rescheduling.arXiv preprint arXiv:2310.15169, 2023
-
[31]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 11
2022
-
[32]
Motion- stream: Real-time video generation with interactive motion controls
Joonghyuk Shin, Zhengqi Li, Richard Zhang, Jun-Yan Zhu, Jaesik Park, Eli Shechtman, and Xun Huang. Motionstream: Real-time video generation with interactive motion controls.arXiv preprint arXiv:2511.01266, 2025
-
[33]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[34]
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, Tengfei Wang, and Chunchao Guo. Worldplay: Towards long-term geometric consistency for real-time interactive world modeling.arXiv preprint arXiv:2512.14614, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Hunyuan-gamecraft-2: Instruction-following interactive game world model
Junshu Tang, Jiacheng Liu, Jiaqi Li, Longhuang Wu, Haoyu Yang, Penghao Zhao, Siruis Gong, Xiang Yuan, Shuai Shao, and Qinglin Lu. Hunyuan-gamecraft-2: Instruction-following interactive game world model.arXiv preprint arXiv:2511.23429, 2025
-
[36]
HunyuanWorld Team, Zhenwei Wang, Yuhao Liu, Junta Wu, Zixiao Gu, Haoyuan Wang, Xuhui Zuo, Tianyu Huang, Wenhuan Li, Sheng Zhang, et al. Hunyuanworld 1.0: Generating immersive, explorable, and interactive 3d worlds from words or pixels.arXiv preprint arXiv:2507.21809, 2025
-
[37]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Diffusion Models Are Real-Time Game Engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines.arXiv preprint arXiv:2408.14837, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Zun Wang, Han Lin, Jaehong Yoon, Jaemin Cho, Yue Zhang, and Mohit Bansal. Anchor- weave: World-consistent video generation with retrieved local spatial memories.arXiv preprint arXiv:2602.14941, 2026
-
[41]
Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
Tong Wu, Shuai Yang, Ryan Po, Yinghao Xu, Ziwei Liu, Dahua Lin, and Gordon Wetzstein. Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
-
[42]
Chendong Xiang, Jiajun Liu, Jintao Zhang, Xiao Yang, Zhengwei Fang, Shizun Wang, Zijun Wang, Yingtian Zou, Hang Su, and Jun Zhu. Geometry-aware rotary position embedding for consistent video world model.arXiv preprint arXiv:2602.07854, 2026
-
[43]
Pan: A world model for general, interactable, and long-horizon world simulation
Jiannan Xiang, Yi Gu, Zihan Liu, Zeyu Feng, Qiyue Gao, Yiyan Hu, Benhao Huang, Guangyi Liu, Yichi Yang, Kun Zhou, et al. Pan: A world model for general, interactable, and long-horizon world simulation.arXiv preprint arXiv:2511.09057, 2025
-
[44]
Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
Zeqi Xiao, Yushi Lan, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xin- gang Pan. Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
-
[45]
LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Y an: Foundational interactive video generation
Deheng Ye, Fangyun Zhou, Jiacheng Lv, Jianqi Ma, Jun Zhang, Junyan Lv, Junyou Li, Minwen Deng, Mingyu Yang, Qiang Fu, et al. Yan: Foundational interactive video generation.arXiv preprint arXiv:2508.08601, 2025
-
[48]
Deep forcing: Training-free long video generation with deep sink and participative compression
Jung Yi, Wooseok Jang, Paul Hyunbin Cho, Jisu Nam, Heeji Yoon, and Seungryong Kim. Deep forcing: Training-free long video generation with deep sink and participative compression. arXiv preprint arXiv:2512.05081, 2025. 12
-
[49]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 22963–22974, 2025
2025
-
[50]
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval.arXiv preprint arXiv:2506.03141, 2025
-
[51]
Jiwen Yu, Yiran Qin, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Gamefactory: Creating new games with generative interactive videos.arXiv preprint arXiv:2501.08325, 2025
-
[52]
Root mean square layer normalization.Advances in neural information processing systems, 32, 2019
Biao Zhang and Rico Sennrich. Root mean square layer normalization.Advances in neural information processing systems, 32, 2019
2019
-
[53]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[54]
Matrix-game: Interactive world foundation model.arXiv preprint arXiv:2506.18701, 2025
Yifan Zhang, Chunli Peng, Boyang Wang, Puyi Wang, Qingcheng Zhu, Fei Kang, Biao Jiang, Zedong Gao, Eric Li, Yang Liu, et al. Matrix-game: Interactive world foundation model.arXiv preprint arXiv:2506.18701, 2025
-
[55]
Spatia: Video generation with updatable spatial memory.arXiv preprint arXiv:2512.15716, 2025
Jinjing Zhao, Fangyun Wei, Zhening Liu, Hongyang Zhang, Chang Xu, and Yan Lu. Spatia: Video generation with updatable spatial memory.arXiv preprint arXiv:2512.15716, 2025
-
[56]
Min Zhao, Guande He, Yixiao Chen, Hongzhou Zhu, Chongxuan Li, and Jun Zhu. Riflex: A free lunch for length extrapolation in video diffusion transformers.arXiv preprint arXiv:2502.15894, 2025
-
[57]
Min Zhao, Hongzhou Zhu, Yingze Wang, Bokai Yan, Jintao Zhang, Guande He, Ling Yang, Chongxuan Li, and Jun Zhu. Ultravico: Breaking extrapolation limits in video diffusion transformers.arXiv preprint arXiv:2511.20123, 2025. 13 A Implementation Details A.1 Experiment Settings. Training and Evaluation Details.We train our DecMem on WorldMem [ 44] datasets, w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.