Weak Critics Make Strong Learners: On-Policy Critique Distillation for Scalable Oversight
Pith reviewed 2026-06-28 21:53 UTC · model grok-4.3
The pith
A weak model used only as a critic can guide a stronger model to better use its own knowledge by supplying revision directions rather than answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
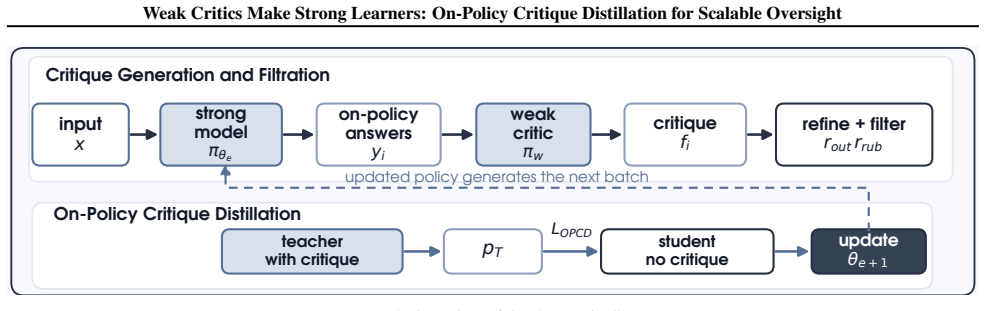
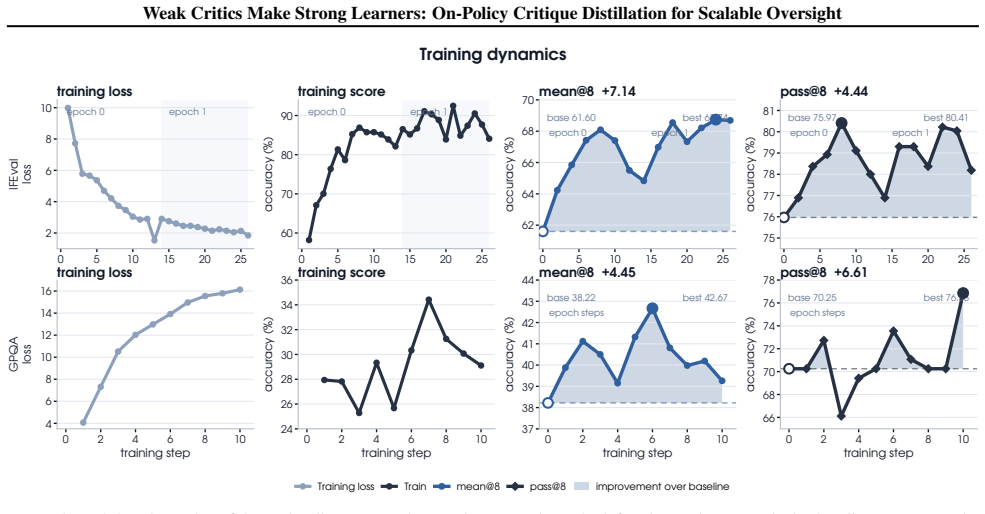
Weak critiques from a smaller model improve the outputs of a frozen stronger model at inference time, and the quality of those critiques determines how much improvement occurs. Progressive on-policy critique distillation filters the higher-quality critiques generated during training and distills the critic-guided revisions into the strong model using self-generated teacher signals, producing measurable gains on reasoning and alignment benchmarks that increase over successive epochs.
What carries the argument
progressive on-policy critique distillation (OPCD), which filters high-quality critiques and transfers critic-guided revision behavior into the strong model via adaptive self-teacher signals
If this is right
- Weak critiques improve the performance of frozen strong models at inference time.
- Higher critique quality produces larger gains in the strong model's outputs.
- OPCD enables the strong model to show progressive improvement across training epochs.
- The approach provides a concrete path toward scalable oversight that relies only on weak supervision.
Where Pith is reading between the lines
- If revision directions remain useful even when the weak model cannot judge correctness, the method could support oversight of models whose outputs exceed direct human evaluation.
- The same filtering and self-teacher mechanism might be applied iteratively within a single model family to create internal improvement loops at different capability levels.
- Partial directional signals may prove more robust than full but noisy judgments when aligning models on tasks where complete evaluation is itself hard.
Load-bearing premise
The weak model can reliably supply revision directions that are non-misleading and help the strong model access its own knowledge rather than requiring the weak model to solve the underlying task.
What would settle it
Running the weak critic's revision suggestions on held-out reasoning and alignment tasks and finding no consistent performance lift or an actual drop in the strong model's accuracy would falsify the central claim.
Figures

read the original abstract
As large language models become stronger, weak supervisors may fail to provide reliable labels, preferences, or final judgments for complex outputs, limiting both weak-to-strong generalization and scalable oversight. We study a more tractable form of weak supervision: using a weak model as a critic rather than as a labeler or judge. Instead of solving the task or selecting the correct answer, the weak critic only needs to provide a non-misleading revision direction that helps the strong model better use its own knowledge. We call this setting *weak-critic strong oversight*. We first show that weak critiques can improve frozen strong models at inference time, and that critique quality is key to this improvement. We then propose progressive on-policy critique distillation (**OPCD**), which filters high-quality critiques and distills critic-guided behavior into the strong model through adaptive self-teacher signals. Experiments on reasoning and alignment benchmarks show that our method improves strong models over training epochs, suggesting an effective path for scalable oversight with weak supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that weak models can serve as critics (providing non-misleading revision directions rather than labels or judgments) to improve stronger models in a 'weak-critic strong oversight' setting. It reports that weak critiques improve frozen strong models at inference time when critique quality is high, and introduces On-Policy Critique Distillation (OPCD) to filter high-quality critiques and distill critic-guided behavior into the strong model via adaptive self-teacher signals. Experiments on reasoning and alignment benchmarks are said to show improvements in strong models over training epochs.
Significance. If the OPCD filtering step can be implemented without ground-truth or strong-model oracle signals, the approach could offer a concrete mechanism for scalable oversight that leverages weak models without requiring them to solve tasks. The inference-time result on frozen models would be a useful finding if it generalizes. The paper does not report machine-checked proofs or parameter-free derivations.
major comments (2)
- [Abstract] Abstract: The OPCD description states that the method 'filters high-quality critiques and distills critic-guided behavior into the strong model through adaptive self-teacher signals,' yet supplies no criteria for determining critique quality. If quality filtering relies on ground-truth labels (standard for reasoning benchmarks), the training loop has oracle access that the weak-critic premise is intended to avoid; this directly affects whether the reported epoch-wise gains can be attributed to weak supervision.
- [Abstract] Abstract (empirical claims): The abstract reports that 'experiments on reasoning and alignment benchmarks show that our method improves strong models over training epochs' but provides no information on experimental controls, baseline comparisons, critique filtering implementation, or statistical significance. These omissions are load-bearing because the central claim of effective weak-critic distillation rests on the empirical results.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback on the abstract. We address the two major comments point-by-point below, clarifying the OPCD filtering mechanism and experimental details while proposing targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The OPCD description states that the method 'filters high-quality critiques and distills critic-guided behavior into the strong model through adaptive self-teacher signals,' yet supplies no criteria for determining critique quality. If quality filtering relies on ground-truth labels (standard for reasoning benchmarks), the training loop has oracle access that the weak-critic premise is intended to avoid; this directly affects whether the reported epoch-wise gains can be attributed to weak supervision.
Authors: The filtering criteria in OPCD rely exclusively on adaptive self-teacher signals: a critique is retained only if the strong model's subsequent on-policy response shows measurable improvement according to the model's own internal consistency or self-evaluation metrics, without any ground-truth labels or external oracles. This is formalized in Section 3.2 and Algorithm 1 of the manuscript. The premise of weak-critic oversight is preserved because the weak model supplies only revision directions and the selection signal is generated on-policy by the strong model itself. We will revise the abstract to explicitly state that filtering uses self-teacher signals rather than ground-truth. revision: yes
-
Referee: [Abstract] Abstract (empirical claims): The abstract reports that 'experiments on reasoning and alignment benchmarks show that our method improves strong models over training epochs' but provides no information on experimental controls, baseline comparisons, critique filtering implementation, or statistical significance. These omissions are load-bearing because the central claim of effective weak-critic distillation rests on the empirical results.
Authors: The abstract is intentionally concise per venue norms, but the full manuscript (Sections 4 and 5) specifies: (i) controls including frozen strong-model baselines and standard supervised fine-tuning without critiques; (ii) critique filtering implemented via the on-policy self-teacher procedure described above; (iii) multiple reasoning (e.g., GSM8K, MATH) and alignment benchmarks with epoch-wise curves; and (iv) statistical significance via paired t-tests and bootstrap confidence intervals. We will expand the abstract by one sentence to note the on-policy, oracle-free nature of the distillation and the inclusion of these controls. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks
full rationale
The paper proposes an empirical method (OPCD) and reports performance improvements on reasoning and alignment benchmarks. No mathematical derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps are present in the provided text. The central claims are externally falsifiable via benchmark results rather than reducing to self-referential definitions or inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abdin, M., Aneja, J., Behl, H., Bubeck, S., Eldan, R., Gunasekar, S., Harrison, M., Hewett, R. J., Javaheripi, M., Kauffmann, P., et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Concrete Problems in AI Safety
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schul- man, J., and Mané, D. Concrete problems in AI safety. arXiv preprint arXiv:1606.06565,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2408.11791 , year =
Ankner, Z., Paul, M., Cui, B., Chang, J. D., and Am- manabrolu, P. Critique-out-Loud reward models.arXiv preprint arXiv:2408.11791,
-
[4]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Art of Problem Solving. 2024 aime i problems and so- lutions. https://artofproblemsolving.com/ wiki/index.php/2024_AIME_I, 2024a. Ac- cessed: 2026-05-24. Art of Problem Solving. 2024 aime ii problems and so- 8 Weak Critics Make Strong Learners: On-Policy Critique Distillation for Scalable Oversight lutions. https://artofproblemsolving.com/ wiki/index.php/...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
arXiv preprint arXiv:2312.09390 , year =
Burns, C., Izmailov, P., Kirchner, J. H., Baker, B., Gao, L., Aschenbrenner, L., Chen, Y ., Ecoffet, A., Joglekar, M., Leike, J., et al. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision.arXiv preprint arXiv:2312.09390,
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capa- bility in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Ding, Z., Wang, Y ., Xiao, T., Wang, H., Jiang, C., and Ding, N. W2S-AlignTree: Weak-to-strong inference- time alignment for large language models via monte carlo tree search.arXiv preprint arXiv:2511.11518,
-
[8]
MiniLLM: On-Policy Distillation of Large Language Models
Gu, Y ., Dong, L., Wei, F., and Huang, M. Minillm: Knowl- edge distillation of large language models.arXiv preprint arXiv:2306.08543,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Irving, G., Christiano, P., and Amodei, D. AI safety via debate.arXiv preprint arXiv:1805.00899,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2508.14313 , year =
Jin, C., Zhou, Y ., Zhang, Q., Peng, H., Zhang, D., Dong, Z., Pavone, M., Han, L., Hong, Z.-W., Che, T., et al. Your re- ward function for rl is your best prm for search: Unifying rl and search-based tts.arXiv preprint arXiv:2508.14313,
-
[11]
Jin, C., Wu, R., Che, T., Zhang, Q., Peng, H., Zhao, J., Wang, Z., Wei, W., Han, L., Zhang, Z., et al. Reason- ing over precedents alongside statutes: Case-augmented deliberative alignment for llm safety.arXiv preprint arXiv:2601.08000,
-
[12]
arXiv preprint arXiv:2402.06782 , year=
Khan, A., Hughes, J., Valentine, D., Ruis, L., Sachan, K., Radhakrishnan, A., Grefenstette, E., Bowman, S. R., Rocktäschel, T., and Perez, E. Debating with more persua- sive llms leads to more truthful answers.arXiv preprint arXiv:2402.06782,
-
[13]
H., Chen, Y ., Edwards, H., Leike, J., McAleese, N., and Burda, Y
Kirchner, J. H., Chen, Y ., Edwards, H., Leike, J., McAleese, N., and Burda, Y . Prover-verifier games improve legibility of LLM outputs.arXiv preprint arXiv:2407.13692,
-
[14]
Training Language Models to Self-Correct via Reinforcement Learning
Kumar, A., Zhuang, V ., Agarwal, R., Su, Y ., Co-Reyes, J. D., Singh, A., Baumli, K., Iqbal, S., Bishop, C., Roelofs, R., et al. Training language models to self-correct via reinforcement learning.arXiv preprint arXiv:2409.12917,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
McAleese, N., Pokorny, R. M., Ceron Uribe, J. F., Nitishin- skaya, E., Trebacz, M., and Leike, J. LLM critics help catch LLM bugs.arXiv preprint arXiv:2407.00215,
-
[16]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y ., Dirani, J., Michael, J., and Bowman, S. R. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Self-critiquing models for assisting human evaluators
Saunders, W., Yeh, C., Wu, J., Bills, S., Ouyang, L., Ward, J., and Leike, J. Self-critiquing models for assisting human evaluators.arXiv preprint arXiv:2206.05802,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
- [19]
-
[20]
arXiv preprint arXiv:2506.10139 , year=
Wen, J., Ankner, Z., Somani, A., Hase, P., Marks, S., Goldman-Wetzler, J., Petrini, L., Sleight, H., Burns, C., He, H., Feng, S., Perez, E., and Leike, J. Unsuper- vised elicitation of language models.arXiv preprint arXiv:2506.10139,
-
[21]
arXiv preprint arXiv:2407.19594 , year =
Wu, T., Yuan, W., Golovneva, O., Xu, J., Tian, Y ., Jiao, J., Weston, J., and Sukhbaatar, S. Meta-rewarding language models: Self-improving alignment with LLM-as-a-Meta- Judge.arXiv preprint arXiv:2407.19594,
-
[22]
Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing
URLhttps://arxiv.org/abs/2406.08464. Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Yang, W., Shen, S., Shen, G., Gong, W., Yao, Y ., and Lin, Y . Super(ficial)-alignment: Strong models may deceive weak models in weak-to-strong generalizat...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Self-Rewarding Language Models
Yuan, W., Pang, R. Y ., Cho, K., Sukhbaatar, S., Xu, J., and Weston, J. Self-rewarding language models.arXiv preprint arXiv:2401.10020,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Instruction-Following Evaluation for Large Language Models
Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y ., Zhou, D., and Hou, L. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.