Consolidating Rewarded Perturbations for LLM Post-Training
Pith reviewed 2026-06-28 22:35 UTC · model grok-4.3
The pith
Rewarded perturbations around a language model exhibit low-rank structure that can be consolidated into a single improved model without gradients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
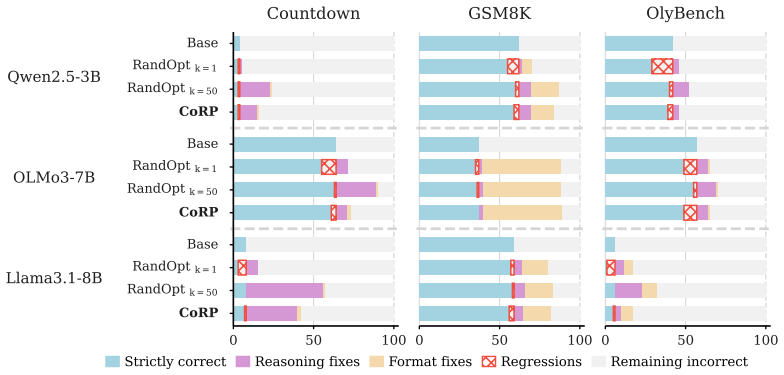
We turn this geometry into CoRP (Consolidating Rewarded Perturbations), a gradient-free operator that combines reward-weighted aggregation, compatibility-aware reweighting, and a held-out validation gate, with no gradient flowing through the language model. Across five language models from 0.5B to 8B and five tasks covering math, code, and creative writing, CoRP improves the base model by 8.1 points on average. Using one tenth of RandOpt's perturbation budget, CoRP exceeds single-inference RandOpt by 6.5 points and recovers more than half of the gain of the 50-pass majority-vote ensemble, at one forward pass per test example.
What carries the argument
The reproducible low-rank structure in the rewarded perturbation population, turned into a gradient-free consolidation operator via reward-weighted aggregation, compatibility reweighting, and validation gating.
If this is right
- CoRP improves the base model by 8.1 points on average across the tested models and tasks.
- It exceeds single-inference RandOpt by 6.5 points while using only one tenth the perturbation budget.
- It recovers more than half the performance gain of a 50-pass majority-vote ensemble at a single forward pass.
- The method requires no gradient computation through the language model itself.
- The consolidation works for models from 0.5B to 8B parameters on math, code, and creative writing.
Where Pith is reading between the lines
- The low-rank property may allow similar consolidation for other sampling-based post-training techniques that currently rely on inference-time ensembles.
- Reducing the number of forward passes could make perturbation methods viable for latency-sensitive deployment scenarios.
- Testing whether the same structure appears under different perturbation distributions or on larger models would be a direct next measurement.
Load-bearing premise
The differences among rewarded perturbations always display a low-rank structure that a held-out validation gate can reliably turn into a single improved model.
What would settle it
A new model-task pair in which the low-rank structure is absent or the consolidated model shows no improvement over the base would falsify the claim that the operator reliably recovers ensemble gains at one pass.
Figures


read the original abstract
Post-training of language models is commonly framed as a sample-score-update loop implemented by gradient descent. A recent line of work, exemplified by RandOpt, relocates this loop to weight space, sampling Gaussian perturbations around a pretrained model and ensembling the top-K rewarded specialists at inference. While competitive with PPO and GRPO under matched training compute, this prediction-level ensemble incurs K forward passes per test example and does not extend cleanly to free-form generation. We ask whether the rewarded population can instead be folded into a single deployable model, replacing the inference-time ensemble with one consolidated update. A split-half analysis over 25 model-task pairs reveals reproducible low-rank structure in every case. We turn this geometry into CoRP (Consolidating Rewarded Perturbations), a gradient-free operator that combines reward-weighted aggregation, compatibility-aware reweighting, and a held-out validation gate, with no gradient flowing through the language model. Across five language models from 0.5B to 8B and five tasks covering math, code, and creative writing, CoRP improves the base model by 8.1 points on average. Using one tenth of RandOpt's perturbation budget, CoRP exceeds single-inference RandOpt by 6.5 points and recovers more than half of the gain of the 50-pass majority-vote ensemble, at one forward pass per test example.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CoRP, a gradient-free operator that consolidates rewarded perturbations sampled around a base LLM into a single deployable model. It identifies reproducible low-rank structure via split-half analysis across 25 model-task pairs and combines reward-weighted aggregation, compatibility-aware reweighting, and a held-out validation gate. Across five models (0.5B–8B) and five tasks (math, code, creative writing), CoRP yields an 8.1-point average gain over the base model, exceeds single-inference RandOpt by 6.5 points while using one-tenth the perturbation budget, and recovers more than half the gain of a 50-pass majority-vote ensemble at one forward pass per example.
Significance. If the low-rank consolidation operator proves robust, the work would meaningfully advance weight-space post-training by converting inference-time ensembles into efficient single-model updates without gradients. The held-out validation gate supplies an external check that reduces circularity risk relative to pure fitting, and the reported efficiency gains (budget reduction and single-pass inference) address a practical limitation of prior perturbation methods such as RandOpt.
major comments (3)
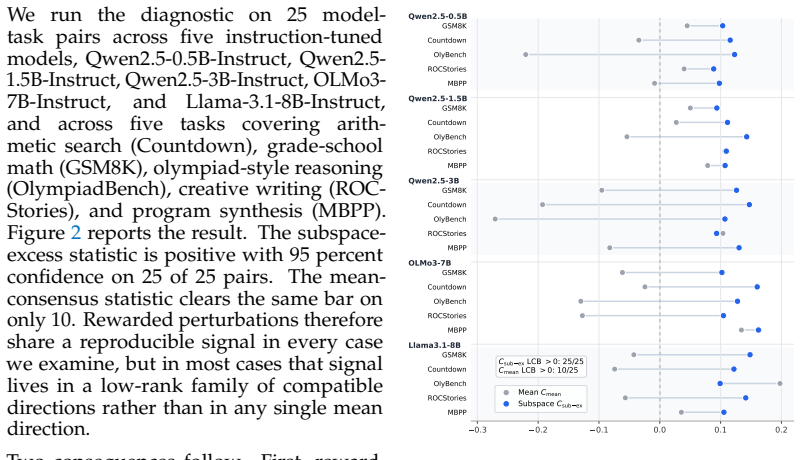
- [§3] §3 (Split-half analysis and low-rank geometry): The central claim that rewarded perturbations exhibit reproducible low-rank structure across all 25 model-task pairs, which is then turned into a generalizable consolidation operator, rests on split-half analysis of the same perturbation set. No quantitative evidence is provided that the identified subspace remains stable under independent random splits or when the operator is applied to a fresh draw of perturbations; correlated sampling noise or reward correlations between halves could artifactually produce the reported low-rank geometry, directly undermining the 8.1-point gain and half-ensemble recovery claims.
- [§4.1–4.2] §4.1–4.2 (Performance tables and ablation): The 8.1-point average improvement, 6.5-point margin over single-inference RandOpt, and recovery of >50% of the 50-pass ensemble gain are load-bearing results, yet the manuscript provides no per-task standard deviations, statistical significance tests, or ablation removing the validation gate. Without these, it is impossible to determine whether the gains are reproducible or driven by post-hoc choices in the operator.
- [§3.3] §3.3 (Operator definition): The compatibility-aware reweighting step is described at a high level but lacks an explicit equation or pseudocode showing how compatibility is computed and how it interacts with the reward-weighted aggregation; this definition is required to verify that the operator is indeed gradient-free and parameter-free as claimed.
minor comments (2)
- [Abstract / §2] The abstract and §2 should explicitly list the five models and five tasks rather than referring readers to an appendix; this improves reproducibility.
- [Figures] Figure captions for any perturbation visualizations should state the exact number of perturbations used and the split ratio employed in the half-analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which identify areas where the manuscript can be strengthened. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§3] §3 (Split-half analysis and low-rank geometry): The central claim that rewarded perturbations exhibit reproducible low-rank structure across all 25 model-task pairs, which is then turned into a generalizable consolidation operator, rests on split-half analysis of the same perturbation set. No quantitative evidence is provided that the identified subspace remains stable under independent random splits or when the operator is applied to a fresh draw of perturbations; correlated sampling noise or reward correlations between halves could artifactually produce the reported low-rank geometry, directly undermining the 8.1-point gain and half-ensemble recovery claims.
Authors: We acknowledge that the split-half analysis was performed within the same perturbation sample. While this approach is commonly used to detect internal structure, the referee correctly notes the absence of evidence for stability across independent draws. In the revision we will add experiments that draw fresh, independent perturbation sets for each of the 25 model-task pairs, compute the principal subspaces, and report quantitative stability metrics (e.g., average principal-angle distance and cosine similarity of the top-k singular vectors). These results will be presented alongside the original split-half findings. revision: yes
-
Referee: [§4.1–4.2] §4.1–4.2 (Performance tables and ablation): The 8.1-point average improvement, 6.5-point margin over single-inference RandOpt, and recovery of >50% of the 50-pass ensemble gain are load-bearing results, yet the manuscript provides no per-task standard deviations, statistical significance tests, or ablation removing the validation gate. Without these, it is impossible to determine whether the gains are reproducible or driven by post-hoc choices in the operator.
Authors: We agree that the current tables lack per-task standard deviations and statistical tests, and that an ablation isolating the validation gate is missing. The revised manuscript will expand Tables 1–3 to include per-task means, standard deviations across three independent runs, and paired t-test p-values against the base model and RandOpt. We will also add a dedicated ablation subsection that removes the held-out validation gate while keeping all other components fixed, reporting the resulting performance drop. revision: yes
-
Referee: [§3.3] §3.3 (Operator definition): The compatibility-aware reweighting step is described at a high level but lacks an explicit equation or pseudocode showing how compatibility is computed and how it interacts with the reward-weighted aggregation; this definition is required to verify that the operator is indeed gradient-free and parameter-free as claimed.
Authors: We will expand §3.3 with an explicit equation for the compatibility score (defined as the cosine similarity between the perturbation vectors after reward weighting) and the full reweighting formula that combines it with the reward-weighted aggregation. Pseudocode for the complete operator will also be added, making clear that no gradients are computed and that the only hyperparameters are the rank and the validation threshold already stated in the text. revision: yes
Circularity Check
No significant circularity; derivation is empirical and self-contained
full rationale
The paper's central chain proceeds from sampling perturbations, performing split-half analysis to observe low-rank structure across 25 model-task pairs, and constructing a gradient-free CoRP operator (reward-weighted aggregation + compatibility reweighting + held-out validation gate) from that geometry. This is an empirical discovery step followed by operator design and performance measurement on the tasks, with the validation gate providing an external check. No equations are present, no parameters are fitted to a subset and then renamed as a prediction of a closely related quantity, and no self-citations or uniqueness theorems are invoked to force the result by construction. The reported gains (8.1 points average, recovery of half the ensemble benefit) are therefore not equivalent to the inputs by definition but remain open to external falsification on new perturbation draws or models.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rewarded perturbations exhibit reproducible low-rank structure across 25 model-task pairs
Reference graph
Works this paper leans on
-
[1]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
URL https://proceedings.neurips.cc/paper_files/ paper/2022/file/b1efde53be364a73914f58805a001731-Paper-Conference.pdf. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms,
2022
-
[2]
Proximal Policy Optimization Algorithms
URLhttps://arxiv.org/abs/1707.06347. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
URLhttps://arxiv.org/abs/2412.16720. Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Fengxiang Tang, Flood Sung, Guangda Wei, Guokun Lai, Haiqing Guo, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haotian Yao, H...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
URL https://arxiv.org/abs/2501.12599. Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learn- ing from self-generated mistakes. InThe Twelfth International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URLhttps://arxiv.org/abs/2505.09388. Core Team, Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, Gang Xie, Hailin Zhang, Hanglong Lv, Hanyu Li, Heyu Chen, Hongshen Xu, Houbin Zhang, Huaqiu Liu, Jiangshan Duo, Jianyu Wei, Jiebao Xiao, Jinhao Dong, Jun Shi, Junhao Hu, Kainan Bao, Kang Zho...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
MiMo-V2-Flash Technical Report
URL https://arxiv.org/abs/2601.02780. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Spurious Rewards: Rethinking Training Signals in RLVR
URLhttps://arxiv.org/abs/2506.10947. Jake Ward, Chuqiao Lin, Constantin Venhoff, and Neel Nanda. Reasoning-finetuning repurposes latent representations in base models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin
URL https://arxiv.org/abs/ 2507.12638. Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. InSecond Conference on Language Modeling,
-
[9]
URLhttps://arxiv.org/abs/2603.12228. Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo- Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In Kamalika Chaud...
-
[10]
Some experimental results in the correlation of mental abilities 1.British Journal of Psychology, 1904-1920, 3(3):296–322,
William Brown. Some experimental results in the correlation of mental abilities 1.British Journal of Psychology, 1904-1920, 3(3):296–322,
1904
-
[11]
Association for Computing Machinery. ISBN 9781595937933. doi: 10.1145/1273496.1273590. URL https://doi.org/ 10.1145/1273496.1273590. Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning,
-
[12]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
URL https: //arxiv.org/abs/1910.00177. Reuven Rubinstein. The cross-entropy method for combinatorial and continuous optimiza- tion.Methodology and computing in applied probability, 1(2):127–190,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[13]
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
URL https://arxiv.org/abs/ 1703.03864. Nikolaus Hansen. The cma evolution strategy: A tutorial,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
The CMA Evolution Strategy: A Tutorial
URL https://arxiv.org/ abs/1604.00772. Niru Maheswaranathan, Luke Metz, George Tucker, Dami Choi, and Jascha Sohl-Dickstein. Guided evolutionary strategies: augmenting random search with surrogate gradients. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URL https://proceedings.neurips.cc/paper_files/paper/ 2019/file/88bade49e98db8790df275fcebb37a13-Paper.pdf. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming...
2019
-
[16]
URLhttps://arxiv.org/abs/2412.15115. Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saum...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
URLhttps://arxiv.org/abs/2512.13961. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sra- vankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aure...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
URLhttps://arxiv.org/abs/2407.21783. Kanishk Gandhi, Denise H J Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, and Noah Goodman. Stream of search (sos): Learning to search in language. In First Conference on Language Modeling,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Training Verifiers to Solve Math Word Problems
URL https://arxiv.org/abs/2110.14168. Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. OlympiadBench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. In Lun-Wei Ku, Andre Martins, and...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
doi: 10.18653/v1/2024.acl-long.211
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.211. URL https://aclanthology.org/2024.acl-long.211/. Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Pushmeet Kohli, and James Allen. A corpus and cloze evaluation for deeper understanding of commonsense stories. In Kevin Knight, An...
-
[21]
Association for Computational Linguistics. doi: 10.18653/v1/N16-1098. URLhttps://aclanthology.org/N16-1098/. Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models,
-
[22]
Program Synthesis with Large Language Models
URL https://arxiv.org/abs/2108.07732. Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors,Proceedings of the 59th Annual Meeting of the Associ- ation for Computational Linguistics and the 11th Internationa...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
doi: 10.18653/v1/2021.acl-long.568
Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.568. URL https://aclanthology.org/2021.acl-long.568/. Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations,
- [24]
-
[25]
URLhttps://arxiv.org/abs/2602.04118. 17 Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32,
-
[26]
HybridFlow: A Flexible and Efficient RLHF Framework
URL https://github.com/modelscope/evalscope. Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
The iteration step helps most on Qwen2.5-3B/ROCStories, where Full CoRP improves over the no-iteration variant by 2.40 points
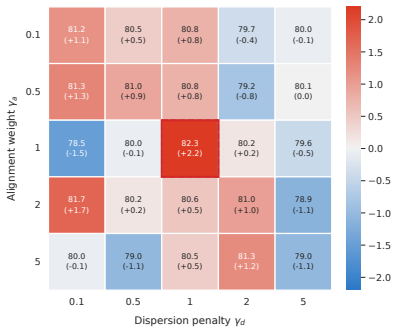
GSM8K ROCStories Method Acc.∆Acc.∆ Qwen2.5-3B-Instruct Base 79.81 – 54.73 – reward only 80.97+1.16 54.70−0.03 reward+alignment 80.89+1.08 53.97−0.76 reward+dispersion 79.76−0.05 54.66−0.07 no gate 80.67+0.86 54.59−0.14 no iteration82.31+2.5056.71+1.98 Full CoRP 82.31+2.50 59.11+4.38 OLMo3-7B-Instruct Base 82.92 – 64.04 – reward only 84.16+1.24 63.31−0.73 ...
2023
-
[28]
The accuracy surface drops at the corners where one weight saturates the exponent in Eq
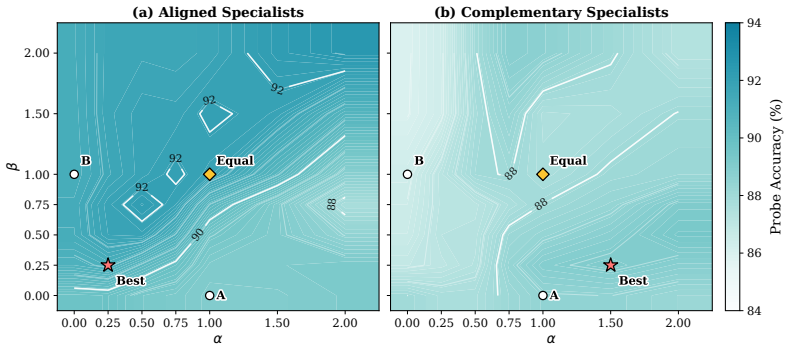
is the strongest configuration on the sweep, and the central region [0.5, 2]2 remains mostly positive, with small negative outliers at a few asymmetric settings. The accuracy surface drops at the corners where one weight saturates the exponent in Eq. 9 and the other becomes negligible, which is the regime in which compatibility scoring effectively reduces...
2019
-
[29]
This design separates proposal construction from validation
The test set plays no role in selectingq, β, or α, nor in deciding whether to accept an update. This design separates proposal construction from validation. If no candidate achieves a positive construction score and a positive lower-confidence-bound improvement on fold B (defined in §C.5), CoRP abstains and returns the base model. If a candidate passes th...
2026
-
[30]
C.6 Prompts Following Gan and Isola [2026], we set up the prompts for different datasets in our experiments following EvalScope [Team, 2024] and Verl [Sheng et al., 2024]
This bound is computed separately for each candidate and fold, and is distinct from the bootstrap procedure used for the split-half diagnostics in §3. C.6 Prompts Following Gan and Isola [2026], we set up the prompts for different datasets in our experiments following EvalScope [Team, 2024] and Verl [Sheng et al., 2024]. Countdown Your Task Using the numb...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.