SKIP: Sparse Keyframe Interpolation Paradigm for Efficient Embodied World Models
Pith reviewed 2026-06-28 18:42 UTC · model grok-4.3
The pith
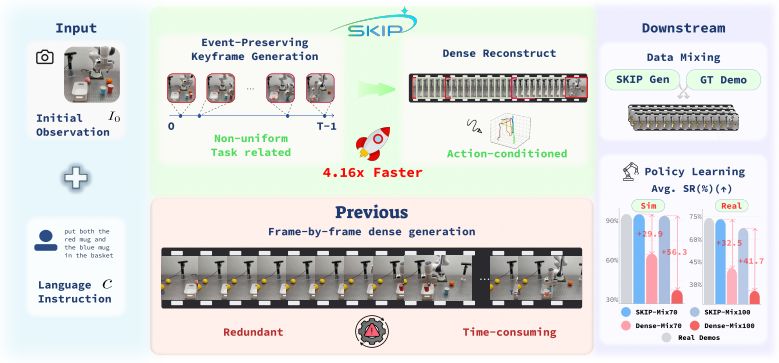
SKIP generates dense embodied world model rollouts 4.16 times faster than dense baselines by generating only task-relevant keyframes and interpolating the rest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
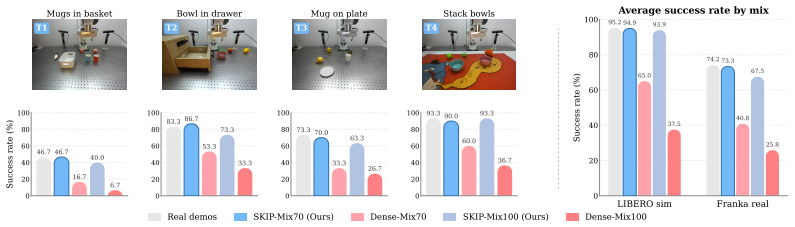
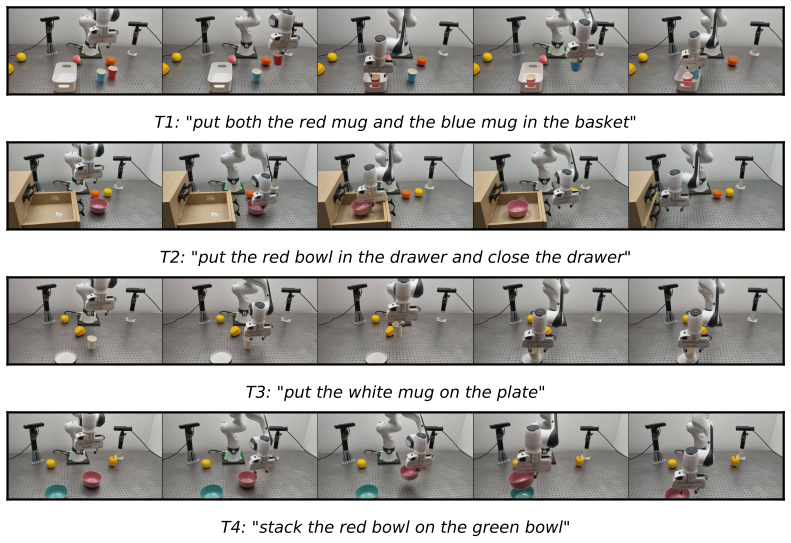
SKIP identifies task-relevant keyframes by leveraging robot-aware multimodal features, synthesizes only these keyframes with a sparse video diffusion model, and then uses a learned gap predictor plus an action-conditioned interpolator to reconstruct the missing intervals according to the robot actions. On LIBERO this produces dense rollouts 4.16 times faster than a dense baseline, improves visual fidelity, and reduces aggregate FVD by 89.0 percent. When SKIP-generated videos fully replace real demonstrations, policy success drops only 1.3 percentage points in simulation and 6.7 points on the real robot, while fully dense generation drops 48 to 58 points.
What carries the argument
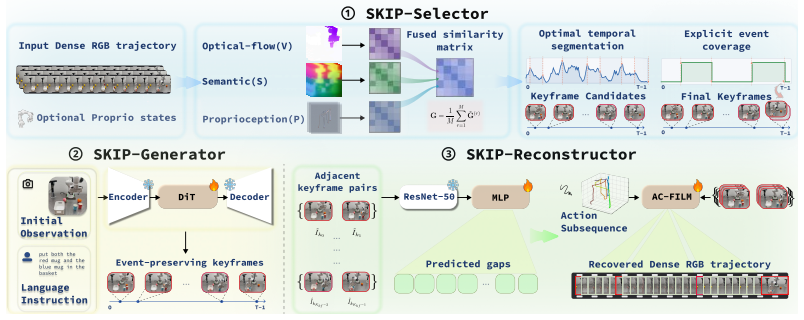
Sparse Keyframe Interpolation Paradigm (SKIP): robot-aware multimodal keyframe selection, followed by sparse video diffusion generation of selected frames, then action-conditioned interpolation to fill gaps.
If this is right
- World-model rollouts become fast enough for longer horizons without losing policy-relevant events.
- Generated videos serve as near-substitutes for real demonstrations in policy training.
- Visual quality of rollouts improves while Fréchet Video Distance drops sharply.
- Frame-by-frame dense generation is shown to destroy policy utility when used as training data.
Where Pith is reading between the lines
- The same sparse-to-dense pattern could be tested on non-robot video prediction tasks where events are unevenly spaced.
- If keyframe selection is made task-agnostic, SKIP might reduce the need for task-specific real data collection in new environments.
- Combining SKIP with existing action models could enable online world-model planning at higher frame rates.
- Failure modes would likely appear first in tasks where critical events are visually subtle rather than distinct actions.
Load-bearing premise
Task-relevant keyframes can be identified reliably from multimodal features without omitting critical manipulation events, and the gap predictor plus action-conditioned interpolator can reconstruct intervals that still contain the information policies need.
What would settle it
Run policy training on a held-out LIBERO task or real-robot setup where SKIP videos fully replace real demonstrations and measure whether success rate falls by more than 10 percentage points relative to real data.
Figures
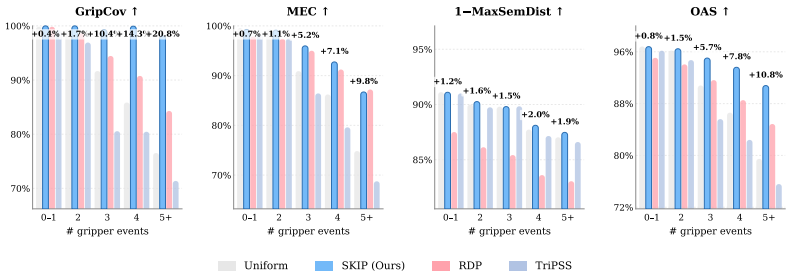

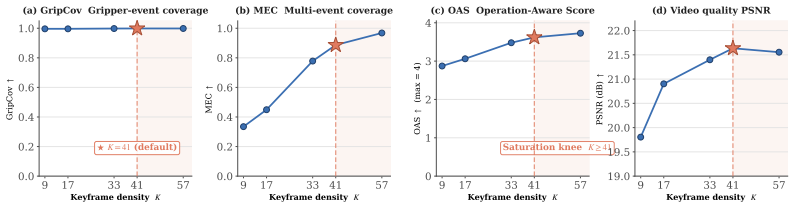



read the original abstract
Embodied world models have emerged as a promising paradigm in robotics by predicting how robot actions affect the surrounding scene. However, the rollout inference remains computationally expensive in pixel space, as long-horizon manipulation videos typically have to be generated frame by frame. This cost cannot be easily reduced by indiscriminately dropping frames, since downstream policies rely on complete preservation of sparse task-relevant events such as approach, contact, grasp, and release. To address this challenge, we propose Sparse Keyframe Interpolation Paradigm (SKIP), an event-preserving sparse-to-dense framework that avoids dense frame-by-frame generation. SKIP first identifies task-relevant keyframes by leveraging robot-aware multimodal features. It then synthesizes only these keyframes with a sparse video diffusion model. A learned gap predictor and an action-conditioned interpolator subsequently reconstruct the missing intervals according to the robot actions. On LIBERO, SKIP generates dense rollouts $4.16\times$ faster than a dense baseline while improving visual fidelity and reducing aggregate FVD by $89.0\%$. Importantly, SKIP-generated videos are effective policy-training data. Even when they fully replace real demonstrations, $\pi_{0.5}$ success drops only $1.3$ pp in LIBERO simulation and $6.7$ pp on the real robot, whereas fully dense frame-by-frame generation collapses by $48$ to $58$ pp.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SKIP, a sparse-to-dense framework for embodied world models that first selects task-relevant keyframes via robot-aware multimodal features, generates those keyframes with a sparse video diffusion model, and then reconstructs intervening frames using a learned gap predictor and action-conditioned interpolator. On LIBERO it reports 4.16× faster dense rollout generation, an 89% aggregate FVD reduction, and that SKIP-generated videos can fully replace real demonstrations for training π0.5 with only 1.3 pp success drop in simulation and 6.7 pp on the real robot, while dense frame-by-frame generation causes 48–58 pp drops.
Significance. If the policy-replacement result holds under rigorous controls, the work would demonstrate a practical route to reducing the inference cost of pixel-space world models while preserving downstream utility, which could improve scalability of long-horizon planning and synthetic data generation in robotics.
major comments (2)
- [Abstract / §4] Abstract / §4 (policy experiments): The central claim that SKIP videos can replace real demonstrations with only 1.3 pp (sim) / 6.7 pp (real) success drop—while dense generation collapses 48–58 pp—depends on the keyframe selector never omitting task-critical events and the interpolator recovering policy-relevant dynamics. No ablation on missed events, no quantitative comparison of contact forces or grasp stability between SKIP intervals and ground truth, and no sensitivity analysis on the multimodal feature threshold are reported, leaving the attribution of the performance gap unverified.
- [§3.1] §3.1 (keyframe identification): The robot-aware multimodal keyframe selector is presented at a high level without the explicit selection criterion, decision rule, or failure-mode analysis (e.g., fraction of trajectories where a grasp or release is missed). This directly affects reproducibility and the reliability of the “event-preserving” premise that underpins both the speed and policy claims.
minor comments (1)
- [Figures 3–5] Figure captions and axis labels in the LIBERO rollout comparisons could more explicitly state whether the dense baseline uses the identical diffusion backbone or a different architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the policy replacement claims and the reproducibility of the keyframe selector. We address each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract / §4 (policy experiments): The central claim that SKIP videos can replace real demonstrations with only 1.3 pp (sim) / 6.7 pp (real) success drop—while dense generation collapses 48–58 pp—depends on the keyframe selector never omitting task-critical events and the interpolator recovering policy-relevant dynamics. No ablation on missed events, no quantitative comparison of contact forces or grasp stability between SKIP intervals and ground truth, and no sensitivity analysis on the multimodal feature threshold are reported, leaving the attribution of the performance gap unverified.
Authors: The substantial gap between SKIP (1.3/6.7 pp drop) and dense generation (48–58 pp drop) provides direct empirical support that critical events are preserved for policy training. We agree that a sensitivity analysis on the multimodal threshold would further strengthen attribution and will add this in the revision. However, our experimental setup records only visual observations and does not include force or tactile sensors, so quantitative contact-force or grasp-stability comparisons are not feasible without new hardware instrumentation. revision: partial
-
Referee: [§3.1] §3.1 (keyframe identification): The robot-aware multimodal keyframe selector is presented at a high level without the explicit selection criterion, decision rule, or failure-mode analysis (e.g., fraction of trajectories where a grasp or release is missed). This directly affects reproducibility and the reliability of the “event-preserving” premise that underpins both the speed and policy claims.
Authors: We will revise §3.1 to provide the explicit selection criterion, the decision rule (including the multimodal similarity threshold), and failure-mode statistics such as the fraction of trajectories in which grasp or release events are missed. This will directly address reproducibility concerns. revision: yes
- Quantitative comparison of contact forces or grasp stability between SKIP intervals and ground truth, as the experiments use only visual observations without force or tactile measurements.
Circularity Check
No circularity; empirical engineering contribution with independent experimental validation
full rationale
The paper proposes SKIP as a practical sparse-to-dense video generation framework for embodied world models, relying on keyframe selection from multimodal features, a gap predictor, and action-conditioned interpolation. No equations, derivations, or first-principles claims appear in the abstract or described content that reduce outputs to inputs by construction. Performance metrics (4.16× speedup, FVD reduction, policy success rates) are presented as empirical results on the LIBERO benchmark rather than fitted quantities renamed as predictions. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work are invoked as load-bearing. The central claims rest on experimental comparisons (SKIP vs. dense baselines) that remain falsifiable outside any internal fitting, satisfying the criteria for a self-contained non-circular contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. Robotics: Science and Systems XIX, 2023
2023
-
[2]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. Openvla: An open-source vision-language-action model. In Conference on Robot Learning, pages 2679–2713. PMLR, 2025
2025
-
[4]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fu- sai, M. Y . Galliker, et al.π0.5: a vision-language-action model with open-world generalization. In9th Annual Conference on Robot Learning, 2025
2025
-
[7]
P. Li, Y . Chen, H. Wu, X. Ma, X. Wu, Y . Huang, L. Wang, T. Kong, and T. Tan. Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models. Advances in Neural Information Processing Systems, 38:63635–63673, 2026
2026
-
[8]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[9]
Brooks, B
T. Brooks, B. Peebles, C. Holmes, W. DePue, Y . Guo, L. Jing, D. Schnurr, J. Taylor, T. Luhman, E. Luhman, C. Ng, R. Wang, and A. Ramesh. Video generation models as world simulators
-
[10]
URL https://openai.com/research/video-generation-models-as-world- simulators
-
[11]
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y . Yang, W. Hong, X. Zhang, G. Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. InInternational Conference on Learning Representations, volume 2025, pages 83048–83077, 2025
2025
-
[12]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Gygli, H
M. Gygli, H. Grabner, H. Riemenschneider, and L. Van Gool. Creating summaries from user videos. InEuropean conference on computer vision, pages 505–520. Springer, 2014
2014
-
[14]
K. Zhou, Y . Qiao, and T. Xiang. Deep reinforcement learning for unsupervised video summa- rization with diversity-representativeness reward. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[15]
T. Lin, X. Liu, X. Li, E. Ding, and S. Wen. Bmn: Boundary-matching network for temporal action proposal generation. InProceedings of the IEEE/CVF international conference on computer vision, pages 3889–3898, 2019
2019
-
[16]
Zhang, J
C.-L. Zhang, J. Wu, and Y . Li. Actionformer: Localizing moments of actions with transformers. InEuropean Conference on Computer Vision, pages 492–510. Springer, 2022. 9
2022
-
[17]
C. Zhao, M. Liu, W. Wang, W. Chen, F. Wang, H. Chen, B. Zhang, and C. Shen. Moviedreamer: Hierarchical generation for coherent long visual sequences. InInternational Conference on Learning Representations, volume 2025, pages 50060–50090, 2025
2025
- [18]
-
[19]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36: 44776–44791, 2023
2023
-
[20]
Hafner, T
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination. InInternational Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=S1lOTC4tDS
2020
-
[21]
Hafner, J
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
2025
-
[22]
Hansen, H
N. Hansen, H. Su, and X. Wang. Td-mpc2: Scalable, robust world models for continuous control. InInternational Conference on Learning Representations, volume 2024, pages 47376–47405, 2024
2024
-
[23]
Bardes, Q
A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. Rabbat, Y . LeCun, M. Assran, and N. Ballas. Revisiting feature prediction for learning visual representations from video.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/ forum?id=QaCCuDfBk2. Featured Certification
2024
-
[24]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
F. Zhu, H. Wu, S. Guo, Y . Liu, C. Cheang, and T. Kong. Irasim: A fine-grained world model for robot manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9834–9844, 2025
2025
-
[26]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. InConference on Robot Learning, pages 1820–1864. PMLR, 2023
2023
- [27]
-
[28]
Y . Wang, Z. Xian, F. Chen, T.-H. Wang, Y . Wang, K. Fragkiadaki, Z. Erickson, D. Held, and C. Gan. Robogen: towards unleashing infinite data for automated robot learning via generative simulation. InProceedings of the 41st International Conference on Machine Learning, pages 51936–51983, 2024
2024
-
[29]
J. Bae, I. Hwang, Y .-Y . Lee, Z. Guo, J. Liu, Y . Ben-Shabat, Y . M. Kim, and M. Kapadia. Less is more: Improving motion diffusion models with sparse keyframes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11069–11078, 2025
2025
- [30]
-
[31]
L. Yang, Y . Bai, G. Eskandar, F. Shen, M. Altillawi, D. Chen, S. Majumder, Z. Liu, G. Kutyniok, and A. Valada. Roboenvision: A long-horizon video generation model for multi-task robot manipulation. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 21281–21288. IEEE, 2025. 10
2025
-
[32]
Jiang, D
H. Jiang, D. Sun, V . Jampani, M.-H. Yang, E. Learned-Miller, and J. Kautz. Super slomo: High quality estimation of multiple intermediate frames for video interpolation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 9000–9008, 2018
2018
-
[33]
Huang, T
Z. Huang, T. Zhang, W. Heng, B. Shi, and S. Zhou. Real-time intermediate flow estimation for video frame interpolation. InEuropean conference on computer vision, pages 624–642. Springer, 2022
2022
-
[34]
Li, Z.-L
Z. Li, Z.-L. Zhu, L.-H. Han, Q. Hou, C.-L. Guo, and M.-M. Cheng. Amt: All-pairs multi-field transforms for efficient frame interpolation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9801–9810, 2023
2023
-
[35]
J. Oh, X. Guo, H. Lee, R. L. Lewis, and S. Singh. Action-conditional video prediction using deep networks in atari games.Advances in neural information processing systems, 28, 2015
2015
-
[36]
Finn and S
C. Finn and S. Levine. Deep visual foresight for planning robot motion. In2017 IEEE international conference on robotics and automation (ICRA), pages 2786–2793. IEEE, 2017
2017
-
[37]
Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control
F. Ebert, C. Finn, S. Dasari, A. Xie, A. Lee, and S. Levine. Visual foresight: Model-based deep reinforcement learning for vision-based robotic control.arXiv preprint arXiv:1812.00568, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
O. Sim´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, et al. Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research Journal, 2024
2024
-
[40]
Sch¨olkopf, A
B. Sch¨olkopf, A. Smola, and A. F. Atiya. Learning with kernels: Support vector machines, regularization, optimization, and beyond.IEEE Transactions on Information Theory, 16(3): 781–781, 2005
2005
-
[41]
Potapov, M
D. Potapov, M. Douze, Z. Harchaoui, and C. Schmid. Category-specific video summarization. InEuropean conference on computer vision, pages 540–555. Springer, 2014
2014
-
[42]
F. Reda, J. Kontkanen, E. Tabellion, D. Sun, C. Pantofaru, and B. Curless. Film: Frame interpolation for large motion. InEuropean Conference on Computer Vision, pages 250–266. Springer, 2022
2022
-
[43]
Perez, F
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[44]
D. H. Douglas and T. K. Peucker. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature.Cartographica: the international journal for geographic information and geovisualization, 10(2):112–122, 1973
1973
- [45]
-
[46]
Otani, Y
M. Otani, Y . Nakashima, E. Rahtu, and J. Heikkila. Rethinking the evaluation of video summaries. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7596–7604, 2019
2019
-
[47]
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 11
2004
-
[48]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[49]
Towards Accurate Generative Models of Video: A New Metric & Challenges
T. Unterthiner, S. Van Steenkiste, K. Kurach, R. Marinier, M. Michalski, and S. Gelly. To- wards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[50]
A. Ng, M. Jordan, and Y . Weiss. On spectral clustering: Analysis and an algorithm.Advances in neural information processing systems, 14, 2001
2001
-
[51]
J. H. Ward Jr. Hierarchical grouping to optimize an objective function.Journal of the American statistical association, 58(301):236–244, 1963
1963
-
[52]
R. P. Adams and D. J. MacKay. Bayesian online changepoint detection.arXiv preprint arXiv:0710.3742, 2007
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[53]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770– 778, 2016
2016
-
[54]
H. Xu, J. Zhang, J. Cai, H. Rezatofighi, F. Yu, D. Tao, and A. Geiger. Unifying flow, stereo and depth estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11): 13941–13958, 2023
2023
-
[55]
put both the red mug and the blue mug in the basket
H. Wang, A. Kl ¨aser, C. Schmid, and C.-L. Liu. Dense trajectories and motion boundary descriptors for action recognition.International journal of computer vision, 103(1):60–79, 2013. 12 Appendix overview.Appendix A details the datasets, splits, baselines, and evaluation metrics. Ap- pendix B reports hardware, training hyperparameters, and feature-stream ...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.