Local Diagnostics of Continuous Normalizing Flow for Out-of-Distribution Detection
Pith reviewed 2026-07-02 22:41 UTC · model grok-4.3
The pith
Lagrangian sub-flows isolate components in continuous normalizing flows so that velocity-field signals can detect out-of-distribution samples such as mispronounced phonemes more reliably than likelihood.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
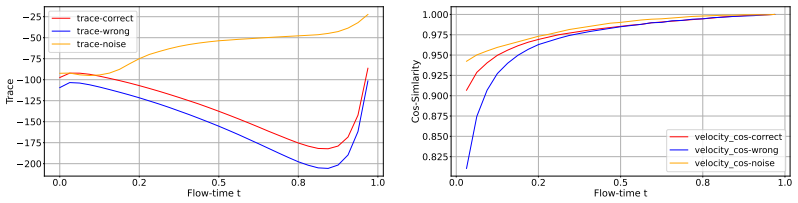
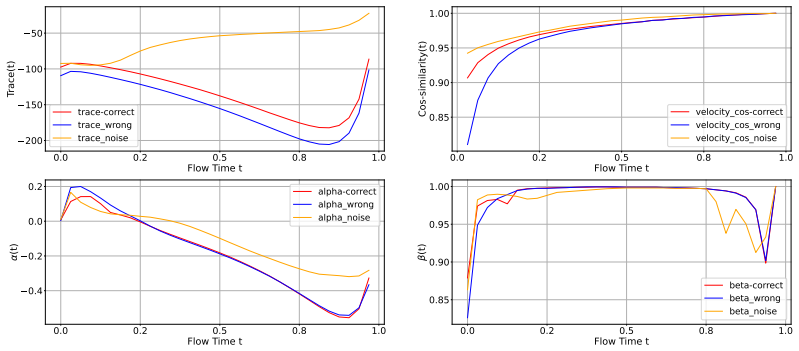
Using continuous normalizing flows the authors develop a Lagrangian sub-flow framework to isolate and estimate densities for relevant components in high-dimensional data subspaces by conditioning on the remaining components. They identify that the likelihood paradox arises from an inductive bias toward low-level details and propose geometric diagnostic signals based on the velocity field over the sub-flow trajectory. These signals enable new metrics that outperform likelihood for zero-shot phoneme-level mispronunciation detection on a real-world benchmark.
What carries the argument
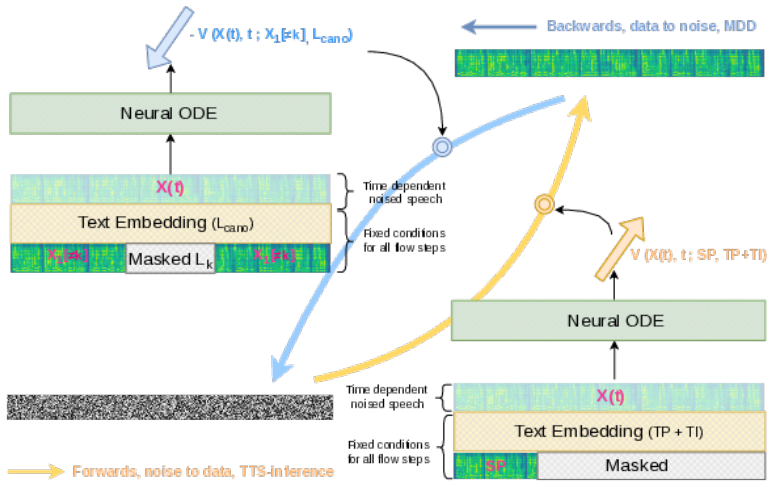
The Lagrangian sub-flow (LSF) framework, which isolates relevant components for density estimation using the rest as context, together with geometric diagnostic signals extracted from the velocity field along the sub-flow trajectory.
If this is right
- Metrics derived from velocity-field signals enable zero-shot detection of phoneme mispronunciations without additional training.
- The same geometric diagnostics address the likelihood paradox by shifting attention from global likelihood to local trajectory properties.
- The LSF framework applies to any target observations embedded in a subspace of high-dimensional data.
- CNF-based speech synthesis models can incorporate these local diagnostics to flag OOD inputs at inference time.
Where Pith is reading between the lines
- The same velocity signals could be tested on OOD detection tasks outside speech, such as image or audio anomalies, to check whether the geometric approach travels.
- If the sub-flow isolation succeeds, it might allow detectors to be built from a single trained generative model rather than requiring separate OOD training data.
- The diagnostics might be inserted directly into the sampling loop of a speech synthesizer to reject or correct generations that deviate from expected trajectories.
Load-bearing premise
The likelihood paradox in CNFs is produced by inductive bias that favors low-level structural details, and the Lagrangian sub-flow can reliably separate the relevant components by treating the others as context.
What would settle it
If the velocity-based metrics do not outperform likelihood-based methods when both are evaluated on the same real-world mispronunciation detection benchmark, the claimed superiority would be falsified.
Figures


read the original abstract
We address the problem of out-of-distribution (OOD) detection for target observations embedded in a subspace of the high dimensional data space. Using continuous normalizing flows (CNFs), we propose a Lagrangian sub-flow (LSF) framework designed to isolate and estimate the density for the relevant components in the representation and using the remaining components as context. Through experimentation with models for speech synthesis, we show that CNFs, similarly to other deep generative models (DGMs), are susceptible to the "likelihood paradox", where high likelihood is erroneously assigned to OOD samples. This is attributed to the inductive bias of DGMs that prioritize low-level structural details over high-level semantic coherence. To mitigate this phenomenon, we propose a number of geometric diagnostic signals based on the velocity field over the sub-flow trajectory. Based on these signals, we design metrics for the challenging task of zero-shot phoneme-level mispronunciation detection. Finally, we demonstrate the superiority of these metrics compared to likelihood-based methods on a real-world mispronunciation detection benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Lagrangian sub-flow (LSF) framework within continuous normalizing flows (CNFs) to isolate and density-estimate relevant components of high-dimensional observations while treating the remainder as context, with the goal of mitigating the likelihood paradox in out-of-distribution detection. The work attributes this paradox to inductive biases in deep generative models that favor low-level structure over semantic coherence, introduces geometric diagnostic signals derived from the velocity field along sub-flow trajectories, and applies the resulting metrics to zero-shot phoneme-level mispronunciation detection, claiming superiority over likelihood-based baselines on a real-world benchmark.
Significance. If the LSF construction and velocity-field diagnostics prove robust, the approach could offer a principled geometric alternative to likelihood-based OOD detection in speech synthesis models, addressing a documented limitation of DGMs. The explicit focus on zero-shot phoneme-level tasks and the attempt to derive metrics from sub-flow trajectories represent a targeted contribution, though the strength depends on whether the unsupervised partitioning step is shown to be independent of domain-specific assumptions.
major comments (2)
- [Abstract] Abstract (final two paragraphs): The central claim that LSF isolates relevant high-level semantic components for zero-shot phoneme-level detection without labels or boundaries rests on an unstated mechanism for unsupervised partitioning. No derivation is supplied showing that the velocity-field diagnostics remain informative once the sub-flow split itself must be learned without supervision; if the split implicitly relies on speech-specific features or alignment, the superiority over likelihood methods is not established by the geometric signals alone.
- [Abstract] Abstract (paragraph on likelihood paradox): The attribution of the likelihood paradox specifically to inductive bias prioritizing low-level structural details is presented without a supporting argument or counter-example demonstrating that the proposed diagnostics correct for this bias rather than for other CNF pathologies (e.g., trajectory length or integration error). This is load-bearing for the metric design.
minor comments (1)
- The abstract refers to “models for speech synthesis” and a “real-world mispronunciation detection benchmark” without naming the specific architectures or dataset; these details should be supplied in the introduction or experimental section for reproducibility.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments on our manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (final two paragraphs): The central claim that LSF isolates relevant high-level semantic components for zero-shot phoneme-level detection without labels or boundaries rests on an unstated mechanism for unsupervised partitioning. No derivation is supplied showing that the velocity-field diagnostics remain informative once the sub-flow split itself must be learned without supervision; if the split implicitly relies on speech-specific features or alignment, the superiority over likelihood methods is not established by the geometric signals alone.
Authors: The LSF construction learns the sub-flow partition in a fully unsupervised manner by optimizing the CNF velocity field to isolate components with high semantic relevance in the data-driven trajectory, without labels, boundaries, or speech-specific alignments; this is formalized in Section 3. The velocity diagnostics are then evaluated along the resulting trajectories. We agree the abstract would benefit from a brief clarification of this unsupervised mechanism to emphasize generality, and will revise accordingly. revision: partial
-
Referee: [Abstract] Abstract (paragraph on likelihood paradox): The attribution of the likelihood paradox specifically to inductive bias prioritizing low-level structural details is presented without a supporting argument or counter-example demonstrating that the proposed diagnostics correct for this bias rather than for other CNF pathologies (e.g., trajectory length or integration error). This is load-bearing for the metric design.
Authors: The main text (Section 4.2 and associated experiments) supplies the requested supporting arguments and controlled counter-examples, where trajectory length and integration error are held fixed while the paradox persists under likelihood but is mitigated by the velocity-based metrics. We will revise the abstract to reference these results explicitly. revision: yes
Circularity Check
No circularity; derivation self-contained against external benchmarks
full rationale
The provided abstract and context contain no equations, parameter-fitting procedures, or self-citations that reduce any claimed prediction or diagnostic to its own inputs by construction. The LSF framework and velocity-field metrics are introduced as proposals to address the likelihood paradox, with superiority demonstrated on an external benchmark; no load-bearing step is shown to be a renaming, ansatz smuggling, or fitted-input prediction. This matches the default expectation that most papers exhibit no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Do deep generative models know what they don’t know?
E. Nalisnick, A. Matsukawa, Y . W. Teh, D. Gorur, and B. Lakshminarayanan, “Do deep generative models know what they don’t know?” InInternational Conference on Learning Representations, 2019
2019
-
[2]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” MIT, Tech. Rep., 2009
2009
-
[3]
Reading digits in nat- ural images with unsupervised feature learning,
Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y . Ng, “Reading digits in nat- ural images with unsupervised feature learning,” inNIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011
2011
-
[4]
Likelihood ratios for out-of-distribution detection,
J. Ren et al., “Likelihood ratios for out-of-distribution detection,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
2019
-
[5]
Why normalizing flows fail to detect out-of- distribution data,
P. Kirichenko, P. Izmailov, and A. G. Wilson, “Why normalizing flows fail to detect out-of- distribution data,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 20 549–20 558
2020
-
[6]
Input complexity and out-of-distribution detection with likelihood-based generative models,
J. Serrà, D. Álvarez, K. Vicent, C. Martínez, A. Gauchia, and J. Martí, “Input complexity and out-of-distribution detection with likelihood-based generative models,” inInternational Conference on Learning Representations (ICLR), 2020
2020
-
[7]
A geometric explanation of the likelihood ood detection paradox,
C. Le Lan and L. Dinh, “A geometric explanation of the likelihood ood detection paradox,” in arXiv preprint arXiv:2003.06413, 2021
-
[8]
Likelihood regret: An out-of-distribution detection score for variational autoencoder,
Z. Xiao, Q. Yan, and Y . Amit, “Likelihood regret: An out-of-distribution detection score for variational autoencoder,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 2051–2062
2020
-
[9]
Multi-scale score matching for out-of-distribution detection,
A. Jolicoeur-Martineau, R. Piché-Taillefer, R. T. des Combes, and H. Larochelle, “Multi-scale score matching for out-of-distribution detection,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[10]
Diffguard: Semantic mismatch-guided out-of- distribution detection using pre-trained diffusion models,
R. Gao, C. Zhao, L. Hong, and Q. Xu, “Diffguard: Semantic mismatch-guided out-of- distribution detection using pre-trained diffusion models,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 1579–1589
2023
-
[11]
Latent ordinary differential equations for irregularly-sampled time series,
Y . Rubanova, R. T. Chen, and D. K. Duvenaud, “Latent ordinary differential equations for irregularly-sampled time series,” inAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[12]
Density of states estimation for out-of-distribution detection,
W. Morningstar, C. Ham, V . Ghassemi, B. Alizadeh, A. Chu, and B. Lakshminarayanan, “Density of states estimation for out-of-distribution detection,” inProceedings of the 24th International Conference on Artificial Intelligence and Statistics (AISTATS), ser. Proceedings of Machine Learning Research, vol. 130, PMLR, 2021, pp. 1981–1989. 10
2021
-
[13]
Neural ordinary differential equations,
R. T. Q. Chen, Y . Rubanova, J. Bettencourt, and D. Duvenaud, “Neural ordinary differential equations,” inNeurIPS, 2018, pp. 6572–6583
2018
-
[14]
A stochastic estimator of the trace of the influence matrix for laplacian smooth- ing splines,
M. Hutchinson, “A stochastic estimator of the trace of the influence matrix for laplacian smooth- ing splines,”Communication in Statistics- Simulation and Computation, vol. 18, pp. 1059– 1076, Jan. 1989
1989
-
[15]
Grathwohl, R
W. Grathwohl, R. T. Q. Chen, J. Bettencourt, I. Sutskever, and D. Duvenaud,FFJORD: Free-form continuous dynamics for scalable reversible generative models, 2018
2018
-
[16]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”ArXiv, vol. abs/2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Eskenazi, J
M. Eskenazi, J. Mostow, and D. Graff,The CMU Kids Corpus LDC97S63. Web Download. Philadelphia: Linguistic Data Consortium, accessed 03/07/2023, 1997
2023
-
[18]
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
Y . Chen et al., “F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,” arXiv preprint arXiv:2410.06885, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
The kaldi speech recognition toolkit,
D. Povey et al., “The kaldi speech recognition toolkit,” inIEEE ASRU, IEEE Signal Processing Society, Dec. 2011
2011
-
[20]
Child speech assessment through large language model speech synthesis: Preliminary results,
X. Cao, Z. Fan, T. Svendsen, and G. Salvi, “Child speech assessment through large language model speech synthesis: Preliminary results,” in2025 IEEE 35th International Workshop on Machine Learning for Signal Processing (MLSP), 2025, pp. 1–6
2025
-
[21]
An Analysis of Goodness of Pronunciation for Child Speech,
X. Cao, Z. Fan, T. Svendsen, and G. Salvi, “An Analysis of Goodness of Pronunciation for Child Speech,” inInterspeech, 2023, pp. 4613–4617
2023
-
[22]
Segmentation-free goodness of pronunciation,
X. Cao, Z. Fan, T. Svendsen, and G. Salvi, “Segmentation-free goodness of pronunciation,” IEEE Transactions on Audio, Speech and Language Processing, vol. 34, pp. 796–807, 2026
2026
-
[23]
Do deep generative models know what they don’t know?
E. Nalisnick, A. Matsukawa, Y . W. Teh, D. Gorur, and B. Lakshminarayanan, “Do deep generative models know what they don’t know?” InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[24]
V oicebox: Text-guided multilingual universal speech generation at scale,
M. Le et al., “V oicebox: Text-guided multilingual universal speech generation at scale,” in NeurIPS, 2023
2023
-
[25]
S. E. Eskimez et al.,E2 TTS: Embarrassingly easy fully non-autoregressive zero-shot TTS, 2024
2024
-
[26]
Attention is all you need,
A. Vaswani et al., “Attention is all you need,” inNeurIPS, vol. 30, 2017
2017
-
[27]
Maskgit: Masked generative image transformer,
H. Chang, H. Zhang, L. Jiang, C. Liu, and W. T. Freeman, “Maskgit: Masked generative image transformer,” inThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2022
2022
-
[28]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
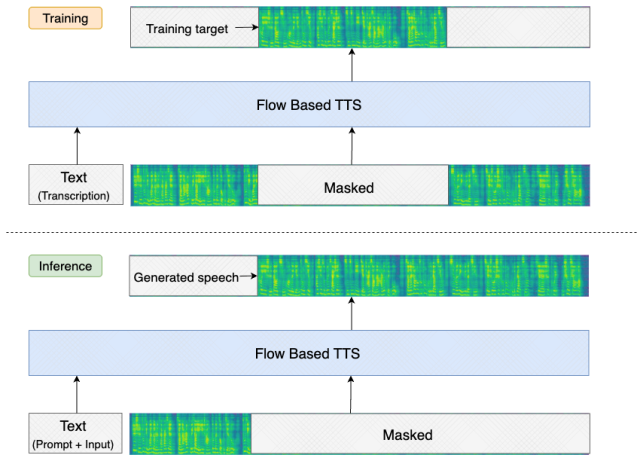
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova,Bert: Pre-training of deep bidirectional transformers for language understanding, cite arxiv:1810.04805Comment: 13 pages, 2018. 11 Figure 3: The masking and filling paradigm for flow-based TTS A Speech Synthesis Using Continuous Normalizing Flows Text-to-speech (TTS) systems use generative speech models for...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
Temporal segmentation: We obtain K ordered segments x1 ={x 1[1], ..., x1[K]} where x1[k]∈R Lk×M denotes the “ k”th segment of length Lk, using techniques such as monotonic-alignment search or forced alignment
-
[30]
Whitening: The assessment speech x1 is inversely filtered by running the CNF backwards in time from t= 1→0 driven by the conditional vector field vk(x, t;C k). The conditions Ck ={C text ←L cano, Csp ←x 1[̸=k]} are rendered for the “k”th phoneme where x1[̸=k] denotes the original speech x1 whose segment x1[k] is replaced by special mask tokens of the same length
-
[31]
sampling- comparing
Projecting the sub-flow: We focus on the local whitening trajectory xk(t) and analyze the sub-flow dynamics for MDD using local kinematic diagnostic signals. It should be noted that the masking applied to the target speech in the second step is critical because we should regard only x1[̸=k] as necessary context such that the semantic of masking is consist...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.