LLMs Need Encoders for Semantic IDs Too
Pith reviewed 2026-06-28 20:30 UTC · model grok-4.3
The pith
Semantic IDs require a dedicated encoder in LLMs because each token's meaning depends on its prefix context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
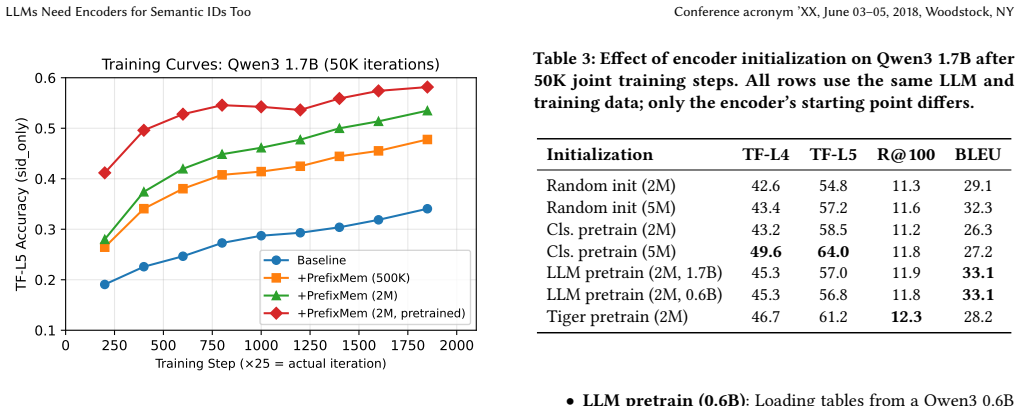
Semantic IDs constitute another modality whose tokens benefit from a dedicated encoder; PrefixMem provides prefix-conditioned representations and improves deepest-level SID accuracy by up to 46% relative and full-SID retrieval recall by up to 22% relative at matched training compute. The encoder can be pre-trained independently and then attached to any LLM for joint training.
What carries the argument
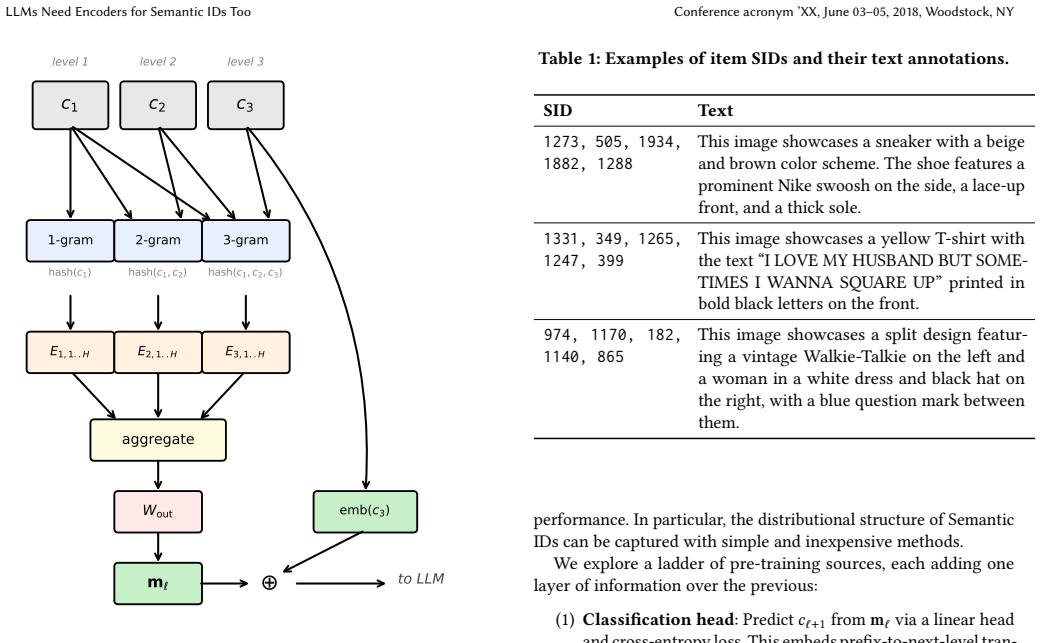
PrefixMem, a lightweight SID encoder based on prefix n-gram memory tables that supplies structured, prefix-conditioned representations at SID token positions.
If this is right
- The encoder can be pre-trained separately before attachment to any LLM family.
- Accuracy gains concentrate on hard examples, reaching up to 77 percent relative improvement where greedy decoding fails.
- Full-SID retrieval recall improves by up to 22 percent relative at matched training compute.
- The same attachment pattern works across multiple LLM families on large recommendation data.
Where Pith is reading between the lines
- Any token sequence whose semantics are prefix-dependent may benefit from an analogous lightweight encoder rather than vocabulary expansion alone.
- The pattern suggests that future multimodal LLMs could maintain a small library of modality-specific encoders, each handling one structured token type.
- Systems that rely solely on vocabulary growth for hierarchical codes may systematically leave performance on the table once training compute is fixed.
Load-bearing premise
The observed gains arise from the prefix-conditioned structure supplied by the n-gram tables rather than from extra parameters or altered training dynamics alone.
What would settle it
An ablation that replaces the prefix n-gram tables with an equal number of extra parameters that emit non-prefix or random vectors for SID positions and then measures no accuracy change would falsify the claim.
Figures

read the original abstract
Multimodal LLMs use dedicated encoders to bridge non-language modalities (vision encoders for images, depth models for audio codec tokens) because raw token embeddings alone cannot capture modality-specific structure. We argue that Semantic IDs (SIDs), the hierarchical codes used in generative recommendation, constitute another such modality: a SID level token's meaning depends on its prefix context, yet current systems simply add SID tokens to the vocabulary and rely on training to learn these context-dependent meanings from scratch. We propose PrefixMem, a lightweight SID encoder based on prefix n-gram memory tables that provides the LLM with structured, prefix-conditioned representations at SID token positions. Like vision encoders in multimodal LLMs, PrefixMem can be pre-trained independently and then attached to any LLM for joint training. We evaluate on large-scale data from Pinterest across multiple LLM families and show that PrefixMem improves deepest-level SID accuracy by up to 46% relative and full-SID retrieval recall by up to 22% relative at matched training compute. The encoder's benefit concentrates on hard examples where greedy decoding fails, with up to 77% relative accuracy gains, confirming that SID tokens benefit from a dedicated encoder just as other non-language modalities do.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Semantic IDs (SIDs) in generative recommendation systems form a distinct modality whose tokens require a dedicated encoder, analogous to vision encoders, because a SID token's meaning depends on its prefix. It proposes PrefixMem, a lightweight prefix n-gram memory table encoder that supplies structured, prefix-conditioned representations and can be pre-trained independently before joint LLM training. On large-scale Pinterest data across LLM families, PrefixMem yields up to 46% relative improvement in deepest-level SID accuracy and 22% in full-SID retrieval recall at matched training compute, with larger gains on hard examples where greedy decoding fails.
Significance. If the performance gains are shown to arise specifically from the prefix-conditioned n-gram structure rather than added capacity, the work would strengthen the case for treating SIDs as a modality requiring explicit encoders and could guide encoder design in industrial recommendation systems. The empirical scale on real Pinterest data is a positive feature, but the absence of parameter-matched controls limits the strength of the modality-encoder analogy.
major comments (2)
- [Abstract / evaluation paragraph] Abstract and evaluation paragraph: the reported gains (46% deepest-level accuracy, 22% retrieval recall) are stated to occur 'at matched training compute,' yet no evidence is given that total parameter count is held constant or that an ablation with equivalent extra capacity (e.g., unstructured MLP or additional embedding layers on SID tokens) was performed. Without this control, the central claim that PrefixMem's benefit derives from structured prefix-conditioned representations rather than capacity or optimization dynamics alone cannot be substantiated.
- [Abstract] Abstract: the manuscript provides no details on baselines, error bars, exact data splits, or ablation controls for the Pinterest experiments. This makes it impossible to assess whether the reported relative improvements are robust or whether they could be explained by differences in training dynamics unrelated to the proposed encoder structure.
minor comments (2)
- [Abstract] The abstract mentions improvements 'across multiple LLM families' but does not name the families or report per-family breakdowns; adding this would improve reproducibility.
- [evaluation paragraph] Notation for 'deepest-level SID accuracy' and 'full-SID retrieval recall' is used without an explicit definition or reference to the precise metric formulas in the evaluation section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing the need for parameter-matched controls and fuller experimental details to strengthen the modality-encoder analogy. We respond to each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / evaluation paragraph] Abstract and evaluation paragraph: the reported gains (46% deepest-level accuracy, 22% retrieval recall) are stated to occur 'at matched training compute,' yet no evidence is given that total parameter count is held constant or that an ablation with equivalent extra capacity (e.g., unstructured MLP or additional embedding layers on SID tokens) was performed. Without this control, the central claim that PrefixMem's benefit derives from structured prefix-conditioned representations rather than capacity or optimization dynamics alone cannot be substantiated.
Authors: We agree that matching training compute in FLOPs does not by itself rule out capacity or optimization effects, and the current manuscript does not report total parameter counts or include an unstructured MLP ablation of matched capacity. In the revision we will add (i) explicit parameter counts for PrefixMem-augmented models versus baselines and (ii) a capacity-matched ablation replacing the prefix n-gram tables with an unstructured MLP of equivalent parameter budget applied to SID token positions. These additions will directly test whether the prefix-conditioned structure, rather than added capacity, drives the observed gains. revision: yes
-
Referee: [Abstract] Abstract: the manuscript provides no details on baselines, error bars, exact data splits, or ablation controls for the Pinterest experiments. This makes it impossible to assess whether the reported relative improvements are robust or whether they could be explained by differences in training dynamics unrelated to the proposed encoder structure.
Authors: The current manuscript is indeed concise on these points. In the revision we will expand the experimental section to report: baseline configurations and hyper-parameters, error bars computed over multiple random seeds, precise train/validation/test splits on the Pinterest data, and the full set of ablation controls (including the new capacity-matched MLP ablation noted above). This will enable readers to evaluate robustness and rule out unrelated training dynamics. revision: yes
Circularity Check
No significant circularity; empirical evaluation on external data
full rationale
The paper proposes PrefixMem as an SID encoder and reports relative accuracy/recall gains on large-scale Pinterest data across LLM families. No mathematical derivations, equations, or 'predictions' appear that reduce by construction to fitted inputs or self-defined quantities. Claims rest on observed metrics at matched training compute rather than any self-referential loop, uniqueness theorem, or ansatz smuggled via self-citation. This matches the default case of a self-contained empirical result against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Prabhat Agarwal, Anirudhan Badrinath, Laksh Bhasin, Jaewon Yang, Edoardo Botta, Jiajing Xu, and Charles Rosenberg. 2025. Pinrec: Outcome-conditioned, multi-token generative retrieval for industry-scale recommendation systems. arXiv preprint arXiv:2504.10507(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Honghui Bao et al. 2024. Learnable Item Tokenization for Generative Recommen- dation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM)
2024
-
[3]
Josh Beal, Eric Kim, Jinfeng Rao, Rex Wu, Dmitry Kislyuk, and Charles Rosenberg
-
[4]
PinCLIP: Large-scale Foundational Multimodal Representation at Pinterest. (2026)
2026
-
[5]
Daiwei Chen, Zhoutong Fu, Chengming Jiang, Haichao Zhang, Ran Zhou, Tan Wang, Chunnan Yao, Guoyao Li, Rui Cai, Yihan Cao, Ruijie Jiang, Fedor Borisyuk, Jianqiang Shen, Jingwei Wu, and Ramya Korlakai Vinayak. 2026. Grounded Token Initialization for New Vocabulary in LMs for Generative Recommendation. arXiv preprint arXiv:2604.02324(2026)
-
[6]
Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. 2026. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?Advances in Neural Information Processing Systems 38 (2026), 57654–57689
2026
-
[7]
Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, et al. 2026. Conditional memory via scalable lookup: A new axis of sparsity for large language models. arXiv preprint arXiv:2601.07372(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. 2024. Moshi: a speech-text foundation model for real-time dialogue.arXiv preprint arXiv:2410.00037(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5). InProceedings of the 16th ACM Conference on Recommender Systems. 299–315
2022
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, et al . 2025. Mtgr: Industrial- scale generative recommendation framework in meituan. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5731–5738
2025
-
[13]
Ruining He, Lukasz Heldt, Lichan Hong, Raghunandan Keshavan, Shifan Mao, Nikhil Mehta, Zhengyang Su, Alicia Tsai, Yueqi Wang, Shao-Chuan Wang, et al
-
[14]
InProceedings of the ACM Web Conference 2026
Plum: Adapting pre-trained language models for industrial-scale generative recommendations. InProceedings of the ACM Web Conference 2026. 8093–8104
2026
-
[15]
Yingzhi He, Yan Sun, Junfei Tan, Yuxin Chen, Xiaoyu Kong, Chunxu Shen, Xi- ang Wang, An Zhang, and Tat-Seng Chua. 2026. Reasoning over Semantic IDs Enhances Generative Recommendation.arXiv preprint arXiv:2603.23183(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [16]
-
[17]
Clark Mingxuan Ju, Tong Zhao, Leonardo Neves, Liam Collins, Bhuvesh Kumar, Jiwen Ren, Lili Zhang, Wenfeng Zhuo, Vincent Zhang, Xiao Bai, et al. 2026. Seman- tic IDs for Recommender Systems at Snapchat.arXiv preprint arXiv:2604.03949 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, et al. 2025. Gemma 3 technical report.arXiv preprint arXiv:2503.19786 4 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[20]
Zhirui Kuai, Zuxu Chen, Huimu Wang, Mingming Li, Dadong Miao, Binbin Wang, Xusong Chen, Li Kuang, Yuxing Han, Jiaxing Wang, Guoyu Tang, Lin Liu, Songlin Wang, and Jingwei Zhuo. 2024. Breaking the Hourglass Phenomenon of Residual Quantization: Enhancing the Upper Bound of Generative Retrieval. InProceedings of the 2024 Conference on Empirical Methods in Na...
2024
-
[21]
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. 2022. Autoregressive image generation using residual quantization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11523–11532
2022
-
[22]
Mingfu Liang, Yufei Li, Jay Xu, Kavosh Asadi, Xi Liu, Shuo Gu, Kaushik Rangadu- rai, Frank Shyu, Shuaiwen Wang, Song Yang, et al. 2026. Generative Reasoning Re-ranker.arXiv preprint arXiv:2602.07774(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Enze Liu, Bowen Zheng, Cheng Ling, Lantao Hu, Han Li, and Wayne Xin Zhao
-
[24]
InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval
Generative recommender with end-to-end learnable item tokenization. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 729–739
-
[25]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[26]
Zhanyu Liu, Shiyao Wang, Xingmei Wang, Rongzhou Zhang, Jiaxin Deng, Honghui Bao, Jinghao Zhang, Wuchao Li, Pengfei Zheng, Xiangyu Wu, et al
- [27]
-
[28]
Benjamin Minixhofer, Fabian Paischer, and Navid Rekabsaz. 2022. WECHSEL: Ef- fective initialization of subword embeddings for cross-lingual transfer of monolin- gual language models. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics
2022
-
[29]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[30]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[31]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Anima Singh, Trung Vu, Nikhil Mehta, Raghunandan Keshavan, Maheswaran Sathiamoorthy, Yilin Zheng, Lichan Hong, Lukasz Heldt, Li Wei, Devansh Tandon, et al. 2024. Better generalization with semantic ids: A case study in ranking for recommendations. InProceedings of the 18th ACM Conference on Recommender Systems. 1039–1044
2024
-
[33]
Zhengyang Su, Isay Katsman, Yueqi Wang, Ruining He, Lukasz Heldt, Raghu- nandan Keshavan, Shao-Chuan Wang, Xinyang Yi, Mingyan Gao, Onkar Dalal, Lichan Hong, Ed Chi, and Ningren Han. 2026. Vectorizing the Trie: Efficient Con- strained Decoding for LLM-based Generative Retrieval on Accelerators.arXiv preprint arXiv:2602.22647(2026)
-
[34]
Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, et al. 2022. Transformer memory as a differentiable search index. InAdvances in Neural Information Processing Systems, Vol. 35
2022
-
[35]
Neha Verma, Nikhil Mehta, Shao-Chuan Wang, Naijing Zhang, Alicia Tsai, Li Wei, Lukasz Heldt, Lichan Hong, Ed Chi, and Xinyang Yi. 2026. ORBIT: Preserv- ing Foundational Language Capabilities in GenRetrieval via Origin-Regulated Merging.arXiv preprint arXiv:2605.12419(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Ye Wang, Jiahao Xun, Minjie Hong, Jieming Zhu, Tao Jin, Wang Lin, Haoyuan Li, Linjun Li, Yan Xia, Zhou Zhao, et al . 2024. Eager: Two-stream generative recommender with behavior-semantic collaboration. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3245–3254
2024
-
[37]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Vber, Boshi Li, Celena Guan, et al. 2024. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [39]
-
[40]
Carolina Zheng, Minhui Huang, Dmitrii Pedchenko, Kaushik Rangadurai, Siyu Wang, Fan Xia, Gaby Nahum, Jie Lei, Yang Yang, Tao Liu, et al. 2025. Enhancing embedding representation stability in recommendation systems with semantic id. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 954–957
2025
- [41]
- [42]
-
[43]
Guorui Zhou, Hengrui Hu, Hongtao Cheng, Huanjie Wang, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Lu Ren, Liao Yu, et al. 2025. OneRec-v2 Technical Report.arXiv preprint arXiv:2508.20900(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Jieming Zhu, Mengqun Jin, Qijiong Liu, Zexuan Qiu, Zhenhua Dong, and Xiu Li
-
[45]
InProceedings of the 18th ACM Conference on Recommender Systems
Cost: Contrastive quantization based semantic tokenization for generative recommendation. InProceedings of the 18th ACM Conference on Recommender Systems. 969–974
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.