World Models: A Comprehensive Survey of Architectures, Methodologies, Reasoning Paradigms, and Applications
Pith reviewed 2026-06-29 08:34 UTC · model grok-4.3
The pith
World models are organized by a four-axis taxonomy covering architecture, methodology, reasoning, and application domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
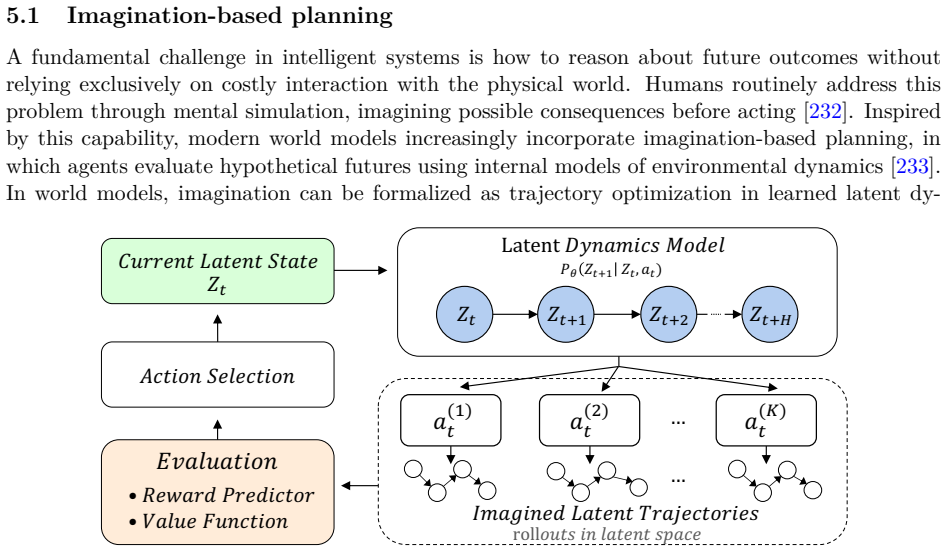
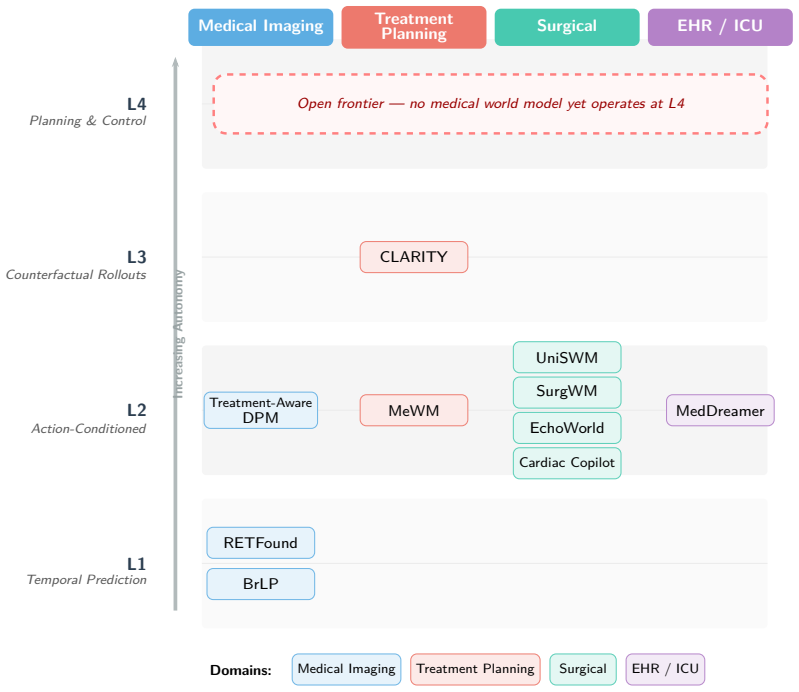
The field of world models lacks a unified framework integrating its diverse architectural choices, training methods, reasoning mechanisms, and application settings; this survey supplies a multi-axis taxonomy organized along four dimensions—architecture (representation, dynamics, modality, paradigm), methodological family (state-space, recurrent, transformer, diffusion, physics-informed, language-augmented), reasoning strategy (imagination-based planning, latent policy, counterfactual, uncertainty), and application domain—to trace interactions, highlight convergence of chain-of-thought with imagination, and outline directions toward foundation-scale interactive simulators.
What carries the argument
The multi-axis taxonomy along architecture, methodological family, reasoning strategy, and application domain, used to classify milestone systems and their interactions.
If this is right
- Milestone systems such as Dreamer and MuZero can be placed and compared directly on the four axes.
- Recent convergence between chain-of-thought reasoning and world-model imagination becomes visible as an interaction across the reasoning and methodological axes.
- Persistent challenges such as compounding prediction errors and fragmented evaluation can be examined uniformly across domains.
- Future work on unified multimodal world models and safe deployment follows as extensions along the architecture and application axes.
Where Pith is reading between the lines
- The taxonomy could be used to identify missing combinations, such as physics-informed diffusion models for scientific domains, that have not yet been built.
- Extending the same four axes to large language models that incorporate internal simulation would test whether the structure generalizes beyond the surveyed reinforcement-learning and robotics literature.
- Standardizing benchmarks according to the taxonomy's dimensions would allow direct measurement of how architectural choices affect sim-to-real transfer.
- The survey's emphasis on evaluation protocols suggests that new metrics could be defined per cell of the taxonomy to reduce fragmentation.
Load-bearing premise
The four chosen dimensions and listed milestone systems suffice to organize the full literature without major omissions or overlaps requiring extra axes.
What would settle it
Discovery of multiple important world-model papers or systems that require a fifth organizing dimension or cannot be placed on the four axes without distortion.
Figures


read the original abstract
World models, internal simulators that learn the structure and dynamics of an environment, have emerged as a central paradigm in the pursuit of artificial general intelligence, enabling agents to predict, plan, and reason within learned representations. Despite rapid progress across reinforcement learning, robotics, autonomous driving, and video generation, the field lacks a unified framework integrating its diverse architectural choices, training methods, reasoning mechanisms, and application settings. This survey addresses that gap with a multi-axis taxonomy organized along four dimensions: (i) architecture, encompassing representation format, dynamics formulation, input modality, learning paradigm, and downstream application; (ii) methodological family, including state-space and recurrent approaches, transformer-based models, diffusion-based generators, physics-informed networks, and language-augmented multimodal systems; (iii) reasoning strategy, covering imagination-based planning, latent policy learning, counterfactual reasoning, and planning under uncertainty; and (iv) application domain, spanning robotics, autonomous driving, video prediction, multimodal agents, reinforcement learning, scientific modeling, medical imaging, educational measurement, and business and finance. Tracing the field from early cognitive-science foundations to milestone systems such as PlaNet, the Dreamer family, MuZero, Sora, Cosmos, and Genie, we examine how these dimensions interact and highlight the recent convergence of chain-of-thought reasoning with world-model imagination. We review evaluation protocols and benchmarks, identify persistent challenges such as compounding prediction errors, sim-to-real transfer, and fragmented evaluation, and outline future directions toward unified multimodal world models, foundation-scale interactive simulators, and safe deployment in safety-critical domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that world models lack a unified framework integrating architectural choices, training methods, reasoning mechanisms, and applications, and addresses this gap via a four-axis taxonomy: (i) architecture (representation format, dynamics formulation, input modality, learning paradigm, downstream application), (ii) methodological family (state-space/recurrent, transformer-based, diffusion-based, physics-informed, language-augmented), (iii) reasoning strategy (imagination-based planning, latent policy learning, counterfactual reasoning, planning under uncertainty), and (iv) application domain (robotics, autonomous driving, video prediction, etc.). It traces the field from cognitive-science roots through milestones such as PlaNet, the Dreamer family, MuZero, Sora, Cosmos, and Genie; examines dimension interactions including convergence of chain-of-thought with imagination; reviews evaluation protocols and benchmarks; identifies challenges such as compounding errors and sim-to-real transfer; and outlines future directions toward unified multimodal models and safe deployment.
Significance. A well-constructed, non-overlapping taxonomy could provide a useful organizing lens for the rapidly growing world-model literature across RL, robotics, video generation, and scientific domains, especially given the paper's coverage of historical foundations and recent systems. The explicit discussion of persistent challenges and future directions toward foundation-scale simulators adds reference value if the taxonomy axes can be made disjoint.
major comments (2)
- [Abstract] Abstract: dimension (i) is defined to encompass 'representation format, dynamics formulation, input modality, learning paradigm, and downstream application.' This scope directly intersects with dimension (iv) 'application domain, spanning robotics, autonomous driving,...', violating the requirement that the four axes be disjoint for the taxonomy to supply a unified framework without important overlaps.
- [Abstract] Abstract: methodological family (ii) lists state-space/recurrent approaches, transformer-based models, etc., which are already subsumed under the architectural choices enumerated in dimension (i). No evidence is supplied that the authors apply a non-overlapping assignment rule when classifying concrete systems such as Dreamer or MuZero.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for a disjoint taxonomy. We address each major comment below and will incorporate revisions to strengthen the framework.
read point-by-point responses
-
Referee: [Abstract] Abstract: dimension (i) is defined to encompass 'representation format, dynamics formulation, input modality, learning paradigm, and downstream application.' This scope directly intersects with dimension (iv) 'application domain, spanning robotics, autonomous driving,...', violating the requirement that the four axes be disjoint for the taxonomy to supply a unified framework without important overlaps.
Authors: We agree that listing 'downstream application' within dimension (i) creates an unintended overlap with dimension (iv). In the revised version we will remove 'downstream application' from the definition of dimension (i), restricting it to representation format, dynamics formulation, input modality, and learning paradigm. Dimension (iv) will remain the sole locus for application domains. The change will appear in the abstract, the taxonomy section, and the classification tables. revision: yes
-
Referee: [Abstract] Abstract: methodological family (ii) lists state-space/recurrent approaches, transformer-based models, etc., which are already subsumed under the architectural choices enumerated in dimension (i). No evidence is supplied that the authors apply a non-overlapping assignment rule when classifying concrete systems such as Dreamer or MuZero.
Authors: Dimension (i) enumerates granular design decisions (e.g., whether the dynamics are formulated as a state-space model or a transformer), while dimension (ii) groups models by their dominant methodological family at a higher level of abstraction. Nevertheless, the current text does not explicitly state the assignment rule or demonstrate its application to the cited systems. We will add a short subsection that defines a priority ordering (family first, then component choices) and will include explicit assignments for Dreamer, MuZero, Sora, and several other milestones to make the separation transparent. revision: partial
Circularity Check
No circularity: survey proposes taxonomy without derivations or self-referential reductions
full rationale
This is a literature survey paper whose central contribution is a four-axis taxonomy for organizing existing world-model research. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The dimensions are stated explicitly as (i) architecture (with listed sub-elements), (ii) methodological family, (iii) reasoning strategy, and (iv) application domain; these are applied to external milestone systems such as PlaNet, Dreamer, MuZero, Sora, and Genie. No step reduces a claim to a self-citation, an ansatz smuggled via prior work, or a renaming of a known result. The taxonomy is an author-proposed organizational tool rather than a quantity derived from itself. Minor self-citations, if present, are not load-bearing for any derivation because none exists. The paper is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption World models constitute a central paradigm for artificial general intelligence
Reference graph
Works this paper leans on
-
[1]
A Comprehensive Survey on World Models for Embodied AI
Xinqing Li et al. A comprehensive survey on world models for embodied AI.arXiv preprint arXiv:2510.16732, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Harvard University Press, 1983
PhilipN.Johnson-Laird.Mental Models: Towards a Cognitive Science of Language, Inference, and Consciousness. Harvard University Press, 1983
1983
-
[3]
A framework for representing knowledge
Marvin Minsky. A framework for representing knowledge. Technical Report Memo 306, MIT AI Laboratory, 1974
1974
-
[5]
A path towards autonomous machine intelligence.OpenReview preprint, 2022
Yann LeCun. A path towards autonomous machine intelligence.OpenReview preprint, 2022. Version 0.9.2, 2022-06-27
2022
-
[6]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[7]
Mastering atari with discrete world models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models. InInternational Conference on Learning Representations, 2021
2021
-
[8]
Mastering diverse domains through world models.Nature, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.Nature, 2025
2025
-
[9]
Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, and David Silver. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
2020
-
[10]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, and Lichao Sun. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Jingtao Ding, Yunke Zhang, Yu Shang, Yuheng Zhang, Zefang Zong, Jie Feng, Yuan Yuan, Hongyuan Su, Nian Li, Jinghua Piao, Yucheng Deng, Nicholas Sukiennik, Chen Gao, Fengli Xu, and Yong Li. Understanding world or predicting future? a comprehensive survey of world models.ACM Computing Surveys, 58(3):1–38, 2025. doi: 10.1145/3746449
-
[12]
V-JEPA 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint, 2025
Mahmoud Assran et al. V-JEPA 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint, 2025
2025
-
[13]
Genie: Generative inter- active environments.arXiv preprint arXiv:2402.15391, 2024
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steiber, Chris Apps, et al. Genie: Generative inter- active environments.arXiv preprint arXiv:2402.15391, 2024
-
[14]
Cosmos: World foundation model platform for physical AI.arXiv preprint, 2025
NVIDIA. Cosmos: World foundation model platform for physical AI.arXiv preprint, 2025
2025
-
[15]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 35, 2022. 111
2022
-
[16]
Reasoning beyond language: A comprehensive survey on latent chain-of-thought reasoning,
Xinghao Chen et al. Reasoning beyond language: A comprehensive survey on latent chain- of-thought reasoning.arXiv preprint arXiv:2505.16782, 2025
-
[17]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao et al. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Latent Chain-of-Thought World Modeling for End-to-End Driving
Shuhan Tan, Kashyap Chitta, Yuxiao Chen, Ran Tian, Yurong You, Yan Wang, Wenjie Luo, Yulong Cao, Philipp Krähenbühl, Marco Pavone, and Boris Ivanovic. Latent chain-of-thought world modeling for end-to-end driving.arXiv preprint arXiv:2512.10226, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Zhiyu Xiang et al. Futurex: Enhance end-to-end autonomous driving with chain-of-thought reasoning in latent world model.arXiv preprint arXiv:2512.11226, 2025
-
[20]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. URLhttps://arxiv. org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
A survey of transformers.AI Open, 3:111–132, 2022
Tianyang Lin, Yuxin Wang, Xiangyang Liu, and Xipeng Qiu. A survey of transformers.AI Open, 3:111–132, 2022
2022
-
[22]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Evaluation of OpenAI o1: Opportunities and challenges of AGI.arXiv preprint arXiv:2409.18486, 2025
Tianyang Zhong, Zhengliang Liu, Yi Pan, Yutong Zhang, Zeyu Zhang, Yifan Zhou, Shizhe Liang, Zihao Wu, Yanjun Lyu, Peng Shu, et al. Evaluation of OpenAI o1: Opportunities and challenges of AGI.arXiv preprint arXiv:2409.18486, 2025
-
[24]
Harvard University Press, 1988
Hans Moravec.Mind Children: The Future of Robot and Human Intelligence. Harvard University Press, 1988
1988
-
[25]
Advanced machine intelligence (AMI): Building AI systems that understand the physical world, 2025
Yann LeCun. Advanced machine intelligence (AMI): Building AI systems that understand the physical world, 2025. Announced November 2025.https://www. advancedmachineintelligence.com
2025
-
[26]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, 2nd edition, 2018
2018
-
[27]
World models for autonomous driving: An initial survey
Yanchen Guan, Haicheng Cui, et al. World models for autonomous driving: An initial survey. arXiv preprint arXiv:2403.02622, 2024
-
[28]
A step toward world models: A survey on robotic manipulation.arXiv preprint arXiv:2511.02097, 2025
Xuan Li et al. A step toward world models: A survey on robotic manipulation.arXiv preprint arXiv:2511.02097, 2025
-
[29]
Steven C. H. Chen et al. 3d and 4d world modeling: A survey.https://worldbench.github. io/survey, 2025
2025
-
[30]
Curious model-building control systems
Jürgen Schmidhuber. Curious model-building control systems. InProc. International Joint Conference on Neural Networks (IJCNN), volume 2, pages 1458–1463. IEEE, 1991. doi: 10.1109/IJCNN.1991.170605
-
[31]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. InProceedings of the 36th International Conference on Machine Learning, pages 2555–2565. PMLR, 2019. 112
2019
-
[32]
Dream to con- trol: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to con- trol: Learning behaviors by latent imagination. InInternational Conference on Learning Representations, 2020
2020
-
[33]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
Mastering atari with discrete world models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[35]
Transformers are sample-efficient world learners
Vincent Micheli, Eloi Alonso, and François Fleuret. Transformers are sample-efficient world learners. InThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[36]
STORM: Efficient stochastic transformer based world models for rein- forcement learning
Weipu Zhang et al. STORM: Efficient stochastic transformer based world models for rein- forcement learning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[37]
Diffusion for world modeling: Visual details matter in Atari
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storber, Oriol Vinyals, and François Fleuret. Diffusion for world modeling: Visual details matter in Atari. In Advances in Neural Information Processing Systems, 2024. NeurIPS 2024 Spotlight
2024
-
[38]
Mastering Atari, Go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, and David Silver. Mastering Atari, Go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
2020
-
[39]
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023
2023
-
[40]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.Nature, 2025. arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Moerland, Joost Broekens, Aske Plaat, and Catholijn M
Thomas M. Moerland, Joost Broekens, Aske Plaat, and Catholijn M. Jonker. Model-based reinforcement learning: A survey.Foundations and Trends in Machine Learning, 16(1):1–118, 2023
2023
-
[42]
Rusu, Joel Veness, Marc G
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Pe- tersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep rein- forceme...
2015
-
[43]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[44]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InProceedings of the 35th International Conference on Machine Learning (ICML), pages 1861–1870, 2018. 113
2018
-
[45]
Deepreinforcement learning in a handful of trials using probabilistic dynamics models.Advances in Neural Information Processing Systems, 31, 2018
KurtlandChua, RobertoCalandra, RowanMcAllister, andSergeyLevine. Deepreinforcement learning in a handful of trials using probabilistic dynamics models.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[46]
Temporal difference learning for model pre- dictive control
Nicklas Hansen, Xiaolong Wang, and Hao Su. Temporal difference learning for model pre- dictive control. InInternational Conference on Machine Learning, pages 8487–8506. PMLR, 2022
2022
-
[47]
Pilco: A model-based and data-efficient approach to policy search
Marc Peter Deisenroth and Carl Edward Rasmussen. Pilco: A model-based and data-efficient approach to policy search. InProceedings of the 28th International Conference on Machine Learning (ICML), pages 465–472, 2011
2011
-
[48]
When to trust your model: Model-based policy optimization
Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: Model-based policy optimization. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[49]
Rusu, Loic Matthey, Christopher P
Irina Higgins, Arka Pal, Andrei A. Rusu, Loic Matthey, Christopher P. Burgess, Alexander Pritzel, Matthew Botvinick, Charles Blundell, and Alexander Lerchner. Darla: Improving zero-shot transfer in reinforcement learning. InProceedings of the 34th International Confer- ence on Machine Learning (ICML), pages 1480–1490, 2017
2017
-
[50]
Schema Networks: Zero-shot Transfer with a Generative Causal Model of Intuitive Physics
Ken Kansky, Tom Silver, David A. Mély, Mohamed Eldawy, Miguel Lázaro-Gredilla, Xinghua Lou, Nimrod Dorfman, Szymon Sidor, Scott Phoenix, and Dileep George. Schema net- works: Zero-shot transfer with a generative causal model of intuitive physics.arXiv preprint arXiv:1706.04317, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[51]
Woulda, coulda, shoulda: Counterfactually-guided policy search
Lars Buesing, Theophane Weber, Yori Zwols, Nicolas Heess, Sébastien Racanière, Arthur Guez, and Jean-Baptiste Lespiau. Woulda, coulda, shoulda: Counterfactually-guided policy search. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[52]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InProceedings of the 33rd International Conference on Machine Learning (ICML), pages 1050–1059, 2016
2016
-
[53]
Deep exploration via bootstrapped dqn
Ian Osband, Charles Blundell, Alexander Pritzel, and Benjamin Van Roy. Deep exploration via bootstrapped dqn. InAdvances in Neural Information Processing Systems (NeurIPS), volume 29, 2016
2016
-
[54]
Bellemare, Will Dabney, and Rémi Munos
Marc G. Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on rein- forcement learning. InProceedings of the 34th International Conference on Machine Learning (ICML), pages 449–458, 2017
2017
-
[55]
Devon Hjelm, Aaron Courville, and Philip Bachman
Max Schwarzer, Ankesh Anand, Rishab Goel, R. Devon Hjelm, Aaron Courville, and Philip Bachman. Data-efficient reinforcement learning with self-predictive representations. InIn- ternational Conference on Learning Representations (ICLR), 2021
2021
-
[56]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-encoding variational Bayes.International Con- ference on Learning Representations, 2014
2014
-
[57]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual rep- resentations from video.arXiv preprint arXiv:2404.08471, 2024. 114
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Meta AI. V-JEPA 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Campbell, and Sergey Levine
Mohammad Babaeizadeh, Chelsea Finn, Dumitru Erhan, Roy H. Campbell, and Sergey Levine. Stochastic variational video prediction.International Conference on Learning Rep- resentations, 2018
2018
-
[60]
Stochastic video generation with a learned prior.International Conference on Machine Learning, pages 1174–1183, 2018
Emily Denton and Rob Fergus. Stochastic video generation with a learned prior.International Conference on Machine Learning, pages 1174–1183, 2018
2018
-
[63]
Contrastive learning of structured world models
Thomas Kipf, Elise van der Pol, and Max Welling. Contrastive learning of structured world models. InInternational Conference on Learning Representations, 2020. URLhttps:// openreview.net/forum?id=H1gax6VtDB
2020
-
[64]
Robo- dreamer: learning compositional world models for robot imagination
Siyuan Zhou, Yilun Du, Jiaben Chen, Yandong Li, Dit-Yan Yeung, and Chuang Gan. Robo- dreamer: learning compositional world models for robot imagination. InProceedings of the 41st International Conference on Machine Learning, pages 61885–61896, 2024
2024
-
[65]
Dream to manipulate: Compositional world models empowering robot imitation learning with imagination
Leonardo Barcellona et al. Dream to manipulate: Compositional world models empowering robot imitation learning with imagination. InInternational Conference on Learning Repre- sentations, 2025
2025
-
[67]
Copilot4D:Learningunsupervisedworldmodelsforautonomousdriving via discrete diffusion
YunpengZhangetal. Copilot4D:Learningunsupervisedworldmodelsforautonomousdriving via discrete diffusion. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[68]
3D and 4D world modeling: A survey.arXiv preprint arXiv:2509.07996, 2025
Lingdong Kong et al. 3D and 4D world modeling: A survey.arXiv preprint arXiv:2509.07996, 2025
-
[69]
Mri contrast enhancement kinetics world model.arXiv preprint arXiv:2602.19285, 2026
Jindi Kong, Yuting He, Cong Xia, Rongjun Ge, and Shuo Li. Mri contrast enhancement kinetics world model.arXiv preprint arXiv:2602.19285, 2026
-
[70]
Leworldmodel: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint, 2024
Anonymous. Leworldmodel: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint, 2024
2024
-
[71]
Brain-jepa: Brain dynamics foundation model with gradient positioning and spatiotemporal masking.arXiv preprint, 2024
Anonymous. Brain-jepa: Brain dynamics foundation model with gradient positioning and spatiotemporal masking.arXiv preprint, 2024
2024
-
[72]
Clarity: Medical world model for guiding treatment decisions by modeling context-aware disease trajectories in latent space.arXiv preprint, 2025
Anonymous. Clarity: Medical world model for guiding treatment decisions by modeling context-aware disease trajectories in latent space.arXiv preprint, 2025
2025
-
[73]
Medical world model.arXiv preprint, 2024
Anonymous. Medical world model.arXiv preprint, 2024. 115
2024
-
[74]
Transformers are sample-efficient world models
Vincent Micheli, Eloi Alonso, and François Fleuret. Transformers are sample-efficient world models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[75]
Diffusion for world modeling: Visual details matter in atari
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, 2024
2024
-
[76]
Diffusion Models Are Real-Time Game Engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines.arXiv preprint arXiv:2408.14837, 2024. Published at ICLR 2025
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
Reasoning with language model is planning with world model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. Reasoning with language model is planning with world model. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8154– 8173, Singapore, 2023. Association for Computational Linguistics
2023
-
[78]
Yu Gu, Boyuan Deng, Chen Zhu, Yi Dong, Mingyue Li, Jianwei Xie, Shuyan Lu, Tianbao Shi, Yu Su, and Wen-tau Yih. Is your LLM secretly a world model of the internet? model-based planning for web agents.arXiv preprint arXiv:2411.06559, 2024
-
[79]
Brafman, and Moshe Tennenholtz
Raz Levy, Ronen I. Brafman, and Moshe Tennenholtz. WorldLLM: Learning world models via large language models.arXiv preprint arXiv:2506.05270, 2025
-
[80]
Learning to generate realistic LiDAR point clouds.arXiv preprint arXiv:2209.03954, 2022
Vlas Zyrianov, Xiyue Zhu, and Shenlong Wang. Learning to generate realistic LiDAR point clouds.arXiv preprint arXiv:2209.03954, 2022. ECCV 2022
-
[81]
LidarDM: Generative LiDAR simulation in a generated world.arXiv preprint arXiv:2404.02903, 2024
Vlas Zyrianov, Boris Ivanovic, Vince Zhao, and Marco Pavone. LidarDM: Generative LiDAR simulation in a generated world.arXiv preprint arXiv:2404.02903, 2024
-
[82]
OccWorld: Learning a 3D occupancy world model for autonomous driving
Wenzhao Zheng, Weiliang Chen, Yuanhui Huang, Borui Zhang, Yueqi Duan, and Jiwen Lu. OccWorld: Learning a 3D occupancy world model for autonomous driving. InEuropean Conference on Computer Vision (ECCV), 2024. arXiv preprint arXiv:2311.16038, 2023
-
[83]
Day- dreamer: World models for physical robot learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Day- dreamer: World models for physical robot learning. InConference on robot learning, pages 2226–2240. PMLR, 2023
2023
-
[84]
MLA Team. MLA: A multisensory language-action model for multimodal understanding and forecasting in robotic manipulation.arXiv preprint arXiv:2509.26642, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.