Neuro-symbolic Syntactic Parsing: Shaping a Neural Network with the CYK Algorithm
Pith reviewed 2026-06-28 22:17 UTC · model grok-4.3
The pith
A recurrent neural network can directly encode the CYK algorithm as trainable matrix-vector multiplications for syntactic parsing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
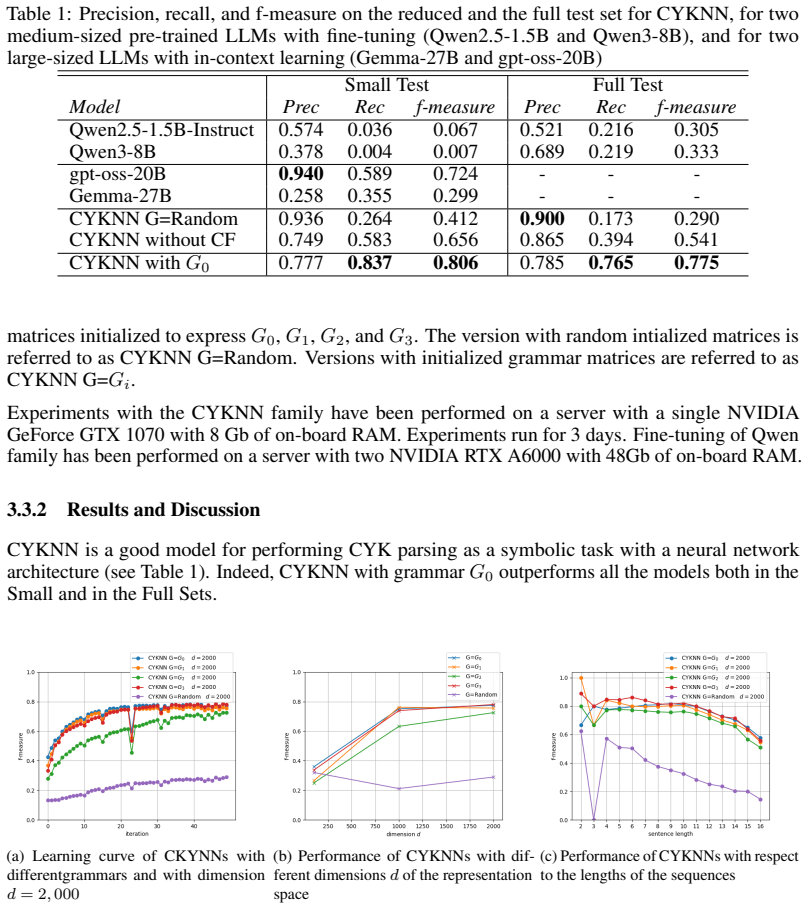
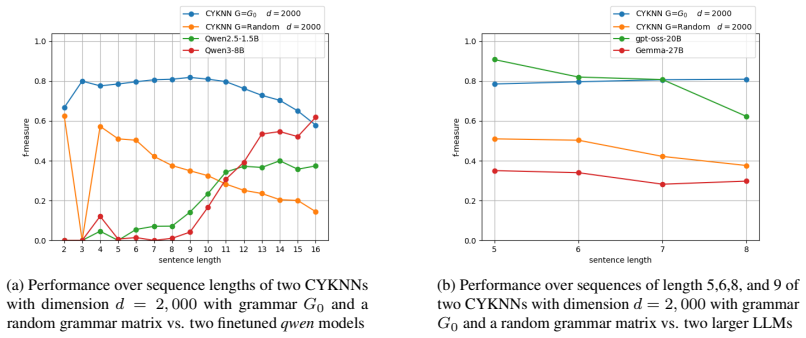
CYKNN is a simple recurrent neural network that encodes the full CYK parsing procedure for context-free grammars in Chomsky normal form inside trainable matrix-vector multiplications, enabling direct algorithmic injection rather than statistical approximation, and on a simple grammar with four variations this yields better parsing performance than LLMs exceeding 20B parameters under in-context learning or smaller Qwen models after LoRA fine-tuning.
What carries the argument
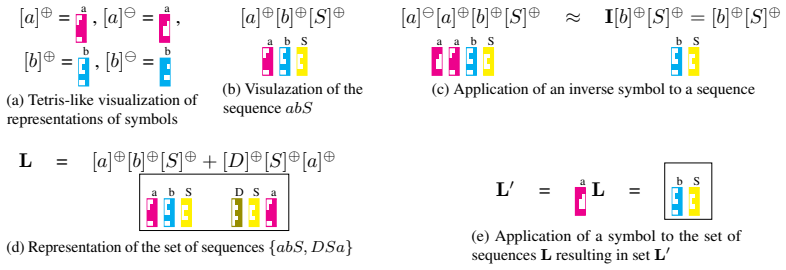
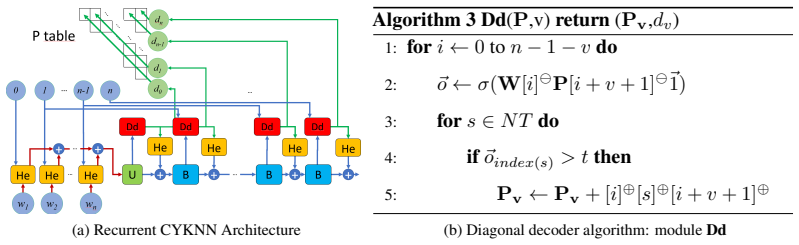
CYKNN, a recurrent neural network whose layers perform the CYK table-filling steps as matrix-vector multiplications that remain trainable.
If this is right
- Symbolic algorithms such as CYK can be executed exactly inside neural networks without external symbolic modules.
- Training can focus on parameters that control how the fixed algorithm is applied rather than rediscovering the algorithm from examples.
- Neuro-symbolic parsing can achieve strong results with far fewer parameters than pure language-model approaches on structured tasks.
- The same matrix-vector encoding technique may apply to other dynamic-programming algorithms used in natural language processing.
Where Pith is reading between the lines
- If the encoding scales, it could allow smaller networks to handle complex syntactic structures that currently require massive pretraining.
- The method supplies an explicit inductive bias that might improve generalization on out-of-distribution sentences compared with purely learned parsers.
- Extending the same principle to other classic algorithms could create hybrid systems where neural components optimize only the parts that remain uncertain.
Load-bearing premise
That performance gains measured on one very simple grammar with four variations will demonstrate the value of the CYK encoding itself rather than being tied to the narrow test setting.
What would settle it
Train CYKNN and the compared LLMs on a larger, more realistic context-free grammar or treebank and measure whether the performance gap persists or reverses when the grammar complexity increases.
Figures

read the original abstract
In this paper, we show the possibility of a direct injection of algorithms into neural network architecture. We focus on a complex algorithm, that is, Cocke-Youger-Kasami (CYK) for parsing context-free grammars in Chomsky Normal Form and we propose CYKNN, a simple recurrent neural network architecture for encoding the CYK algorithm in trainable matrix-vector multiplications.We experimented with a very simple grammar with 4 variations showing that our approach outperforms existing LLMs with more than 20B parameters with an in-context learning setting and smaller LLMs of the Qwen family fine-tuned with LoRA. Our attempt paves the way to a different approach to neuro-symbolic methodologies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CYKNN, a recurrent neural network architecture that directly encodes the Cocke-Younger-Kasami (CYK) algorithm for parsing context-free grammars in Chomsky Normal Form via trainable matrix-vector multiplications. It reports that this approach outperforms LLMs with >20B parameters (in-context learning) and LoRA-fine-tuned Qwen models on experiments with a very simple grammar having four variations.
Significance. If validated, the direct injection of a dynamic programming algorithm like CYK into a neural architecture could advance neuro-symbolic methods by improving structured reasoning and interpretability. The current evidence, however, is confined to a minimal grammar, limiting immediate broader impact.
major comments (2)
- [Abstract] Abstract (final paragraph): the central claim of outperformance rests entirely on results from one very simple grammar with four variations; no evidence is provided that the architecture correctly implements the full CYK recurrence on larger CFGs or that gains can be attributed to the algorithmic encoding rather than the narrow test regime.
- [Abstract] Abstract: the assertion of superiority over >20B-parameter LLMs and LoRA-tuned models supplies no quantitative metrics, error bars, training details, or description of how individual CYK steps (e.g., the DP table construction or non-terminal handling) are realized in the matrix-vector multiplications, preventing evaluation of the claim.
minor comments (1)
- [Abstract] The abstract would benefit from explicit notation for the trainable matrices and how they map to the CYK recurrence.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract overstates the scope of the results and lacks sufficient detail. We will revise the abstract accordingly while preserving the core claim that the architecture directly encodes CYK steps via matrix-vector operations, as demonstrated on the reported grammar. Details of the implementation appear in the methods and experiments sections of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the central claim of outperformance rests entirely on results from one very simple grammar with four variations; no evidence is provided that the architecture correctly implements the full CYK recurrence on larger CFGs or that gains can be attributed to the algorithmic encoding rather than the narrow test regime.
Authors: We agree that all reported experiments use one very simple grammar with four variations and that no results are shown for larger CFGs. The abstract will be revised to state explicitly that outperformance is demonstrated only on this narrow regime and that generalization to larger CFGs remains untested. The architecture is constructed so that each matrix-vector multiplication corresponds to a specific CYK recurrence step (span combination and non-terminal lookup), but we acknowledge that the current evidence does not prove the implementation is correct beyond the tested cases. revision: partial
-
Referee: [Abstract] Abstract: the assertion of superiority over >20B-parameter LLMs and LoRA-tuned models supplies no quantitative metrics, error bars, training details, or description of how individual CYK steps (e.g., the DP table construction or non-terminal handling) are realized in the matrix-vector multiplications, preventing evaluation of the claim.
Authors: The abstract is intentionally brief and therefore omits the quantitative results, error bars, and training hyperparameters, which are reported with standard deviations in the experimental section. We will expand the abstract to include the key accuracy figures and a one-sentence description of the encoding. The DP table is realized by recurrent matrix multiplications whose dimensions match the number of non-terminals; each step computes the max over possible splits exactly as in the CYK recurrence, with grammar rules encoded in the weight matrices. These mappings are derived in Section 3. revision: yes
- We have no experiments on larger CFGs and therefore cannot supply evidence that the architecture correctly implements the full CYK recurrence outside the simple grammar tested.
Circularity Check
No circularity: architecture proposal and toy-grammar experiments contain no self-definitional reductions or load-bearing self-citations
full rationale
The paper proposes CYKNN as a recurrent architecture that encodes the CYK algorithm via trainable matrix-vector multiplications and reports outperformance on one very simple grammar with four variations. No equations, fitted parameters, or derivation steps are supplied in the provided text that would allow a prediction to reduce to an input by construction. No self-citations are invoked to justify uniqueness theorems, ansatzes, or central premises. The central claim therefore rests on empirical comparison rather than on any definitional or citation-based loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Progress measures for grokking via mechanistic interpretability
URLhttps://api.semanticscholar.org/CorpusID:275789950. Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. InProceedings of ICLR, 2023. doi: 10.48550/arXiv. 2301.05217. URLhttp://arxiv.org/abs/2301.05217. arXiv:2301.05217. Zhiquan Tan and Weiran Huang. Understanding Gr...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
-
[2]
gpt-oss-120b & gpt-oss-20b Model Card
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/ 2025.findings-acl.785. URLhttps://aclanthology.org/2025.findings-acl.785/. Jerry A. Fodor and Zenon W. Pylyshyn. Connectionism and cognitive architecture: A critical analysis.Cognition, 28(1):3 – 71, 1988. ISSN 0010-0277. doi: https://doi.org/10.1016/ 0010-0277(88)90031-5...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/ 2025
-
[3]
URLhttps://arxiv.org/abs/2503.19786. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3676151.3719377 2025
-
[4]
ISBN 0262531410. Liang Huang and David Chiang. Better k-best parsing. InProceedings of the Ninth International Work- shop on Parsing Technology, pages 53–64, Vancouver, British Columbia, October 2005. Associa- tion for Computational Linguistics. URLhttps://www.aclweb.org/anthology/W05-1506. John E. Hopcroft, Rajeev Motwani, and Jeffrey D. Ullman.Introduct...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.