PE-means: Improved Differentially Private k-means Clustering through Private Evolution
Pith reviewed 2026-07-04 00:16 UTC · model grok-4.3
The pith
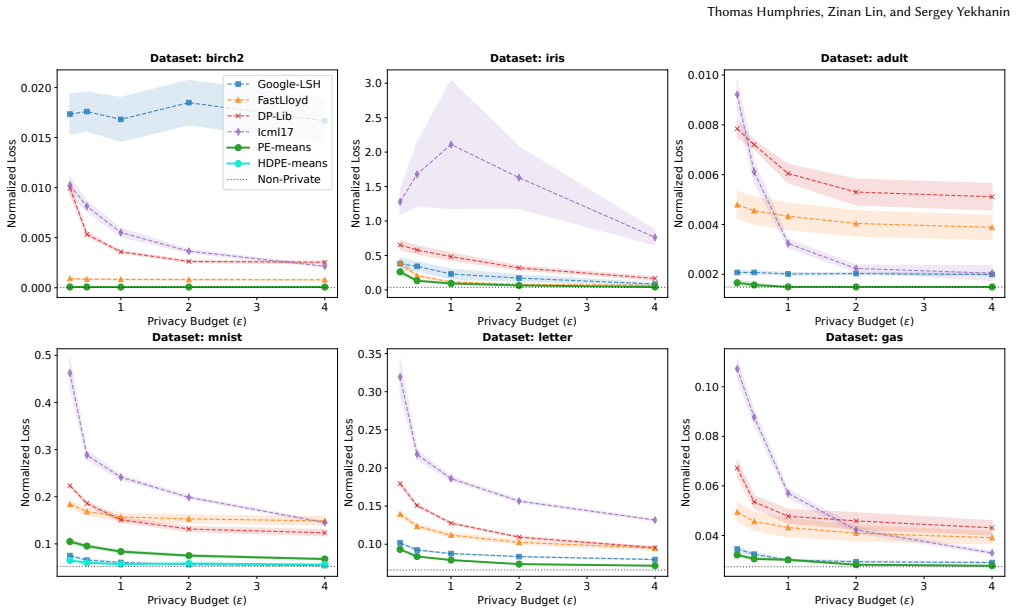
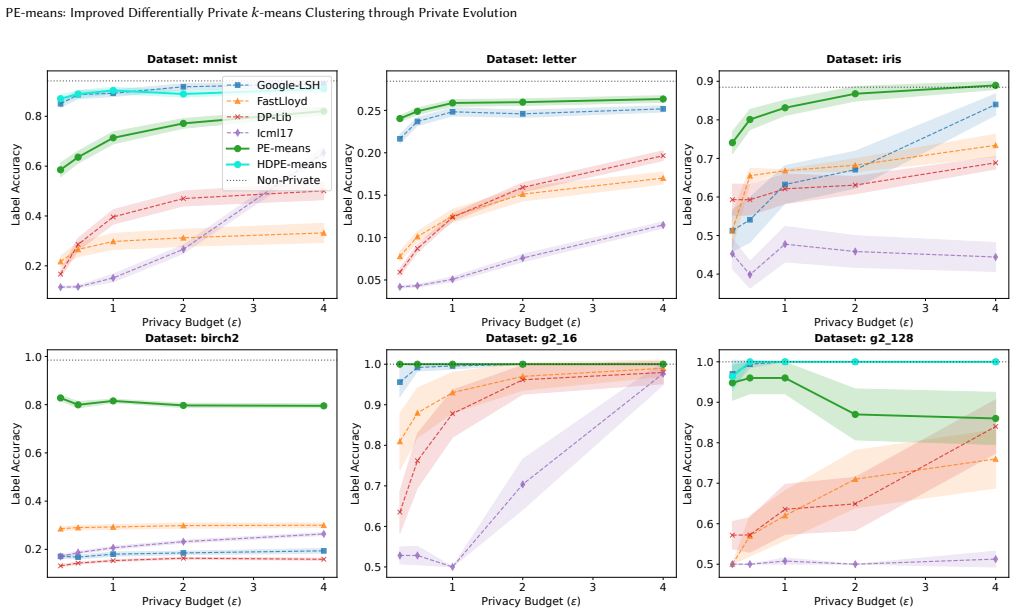
Adapting private evolution to k-means yields 26% better clustering loss under differential privacy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
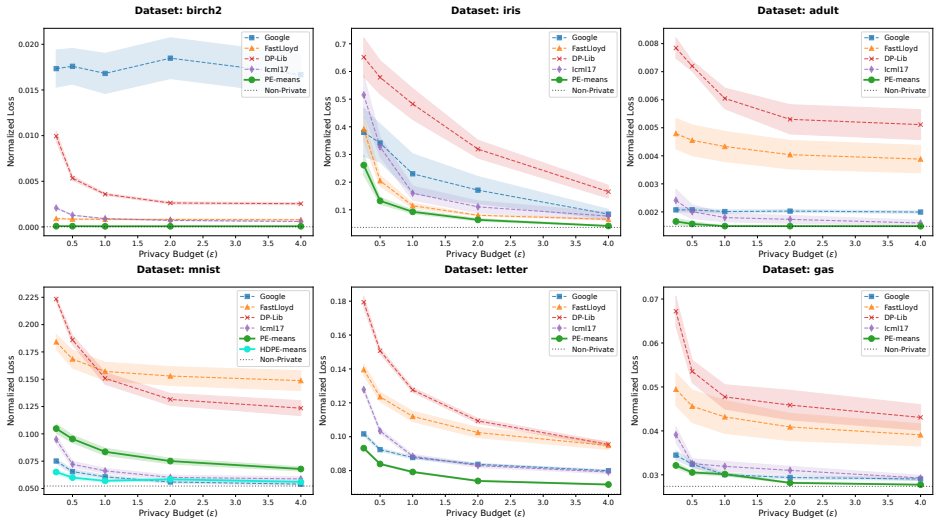
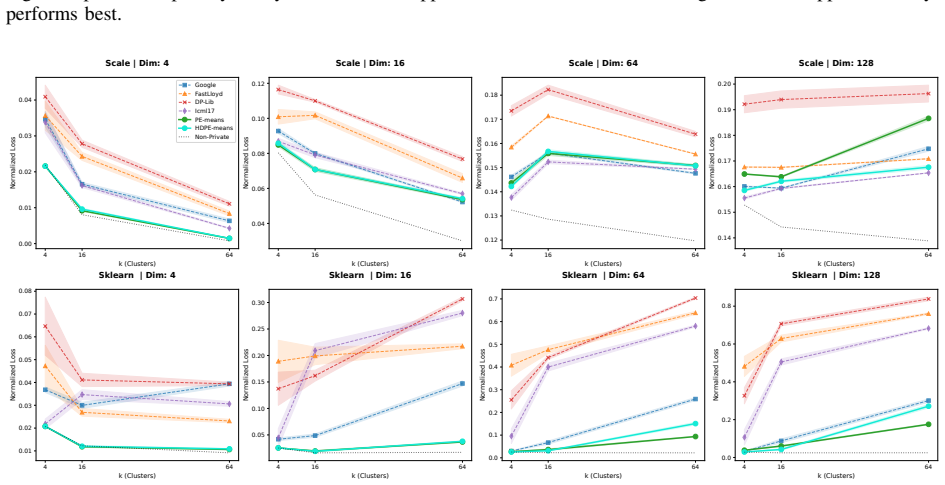
By adapting private evolution to the k-means problem through new evolutionary operators and relying on a private histogram with constant sensitivity to guide the process, PE-means produces higher-utility cluster centers than methods that directly sum private data points, which suffer from sensitivity proportional to the domain.
What carries the argument
Private evolution (PE) adapted with new evolutionary operators for clustering, guided by a private histogram with constant sensitivity.
If this is right
- Noise added for privacy no longer scales with domain size, preserving more signal in the cluster centers.
- The same privacy budget can be used while returning lower clustering loss than direct-summation baselines.
- The approach applies to any Euclidean-space k-means task where a histogram of candidate centers can be maintained privately.
- The 26% average improvement holds across the tested baselines and datasets reported in the paper.
Where Pith is reading between the lines
- The constant-sensitivity histogram may allow the method to scale to much larger or higher-dimensional domains without extra privacy cost.
- The same evolutionary framework could be reused for other private optimization problems that currently rely on direct summation.
- Downstream tasks that consume the resulting cluster centers, such as private classification, may inherit the utility gains.
Load-bearing premise
The private histogram with constant sensitivity combined with the new evolutionary operators is sufficient to produce high-utility cluster centers without the utility degradation that direct summation methods suffer.
What would settle it
A controlled experiment on standard Euclidean datasets in which PE-means shows no statistically significant improvement in clustering loss over the LSH and DP-Lloyd baselines would falsify the central claim.
Figures
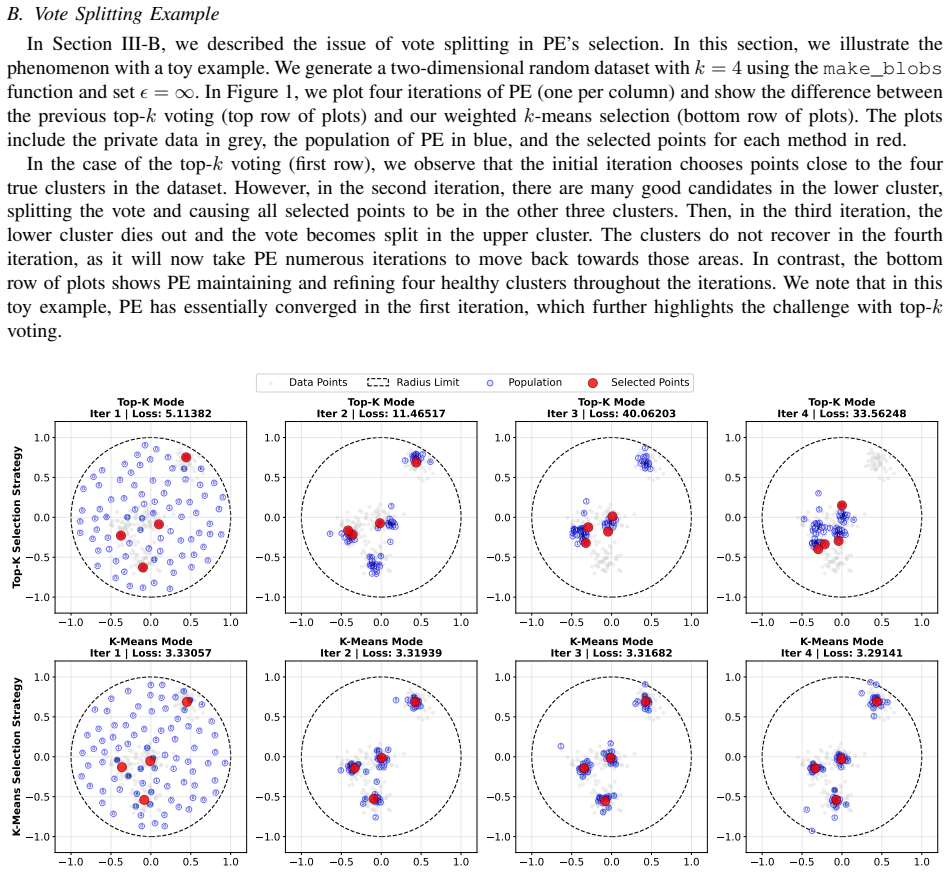
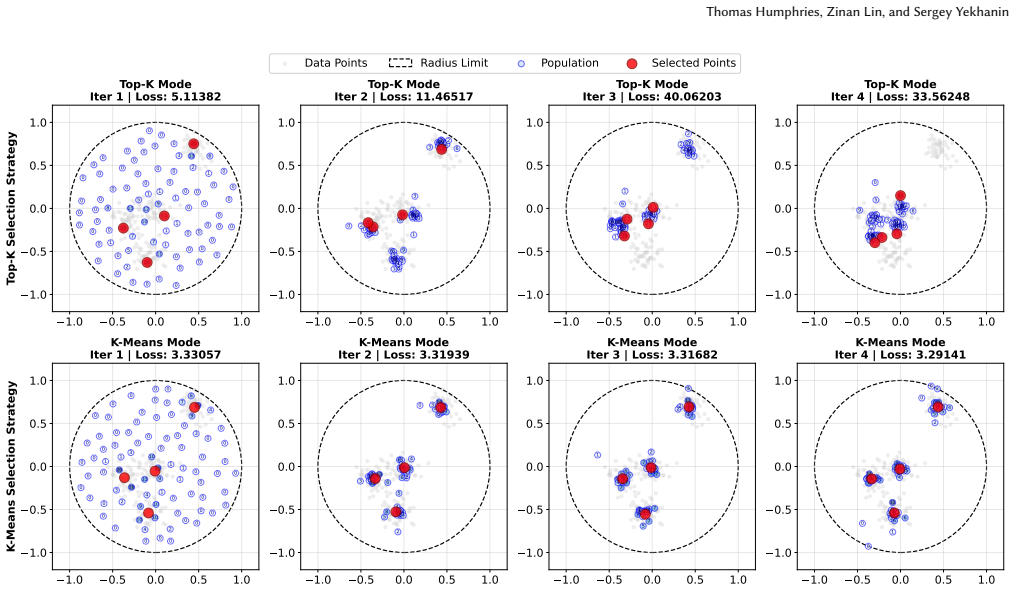
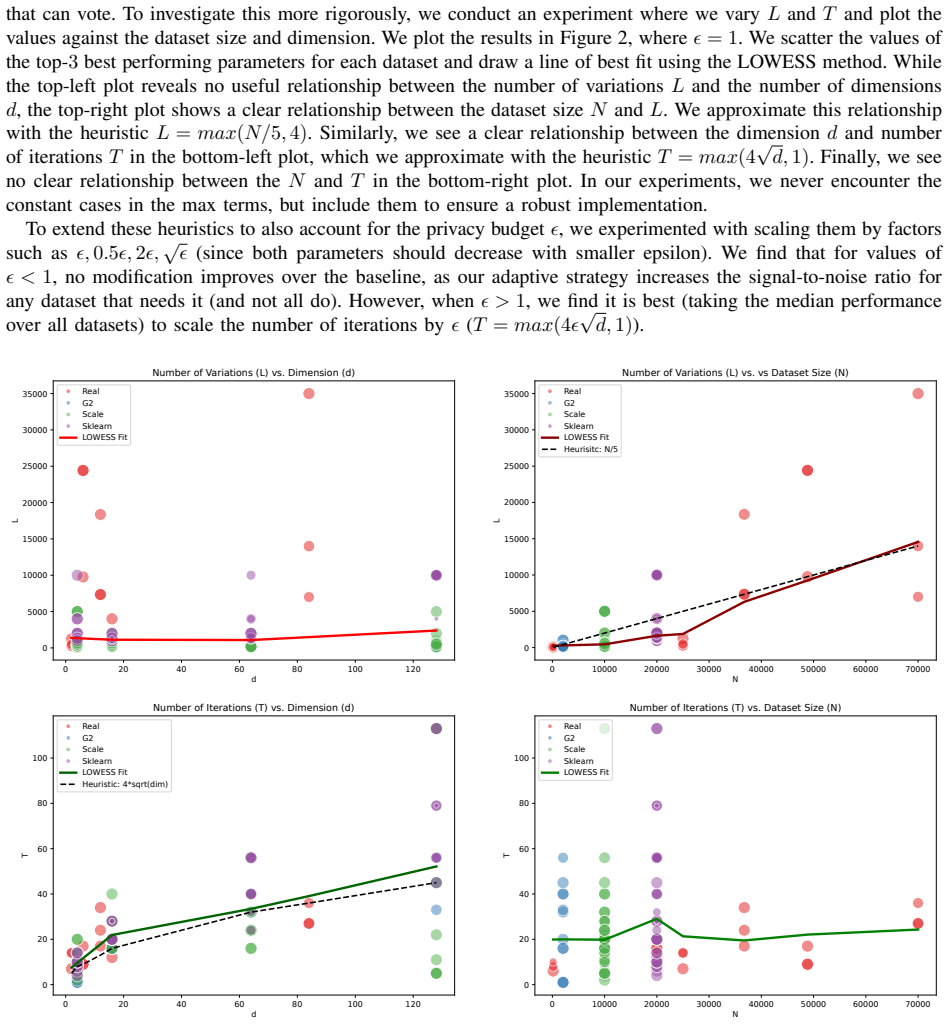
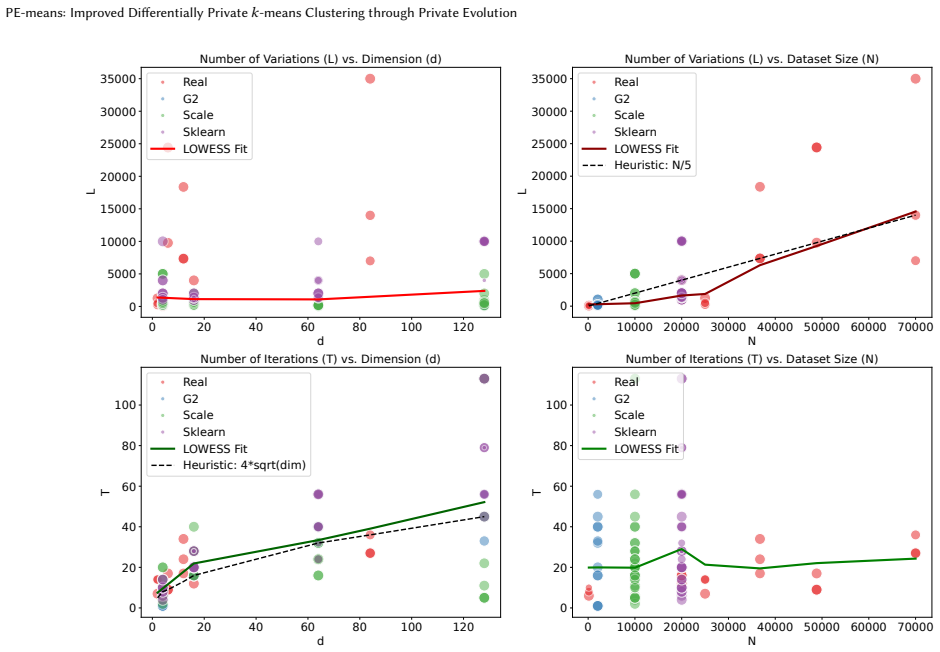


read the original abstract
We study the problem of differentially private (DP) $k$-means clustering in Euclidean space. Previous solutions rely on summing the private data directly, which induces a sensitivity proportional to the domain. We introduce PE-means, an extension of the private evolution (PE) algorithm (an increasingly popular method for synthetic data generation), to the problem of $k$-means clustering. The key advantage of PE is that it only computes a private histogram with constant sensitivity to guide the evolution. Our adaptation of PE includes new evolutionary operators for clustering, as well as other algorithmic improvements of independent interest. Overall, PE-means achieves an average improvement of 26% in clustering loss over state-of-the-art baselines such as Google's LSH-based algorithm and DP-Lloyd variants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PE-means, an adaptation of the private evolution algorithm to differentially private k-means clustering in Euclidean space. It replaces direct summation of private points (which incurs domain-dependent sensitivity) with a private histogram of constant sensitivity to guide the evolutionary process, introduces new evolutionary operators tailored to clustering, and reports an average 26% improvement in clustering loss relative to baselines including Google's LSH-based method and DP-Lloyd variants.
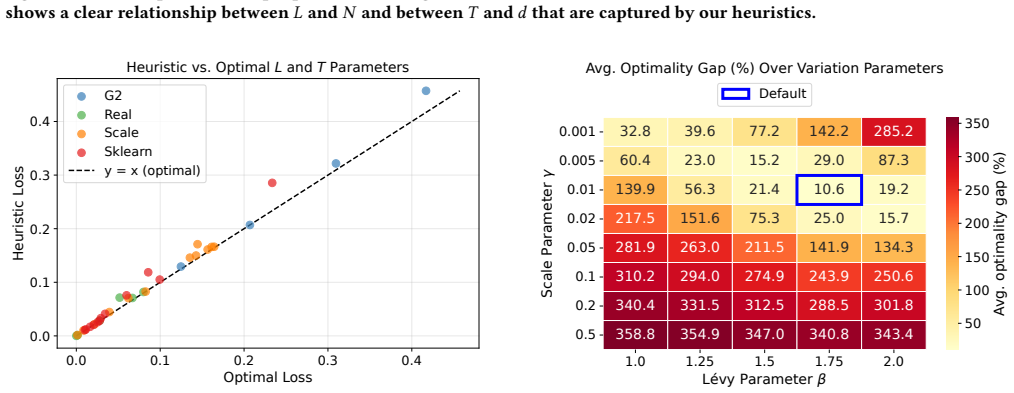
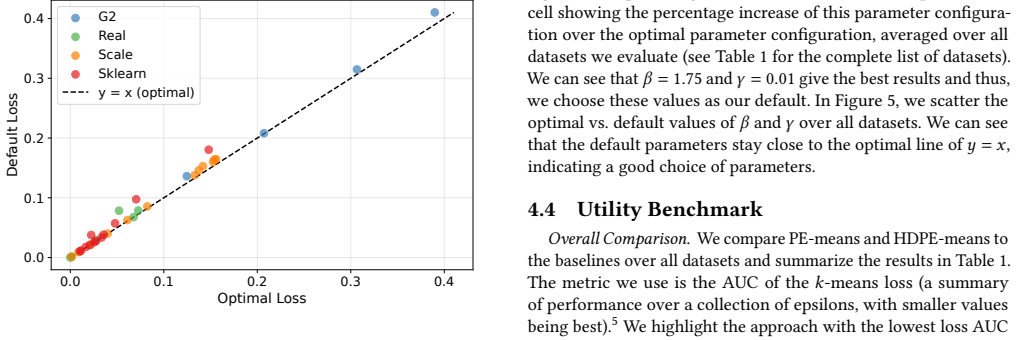
Significance. If the empirical gains are reproducible under the protocol described in the full manuscript, the work provides a concrete utility improvement for a core DP primitive. The constant-sensitivity histogram plus evolutionary operators constitute a clean algorithmic contribution that sidesteps a known sensitivity bottleneck; the absence of free parameters in the core sensitivity argument is a strength.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript and for recommending acceptance. We are pleased that the constant-sensitivity histogram approach and the empirical improvements were viewed as strengths.
Circularity Check
No significant circularity
full rationale
The paper presents PE-means as an algorithmic adaptation of private evolution to k-means, with the 26% improvement stated as an empirical experimental outcome rather than a derived quantity. No equations, derivations, or load-bearing steps are described that reduce the result to a fitted parameter, self-citation chain, or input by construction. The private histogram (constant sensitivity) and new evolutionary operators are independent contributions, and the approach is self-contained against external benchmarks without internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Maria-Florina Balcan, Travis Dick, Yingyu Liang, Wenlong Mou, and Hongyang Zhang. 2017. Differentially Private Clustering in High-Dimensional Euclidean Spaces. InProceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research), Vol. 70. PMLR, 322–331
2017
-
[2]
Borja Balle and Yu-Xiang Wang. 2018. Improving the Gaussian Mechanism for Differential Privacy: Analytical Calibration and Optimal Denoising. InPro- ceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research), Jennifer Dy and Andreas Krause (Eds.), Vol. 80. PMLR, 394–403. https://proceedings.mlr.press/v80/b...
2018
-
[3]
Avrim Blum, Cynthia Dwork, Frank McSherry, and Kobbi Nissim. 2005. Practical privacy: the SuLQ framework. InProceedings of the twenty-fourth ACM SIGMOD- SIGACT-SIGART symposium on Principles of database systems(New York, NY, USA, 2005-06-13)(PODS ’05). 128–138. https://doi.org/10.1145/1065167.1065184
-
[4]
Alisa Chang and Pritish Kamath. 2024. Practical differentially private clustering. https://research.google/blog/practical-differentially-private-clustering
2024
-
[5]
Abdulrahman Diaa, Thomas Humphries, and Florian Kerschbaum. 2025. {FastLloyd}: Federated, accurate, secure, and tunable {k-Means} clustering with differential privacy. In34th USENIX Security Symposium (USENIX Security 25). 2733–2752
2025
-
[6]
Jinshuo Dong, Aaron Roth, and Weijie J. Su. 2022. Gaussian Differential Privacy. Journal of the Royal Statistical Society Series B: Statistical Methodology84, 1 (02 2022), 3–37. https://doi.org/10.1111/rssb.12454
-
[7]
Dheeru Dua and Casey Graff. 2021. UCI Machine Learning Repository. http: //archive.ics.uci.edu/ml
2021
-
[8]
John Duchi, Shai Shalev-Shwartz, Yoram Singer, and Tushar Chandra. 2008. Effi- cient projections onto the l1-ball for learning in high dimensions. InProceedings of the 25th International Conference on Machine Learning(Helsinki, Finland) (ICML ’08). Association for Computing Machinery, New York, NY, USA, 272–279. https://doi.org/10.1145/1390156.1390191
-
[9]
Cynthia Dwork. 2011. A firm foundation for private data analysis.Commun. ACM54, 1 (2011), 86–95
2011
-
[10]
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. 2006. Cali- brating Noise to Sensitivity in Private Data Analysis. InTheory of Cryptography. 265–284
2006
-
[11]
Cynthia Dwork and Aaron Roth. 2014. The algorithmic foundations of differential privacy.Foundations and Trends in Theoretical Computer Science9, 3-4 (2014), 211–407. https://doi.org/10.1561/0400000042
-
[12]
Dan Feldman, Amos Fiat, Haim Kaplan, and Kobbi Nissim. 2009. Private coresets. InProceedings of the forty-first annual ACM symposium on Theory of comput- ing(New York, NY, USA, 2009-05-31)(STOC ’09). Association for Computing Machinery, 361–370. https://doi.org/10.1145/1536414.1536465
-
[13]
Dan Feldman, Chongyuan Xiang, Ruihao Zhu, and Daniela Rus. 2017. Coresets for differentially private k-means clustering and applications to privacy in mobile sensor networks. InProceedings of the 16th ACM/IEEE International Conference on Information Processing in Sensor Networks(Pittsburgh Pennsylvania, 2017-04-18). ACM, 3–15. https://doi.org/10.1145/3055...
-
[14]
Pasi Fränti and Sami Sieranoja. 2018. K-means properties on six clustering benchmark datasets. , 4743–4759 pages. http://cs.uef.fi/sipu/datasets/
2018
-
[15]
Badih Ghazi, Ravi Kumar, and Pasin Manurangsi. 2020. Differentially Private Clustering: Tight Approximation Ratios. InAdvances in Neural Information Processing Systems(2020), Vol. 33. Curran Associates, Inc., 4040–4054. https://proceedings.neurips.cc/paper_files/paper/2020/hash/ 299dc35e747eb77177d9cea10a802da2-Abstract.html
2020
-
[16]
Attri Ghosal, Arunima Nandy, Amit Kumar Das, Saptarsi Goswami, and Mri- tyunjoy Panday. 2020. A short review on different clustering techniques and their applications.Emerging Technology in Modelling and Graphics: Proceedings of IEM Graph 2018(2020), 69–83
2020
-
[17]
Naoise Holohan, Stefano Braghin, Pól Mac Aonghusa, and Killian Levacher. 2019. Diffprivlib: the IBM differential privacy library.ArXiv e-prints1907.02444 [cs.CR] (July 2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[18]
Thomas Humphries and Florian Kerschbaum. 2023. Differentially Private Simple Genetic Algorithms. InProceedings on Privacy Enhancing Technologies (PoPETs). 540–558. Issue 4. https://doi.org/10.56553/popets-2023-0124
-
[19]
Nguyen, and Thy D Nguyen
Matthew Jones, Huy L. Nguyen, and Thy D Nguyen. 2021. Differentially Private Clustering via Maximum Coverage.Proceedings of the AAAI Conference on Artificial Intelligence35, 13 (May 2021), 11555–11563. https://ojs.aaai.org/index. php/AAAI/article/view/17375
2021
-
[20]
Yann LeCun. 1998. The MNIST database of handwritten digits.http://yann. lecun. com/exdb/mnist/(1998)
1998
-
[21]
Zinan Lin, Tadas Baltrusaitis, and Sergey Yekhanin. 2025. Differentially Private Synthetic Data via APIs 3: Using Simulators Instead of Foundation Model. In ICLR 2025 Workshop on Navigating and Addressing Data Problems for Foundation Models
2025
-
[22]
Zinan Lin, Sivakanth Gopi, Janardhan Kulkarni, Harsha Nori, and Sergey Yekhanin. 2024. Differentially Private Synthetic Data via Foundation Model APIs 1: Images. InThe Twelfth International Conference on Learning Representa- tions
2024
-
[23]
S. Lloyd. 1982. Least squares quantization in PCM.IEEE Transactions on Informa- tion Theory28, 2 (March 1982), 129–137. https://doi.org/10.1109/tit.1982.1056489
-
[24]
Rosario Nunzio Mantegna. 1994. Fast, accurate algorithm for numerical simula- tion of Lévy stable stochastic processes.Phys. Rev. E49 (May 1994), 4677–4683. Issue 5. https://doi.org/10.1103/PhysRevE.49.4677
-
[25]
Frank D. McSherry. 2009. Privacy Integrated Queries: An Extensible Platform for Privacy-Preserving Data Analysis. InProceedings of the 2009 ACM SIGMOD International Conference on Management of Data (SIGMOD ’09). Association for Computing Machinery, New York, NY, USA, 19–30. https://doi.org/10.1145/ 1559845.1559850
-
[26]
Prashanth Mohan, Abhradeep Thakurta, Elaine Shi, Dawn Song, and David Culler. 2012. GUPT: privacy preserving data analysis made easy. InProceedings of the 2012 ACM SIGMOD International Conference on Management of Data. ACM, 349–360
2012
-
[27]
Kobbi Nissim, Sofya Raskhodnikova, and Adam Smith. 2007. Smooth sensitivity and sampling in private data analysis. InProceedings of the Thirty-Ninth Annual ACM Symposium on Theory of Computing (STOC ’07). Association for Computing Machinery, New York, NY, USA, 75–84. https://doi.org/10.1145/1250790.1250803
-
[28]
Kobbi Nissim and Uri Stemmer. 2018. Clustering Algorithms for the Centralized and Local Models. InProceedings of Algorithmic Learning Theory(2018-04-09). PMLR, 619–653. https://proceedings.mlr.press/v83/nissim18a.html
2018
-
[29]
2023.Random Cluster Generation (with Specified Degree of Separation)
Weiliang Qiu and Harry Joe. 2023.Random Cluster Generation (with Specified Degree of Separation). https://CRAN.R-project.org/package=clusterGeneration R package version 1.3.8
2023
-
[30]
Uri Stemmer and Haim Kaplan. 2018. Differentially Private k-Means with Con- stant Multiplicative Error. InAdvances in Neural Information Processing Systems (2018), Vol. 31. Curran Associates, Inc. https://papers.nips.cc/paper_files/paper/ 2018/hash/32b991e5d77ad140559ffb95522992d0-Abstract.html
2018
-
[31]
Dong Su, Jianneng Cao, Ninghui Li, Elisa Bertino, and Hongxia Jin. 2016. Differ- entially Private K-Means Clustering. InProceedings of the Sixth ACM Conference on Data and Application Security and Privacy(New Orleans, Louisiana, USA) (CODASPY ’16). 26–37. https://doi.org/10.1145/2857705.2857708
-
[32]
Toan Tran, Arturs Backurs, Zinan Lin, Victor Reis, Li Xiong, and Sergey Yekhanin
-
[33]
Differentially Private Synthetic Data via APIs 4: Tabular Data.arXiv preprint arXiv:2606.08259(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Chulin Xie, Zinan Lin, Arturs Backurs, Sivakanth Gopi, Da Yu, Huseyin A Inan, Harsha Nori, Haotian Jiang, Huishuai Zhang, Yin Tat Lee, Bo Li, and Sergey Yekhanin. 2024. Differentially Private Synthetic Data via Foundation Model APIs 2: Text. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research), ...
2024
-
[35]
Jun Zhang, Xiaokui Xiao, Yin Yang, Zhenjie Zhang, and Marianne Winslett
-
[36]
Association for Computing Machinery, New York, NY, USA
PrivGene: Differentially Private Model Fitting Using Genetic Algorithms. Association for Computing Machinery, New York, NY, USA. https://doi.org/10. 1145/2463676.2465330
-
[37]
Zhang, R
T. Zhang, R. Ramakrishnan, and M. Livny. 1997. BIRCH: A new data clustering algorithm and its applications.Data Mining and Knowledge Discovery1, 2 (1997), 141–182
1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.