MemPro: Agentic Memory Systems as Evolvable Programs
Pith reviewed 2026-06-28 19:13 UTC · model grok-4.3
The pith
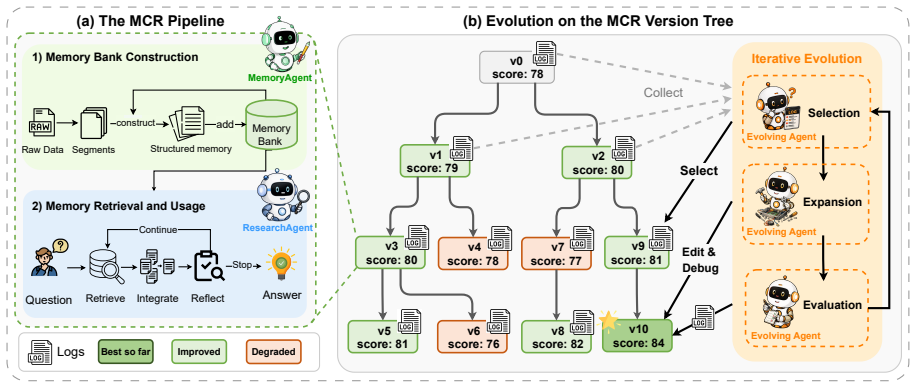
MemPro evolves entire memory construction-retrieval pipelines as programs in a version tree rather than fixing the pipeline after deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that representing the full memory construction-retrieval pipeline as an evolvable program inside a version tree, combined with an Evolving Agent that iteratively diagnoses recurring failure modes and applies failure-mode-guided edit-debug refinement, produces memory systems that continue to improve and outperform fixed-pipeline or prompt-only baselines on long-horizon question-answering tasks.
What carries the argument
A version tree of runnable memory-system implementations, with an Evolving Agent that selects versions and creates improved children through failure-mode-guided edit-debug refinement.
If this is right
- Performance keeps rising with additional evolution iterations instead of plateauing after the first changes.
- The method delivers better accuracy at comparable or lower inference cost than static or prompt-only alternatives.
- The same framework applies across heterogeneous benchmarks without task-specific manual pipeline redesign.
- Memory banks that change in scale or structure can be accommodated by evolving the surrounding pipeline rather than only the stored content.
Where Pith is reading between the lines
- The same version-tree approach could be applied to evolve other agent modules such as planning or tool-use components.
- If the diagnosis step works reliably, it reduces the need for human experts to hand-craft fixes for each new failure pattern.
- Deployed agents could run the evolution process continuously, allowing the memory system to adapt to distribution shifts over time.
Load-bearing premise
The Evolving Agent can reliably diagnose recurring failure modes from observed errors and generate effective child versions without external supervision or extra domain knowledge.
What would settle it
Running several evolution iterations on LongMemEval or HotpotQA and finding no consistent performance gains over the initial versions would falsify the central claim.
Figures












read the original abstract
Long-horizon autonomous agents require memory systems to retain historical information, track evolving states, and reuse relevant knowledge beyond finite context windows. Existing agentic memory systems typically follow a memory construction-retrieval (MCR) pipeline, but often adapt mainly the memory bank while keeping the surrounding pipeline fixed after deployment. This fixed-pipeline design struggles to handle heterogeneous task-specific failure modes and can become misaligned with memory banks that evolve in scale and structure over time. To address these limitations, we propose MemPro, a system-level evolution framework that treats the entire MCR pipeline as an evolvable program rather than adapting only the memory bank or prompt text. MemPro maintains a version tree of runnable memory-system implementations, where an Evolving Agent iteratively selects promising versions, diagnoses recurring failures, and creates improved child versions through failure-mode-guided edit-debug refinement. Experiments on LongMemEval, LoCoMo, HotpotQA, and NarrativeQA show that MemPro consistently outperforms strong static and prompt-level evolving baselines within a few iterations, continues to improve with evolution, and achieves a favorable performance-cost trade-off. Code is available at https://github.com/wanghai673/MemPro.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemPro, a system-level evolution framework that treats the full memory construction-retrieval (MCR) pipeline as an evolvable program. It maintains a version tree of runnable implementations; an LLM-based Evolving Agent iteratively selects versions, diagnoses recurring failure modes from observed errors, and generates improved child versions via failure-mode-guided edit-debug refinement. Experiments on LongMemEval, LoCoMo, HotpotQA, and NarrativeQA report consistent outperformance over static and prompt-level evolving baselines within a few iterations, continued gains with evolution, and a favorable performance-cost trade-off.
Significance. If the central mechanism holds, the work is significant because it shifts agentic memory from fixed-pipeline adaptation of only the memory bank to full-pipeline evolution, addressing misalignment as memory banks scale. The multi-benchmark evaluation and code release support reproducibility and allow direct testing of the evolution loop.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim that the Evolving Agent reliably diagnoses recurring failure modes from observed errors alone and produces functional child versions via unsupervised edit-debug refinement is load-bearing for attributing gains to the framework rather than iteration count or selection bias, yet no quantitative metrics (e.g., diagnosis accuracy, fraction of edits that measurably improve the parent) or ablations isolating the agent's contribution versus random or human-guided edits are reported.
- [§4.3] §4.3 (Results): The reported consistent outperformance 'within a few iterations' and 'continued improvement with evolution' on the four benchmarks cannot be evaluated for robustness without details on variance across runs, whether post-hoc version selection occurred, or controls showing that equivalent gains are not obtained by simply increasing the number of static iterations.
minor comments (2)
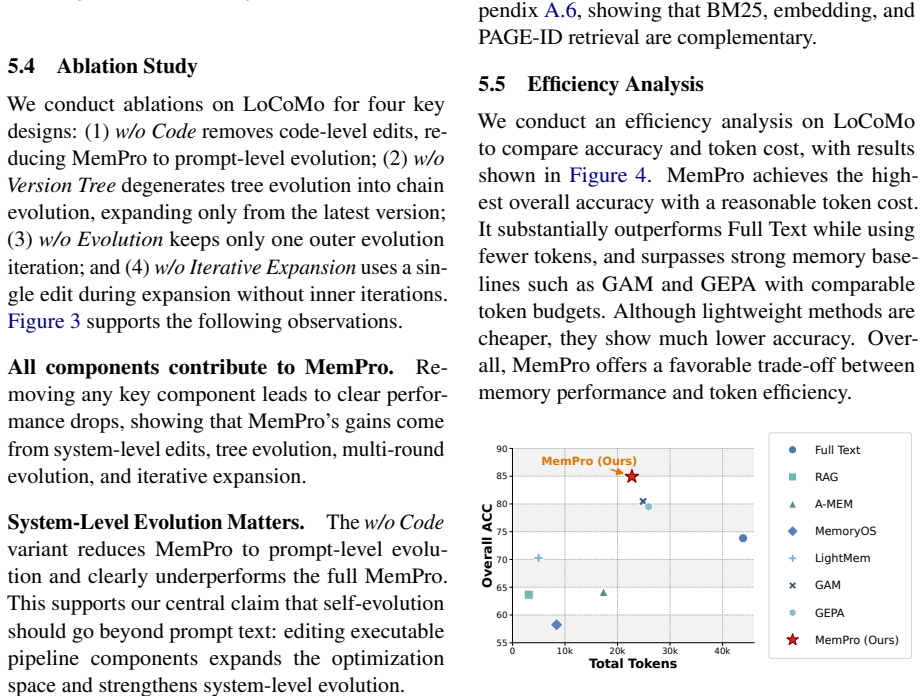
- The abstract states a 'favorable performance-cost trade-off' without defining the cost metric (tokens, API calls, or wall-clock time) or showing the corresponding curves.
- Notation for the version tree and edit operations is introduced without a formal definition or pseudocode in the main text; a small diagram or algorithm box would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects for strengthening the attribution of results to the proposed mechanism and for demonstrating robustness. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim that the Evolving Agent reliably diagnoses recurring failure modes from observed errors alone and produces functional child versions via unsupervised edit-debug refinement is load-bearing for attributing gains to the framework rather than iteration count or selection bias, yet no quantitative metrics (e.g., diagnosis accuracy, fraction of edits that measurably improve the parent) or ablations isolating the agent's contribution versus random or human-guided edits are reported.
Authors: We agree that the manuscript lacks explicit quantitative metrics on diagnosis accuracy and the success rate of edits, as well as ablations against random or human-guided baselines. While end-to-end gains are shown, these elements would better isolate the contribution of failure-mode-guided refinement. In the revision we will add (i) the fraction of child versions that measurably outperform their parents and (ii) an ablation replacing the Evolving Agent with random edit selection while keeping the version tree and iteration budget fixed. revision: yes
-
Referee: [§4.3] §4.3 (Results): The reported consistent outperformance 'within a few iterations' and 'continued improvement with evolution' on the four benchmarks cannot be evaluated for robustness without details on variance across runs, whether post-hoc version selection occurred, or controls showing that equivalent gains are not obtained by simply increasing the number of static iterations.
Authors: No post-hoc selection of final versions occurred; reported performance uses the versions chosen by the Evolving Agent. However, the current results are from single runs and do not include variance or a static-iteration control. In the revision we will report mean and standard deviation over multiple independent runs with different seeds. We will also add a control in which the strongest static baseline is executed for an equivalent number of iterations without the evolution loop to address the iteration-count concern. revision: yes
Circularity Check
No circularity; empirical claims rest on benchmark comparisons without self-referential reductions.
full rationale
The paper describes an empirical system (MemPro) that evolves MCR pipelines via an LLM-based agent and reports performance gains on LongMemEval, LoCoMo, HotpotQA, and NarrativeQA against static and prompt-level baselines. No equations, fitted parameters, or derivations appear in the abstract or described content. The central claim is an experimental outcome (consistent outperformance within iterations) rather than a mathematical result that reduces to its inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The work is self-contained against external benchmarks, warranting a score of 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LangMem SDK for Agent Long-Term Memory , year =
-
[2]
2024 , month = jul, url =
2024
-
[3]
MetaMem: Evolving Meta-Memory for Knowledge Utilization through Self-Reflective Symbolic Optimization , author=. arXiv preprint arXiv:2602.11182 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
Promptbreeder: Self-referential self-improvement via prompt evolution , author=. arXiv preprint arXiv:2309.16797 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Nature , volume=
Optimizing generative AI by backpropagating language model feedback , author=. Nature , volume=
-
[6]
gradient descent
Automatic prompt optimization with “gradient descent” and beam search , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[7]
International Conference on Learning Representations , volume=
Large language models as optimizers , author=. International Conference on Learning Representations , volume=
-
[8]
The eleventh international conference on learning representations , year=
Large language models are human-level prompt engineers , author=. The eleventh international conference on learning representations , year=
-
[9]
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Reasoningbank: Scaling agent self-evolving with reasoning memory , author=. arXiv preprint arXiv:2509.25140 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Remember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution
Remember me, refine me: A dynamic procedural memory framework for experience-driven agent evolution , author=. arXiv preprint arXiv:2512.10696 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Memp: Exploring Agent Procedural Memory
Memp: Exploring agent procedural memory , author=. arXiv preprint arXiv:2508.06433 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Agent workflow memory , author=. arXiv preprint arXiv:2409.07429 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Agentic memory: Learning unified long-term and short-term memory management for large language model agents , author=. arXiv preprint arXiv:2601.01885 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Mem-{\alpha}: Learning Memory Construction via Reinforcement Learning
Mem- \ alpha \ : Learning memory construction via reinforcement learning , author=. arXiv preprint arXiv:2509.25911 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
SimpleMem: Efficient Lifelong Memory for LLM Agents
SimpleMem: Efficient Lifelong Memory for LLM Agents , author=. arXiv preprint arXiv:2601.02553 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
2026 , eprint=
TiMem: Temporal-Hierarchical Memory Consolidation for Long-Horizon Conversational Agents , author=. 2026 , eprint=
2026
-
[17]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[18]
The Twelfth International Conference on Learning Representations , year=
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines , author=. The Twelfth International Conference on Learning Representations , year=
-
[19]
Demonstrate-Search-Predict: Composing Retrieval and Language Models for Knowledge-Intensive
Khattab, Omar and Santhanam, Keshav and Li, Xiang Lisa and Hall, David and Liang, Percy and Potts, Christopher and Zaharia, Matei , journal=. Demonstrate-Search-Predict: Composing Retrieval and Language Models for Knowledge-Intensive
-
[20]
ACM Transactions on Information Systems , volume=
A survey on the memory mechanism of large language model-based agents , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[21]
Frontiers of Computer Science , volume=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[22]
arXiv preprint arXiv:2303.08774 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Aaron Grattafiori and others , title =. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
An Yang and others , title =. arXiv preprint arXiv:2505.09388 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[26]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[27]
Narasimhan and Yuan Cao , title =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R. Narasimhan and Yuan Cao , title =. International Conference on Learning Representations (ICLR) , year =
-
[28]
Liu and Kevin Lin and John Hewitt and Ashwin Paranjape and Michele Bevilacqua and Fabio Petroni and Percy Liang , title =
Nelson F. Liu and Kevin Lin and John Hewitt and Ashwin Paranjape and Michele Bevilacqua and Fabio Petroni and Percy Liang , title =. Transactions of the Association for Computational Linguistics (TACL) , volume =. 2024 , url =
2024
-
[29]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
Yushi Bai and Xin Lv and Jiajie Zhang and Hongchang Lyu and Jiankai Tang and Zhidian Huang and Zhengxiao Du and Xiao Liu and Aohan Zeng and Lei Hou and Yuxiao Dong and Jie Tang and Juanzi Li , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[30]
2025 , month =
Kelly Hong and Anton Troynikov and Jeff Huber , title =. 2025 , month =
2025
-
[31]
Bernstein , title =
Joon Sung Park and Joseph O'Brien and Carrie Jun Cai and Meredith Ringel Morris and Percy Liang and Michael S. Bernstein , title =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , year =
-
[32]
MemoryBank: Enhancing Large Language Models with Long-Term Memory
Wanjun Zhong and Lianghong Guo and Qiqi Gao and He Ye and Yanlin Wang , title =. arXiv preprint arXiv:2305.10250 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
MemGPT: Towards LLMs as Operating Systems
Charles Packer and Sarah Wooders and Kevin Lin and Vivian Fang and Shishir G. Patil and Ion Stoica and Joseph E. Gonzalez , title =. arXiv preprint arXiv:2310.08560 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu and Zujie Liang and Kai Mei and Hang Gao and Juntao Tan and Yongfeng Zhang , title =. arXiv preprint arXiv:2502.12110 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara and Dev Khant and Saket Aryan and Taranjeet Singh and Deshraj Yadav , title =. arXiv preprint arXiv:2504.19413 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Memory os of ai agent , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[37]
LightMem: Lightweight and Efficient Memory-Augmented Generation
Lightmem: Lightweight and efficient memory-augmented generation , author=. arXiv preprint arXiv:2510.18866 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning , author=. arXiv preprint arXiv:2508.19828 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[40]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Expel: Llm agents are experiential learners , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[41]
arXiv preprint arXiv:2410.04444 , year=
G " odel agent: A self-referential agent framework for recursive self-improvement , author=. arXiv preprint arXiv:2410.04444 , year=
-
[42]
Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents
Darwin godel machine: Open-ended evolution of self-improving agents , author=. arXiv preprint arXiv:2505.22954 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
Jiahang Lin and Shichun Liu and Chengjun Pan and Lizhi Lin and Shihan Dou and Xuanjing Huang and Hang Yan and Zhenhua Han and Tao Gui , title =. arXiv preprint arXiv:2604.25850 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
arXiv preprint arXiv:2511.18423 , year=
General agentic memory via deep research , author=. arXiv preprint arXiv:2511.18423 , year=
-
[45]
Dimakis and Ion Stoica and Dan Klein and Matei Zaharia and Omar Khattab , title =
Lakshya A Agrawal and Shangyin Tan and Dilara Soylu and Noah Ziems and Rishi Khare and Krista Opsahl-Ong and Arnav Singhvi and Herumb Shandilya and Michael J Ryan and Meng Jiang and Christopher Potts and Koushik Sen and Alexandros G. Dimakis and Ion Stoica and Dan Klein and Matei Zaharia and Omar Khattab , title =. International Conference on Learning Rep...
-
[46]
arXiv preprint arXiv:2510.08191 , year=
Training-free group relative policy optimization , author=. arXiv preprint arXiv:2510.08191 , year=
-
[47]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
Adyasha Maharana and Dong-Ho Lee and Sergey Tulyakov and Mohit Bansal and Francesco Barbieri and Yuwei Fang , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[48]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu and Hongwei Wang and Wenhao Yu and Yuwei Zhang and Kai-Wei Chang and Dong Yu , title =. arXiv preprint arXiv:2410.10813 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Cohen and Ruslan Salakhutdinov and Christopher D
Zhilin Yang and Peng Qi and Saizheng Zhang and Yoshua Bengio and William W. Cohen and Ruslan Salakhutdinov and Christopher D. Manning , title =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , year =
2018
-
[50]
Tom. The. Transactions of the Association for Computational Linguistics , volume =
-
[51]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[52]
Dan Gusfield , title =. 1997
1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.