SkillPager: Query-Adaptive Intra-Skill Navigation via Semantic Node Retrieval
Pith reviewed 2026-06-28 17:53 UTC · model grok-4.3
The pith
SkillPager parses skill documents into typed semantic nodes and selects a query-adaptive subset via MMR to deliver near-full-document context sufficiency at 47% lower token cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
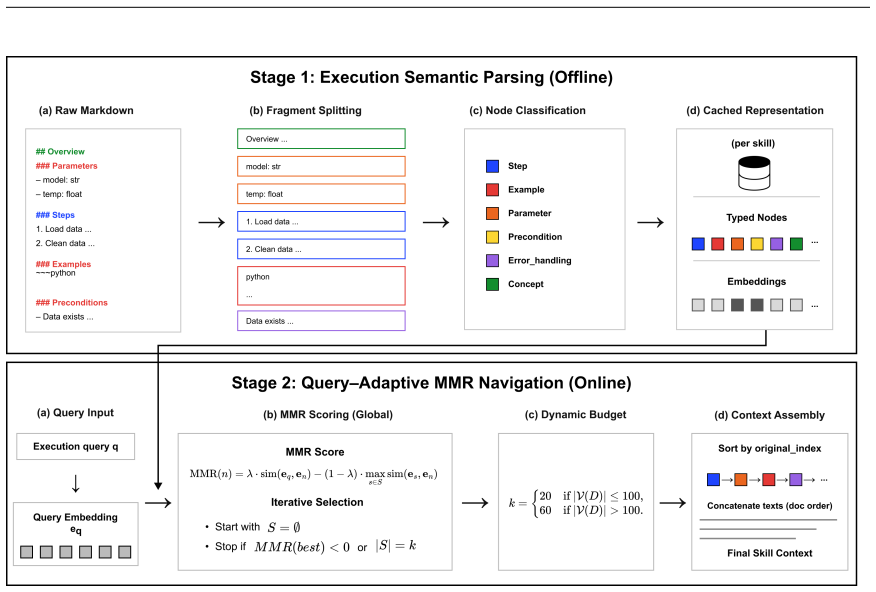
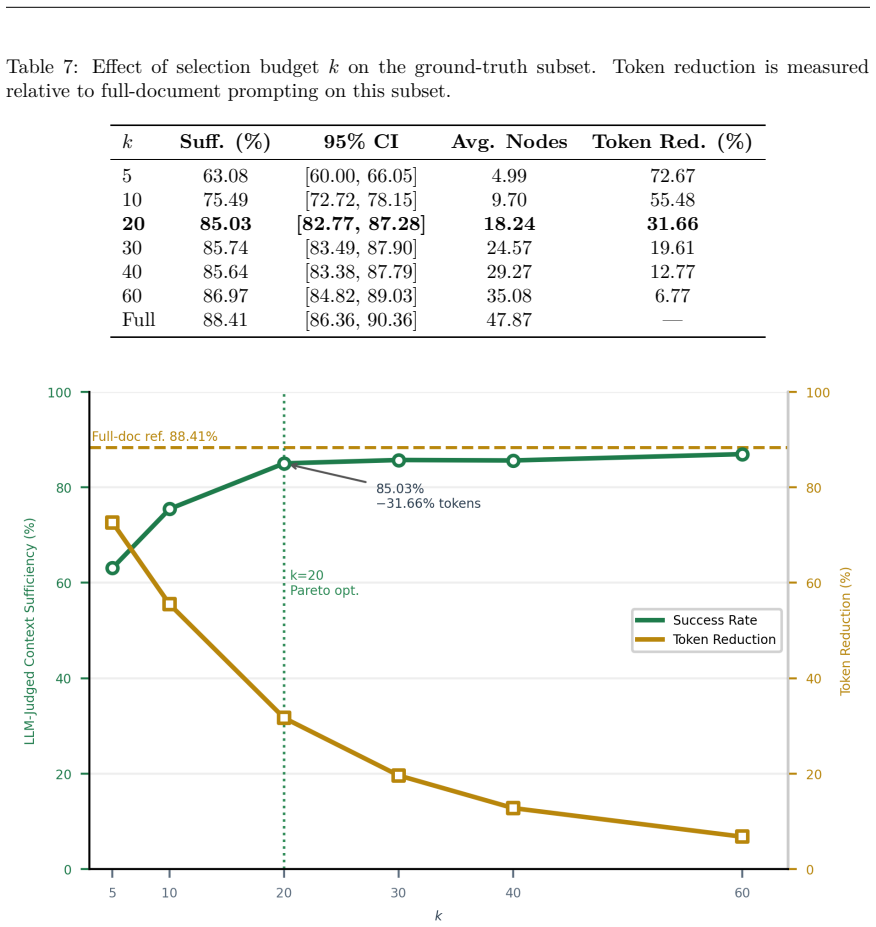
SkillPager is a two-stage framework that parses each Markdown skill into typed semantic nodes offline and leverages Maximal Marginal Relevance (MMR) to perform global, query-conditioned node selection online. On a benchmark of 395 skills and 1,975 queries, SkillPager achieves 78.89% LLM-judged context sufficiency, compared to 82.23% for the exhaustive full-document baseline, while reducing prompt tokens by 47.04%. A granularity ablation shows that applying the same retrieval algorithm to raw fixed-length chunks reaches a comparable 81.77% sufficiency but increases token cost by 28.81%. Among graph-based baselines, SkillPager outperforms the strongest baseline by a margin of 12.16%. Further a
What carries the argument
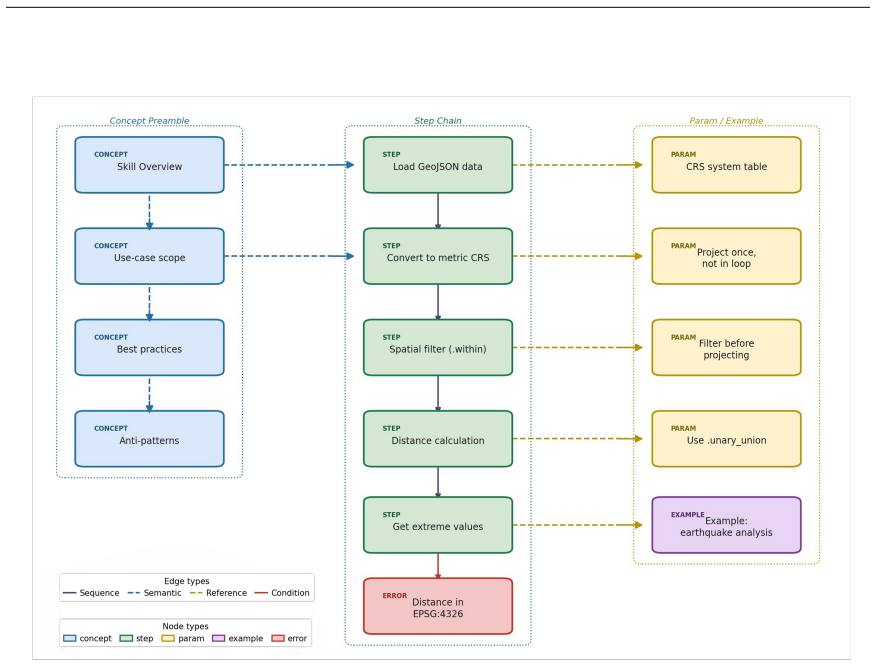
Typed semantic nodes parsed from Markdown skill documents, selected globally by Maximal Marginal Relevance (MMR) under query conditioning
If this is right
- Query-adaptive selection from typed nodes can replace full-document prompting while preserving most execution sufficiency
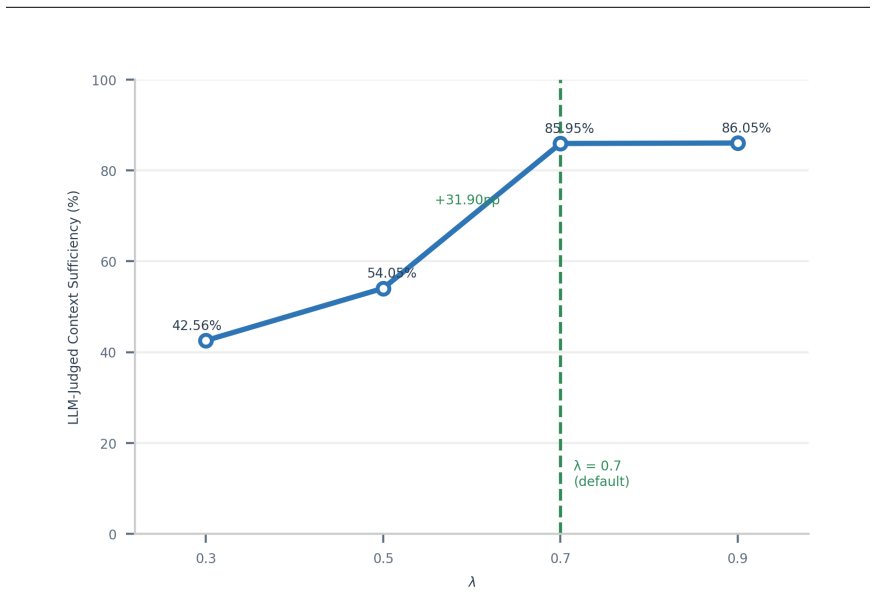
- Efficiency gains arise primarily from semantic typing rather than from the MMR algorithm itself
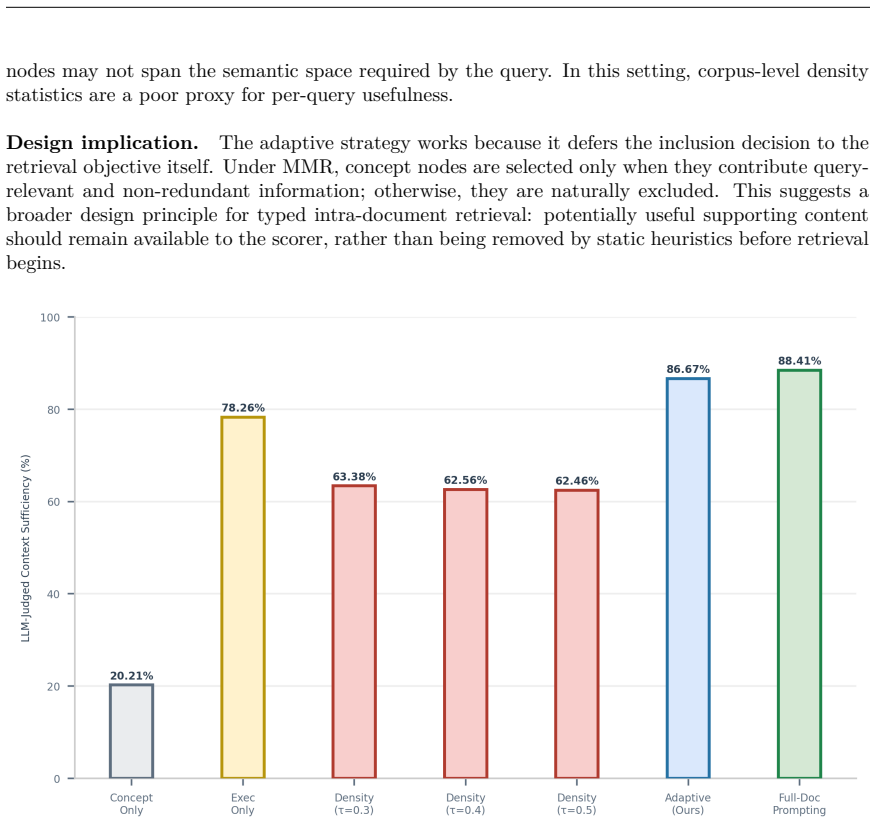
- Retaining supporting content and choosing it adaptively outperforms static removal heuristics
- Intra-skill retrieval constitutes a distinct access pattern that benefits from methods tailored to procedural documents
Where Pith is reading between the lines
- The offline parsing step implies that skill documents must be re-parsed whenever their structure changes, which may limit use in rapidly evolving domains
- If the sufficiency metric tracks actual execution success, the method suggests a route to smaller context windows for agent pipelines
- The same node-based approach could apply to other long procedural texts such as manuals or recipes without requiring graph construction
Load-bearing premise
The LLM judge used to score context sufficiency is a reliable proxy for whether the selected nodes actually enable successful skill execution by the downstream agent.
What would settle it
Run the same 1,975 queries with a downstream LLM agent that must actually execute the skill and compare task success rates between SkillPager-selected nodes, full documents, and the other baselines.
Figures

read the original abstract
Skill-based LLM agents increasingly rely on long procedural documents, but full-document prompting wastes tokens and dilutes information critical to execution. We study this setting as intra-skill retrieval, where the goal is to select a minimal, execution-sufficient context from a known skill document given a query. We present SkillPager, a two-stage framework that parses each Markdown skill into typed semantic nodes offline and leverages Maximal Marginal Relevance (MMR) to perform global, query-conditioned node selection online. On a benchmark of 395 skills and 1,975 queries, SkillPager achieves 78.89% LLM-judged context sufficiency, compared to 82.23% for the exhaustive full-document baseline, while reducing prompt tokens by 47.04%. A granularity ablation shows that applying the same retrieval algorithm to raw fixed-length chunks reaches a comparable 81.77% sufficiency but increases token cost by 28.81%, demonstrating that efficiency gains are driven by typed semantic granularity rather than the retrieval algorithm alone. Among graph-based baselines, SkillPager outperforms the strongest baseline by a margin of 12.16%. Further ablations show that supporting content is most effective when retained in the candidate pool and selected adaptively rather than removed by static heuristics. These results identify typed intra-document retrieval as a distinct access problem for skill-based agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkillPager, a two-stage framework for intra-skill retrieval from long procedural Markdown documents used by LLM agents. Skills are parsed offline into typed semantic nodes; online, MMR performs query-conditioned global node selection. On a benchmark of 395 skills and 1,975 queries, SkillPager reports 78.89% LLM-judged context sufficiency (vs. 82.23% for exhaustive full-document prompting) while cutting prompt tokens by 47.04%. It outperforms the strongest graph baseline by 12.16%. Ablations indicate that typed semantic granularity, rather than the retrieval algorithm alone, drives the efficiency gains, and that retaining supporting content in the candidate pool is beneficial.
Significance. If the LLM-judge sufficiency metric is shown to correlate with downstream agent execution success, the work would usefully identify typed intra-document retrieval as a distinct and practical access problem for skill-based agents, with concrete token savings. The granularity ablation (comparing semantic nodes to fixed-length chunks) and the result that adaptive selection of supporting content outperforms static heuristics are strengths that could inform future agent designs. The benchmark scale is reasonable, but the lack of validation for the primary metric limits immediate impact.
major comments (3)
- [Evaluation section (benchmark results)] Evaluation section (benchmark results paragraph): the headline sufficiency claim (78.89% vs. 82.23%) and the token-reduction claim rest entirely on an LLM judge whose prompt, scoring rubric, and correlation with actual downstream execution success or human judgment are not reported. This is load-bearing for the central thesis that the retrieved nodes enable successful skill execution.
- [Experiments / ablation studies] Experiments / ablation studies: no error bars, statistical significance tests, or details on benchmark construction (query generation process, skill selection criteria, or inter-query variance) are supplied, so the reported margins (including the 12.16% graph-baseline gap and the 28.81% token increase for chunks) cannot be assessed for reliability.
- [Granularity ablation] Granularity ablation (chunk baseline): the claim that efficiency gains are driven by typed semantic nodes rather than the retrieval algorithm assumes the fixed-length chunk baseline is fairly constructed, yet chunk size, overlap, and embedding details are not specified, weakening the attribution to granularity.
minor comments (1)
- The abstract and results text refer to "supporting content" and "typed semantic nodes" without a concise definition or example in the summary; a short illustrative figure or table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas for improved transparency and rigor. We address each major comment below and will revise the manuscript to incorporate additional details where feasible.
read point-by-point responses
-
Referee: Evaluation section (benchmark results paragraph): the headline sufficiency claim (78.89% vs. 82.23%) and the token-reduction claim rest entirely on an LLM judge whose prompt, scoring rubric, and correlation with actual downstream execution success or human judgment are not reported. This is load-bearing for the central thesis that the retrieved nodes enable successful skill execution.
Authors: We will add the full LLM judge prompt and scoring rubric to an appendix in the revised manuscript. A correlation analysis between the sufficiency metric and downstream execution success or human judgments was not performed in this study; we will explicitly discuss this as a limitation of the current evaluation. revision: partial
-
Referee: Experiments / ablation studies: no error bars, statistical significance tests, or details on benchmark construction (query generation process, skill selection criteria, or inter-query variance) are supplied, so the reported margins (including the 12.16% graph-baseline gap and the 28.81% token increase for chunks) cannot be assessed for reliability.
Authors: We will include error bars and statistical significance tests for key results in the revision. Expanded details on benchmark construction, including query generation, skill selection criteria, and inter-query variance analysis, will be added to the experimental setup section. revision: yes
-
Referee: Granularity ablation (chunk baseline): the claim that efficiency gains are driven by typed semantic nodes rather than the retrieval algorithm assumes the fixed-length chunk baseline is fairly constructed, yet chunk size, overlap, and embedding details are not specified, weakening the attribution to granularity.
Authors: We will specify the exact chunk size, overlap, and embedding model used for the fixed-length chunk baseline in the revised ablation description to support the fairness of the comparison. revision: yes
- Correlation of the LLM-judged sufficiency metric with downstream agent execution success or human judgment, as this validation was not conducted in the study.
Circularity Check
No significant circularity; empirical results on held-out benchmark are independent of inputs
full rationale
The paper describes a two-stage retrieval system (offline node parsing + online MMR selection) and reports empirical performance on a fixed benchmark of 395 skills and 1,975 queries. All reported numbers (78.89% sufficiency, 47.04% token reduction, 12.16% margin over baselines) are direct comparisons against full-document and graph baselines on held-out data. No equations, fitted parameters, or self-citations are used to derive the central claims; the sufficiency metric is an external LLM judge applied uniformly to all methods. The derivation chain is therefore self-contained and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Markdown skill documents can be parsed offline into typed semantic nodes that preserve execution-critical information.
Reference graph
Works this paper leans on
-
[1]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge dis- tillation.arXiv preprint arXiv:2402.03216, 4(5), 2024a. Tong Chen, Hongwei Wang, Sihao Chen, Wenhao Yu, Kaixin Ma, Xinran Zhao, Hongming Zhang, and Dong Yu. Dense x ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Mohit Dubey. Objectgraph: From document injection to knowledge traversal–a native file format for the agentic era.arXiv preprint arXiv:2604.27820,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
SkillReducer: Optimizing LLM Agent Skills for Token Efficiency
Yudong Gao, Zongjie Li, Zimo Ji, Pingchuan Ma, Shuai Wang, et al. Skillreducer: Optimizing llm agent skills for token efficiency.arXiv preprint arXiv:2603.29919,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Llmlingua: Compressing prompts for accelerated inference of large language models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compressing prompts for accelerated inference of large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pp. 13358–13376,
2023
-
[6]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InPro- ceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pp. 6769–6781,
2020
-
[7]
DF-RAG: Query-aware diversity for retrieval-augmented generation
Saadat Hasan Khan, Spencer Hong, Jingyu Wu, Kevin Lybarger, Youbing Yin, Erin Babinsky, and Daben Liu. DF-RAG: Query-aware diversity for retrieval-augmented generation. In Vera Demberg, Kentaro Inui, and Lluís Marquez (eds.),Findings of the Association for Computational Linguistics: EACL 2026, pp. 2873–2894, Rabat, Morocco, March
2026
-
[8]
Association for Com- putational Linguistics. ISBN 979-8-89176-386-9. doi: 10.18653/v1/2026.findings-eacl.150. URL https://aclanthology.org/2026.findings-eacl.150/. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented gener- atio...
-
[9]
Graph-of-Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
19 Dawei Li, Zongxia Li, Hongyang Du, Xiyang Wu, Shihang Gui, Yongbei Kuang, and Lichao Sun. Graph of skills: Dependency-aware structural retrieval for massive agent skills.arXiv preprint arXiv:2604.05333,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. InInternational Conference on Learning Representations, volume 2024, pp. 9695–9717,
2024
-
[11]
Raptor: Recursive abstractive processing for tree-organized retrieval
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher Manning. Raptor: Recursive abstractive processing for tree-organized retrieval. InInternational Conference on Learning Representations, volume 2024, pp. 32628–32649,
2024
-
[12]
ISSN 2159-5399. doi: 10.1609/aaai.v40i19. 38619. URLhttp://dx.doi.org/10.1609/aaai.v40i19.38619. Fei Yu and Yikun Liu. A novel extension to topic-hierarchical extractive summarization leveraging mmr and clustering to optimize diversity in long documents.2025 5th International Symposium on Artificial Intelligence and Big Data (AIBDF), pp. 424–427,
-
[13]
doi: 10.1109/aibdf67964. 2025.11440676. Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 19632–19642,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.