Agentic Transformers Provably Learn to Search via Reinforcement Learning
Pith reviewed 2026-06-28 23:24 UTC · model grok-4.3
The pith
A two-head transformer implements randomized depth-first search and acquires it through policy-gradient training on tree environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a stochastic k-ary tree where the agent sees only trajectory history and receives a terminal reward at a hidden goal leaf, a two-head transformer architecture implements randomized depth-first search, and the same mechanism arises spontaneously from policy-gradient dynamics under a depth-wise curriculum, yielding depth generalization and, with discounting, ranked search.
What carries the argument
Two-head transformer in which one attention head tracks previous actions while the other detects failure outcomes and triggers backtracking.
If this is right
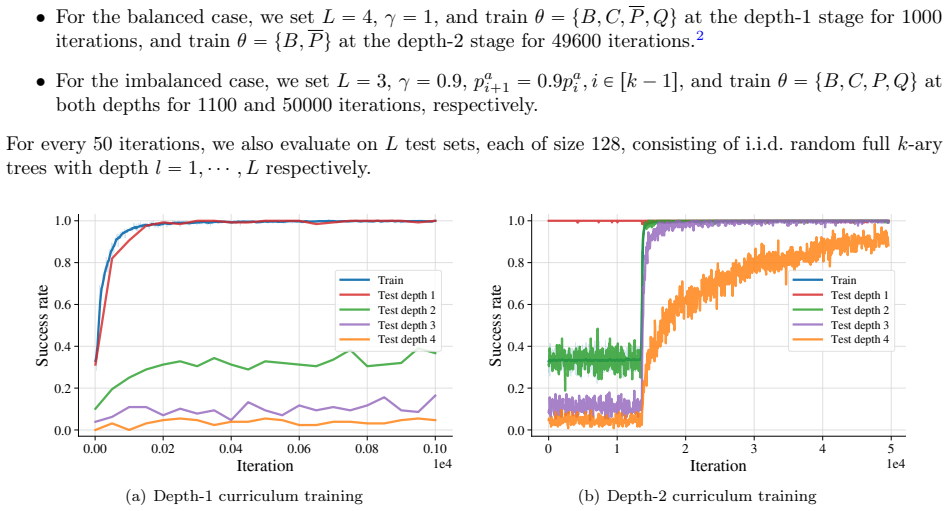
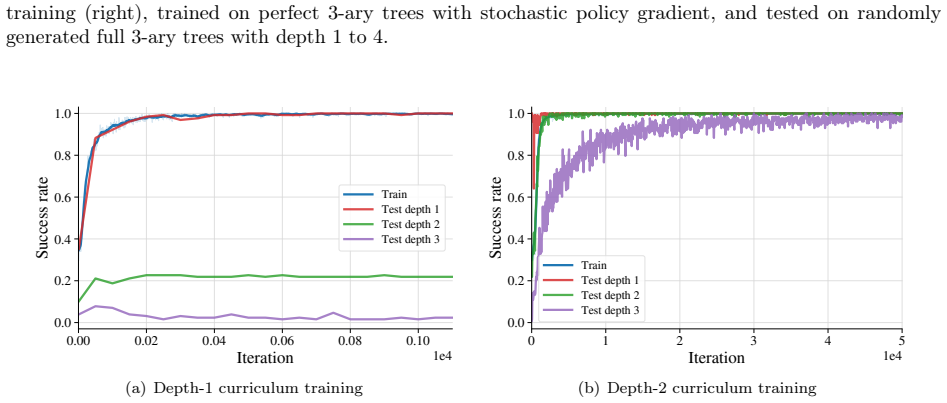
- After training only on depth-1 and depth-2 trees the policy succeeds on deeper full trees.
- Discounting the return produces a ranked depth-first policy that prioritizes higher-probability branches under imbalanced goal distributions.
- The search behavior arises from sparse reinforcement feedback without expert demonstrations.
- Attention heads specialize and cooperate to extract decision-relevant traces from context and map them to action selection.
Where Pith is reading between the lines
- The same head-specialization pattern could appear in language-model agents that must explore and backtrack over multi-step reasoning traces.
- Replacing the tree with other structured environments might reveal whether the curriculum is necessary or whether the specialization occurs more generally.
- If the two-head motif is minimal, removing one head or altering its role should collapse performance on deeper trees.
Load-bearing premise
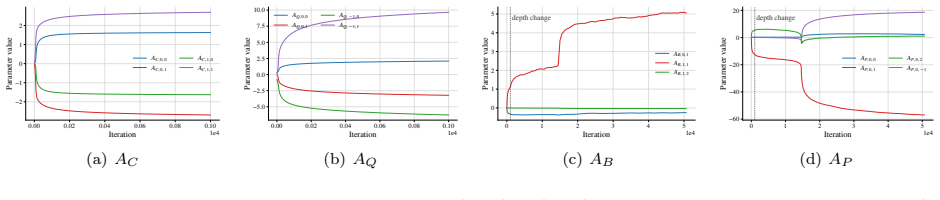
The specific stochastic k-ary tree environment together with the depth-wise curriculum is enough to make policy-gradient updates produce the exact described attention-head specialization rather than some other successful policy.
What would settle it
Train the described policy-gradient procedure on the depth-wise curriculum and inspect the attention heads; if they fail to show one head tracking actions and the other detecting failures and backtracking, the claimed emergence does not occur.
Figures

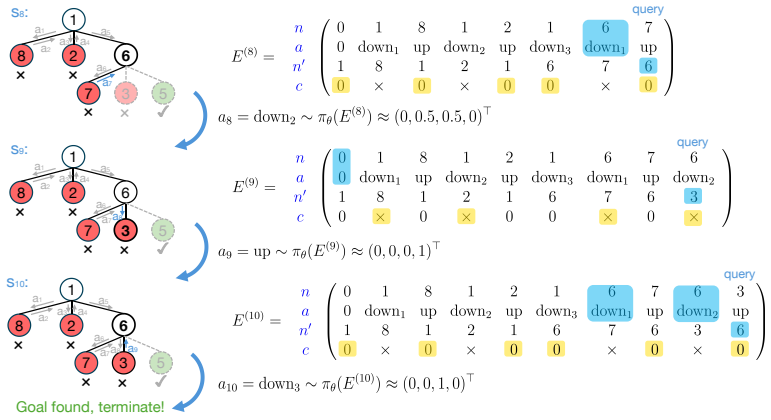
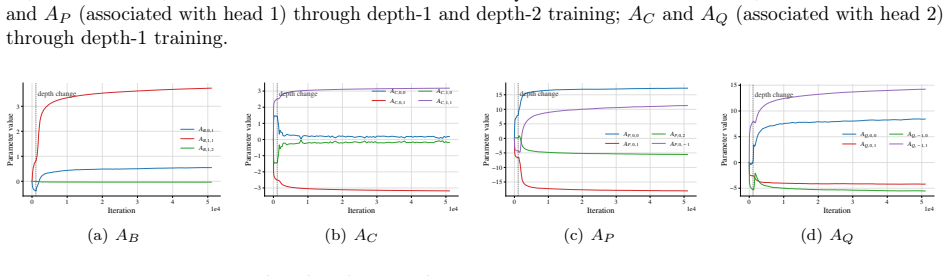
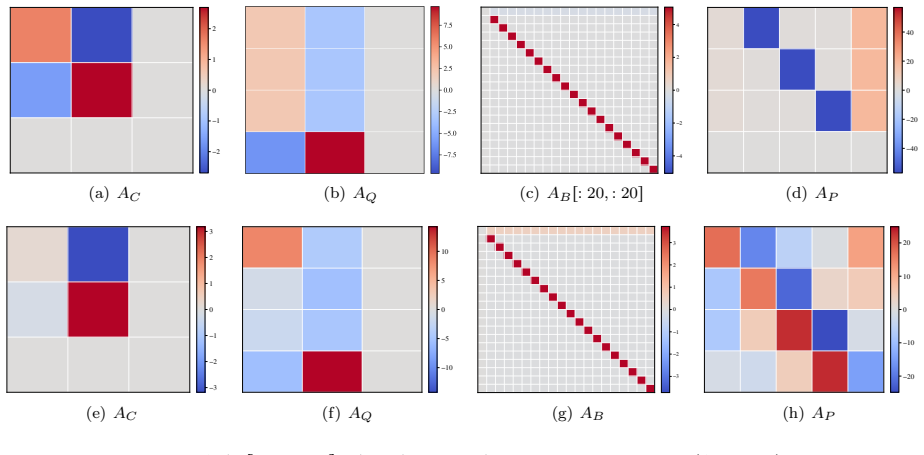
read the original abstract
Tree search is a central abstraction behind many language-agent reasoning and decision-making tasks: agents must explore actions, remember failures, and backtrack toward promising alternatives. Yet, we lack a theoretical understanding of how transformer-based policies acquire such search capabilities from the training dynamics of reinforcement learning (RL). We study this question in a stochastic $k$-ary tree environment, where an agentic transformer observes only its trajectory history through interaction and receives a terminal reward for reaching a hidden leaf goal node. We first construct a two-head transformer that implements randomized depth-first search (DFS): one head tracks previous actions, while the other detects failure outcomes and triggers backtracking. We then analyze the training dynamics of policy gradient under a depth-wise curriculum, showing that this same DFS mechanism emerges in stages from sparse reinforcement feedback without expert demonstrations. The resulting policy exhibits depth generalization: after training only on depth-$1$ and depth-$2$ trees, it succeeds on deeper full trees. We further show that, under imbalanced goal distributions, discounting the return leads to a ranked DFS policy that prioritizes higher-probability branches. Overall, our results identify a mechanistic normal form for transformer-based search, in which attention heads specialize and cooperate to extract decision-relevant traces from context and convert them into agentic action selection via RL training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in a stochastic k-ary tree environment with only trajectory history and terminal rewards, a two-head transformer can be constructed to implement randomized DFS (one head tracks prior actions; the other detects failures and triggers backtracking). It further claims that policy-gradient training under a depth-wise curriculum causes precisely this mechanism to emerge in stages from sparse feedback, yielding depth generalization (success on deeper trees after training only on depths 1-2) and, under imbalanced goal distributions, a ranked DFS policy via discounting.
Significance. If the training-dynamics analysis holds with explicit convergence arguments, the work supplies a mechanistic normal form for how attention heads can specialize via RL to extract decision traces from context, offering a concrete existence proof and emergence pathway for transformer-based search without demonstrations. This would be a notable contribution to the theory of agentic reasoning.
major comments (2)
- [Training-dynamics analysis (post-construction)] The central emergence claim (that policy-gradient updates under the depth-wise curriculum drive attention-head specialization into the exact two-head DFS configuration rather than any other goal-reaching policy) is load-bearing but rests on an implicit uniqueness argument; the provided abstract and construction do not include gradient-flow analysis or bounds showing this attractor dominates on the training distribution.
- [Depth generalization experiments] The depth-generalization result after training only on depth-1 and depth-2 trees requires explicit verification that the learned policy transfers without additional assumptions on the tree structure or reward sparsity that might not hold for arbitrary deeper instances.
minor comments (2)
- Define the precise form of the depth-wise curriculum and the stochastic k-ary tree transition probabilities in a dedicated section or appendix to allow reproduction of the dynamics.
- Clarify whether the two-head construction is used only for the existence proof or also as an inductive hypothesis in the dynamics proof.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our emergence and generalization claims. We address each major point below, indicating where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: The central emergence claim (that policy-gradient updates under the depth-wise curriculum drive attention-head specialization into the exact two-head DFS configuration rather than any other goal-reaching policy) is load-bearing but rests on an implicit uniqueness argument; the provided abstract and construction do not include gradient-flow analysis or bounds showing this attractor dominates on the training distribution.
Authors: We agree that the training-dynamics section presents the emergence via a stage-wise curriculum argument rather than a full gradient-flow analysis with explicit uniqueness bounds. While the construction and curriculum stages demonstrate how the two-head DFS mechanism arises from sparse feedback, we will add a dedicated subsection with a more formal analysis of the policy-gradient updates, including a sketch of why the DFS configuration is the dominant attractor under the depth-wise training distribution. revision: yes
-
Referee: The depth-generalization result after training only on depth-1 and depth-2 trees requires explicit verification that the learned policy transfers without additional assumptions on the tree structure or reward sparsity that might not hold for arbitrary deeper instances.
Authors: The depth-generalization experiments already evaluate the policy trained on depths 1-2 directly on deeper trees. To address potential concerns about implicit assumptions, we will expand the experimental section with additional results on non-uniform tree structures and varying reward sparsity levels, confirming that transfer holds without further training or structural assumptions beyond those stated in the environment definition. revision: yes
Circularity Check
No circularity: explicit construction independent of training-dynamics analysis
full rationale
The paper first gives an explicit construction of a two-head transformer realizing randomized DFS (one head for action tracking, one for failure detection and backtracking). It then separately analyzes policy-gradient dynamics under depth-wise curriculum to show the same mechanism emerges from sparse rewards. These are distinct steps: the construction is an existence proof, while the dynamics analysis derives specialization from the RL objective and stochastic k-ary tree without reducing to the construction by definition, fitted parameters, or self-citation chains. No load-bearing step collapses to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Policy-gradient updates on the transformer policy in the stochastic k-ary tree converge to a DFS-like policy under the depth-wise curriculum.
invented entities (1)
-
Two-head transformer implementing randomized DFS
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Outcome-Based RL Provably Leads Transformers to Reason, but Only With the Right Data
Outcome-Based RL Provably Leads Transformers to Reason, but Only With the Right Data , author=. arXiv preprint arXiv:2601.15158 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Advances in Neural Information Processing Systems , volume=
In-context learning with representations: Contextual generalization of trained transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[4]
arXiv preprint arXiv:2506.21797 , year=
Why Neural Network Can Discover Symbolic Structures with Gradient-based Training: An Algebraic and Geometric Foundation for Neurosymbolic Reasoning , author=. arXiv preprint arXiv:2506.21797 , year=
-
[5]
International Conference on Machine Learning , pages=
The Pitfalls of Next-Token Prediction , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[6]
Advances in Neural Information Processing Systems , year=
Transformers Provably Learn Chain-of-Thought Reasoning with Length Generalization , author=. Advances in Neural Information Processing Systems , year=
-
[7]
arXiv preprint arXiv:2402.11917 , year=
A mechanistic analysis of a transformer trained on a symbolic multi-step reasoning task , author=. arXiv preprint arXiv:2402.11917 , year=
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2505.00926 , year=
How Transformers Learn Regular Language Recognition: A Theoretical Study on Training Dynamics and Implicit Bias , author=. arXiv preprint arXiv:2505.00926 , year=
-
[10]
arXiv preprint arXiv:2208.05051 , year=
Limitations of language models in arithmetic and symbolic induction , author=. arXiv preprint arXiv:2208.05051 , year=
-
[11]
Show your work: Scratchpads for intermediate computation with language models , author=
-
[12]
arXiv preprint arXiv:2210.10749 , year=
Transformers learn shortcuts to automata , author=. arXiv preprint arXiv:2210.10749 , year=
-
[13]
The Thirteenth International Conference on Learning Representations , year=
Generalizing Reasoning Problems to Longer Lengths , author=. The Thirteenth International Conference on Learning Representations , year=
-
[14]
Metastable Dynamics of Chain-of-Thought Reasoning: Provable Benefits of Search,
Kim, Juno and Wu, Denny and Lee, Jason and Suzuki, Taiji , journal=. Metastable Dynamics of Chain-of-Thought Reasoning: Provable Benefits of Search,
-
[15]
Advances in Neural Information Processing Systems , volume=
Understanding transformer reasoning capabilities via graph algorithms , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Advances in Neural Information Processing Systems , volume=
Dissecting chain-of-thought: Compositionality through in-context filtering and learning , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
On the Turing Completeness of Modern Neural Network Architectures
On the turing completeness of modern neural network architectures , author=. arXiv preprint arXiv:1901.03429 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[18]
Advances in Neural Information Processing Systems , volume=
Towards revealing the mystery behind chain of thought: a theoretical perspective , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
arXiv preprint arXiv:2310.07923 , year=
The expressive power of transformers with chain of thought , author=. arXiv preprint arXiv:2310.07923 , year=
-
[20]
arXiv preprint arXiv:2402.12875 , volume=
Chain of thought empowers transformers to solve inherently serial problems , author=. arXiv preprint arXiv:2402.12875 , volume=
-
[21]
First Conference on Language Modeling , year=
On limitations of the transformer architecture , author=. First Conference on Language Modeling , year=
-
[22]
arXiv preprint arXiv:2501.12997 , year=
Ehrenfeucht-Haussler Rank and Chain of Thought , author=. arXiv preprint arXiv:2501.12997 , year=
-
[23]
arXiv preprint arXiv:2502.02393 , year=
Lower Bounds for Chain-of-Thought Reasoning in Hard-Attention Transformers , author=. arXiv preprint arXiv:2502.02393 , year=
-
[24]
arXiv preprint arXiv:2412.02975 , year=
Theoretical limitations of multi-layer Transformer , author=. arXiv preprint arXiv:2412.02975 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
How far can transformers reason? the globality barrier and inductive scratchpad , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
arXiv preprint arXiv:2303.07971 , year=
A theory of emergent in-context learning as implicit structure induction , author=. arXiv preprint arXiv:2303.07971 , year=
-
[27]
arXiv preprint arXiv:2204.02892 , year=
Sub-task decomposition enables learning in sequence to sequence tasks , author=. arXiv preprint arXiv:2204.02892 , year=
-
[28]
arXiv preprint arXiv:2408.14511 , year=
Unveiling the statistical foundations of chain-of-thought prompting methods , author=. arXiv preprint arXiv:2408.14511 , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
Why think step by step? reasoning emerges from the locality of experience , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
arXiv preprint arXiv:2410.05459 , year=
From sparse dependence to sparse attention: unveiling how chain-of-thought enhances transformer sample efficiency , author=. arXiv preprint arXiv:2410.05459 , year=
-
[31]
arXiv preprint arXiv:2410.08633 , year=
Transformers provably solve parity efficiently with chain of thought , author=. arXiv preprint arXiv:2410.08633 , year=
-
[32]
arXiv preprint arXiv:2410.02167 , year=
Training Nonlinear Transformers for Chain-of-Thought Inference: A Theoretical Generalization Analysis , author=. arXiv preprint arXiv:2410.02167 , year=
-
[33]
arXiv preprint arXiv:2310.16028 , year=
What algorithms can transformers learn? a study in length generalization , author=. arXiv preprint arXiv:2310.16028 , year=
-
[34]
arXiv preprint arXiv:2410.02140 , year=
A formal framework for understanding length generalization in transformers , author=. arXiv preprint arXiv:2410.02140 , year=
-
[35]
arXiv preprint arXiv:2406.01895 , year=
Explicitly encoding structural symmetry is key to length generalization in arithmetic tasks , author=. arXiv preprint arXiv:2406.01895 , year=
-
[36]
arXiv preprint arXiv:2402.04875 , year=
On provable length and compositional generalization , author=. arXiv preprint arXiv:2402.04875 , year=
-
[37]
arXiv preprint arXiv:2502.16792 , year=
The Role of Sparsity for Length Generalization in Transformers , author=. arXiv preprint arXiv:2502.16792 , year=
-
[38]
arXiv preprint arXiv:2406.06893 , year=
Transformers provably learn sparse token selection while fully-connected nets cannot , author=. arXiv preprint arXiv:2406.06893 , year=
-
[39]
arXiv preprint arXiv:2411.01035 , year=
Provable Length Generalization in Sequence Prediction via Spectral Filtering , author=. arXiv preprint arXiv:2411.01035 , year=
-
[40]
arXiv preprint arXiv:2402.09963 , year=
Why are Sensitive Functions Hard for Transformers? , author=. arXiv preprint arXiv:2402.09963 , year=
-
[41]
arXiv preprint arXiv:2502.10927 , year=
The underlying structures of self-attention: symmetry, directionality, and emergent dynamics in Transformer training , author=. arXiv preprint arXiv:2502.10927 , year=
-
[42]
International Conference on Machine Learning , pages=
In-Context Convergence of Transformers , author=. International Conference on Machine Learning , pages=
-
[43]
Journal of Machine Learning Research , volume=
Trained transformers learn linear models in-context , author=. Journal of Machine Learning Research , volume=
-
[44]
arXiv preprint arXiv:2402.15607 , year=
How do nonlinear transformers learn and generalize in in-context learning? , author=. arXiv preprint arXiv:2402.15607 , year=
-
[45]
arXiv preprint arXiv:2402.19442 , year=
Training dynamics of multi-head softmax attention for in-context learning: Emergence, convergence, and optimality , author=. arXiv preprint arXiv:2402.19442 , year=
-
[46]
International Conference on Machine Learning , pages=
How transformers learn causal structure with gradient descent , author=. International Conference on Machine Learning , pages=
-
[47]
arXiv preprint arXiv:2409.10559 , year=
Unveiling induction heads: Provable training dynamics and feature learning in transformers , author=. arXiv preprint arXiv:2409.10559 , year=
-
[48]
The Thirteenth International Conference on Learning Representations , year=
A Theoretical Analysis of Self-Supervised Learning for Vision Transformers , author=. The Thirteenth International Conference on Learning Representations , year=
-
[49]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[50]
arXiv preprint arXiv:2402.10200 , year=
Chain-of-thought reasoning without prompting , author=. arXiv preprint arXiv:2402.10200 , year=
-
[51]
arXiv preprint arXiv:2402.18312 , year=
How to think step-by-step: A mechanistic understanding of chain-of-thought reasoning , author=. arXiv preprint arXiv:2402.18312 , year=
-
[52]
0-shot” in the paper is “0-shot
Finite state automata inside transformers with chain-of-thought: A mechanistic study on state tracking , author=. arXiv preprint arXiv:2502.20129 , year=
-
[53]
Advances in neural information processing systems , volume=
The unreasonable effectiveness of structured random orthogonal embeddings , author=. Advances in neural information processing systems , volume=
-
[54]
2002 , publisher=
Optimal Learning: Computational procedures for Bayes-adaptive Markov decision processes , author=. 2002 , publisher=
2002
-
[55]
Machine learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[56]
Advances in neural information processing systems , volume=
Policy gradient methods for reinforcement learning with function approximation , author=. Advances in neural information processing systems , volume=
-
[57]
International Conference on Machine Learning , pages=
Global Convergence of Policy Gradient Methods for the Linear Quadratic Regulator , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[58]
International Conference on Machine Learning , pages=
On the Global Convergence Rates of Softmax Policy Gradient Methods , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[59]
International Conference on Learning Representations , year=
Neural Policy Gradient Methods: Global Optimality and Rates of Convergence , author=. International Conference on Learning Representations , year=
-
[60]
Journal of Machine Learning Research , volume=
On the Theory of Policy Gradient Methods: Optimality, Approximation, and Distribution Shift , author=. Journal of Machine Learning Research , volume=
-
[61]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[62]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[63]
International Conference on Machine Learning , pages=
Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models , author=. International Conference on Machine Learning , pages=
-
[64]
Snell, Charlie Victor and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , booktitle=. Scaling
-
[65]
Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
Learned token pruning for transformers , author=. Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[66]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Advances in Neural Information Processing Systems , year=
Multi-head Transformers Provably Learn Symbolic Multi-step Reasoning via Gradient Descent , author=. Advances in Neural Information Processing Systems , year=
-
[69]
IEEE Transactions on Computational Intelligence and AI in games , volume=
A survey of monte carlo tree search methods , author=. IEEE Transactions on Computational Intelligence and AI in games , volume=. 2012 , publisher=
2012
-
[70]
nature , volume=
Mastering the game of Go with deep neural networks and tree search , author=. nature , volume=. 2016 , publisher=
2016
-
[71]
Science , volume=
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play , author=. Science , volume=. 2018 , publisher=
2018
-
[72]
Advances in Neural Information Processing Systems , volume=
Lample, Guillaume and Lachaux, Marie-Anne and Lavril, Thibaut and Martinet, Xavier and Hayat, Amaury and Ebner, Gabriel and Rodriguez, Aur. Advances in Neural Information Processing Systems , volume=
-
[73]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle=
-
[74]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[75]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Reasoning with language model is planning with world model , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[76]
International Conference on Learning Representations , year=
Transformers Struggle to Learn to Search , author=. International Conference on Learning Representations , year=
-
[77]
2026 , eprint=
Transformers Provably Learn Algorithmic Solutions for Graph Connectivity, But Only with the Right Data , author=. 2026 , eprint=
2026
-
[78]
International Conference on Learning Representations , year=
Benefits and pitfalls of reinforcement learning for language model planning: a theoretical perspective , author=. International Conference on Learning Representations , year=
-
[79]
Wang, Siwei and Shen, Yifei and Feng, Shi and Sun, Haoran and Teng, Shang-Hua and Chen, Wei , booktitle=
-
[80]
Transactions on Machine Learning Research , year=
Tree Search for Language Model Agents , author=. Transactions on Machine Learning Research , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.