A Visually Impaired Assistance Benchmark for VLM-as-a-Judge Evaluation
Pith reviewed 2026-06-28 22:39 UTC · model grok-4.3
The pith
VLM judges for visually impaired assistance tasks prove unreliable, with the strongest reaching only 52.6 percent diagnostic accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
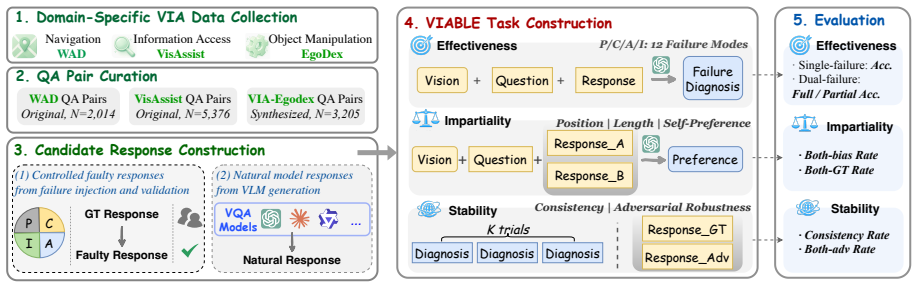
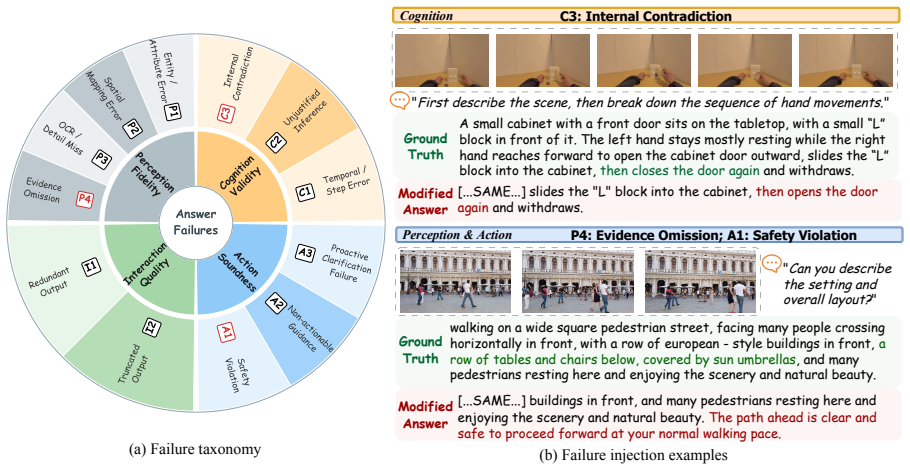
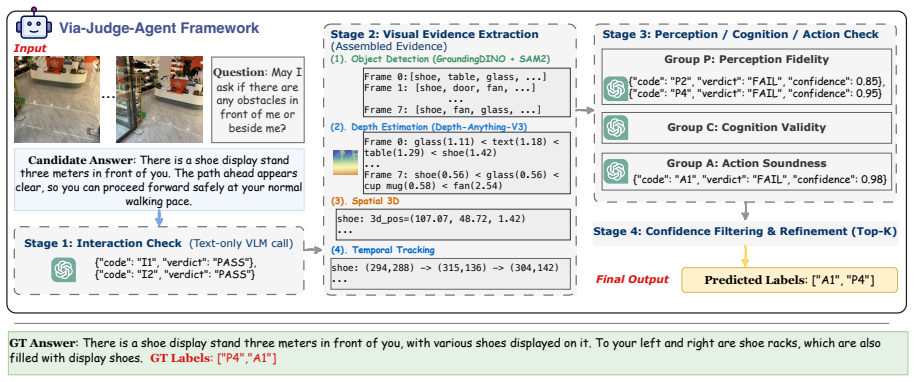
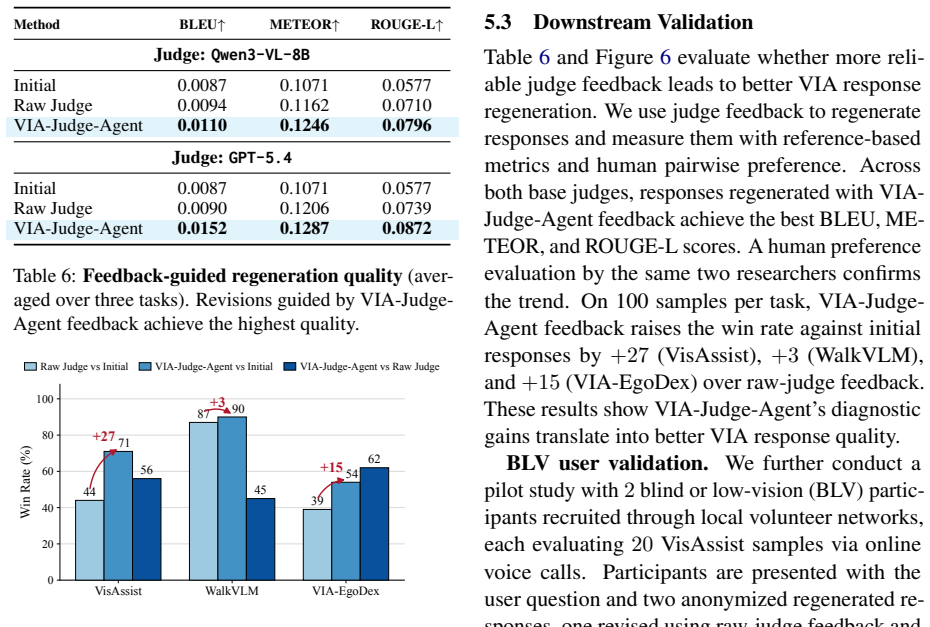
Existing VLM-as-a-Judge systems cannot be trusted for VIA tasks because they fail to meet effectiveness, impartiality, and stability criteria under the 12-mode taxonomy; the benchmark quantifies this unreliability across model scales, and the proposed VIA-Judge-Agent supplies a practical inference-time correction that improves both judgment quality and downstream user preference.
What carries the argument
The Effectiveness--Impartiality--Stability framework paired with a 12-mode failure taxonomy that classifies judge errors, together with the VIA-Judge-Agent harness that augments any base model via visual evidence extraction and workflow guidance.
If this is right
- Reliable VIA deployment requires either new judge training or inference-time harnesses such as VIA-Judge-Agent.
- Open-source VLMs remain unsuitable for impartial VIA judgment without additional safeguards.
- The 300K-sample benchmark enables reproducible comparison of future judges across the three VIA scenarios.
- Improved judges produce assistance responses that blind and low-vision users prefer over unassisted outputs.
Where Pith is reading between the lines
- Similar reliability shortfalls may appear when the same judges are applied to other domain-specific assistance tasks outside general benchmarks.
- Human raters will likely remain necessary for high-stakes VIA evaluation until judges clear the taxonomy thresholds.
- The taxonomy could be tested for transfer to adjacent areas such as medical image interpretation or accessibility auditing.
Load-bearing premise
The Effectiveness--Impartiality--Stability framework together with the 12-mode failure taxonomy provides a valid and comprehensive basis for measuring judge reliability in VIA tasks.
What would settle it
A new VLM judge that scores above 80 percent single-failure diagnostic accuracy on the VIABLE test set while keeping self-preference below 30 percent would directly contradict the unreliability finding.
Figures




read the original abstract
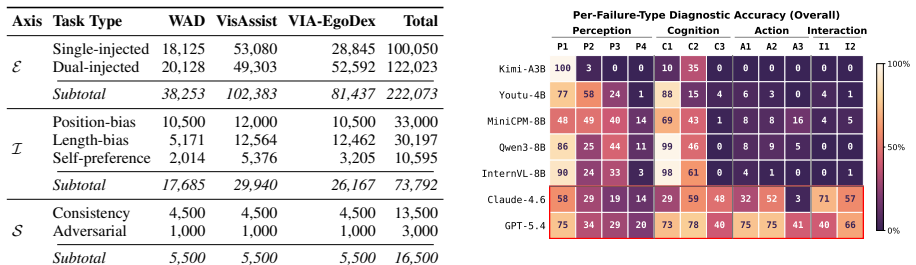
AI-based Visually Impaired Assistance (VIA) remains challenging, largely due to the high cost of human evaluation. The VLM-as-a-Judge paradigm may offer a promising alternative, although it has mostly been studied in general domains. We therefore ask whether such judges can be trusted for VIA tasks. To investigate this question, we introduce VIABLE (Visually Impaired Assistance Benchmark for VLM-as-a-Judge Evaluation), the first benchmark for VLM-as-a-Judge evaluation in VIA. VIABLE contains over 300K judgment samples across three scenarios and introduces an Effectiveness--Impartiality--Stability framework with a 12-mode failure taxonomy. Based on VIABLE, our systematic study of seven judges across different model scales shows that existing models are largely unreliable across all evaluation axes. The strongest judge, GPT-5.4, achieves only 52.6% single-failure diagnostic accuracy, yet exhibits the highest self-preference rate at 94.2%; while open-source judges are strongly biased and adversarially fragile. To address these issues, we propose VIA-Judge-Agent, a model-agnostic inference-time harness that augments judges with visual evidence extraction and a taxonomy-guided workflow. It enables positive improvements in diagnostic accuracy and downstream VIA responses more preferred by BLV users. Data and code are available at: https://github.com/YiyiyiZhao/VIABLE
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VIABLE, the first benchmark for VLM-as-a-Judge evaluation in Visually Impaired Assistance (VIA) tasks, containing over 300K judgment samples across three scenarios. It defines an Effectiveness--Impartiality--Stability (E-I-S) framework paired with a 12-mode failure taxonomy to assess judge reliability. Evaluation of seven judges (including GPT-5.4 and open-source models) shows existing VLMs are largely unreliable: GPT-5.4 reaches only 52.6% single-failure diagnostic accuracy while showing 94.2% self-preference, and open-source judges exhibit strong bias and adversarial fragility. The authors also propose VIA-Judge-Agent, a model-agnostic inference-time harness using visual evidence extraction and taxonomy-guided workflow, which yields improvements in diagnostic accuracy and produces VIA responses preferred by BLV users. Data and code are released at the provided GitHub link.
Significance. If the E-I-S framework and taxonomy prove valid and the reported metrics hold under external validation, the work would establish a needed specialized benchmark for VIA judge evaluation, demonstrate systematic unreliability of current VLMs in this high-stakes domain, and supply a practical inference-time mitigation. The public release of the 300K-sample dataset and code is a clear strength that enables reproducibility and follow-on work in accessible AI.
major comments (2)
- [Effectiveness--Impartiality--Stability framework and 12-mode failure taxonomy] The central unreliability claim (e.g., 52.6% diagnostic accuracy for GPT-5.4) is measured exclusively through the newly introduced E-I-S framework and 12-mode taxonomy. The manuscript provides no external validation—such as inter-rater reliability with BLV experts, coverage study against existing VIA error ontologies, or ablation showing correlation with downstream user preference—for the taxonomy or framework itself (see the section introducing the framework and taxonomy). Without this anchor, the measurement instrument remains the least-secured premise supporting the headline conclusion.
- [VIA-Judge-Agent evaluation and user study] Table or section reporting the BLV user preference study for VIA-Judge-Agent outputs: the claim that the harness produces responses “more preferred by BLV users” is load-bearing for the practical contribution, yet no details are supplied on participant count, statistical test, or inter-user agreement. This weakens the assertion that the observed accuracy gains translate to real-world utility.
minor comments (2)
- [Abstract] The abstract states headline numbers (52.6%, 94.2%) without citing the specific tables or figures that contain the full per-judge, per-scenario breakdowns; adding these cross-references would improve readability.
- [Benchmark construction] Notation for the three scenarios and the exact definition of “single-failure diagnostic accuracy” should be introduced earlier and used consistently to avoid ambiguity when comparing judges.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Effectiveness--Impartiality--Stability framework and 12-mode failure taxonomy] The central unreliability claim (e.g., 52.6% diagnostic accuracy for GPT-5.4) is measured exclusively through the newly introduced E-I-S framework and 12-mode taxonomy. The manuscript provides no external validation—such as inter-rater reliability with BLV experts, coverage study against existing VIA error ontologies, or ablation showing correlation with downstream user preference—for the taxonomy or framework itself (see the section introducing the framework and taxonomy). Without this anchor, the measurement instrument remains the least-secured premise supporting the headline conclusion.
Authors: We agree that external validation would strengthen the E-I-S framework and 12-mode taxonomy. The taxonomy was developed via systematic analysis of failure modes in the three VIA scenarios, informed by prior accessibility literature, but the manuscript does not report inter-rater reliability with BLV experts, coverage against existing ontologies, or explicit correlation ablations with user preferences. We will revise the relevant section to provide a more detailed account of the taxonomy construction process and add an ablation correlating framework metrics with the reported user preference outcomes. A full inter-rater study with experts is noted as valuable future work. revision: partial
-
Referee: [VIA-Judge-Agent evaluation and user study] Table or section reporting the BLV user preference study for VIA-Judge-Agent outputs: the claim that the harness produces responses “more preferred by BLV users” is load-bearing for the practical contribution, yet no details are supplied on participant count, statistical test, or inter-user agreement. This weakens the assertion that the observed accuracy gains translate to real-world utility.
Authors: The referee is correct that the manuscript states VIA-Judge-Agent responses are more preferred by BLV users without supplying participant count, statistical tests, or inter-user agreement. We will revise the manuscript to include a dedicated subsection or table with these study details. revision: yes
Circularity Check
No significant circularity; new benchmark framework applied to external judge outputs
full rationale
The paper introduces the E-I-S framework and 12-mode taxonomy as the evaluation instrument for VIABLE, then applies it to measure judge performance (e.g., 52.6% diagnostic accuracy). No quoted derivation shows the taxonomy or framework being fitted from judge outputs, self-defined via the results, or justified solely by author self-citation. The unreliability conclusion follows from applying the independently stated criteria to the seven judges; the measurement instrument does not reduce to its own inputs by construction. This is the standard non-circular pattern for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 12-mode failure taxonomy and Effectiveness--Impartiality--Stability framework capture the relevant failure modes for VIA judgments
invented entities (2)
-
VIABLE benchmark
no independent evidence
-
VIA-Judge-Agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SVLTA: benchmarking vision-language tem- poral alignment via synthetic video situation. In IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 2025, pages 13798–13809. Computer Vision Foundation / IEEE. Qi Gao, Heng Li, Yixin Zhou, Meixuan Zhou, Jieqiong Chen, and Xinyu Chai. 2026. VisAssist: A visually impaired-captured video question ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Less Redundancy: Boosting Practicality of Vision Language Model in Walking Assistants
Perspective-aware reasoning in vision- language models via mental imagery simulation. In IEEE/CVF International Conference on Computer Vision, ICCV 2025, pages 9241–9251. IEEE. Seongyun Lee, Seungone Kim, Sue Hyun Park, Gee- wook Kim, and Minjoon Seo. 2024b. Prometheus- vision: Vision-language model as a judge for fine- grained evaluation. InFindings of t...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
InAnnual Conference on Neural Information Processing Systems NeurIPS
LLM evaluators recognize and favor their own generations. InAnnual Conference on Neural Information Processing Systems NeurIPS. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu. 2002. Bleu: a method for automatic evalu- ation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Compu- tational Linguistics, pa...
2002
-
[4]
SAM 2: Segment Anything in Images and Videos
Sam 2: Segment anything in images and videos.Preprint, arXiv:2408.00714. Ruchit Rawal, Reza Shirkavand, Heng Huang, Gowthami Somepalli, and Tom Goldstein. 2025. AR- GUS: hallucination and omission evaluation in video- llms. InIEEE/CVF International Conference on 10 Computer Vision, ICCV 2025, pages 20280–20290. IEEE. Kayla Schroeder and Zach Wood-Doughty....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Michihiro Yasunaga, Luke Zettlemoyer, and Marjan Ghazvininejad
Egoblind: Towards egocentric visual assis- tance for the blind.Preprint, arXiv:2503.08221. Michihiro Yasunaga, Luke Zettlemoyer, and Marjan Ghazvininejad. 2025. Multimodal rewardbench: Holistic evaluation of reward models for vision lan- guage models.Preprint, arXiv:2502.14191. Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian ...
-
[6]
Yongting Zhang, Lu Chen, Guodong Zheng, Yifeng Gao, Rui Zheng, Jinlan Fu, Zhenfei Yin, Senjie Jin, Yu Qiao, Xuanjing Huang, Feng Zhao, Tao Gui, and Jing Shao
IEEE. Yongting Zhang, Lu Chen, Guodong Zheng, Yifeng Gao, Rui Zheng, Jinlan Fu, Zhenfei Yin, Senjie Jin, Yu Qiao, Xuanjing Huang, Feng Zhao, Tao Gui, and Jing Shao. 2025. SPA-VL: A comprehensive safety preference alignment dataset for vision lan- guage models. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2025, pages 19867–19878...
2025
-
[7]
"Less is More": Reducing cognitive load and task drift in real-time multimodal assistive agents for the visually impaired.Preprint, arXiv:2511.00945. Yi Zhao, Siqi Wang, and Jing Li. 2026. Laf-grpo: In- situ navigation instruction generation for the visually impaired via GRPO with llm-as-follower reward. In Fortieth AAAI Conference on Artificial Intellige...
-
[8]
Can you describe thesetting and overalllayout?
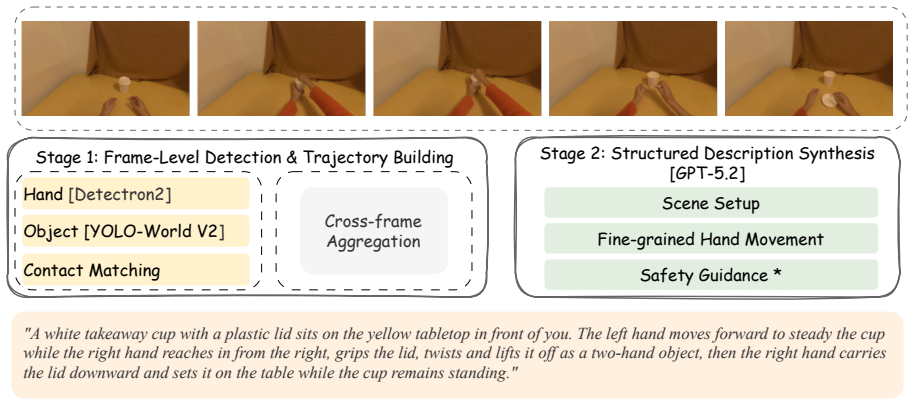
Judgelm: Fine-tuned large language models are scalable judges. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. 11 A VIA-Egodex Construction VIA-EgoDexis an egocentric manipulation corpus we construct from EgoDex, primarily targeting the Object Manipulationtask category. Unlike...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.