TunerDiT: Training-free Progressive Steering of Diffusion Transformer for Multi-Event Video Generation
Pith reviewed 2026-06-28 23:10 UTC · model grok-4.3
The pith
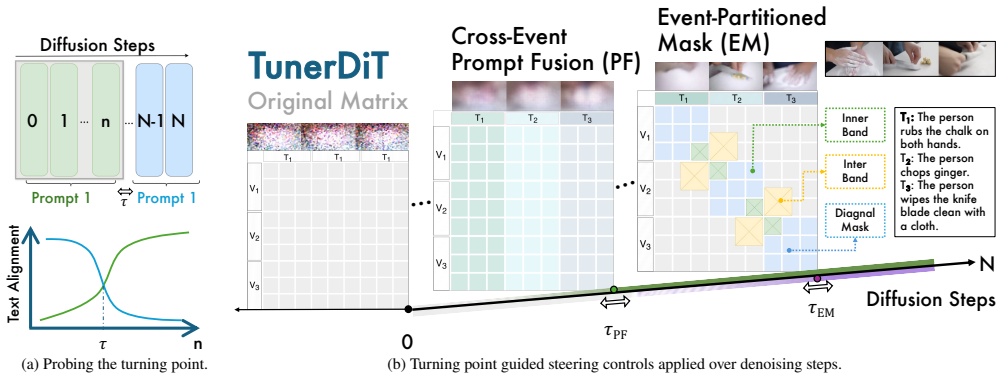
Diffusion transformers contain turning points in denoising where text shifts from global layout to fine details, enabling a training-free steering method for multi-event videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By identifying turning points in the DiT denoising trajectory where text conditioning shifts from global layout to fine-grained details, TunerDiT applies event-partitioned masking and cross-event prompt fusion to achieve state-of-the-art results across eight metrics on multi-event text-to-video generation, offering a tunable consistency-separation trade-off and scaling improvement in text alignment as event count rises.
What carries the argument
Event-partitioned masking and cross-event prompt fusion, applied progressively at the probed turning points in the DiT denoising trajectory.
If this is right
- State-of-the-art performance across eight metrics compared with other training-free multi-event methods.
- A tunable trade-off between video consistency and event separation.
- Text-alignment gains that increase with the number of events in the prompt.
Where Pith is reading between the lines
- The turning-point observation could be tested for consistency across different diffusion transformer architectures beyond the specific models examined.
- The progressive steering pattern might support generation of videos with substantially longer event sequences than those in the current benchmark.
- The self-curated multi-event prompt suite could be expanded to include more varied event types or temporal relations to stress-test the method further.
Load-bearing premise
The denoising trajectory contains consistent turning points at which text conditioning predictably shifts from controlling global layout to fine details in a steerable way.
What would settle it
Running the two steering handles at the identified turning points on the Meve benchmark and measuring whether text-alignment scores fail to exceed those of other training-free baselines, especially as event count increases.
Figures











read the original abstract
Text-to-video (T2V) generation faces challenging questions when generating videos with long horizons containing multiple events. Inspired by the intrinsics of the diffusion process, we probe video diffusion transformers (DiTs) and uncover intrinsic turning points in the DiT denoising trajectory where conditioning text affects generation from global layout to fine-grained details. Building on this finding, we present TunerDiT, a simple yet effective progressive steering method that requires no additional training for multi-event generation. TunerDiT comprises two steering handles: (1) Event-Partitioned Masking that enforces event boundaries while allowing cross-event transition bands; (2) Cross-Event Prompt Fusion that injects neighboring event semantics for late-stage refinement. We contribute a self-curated prompt suite for benchmarking multi-event generation, i.e., Meve. TunerDiT achieves state-of-the-art performance across 8 metrics and offers a tunable trade-off between video consistency and event separation, compared with other training-free methods. The improvement in text alignment increases with the event count, indicating a scaling possibility with increasing event count.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that probing DiT denoising trajectories reveals intrinsic turning points where text conditioning shifts from controlling global layout to fine-grained details. Building on this, TunerDiT is a training-free progressive steering method with two handles—Event-Partitioned Masking (enforcing boundaries with transition bands) and Cross-Event Prompt Fusion (injecting neighboring semantics for refinement)—applied at those points. A self-curated Meve benchmark is introduced, and TunerDiT is reported to achieve SOTA results on 8 metrics versus other training-free methods, with a tunable consistency/separation trade-off and scaling improvement in text alignment as event count grows.
Significance. If the results hold, the work provides a simple, training-free approach to the challenging multi-event T2V setting and contributes the Meve benchmark. The training-free nature, explicit tunable trade-off, and reported scaling with event count are concrete strengths. The probing-based insight into DiT trajectories, if substantiated, could inform future steering methods.
major comments (1)
- [Probing experiment and §4 (method)] The central justification for the method (abstract and method description) is that the two steering handles must be applied at the probed turning points. No ablation is reported that applies the handles at alternative schedules or timesteps and compares resulting metrics on Meve; without this, it is unclear whether the claimed SOTA performance and scaling depend on the specific turning-point timing or would arise from the handles alone.
minor comments (1)
- [Abstract] The abstract asserts SOTA across 8 metrics and scaling behavior but supplies no numerical values, metric definitions, or baseline details; these should be summarized with references to the experimental tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Probing experiment and §4 (method)] The central justification for the method (abstract and method description) is that the two steering handles must be applied at the probed turning points. No ablation is reported that applies the handles at alternative schedules or timesteps and compares resulting metrics on Meve; without this, it is unclear whether the claimed SOTA performance and scaling depend on the specific turning-point timing or would arise from the handles alone.
Authors: We agree that the manuscript lacks an ablation comparing the steering handles applied at the probed turning points versus alternative schedules or timesteps, with quantitative results on Meve. This omission leaves open whether the reported gains and scaling behavior are specifically due to the timing identified by probing. In the revised manuscript we will add this ablation study, reporting the eight metrics for multiple alternative schedules on the Meve benchmark to clarify the contribution of the turning-point schedule. revision: yes
Circularity Check
No circularity; empirical method with external benchmark
full rationale
The paper describes a training-free steering method whose design is motivated by observational probing of DiT trajectories, with performance measured on the self-curated Meve benchmark. No equations, fitted parameters, or self-citations are shown that reduce the claimed SOTA metrics or scaling behavior to quantities defined by the method itself. The derivation chain consists of an empirical observation followed by a heuristic implementation and external evaluation, satisfying the criteria for a self-contained non-circular result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Qinsheng Zhang, Karsten Kreis, Miika Ait- tala, Timo Aila, Samuli Laine, Bryan Catanzaro, Tero Kar- ras, and Ming-Yu Liu. ediff-i: Text-to-image diffusion models with ensemble of expert denoisers.arXiv preprint arXiv:2211.01324, 2022. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Ditctrl: Exploring attention control in multi-modal diffusion transformer for tuning-free multi-prompt longer video gen- eration
Minghong Cai, Xiaodong Cun, Xiaoyu Li, Wenze Liu, Zhaoyang Zhang, Yong Zhang, Ying Shan, and Xiangyu Yue. Ditctrl: Exploring attention control in multi-modal diffusion transformer for tuning-free multi-prompt longer video gen- eration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7763–7772, 2025. 2, 3, 6
2025
-
[3]
Ditctrl: Exploring attention control in multi-modal diffusion transformer for tuning-free multi-prompt longer video gener- ation, 2025
Minghong Cai, Xiaodong Cun, Xiaoyu Li, Wenze Liu, Zhaoyang Zhang, Yong Zhang, Ying Shan, and Xiangyu Yue. Ditctrl: Exploring attention control in multi-modal diffusion transformer for tuning-free multi-prompt longer video gener- ation, 2025. 1
2025
-
[4]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7310–7320,
-
[5]
Training-free layout control with cross-attention guidance
Minghao Chen, Iro Laina, and Andrea Vedaldi. Training-free layout control with cross-attention guidance. InProceedings of the IEEE/CVF winter conference on applications of com- puter vision, pages 5343–5353, 2024. 2, 3
2024
-
[6]
Gentron: Diffusion transformers for image and video generation, 2024
Shoufa Chen, Mengmeng Xu, Jiawei Ren, Yuren Cong, Sen He, Yanping Xie, Animesh Sinha, Ping Luo, Tao Xiang, and Juan-Manuel Perez-Rua. Gentron: Diffusion transformers for image and video generation, 2024. 1
2024
-
[7]
Joseph Cho, Fachrina Dewi Puspitasari, Sheng Zheng, Jingyao Zheng, Lik-Hang Lee, Tae-Ho Kim, Choong Seon Hong, and Chaoning Zhang. Sora as an agi world model? a complete survey on text-to-video generation.arXiv preprint arXiv:2403.05131, 2024. 2
-
[8]
Gemini 2.5: Pushing the frontier with advanced reason- ing, multimodality, long context, and next generation agentic capabilities, 2025
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, and et al. Gemini 2.5: Pushing the frontier with advanced reason- ing, multimodality, long context, and next generation agentic capabilities, 2025. 7, 1
2025
-
[9]
Haoyi Duan, Hong-Xing Yu, Sirui Chen, Li Fei-Fei, and Jiajun Wu. Worldscore: A unified evaluation benchmark for world generation.arXiv preprint arXiv:2504.00983, 2025. 1
-
[10]
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, Eugene Byrne, Zach Chavis, Joya Chen, Feng Cheng, Fu-Jen Chu, Sean Crane, Avijit Dasgupta, Jing Dong, Maria Escobar, Cristhian Forigua, Abrham Gebreselasie, Sanjay Haresh, Jing Huang, Md Moha...
2024
-
[11]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Vbench: Compre- hensive benchmark suite for video generative models, 2023
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Vbench: Compre- hensive benchmark suite for video generative models, 2023. 7, 1
2023
-
[13]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 3
2024
-
[14]
Vbench++: Comprehensive and versatile benchmark suite for video generative models, 2024
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Vbench++: Comprehensive and versatile benchmark suite for video generative models, 2024. 3, 1
2024
-
[15]
Ultralytics yolo11, 2024
Glenn Jocher and Jing Qiu. Ultralytics yolo11, 2024. 7
2024
-
[16]
How Far is Video Generation from World Model: A Physical Law Perspective
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective. arXiv preprint arXiv:2411.02385, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Shotadapter: Text-to-multi- shot video generation with diffusion models
Ozgur Kara, Krishna Kumar Singh, Feng Liu, Duygu Ceylan, James M Rehg, and Tobias Hinz. Shotadapter: Text-to-multi- shot video generation with diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28405–28415, 2025. 2, 3, 6, 1
2025
-
[18]
Fifo-diffusion: Generating infinite videos from text without training.Advances in Neural Information Processing Sys- tems, 37:89834–89868, 2024
Jihwan Kim, Junoh Kang, Jinyoung Choi, and Bohyung Han. Fifo-diffusion: Generating infinite videos from text without training.Advances in Neural Information Processing Sys- tems, 37:89834–89868, 2024. 2
2024
-
[19]
Gonzalez, Ion Stoica, Song Han, and Y ao Lu
Dacheng Li, Yunhao Fang, Yukang Chen, Shuo Yang, Shiyi Cao, Justin Wong, Michael Luo, Xiaolong Wang, Hongxu Yin, Joseph E Gonzalez, et al. Worldmodelbench: Judging video generation models as world models.arXiv preprint arXiv:2502.20694, 2025. 2 10
-
[20]
Zongjian Li, Bin Lin, Yang Ye, Liuhan Chen, Xinhua Cheng, Shenghai Yuan, and Li Yuan. Wf-vae: Enhancing video vae by wavelet-driven energy flow for latent video diffusion model.arXiv preprint arXiv:2411.17459, 2024. 2, 6
-
[21]
Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Xiong, Yanxin Long, Xinchi Deng, Yingfang Zhang, Xingchao Liu, Min- bin Huang, Zedong Xiao, et al. Hunyuan-dit: A powerful multi-resolution diffusion transformer with fine-grained chi- nese understanding.arXiv preprint arXiv:2405.08748, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Videoinsta: Zero-shot long video understanding via informative spatial- temporal reasoning with llms
Ruotong Liao, Max Erler, Huiyu Wang, Guangyao Zhai, Gengyuan Zhang, Yunpu Ma, and Volker Tresp. Videoinsta: Zero-shot long video understanding via informative spatial- temporal reasoning with llms. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 6577– 6602, 2024. 2
2024
-
[23]
Gentkg: Generative forecasting on temporal knowl- edge graph with large language models
Ruotong Liao, Xu Jia, Yangzhe Li, Yunpu Ma, and Volker Tresp. Gentkg: Generative forecasting on temporal knowl- edge graph with large language models. InFindings of the as- sociation for computational linguistics: NAACL 2024, pages 4303–4317, 2024. 2
2024
-
[24]
When and where do events switch in multi-event video generation?, 2025
Ruotong Liao, Guowen Huang, Qing Cheng, Thomas Seidl, Daniel Cremers, and Volker Tresp. When and where do events switch in multi-event video generation?, 2025. 2, 9
2025
-
[25]
Open-Sora Plan: Open-Source Large Video Generation Model
Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Li- uhan Chen, et al. Open-sora plan: Open-source large video generation model.arXiv preprint arXiv:2412.00131, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Zhiheng Liu, Xueqing Deng, Shoufa Chen, Angtian Wang, Qiushan Guo, Mingfei Han, Zeyue Xue, Mengzhao Chen, Ping Luo, and Linjie Yang. Worldweaver: Generating long- horizon video worlds via rich perception.arXiv preprint arXiv:2508.15720, 2025. 2
-
[27]
The shape variational autoencoder: A deep generative model of part- segmented 3d objects
Charlie Nash and Christopher KI Williams. The shape variational autoencoder: A deep generative model of part- segmented 3d objects. InComputer Graphics Forum, pages 1–12. Wiley Online Library, 2017. 2
2017
-
[28]
Mevg: Multi-event video generation with text-to-video models
Gyeongrok Oh, Jaehwan Jeong, Sieun Kim, Wonmin Byeon, Jinkyu Kim, Sungwoong Kim, and Sangpil Kim. Mevg: Multi-event video generation with text-to-video models. In European Conference on Computer Vision, pages 401–418. Springer, 2024. 2, 3, 6
2024
-
[29]
Dinov2: Learning robust visual features without supervision, 2024
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e Je- gou, Julien Mairal, P...
2024
-
[30]
Scalable diffusion models with transformers, 2023
William Peebles and Saining Xie. Scalable diffusion models with transformers, 2023. 1, 2
2023
-
[31]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih- Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Maskˆ 2dit: Dual mask-based diffusion transformer for multi-scene long video generation
Tianhao Qi, Jianlong Yuan, Wanquan Feng, Shancheng Fang, Jiawei Liu, SiYu Zhou, Qian He, Hongtao Xie, and Yongdong Zhang. Maskˆ 2dit: Dual mask-based diffusion transformer for multi-scene long video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18837–18846, 2025. 3
2025
-
[33]
Mask2dit: Dual mask-based diffusion transformer for multi-scene long video generation, 2025
Tianhao Qi, Jianlong Yuan, Wanquan Feng, Shancheng Fang, Jiawei Liu, SiYu Zhou, Qian He, Hongtao Xie, and Yongdong Zhang. Mask2dit: Dual mask-based diffusion transformer for multi-scene long video generation, 2025. 2, 3
2025
-
[34]
Freenoise: Tuning-free longer video diffusion via noise rescheduling, 2024
Haonan Qiu, Menghan Xia, Yong Zhang, Yingqing He, Xin- tao Wang, Ying Shan, and Ziwei Liu. Freenoise: Tuning-free longer video diffusion via noise rescheduling, 2024. 2, 6
2024
-
[35]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. 7
2021
-
[36]
Sam 2: Segment anything in images and videos, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll ´ar, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos, 2024. 7
2024
-
[37]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural lan- guage processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 3982–3992, 2019. 7
2019
-
[38]
arXiv preprint arXiv:2411.02265 (2024) 31
Xingwu Sun, Yanfeng Chen, Yiqing Huang, Ruobing Xie, Jiaqi Zhu, Kai Zhang, Shuaipeng Li, Zhen Yang, Jonny Han, Xiaobo Shu, et al. Hunyuan-large: An open-source moe model with 52 billion activated parameters by tencent.arXiv preprint arXiv:2411.02265, 2024. 2
-
[39]
Mochi 1.https://github.com/ genmoai/models, 2024
Genmo Team. Mochi 1.https://github.com/ genmoai/models, 2024. 2
2024
-
[40]
The tensor brain: A unified theory of perception, memory, and semantic decoding.Neu- ral Computation, 35(2):156–227, 2023
Volker Tresp, Sahand Sharifzadeh, Hang Li, Dario Konopatzki, and Yunpu Ma. The tensor brain: A unified theory of perception, memory, and semantic decoding.Neu- ral Computation, 35(2):156–227, 2023. 1
2023
-
[41]
Wan: Open and advanced large-scale video gener- ative models
Wan-AI. Wan: Open and advanced large-scale video gener- ative models. 2025. 6
2025
-
[42]
Fu-Yun Wang, Wenshuo Chen, Guanglu Song, Han-Jia Ye, Yu Liu, and Hongsheng Li. Gen-l-video: Multi-text to long video generation via temporal co-denoising.arXiv preprint arXiv:2305.18264, 2023. 2
-
[43]
Gen-l-video: Multi-text to long video generation via temporal co-denoising, 2023
Fu-Yun Wang, Wenshuo Chen, Guanglu Song, Han-Jia Ye, Yu Liu, and Hongsheng Li. Gen-l-video: Multi-text to long video generation via temporal co-denoising, 2023. 2
2023
-
[44]
Internvid: A large-scale video-text dataset for multimodal understanding and generation, 2024
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, Conghui He, Ping Luo, Ziwei Liu, Yali Wang, Limin Wang, and Yu Qiao. Internvid: A large-scale video-text dataset for multimodal understanding and generation, 2024. 7 11
2024
-
[45]
Mind the time: Temporally-controlled multi-event video generation
Ziyi Wu, Aliaksandr Siarohin, Willi Menapace, Ivan Sko- rokhodov, Yuwei Fang, Varnith Chordia, Igor Gilitschenski, and Sergey Tulyakov. Mind the time: Temporally-controlled multi-event video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23989– 24000, 2025. 2, 6
2025
-
[46]
A survey on video diffusion models, 2024
Zhen Xing, Qijun Feng, Haoran Chen, Qi Dai, Han Hu, Hang Xu, Zuxuan Wu, and Yu-Gang Jiang. A survey on video diffusion models, 2024. 1
2024
-
[47]
Dynamic prompt learning: Addressing cross- attention leakage for text-based image editing.Advances in Neural Information Processing Systems, 36:26291–26303,
Fei Yang, Shiqi Yang, Muhammad Atif Butt, Joost van de Weijer, et al. Dynamic prompt learning: Addressing cross- attention leakage for text-based image editing.Advances in Neural Information Processing Systems, 36:26291–26303,
-
[48]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Instadrive: Instance-aware driving world models for realistic and consistent video generation
Zhuoran Yang, Xi Guo, Chenjing Ding, Chiyu Wang, Wei Wu, and Yanyong Zhang. Instadrive: Instance-aware driving world models for realistic and consistent video generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 25410–25420, 2025. 2
2025
-
[50]
Fan Zhang, Shulin Tian, Ziqi Huang, Yu Qiao, and Ziwei Liu. Evaluation agent: Efficient and promptable evalua- tion framework for visual generative models.arXiv preprint arXiv:2412.09645, 2024. 3, 1
-
[51]
Hongyu Zhang, Yufan Deng, Shenghai Yuan, Peng Jin, Zesen Cheng, Yian Zhao, Chang Liu, and Jie Chen. Magiccomp: Training-free dual-phase refinement for compositional video generation.arXiv preprint arXiv:2503.14428, 2025. 3
-
[52]
Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness,
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, Yu Qiao, and Ziwei Liu. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness,
-
[53]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei- Shi Zheng, et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025. 3, 1 12 TunerDiT: Training-free Progressive Steering of Diffusion Transformer for Consistent Multi-Event Video ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Figure 10
Overall Preference:Please rate your overall preference for the video. Figure 10. Interface of annotating multi-event generation quality
-
[55]
Motion Naturalness:How natural and realistic is the motion in the video?
-
[56]
Transition Smoothness:How smoothly does the video content transition across different frames?
-
[57]
TunerDiT achieves superior Text-Video Alignment scores compared to the base- line models, including open-source base models and zero- shot methods MEVG, DiTCtrl and FreeNoise
Text-Video Alignment:To what extent does the video content match the given text descriptions? Evaluation ResultsThe quantitative results, derived from evaluations by 14 participants with mimum degree in bachlors, are presented in Table 1b. TunerDiT achieves superior Text-Video Alignment scores compared to the base- line models, including open-source base ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.