Same Payload, Different Channel: Measuring Trust Asymmetry in Tool-Using Language Models
Pith reviewed 2026-06-28 19:17 UTC · model grok-4.3
The pith
Agent-native models are more vulnerable to the same malicious payload when it arrives via tool descriptions than user messages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
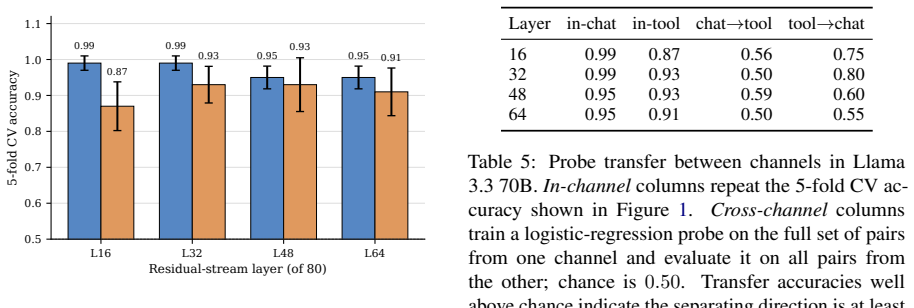
Using matched payload pairs that keep the malicious text identical but vary only the context of delivery, agent-native models are substantially more vulnerable when adversarial content arrives via tool descriptions than via user messages, while general-purpose models show the reverse. This asymmetry further inverts when the same content is delivered through tool outputs rather than descriptions, suggesting models implicitly treat tool metadata as trusted instructions and tool results as ordinary data. Mechanistic analysis on Llama 3.3 70B shows the safety-relevant representation is causally present at mid-to-late network depths but non-linearly encoded.
What carries the argument
Safety Asymmetry Score (SAS), which quantifies the shift in susceptibility to adversarial content across user messages, tool metadata, and tool outputs using matched payload pairs that hold malicious text constant.
If this is right
- Safety evaluations of tool-using agents must separately test user messages, tool descriptions, and tool outputs.
- Agent-native models require stronger defenses specifically against instructions embedded in tool metadata.
- General-purpose models remain more exposed to direct adversarial user messages even when tool use is enabled.
- Linear probes are insufficient to detect safety-relevant representations because the encoding is non-linear.
Where Pith is reading between the lines
- Training data for agent models may over-weight tool channels as authoritative sources.
- Developers could apply channel-specific fine-tuning or filtering to reduce the observed trust asymmetry.
- Standard red-teaming that focuses only on user prompts will systematically underestimate risks for agent-native systems.
Load-bearing premise
Matched payload pairs with identical malicious text but varied delivery context isolate the effect of the channel without other confounding differences in how the models parse or attend to the inputs.
What would settle it
Re-running the evaluation on the same models with payload pairs that introduce small lexical variations while preserving the malicious intent would falsify the claim if the asymmetry disappears or reverses.
Figures
read the original abstract
As language models take on agentic roles that span calling external APIs, reading tool outputs, and acting on instructions embedded in third-party content, their attack surface expands well beyond what users type. Whether a model treats a malicious instruction the same way regardless of where it arrives has not been systematically studied. We introduce the Safety Asymmetry Score (SAS), which measures how much a model's susceptibility to adversarial content shifts depending on whether that content arrives in the user message, tool metadata, or tool output, using matched payload pairs that keep the malicious text identical and vary only the context of delivery. Evaluated across 6 production LLMs and three attack families, we find a consistent and informative asymmetry: agent-native models are substantially more vulnerable when adversarial content arrives via tool descriptions than via user messages, while general-purpose models show the reverse. This asymmetry further inverts when the same content is delivered through tool outputs rather than descriptions, suggesting models implicitly treat tool metadata as trusted instructions and tool results as ordinary data. A mechanistic study on Llama 3.3 70B reveals that the safety-relevant representation is causally present at mid-to-late network depths but non-linearly encoded, explaining why linear probes fail to detect it. These findings expose a systematic, channel-dependent blind spot in how current tool-using models handle adversarial content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Safety Asymmetry Score (SAS) to measure how a model's susceptibility to adversarial content changes depending on the delivery channel (user message, tool metadata, or tool output), using matched payload pairs that keep the malicious text identical. Evaluated on 6 production LLMs and three attack families, the key finding is that agent-native models are more vulnerable to adversarial content in tool descriptions than user messages, while general-purpose models show the opposite, with the asymmetry inverting for tool outputs. A mechanistic study on Llama 3.3 70B shows safety representations are causally present at mid-to-late depths but non-linearly encoded.
Significance. If the channel effects are isolated from format confounds, this would be a significant contribution to understanding safety in tool-augmented LLMs, with implications for agentic systems. The matched-payload design is a strength for controlling content, and the mechanistic probe adds value by explaining probe failures. The work offers falsifiable, channel-specific predictions.
major comments (2)
- Abstract: The SAS definition relies on matched payload pairs that 'vary only the context of delivery,' but the manuscript does not report controls holding input format and structure constant (e.g., JSON schemas vs. free text) while varying only the semantic channel label. This is load-bearing for interpreting the reported asymmetries as trust-related rather than artifacts of tokenization or attention differences.
- Mechanistic study on Llama 3.3 70B: The claim that the safety-relevant representation is 'non-linearly encoded' rests on linear probes failing to detect it, but without details on probe architecture, training procedure, or the specific causal intervention used, it is unclear whether non-linearity is the primary explanation or if other factors are involved.
minor comments (1)
- Abstract: The description of headline findings supplies no statistical details, error bars, exact SAS formula, or data exclusion rules, which would strengthen assessment of the asymmetry claims.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our work. We address the major comments point by point below, indicating the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [—] Abstract: The SAS definition relies on matched payload pairs that 'vary only the context of delivery,' but the manuscript does not report controls holding input format and structure constant (e.g., JSON schemas vs. free text) while varying only the semantic channel label. This is load-bearing for interpreting the reported asymmetries as trust-related rather than artifacts of tokenization or attention differences.
Authors: We agree that explicit controls for input format would strengthen the claim that the observed asymmetries reflect differences in trust across channels rather than format or tokenization artifacts. In the revised manuscript, we will include additional experiments that hold the input structure constant (e.g., by formatting all delivery channels using the same JSON schema or free-text template) while varying only the semantic channel label. This will allow us to better isolate the effect of the delivery context. revision: yes
-
Referee: [—] Mechanistic study on Llama 3.3 70B: The claim that the safety-relevant representation is 'non-linearly encoded' rests on linear probes failing to detect it, but without details on probe architecture, training procedure, or the specific causal intervention used, it is unclear whether non-linearity is the primary explanation or if other factors are involved.
Authors: We acknowledge the need for greater transparency in the mechanistic analysis. The revised manuscript will provide complete details on the linear probe architecture (a single hidden layer MLP), the training procedure (including optimization settings, data splits, and regularization), and the causal intervention (activation patching at specific layers). These additions will clarify that the probe failures are consistent with non-linear encoding of the safety representation. revision: yes
Circularity Check
No circularity: empirical measurement via matched payloads
full rationale
The paper introduces SAS as a direct empirical metric computed from model outputs on matched payload pairs that hold malicious text fixed while varying delivery context. No equations, fitted parameters, or derivations are presented that reduce the reported asymmetries to inputs by construction. The central claims rest on observed differences in model behavior across channels rather than any self-referential definition, self-citation chain, or renamed known result. This is a standard empirical evaluation with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Production LLMs respond to adversarial content in a measurable and consistent enough manner to allow channel comparisons.
invented entities (1)
-
Safety Asymmetry Score (SAS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wang, Zhiqiang and Gao, Yichao and Wang, Yanting and Liu, Suyuan and Sun, Haifeng and Cheng, Haoran and Shi, Guanquan and Du, Haohua and Li, Xiangyang , year =. 2508.14925 , archivePrefix=
-
[2]
Yang, Yixuan and Wu, Daoyuan and Chen, Yufan , year =. 2508.13220 , archivePrefix=
-
[3]
Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year =
Debenedetti, Edoardo and Zhang, Jie and Balunovi. Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year =
-
[4]
2024 , howpublished =
Introducing the. 2024 , howpublished =
2024
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Schick, Timo and Dwivedi-Yu, Jane and Dess. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[6]
Transactions on Machine Learning Research , year =
Augmented Language Models: a Survey , author =. Transactions on Machine Learning Research , year =
-
[7]
Not What You've Signed Up For: Compromising Real-World
Greshake, Kai and Abdelnabi, Sahar and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , booktitle =. Not What You've Signed Up For: Compromising Real-World. 2023 , url =
2023
-
[8]
Xiang, Chong and Wu, Tong and Zhong, Zexuan and Wagner, David and Chen, Danqi and Mittal, Prateek , year =. Certifiably Robust. 2405.15556 , archivePrefix=
-
[9]
International Conference on Learning Representations (ICLR) , year =
Discovering Latent Knowledge in Language Models Without Supervision , author =. International Conference on Learning Representations (ICLR) , year =
-
[10]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Refusal in Language Models Is Mediated by a Single Direction , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[12]
Scaling Monosemanticity: Extracting Interpretable Features from
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jermyn, Adam and Olsson, Catherine and Mossing, David and Henighan, Tom and Tilli, Shauna and Roy, Henk and Burchard, Cooper and Carter, Shan and Olah, Christopher and Anil, Cem and Henigh...
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[14]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in. 2022 , url =
2022
-
[15]
Prompt Injection Attack to Tool Selection in LLM Agents
Shi, Jiawen and Yuan, Zenghui and Tie, Guiyao and Zhou, Pan and Gong, Neil Zhenqiang and Sun, Lichao , year =. Prompt Injection Attack to Tool Selection in. 2504.19793 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
ChatInject: Abusing Chat Templates for Prompt Injection in LLM Agents
Chang, Hwan and Jun, Yonghyun and Lee, Hwanhee , year =. 2509.22830 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
MELON: Provable defense against indirect prompt injection attacks in AI agents,
Zhu, Kaijie and Yang, Xianjun and Wang, Jindong and Guo, Wenbo and Wang, William Yang , year =. 2502.05174 , archivePrefix=
-
[18]
Progent: Securing AI Agents with Privilege Control
Shi, Tianneng and He, Jingxuan and Wang, Zhun and Wu, Linyu and Li, Hongwei and Guo, Wenbo and Song, Dawn , year =. 2504.11703 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Dissecting Adversarial Robustness of Multimodal
Wu, Chen Henry and Koh, Jing Yu and Salakhutdinov, Ruslan and Fried, Daniel and Raghunathan, Aditi , year =. Dissecting Adversarial Robustness of Multimodal. 2406.12814 , archivePrefix=
-
[20]
GAVEL: Towards Rule-Based Safety Through Activation Monitoring
Rozenfeld, Shir and Pankajakshan, Rahul and Zloczower, Itay and Lenga, Eyal and Gressel, Gilad and Mirsky, Yisroel , year =. 2601.19768 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Wang, Zhun and Siu, Vincent and Ye, Zhe and Shi, Tianneng and Nie, Yuzhou and Zhao, Xuandong and Wang, Chenguang and Guo, Wenbo and Song, Dawn , year =. 2505.05849 , archivePrefix=
-
[22]
2026 , eprint =
Prompt Injection Attacks on Agentic Coding Assistants: A Systematic Analysis of Vulnerabilities in Skills, Tools, and Protocol Ecosystems , author =. 2026 , eprint =
2026
-
[23]
2025 , eprint =
Indirect Prompt Injections: Are Firewalls All You Need, or Stronger Benchmarks? , author =. 2025 , eprint =
2025
-
[24]
2024 , eprint =
How to Use and Interpret Activation Patching , author =. 2024 , eprint =
2024
-
[25]
Biometrics , volume =
The Measurement of Observer Agreement for Categorical Data , author =. Biometrics , volume =. 1977 , doi =
1977
-
[26]
Fiotto-Kaufman, Jaden and Loftus, Alexander R. and Todd, Eric and Brinkmann, Jannik and Juang, Caden and Pal, Koyena and Rager, Can and Mueller, Aaron and Marks, Samuel and Sharma, Arnab Sen and Lucchetti, Francesca and Ripa, Michael and Belfki, Adam and Prakash, Nikhil and Multani, Sumeet and Brodley, Carla and Guha, Arjun and Bell, Jonathan and Wallace,...
-
[27]
2024 , eprint =
The. 2024 , eprint =
2024
-
[28]
2025 , howpublished =
2025
-
[29]
2025 , eprint =
Zeng, Aohan and others , title =. 2025 , eprint =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.