LinguIUTics at PsyDefDetect: Iterative Imbalance-Aware Fine-tuning of Qwen3-8B for Psychological Defense Mechanism Classification
Pith reviewed 2026-06-28 19:06 UTC · model grok-4.3
The pith
Fine-tuning Qwen3-8B with grouped cross-validation, minority augmentation and logit-bias post-processing reaches 0.3917 macro F1 on nine-class psychological defense detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By iteratively fine-tuning Qwen3-8B under imbalance-aware conditions and applying leakage-preventing grouped stratified cross-validation, minority-class round-robin lexical augmentation, and logit-bias-tuned ensemble post-processing, the method reaches a macro F1 of 0.3917 on the PsyDefDetect positive-class leaderboard, a 7.7-point absolute gain over the Ministral-8B baseline.
What carries the argument
QLoRA fine-tuning of Qwen3-8B combined with grouped stratified cross-validation, minority-class round-robin lexical augmentation, and logit bias tuning plus ensemble blending in post-processing.
Load-bearing premise
The post-processing pipeline with logit bias tuning and ensemble blending will reliably close the validation-to-leaderboard gap and improve minority-class recall without overfitting to the particular test distribution.
What would settle it
Running the identical fine-tuned model and post-processing parameters on a new conversational test set drawn from a different clinical source and finding that minority-class F1 drops below the level achieved by the fine-tuned model without post-processing.
Figures

read the original abstract
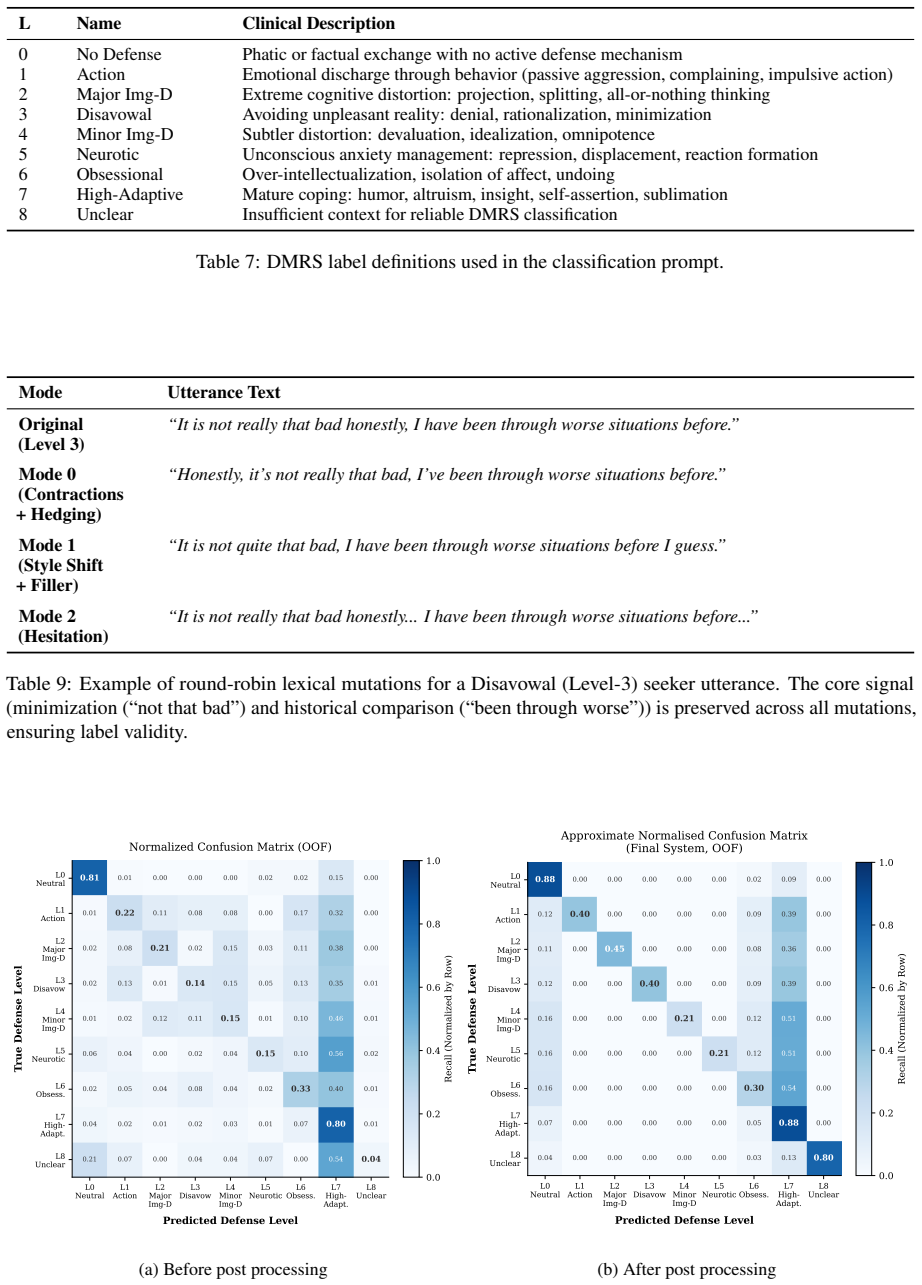
Detecting psychological defense mechanisms in conversational text remains a challenging clinical NLP problem. For the PsyDefDetect 2026 shared task (nine-class utterance classification evaluated via macro F1), our team LinguIUTics achieves a macro F1-score of 0.3917 on the official positive-class leaderboard, ranking 4th out of 21 registered teams and improving over the Ministral-8B task baseline (31.48 macro F1) by 7.7 absolute points (24.4 percent relative). BERT-family encoders and zero-shot LLMs proved ineffective on rare classes due to severe class imbalance, leading us to QLoRA fine-tuning of Qwen3-8B. We leverage three key strategies: grouped stratified cross-validation (preventing leakage), minority-class round-robin lexical augmentation, and a post-processing pipeline with logit bias tuning and ensemble blending. Together, these components close much of the validation-to-leaderboard gap and substantially improve minority-class recall, driving the critical "Unclear" class (Level 8) from near-zero performance to an F1 score of 0.797.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the LinguIUTics system submitted to the PsyDefDetect 2026 shared task on nine-class classification of psychological defense mechanisms from conversational text. The authors report a macro F1 of 0.3917 on the official positive-class leaderboard (4th of 21 teams), obtained via QLoRA fine-tuning of Qwen3-8B together with grouped stratified cross-validation, minority-class round-robin lexical augmentation, and a post-processing pipeline of logit bias tuning plus ensemble blending; this yields a 7.7-point absolute (24.4% relative) gain over the Ministral-8B baseline and raises the rare “Unclear” class F1 to 0.797.
Significance. If the leaderboard result is reproducible, the work supplies a concrete, engineering-oriented demonstration that parameter-efficient fine-tuning combined with imbalance-aware data augmentation and targeted post-processing can substantially lift minority-class recall in a clinical NLP shared task. The reported improvement on the most difficult class offers a practical reference point for other low-resource, imbalanced multi-class problems in psychological text analysis.
major comments (2)
- [Abstract] Abstract and the description of the three key strategies: the manuscript states that grouped stratified cross-validation, minority-class round-robin lexical augmentation, and the post-processing pipeline “drive the critical” gains, yet supplies no ablation tables, incremental addition experiments, or controlled comparisons that isolate the contribution of each component to the 7.7-point improvement. Without such evidence the attribution remains narrative.
- [Results] Results section: neither error bars from the grouped cross-validation folds nor any statistical significance test comparing the final system against the Ministral-8B baseline or against intermediate ablations are reported, leaving the reliability of the 0.3917 macro F1 and the per-class gains (especially the jump to 0.797 on the “Unclear” class) difficult to assess.
minor comments (2)
- The manuscript would benefit from an explicit table listing all hyper-parameters used for QLoRA (rank, alpha, dropout, learning rate, epochs, etc.) to support reproducibility.
- A short related-work paragraph situating the lexical augmentation technique against prior minority-class oversampling methods in clinical NLP would help readers place the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address each major comment below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and the description of the three key strategies: the manuscript states that grouped stratified cross-validation, minority-class round-robin lexical augmentation, and the post-processing pipeline “drive the critical” gains, yet supplies no ablation tables, incremental addition experiments, or controlled comparisons that isolate the contribution of each component to the 7.7-point improvement. Without such evidence the attribution remains narrative.
Authors: We agree that the current manuscript attributes performance gains to the three strategies without quantitative isolation of their effects. In the revision we will add a dedicated ablation subsection (and corresponding table) that starts from the base QLoRA fine-tuned Qwen3-8B and incrementally introduces grouped stratified cross-validation, minority-class round-robin lexical augmentation, and the logit-bias-plus-ensemble post-processing pipeline, reporting macro F1 and per-class F1 at each step on the validation folds. revision: yes
-
Referee: [Results] Results section: neither error bars from the grouped cross-validation folds nor any statistical significance test comparing the final system against the Ministral-8B baseline or against intermediate ablations are reported, leaving the reliability of the 0.3917 macro F1 and the per-class gains (especially the jump to 0.797 on the “Unclear” class) difficult to assess.
Authors: We concur that fold-level variability and formal significance testing are needed to substantiate the reported scores. In the revised results section we will report mean ± standard deviation across the grouped CV folds for all metrics and will add a statistical comparison (paired t-test on per-fold macro F1) between the final system and the Ministral-8B baseline, including the resulting p-value. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a standard shared-task system description that reports an empirical macro F1 of 0.3917 obtained via QLoRA fine-tuning, grouped CV, lexical augmentation, and post-processing on the PsyDefDetect test set. No equations, formal derivations, theorems, or parameter-fitting steps that could reduce a claimed prediction to its inputs by construction are present anywhere in the manuscript. The central result is an externally evaluated leaderboard score rather than a quantity computed from fitted parameters inside the paper, and no self-citation chains or ansatzes are invoked to justify any mathematical claim. The work is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Liu, Siyang and Zheng, Chujie and Demasi, Orianna and Sabour, Sahand and Li, Yu and Yu, Zhou and Jiang, Yong and Huang, Minlie. Towards Emotional Support Dialog Systems. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)....
-
[2]
You Never Know a Person, You Only Know Their Defenses: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
Na, Hongbin and Wang, Zimu and Chen, Zhaoming and Zhou, Peilin and Hua, Yining and Zhou, Grace Ziqi and Zhang, Haiyang and Shen, Tao and Wang, Wei and Torous, John and Ji, Shaoxiong and Chen, Ling. You Never Know a Person, You Only Know Their Defenses: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations. Findings of the Associ...
2026
-
[3]
Studying Defense Mechanisms in Psychotherapy using the Defense Mechanism Rating Scales , volume =
Perry, John and Henry, Melissa , year =. Studying Defense Mechanisms in Psychotherapy using the Defense Mechanism Rating Scales , volume =. Advances in Psychology , doi =
-
[4]
2021 , journal =
LoRA: Low-Rank Adaptation of Large Language Models , author =. 2021 , journal =
2021
-
[5]
2023 , journal =
QLoRA: Efficient Finetuning of Quantized LLMs , author =. 2023 , journal =
2023
-
[6]
2025 , eprint =
Qwen3 Technical Report , author =. 2025 , eprint =
2025
-
[7]
, journal=
He, Haibo and Garcia, Edwardo A. , journal=. Learning from Imbalanced Data , year=
-
[8]
EDA : Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
Wei, Jason and Zou, Kai. EDA : Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1670
-
[9]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month = jun, year =
Christian Szegedy and Vincent Vanhoucke and Sergey Ioffe and Jonathon Shlens and Zbigniew Wojna , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month = jun, year =
-
[10]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , month = oct, year =
Tsung-Yi Lin and Priya Goyal and Ross Girshick and Kaiming He and Piotr Dollár , title =. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , month = oct, year =
-
[11]
International Conference on Learning Representations , year =
Long-tail learning via logit adjustment , author =. International Conference on Learning Representations , year =
-
[12]
M ental BERT : Publicly Available Pretrained Language Models for Mental Healthcare
Ji, Shaoxiong and Zhang, Tianlin and Ansari, Luna and Fu, Jie and Tiwari, Prayag and Cambria, Erik. M ental BERT : Publicly Available Pretrained Language Models for Mental Healthcare. Proceedings of the Thirteenth Language Resources and Evaluation Conference. 2022
2022
-
[13]
2021 , url =
Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen , booktitle =. 2021 , url =
2021
-
[14]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov , year =. 1907.11692 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[15]
Jacob Devlin and Ming-Wei Chang and Kenton Lee and Kristina Toutanova , title =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , month = jun, year =
2019
-
[16]
Overview of the PsyDefDetect Shared Task at BioNLP 2026: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
Na, Hongbin and Wang, Zimu and Chen, Zhaoming and Hua, Yining and Gao, Rena and Yang, Kailai and Chen, Ling and Wang, Wei and Ji, Shaoxiong and Torous, John and Ananiadou, Sophia. Overview of the PsyDefDetect Shared Task at BioNLP 2026: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations. Proceedings of the 25th Workshop on Bi...
2026
-
[17]
In: Findings of the Association for Computational Linguistics: ACL 2025
Na, Hongbin and Hua, Yining and Wang, Zimu and Shen, Tao and Yu, Beibei and Wang, Lilin and Wang, Wei and Torous, John and Chen, Ling. A Survey of Large Language Models in Psychotherapy: Current Landscape and Future Directions. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.385
-
[18]
Addressing Data Scarcity in Bangla Fake News Detection: An LLM-Based Dataset Augmentation Approach
Addressing Data Scarcity in Bangla Fake News Detection: An LLM-Based Dataset Augmentation Approach , author=. arXiv preprint arXiv:2605.01292 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.