PolySpeech-100: A Large-Scale Benchmark for Speech Understanding Across 100+ Languages and Dialects
Pith reviewed 2026-06-28 17:42 UTC · model grok-4.3
The pith
PolySpeech-100 benchmark reveals open-source E2E speech models outperform cascade systems on heavy dialects by preserving paralinguistic cues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
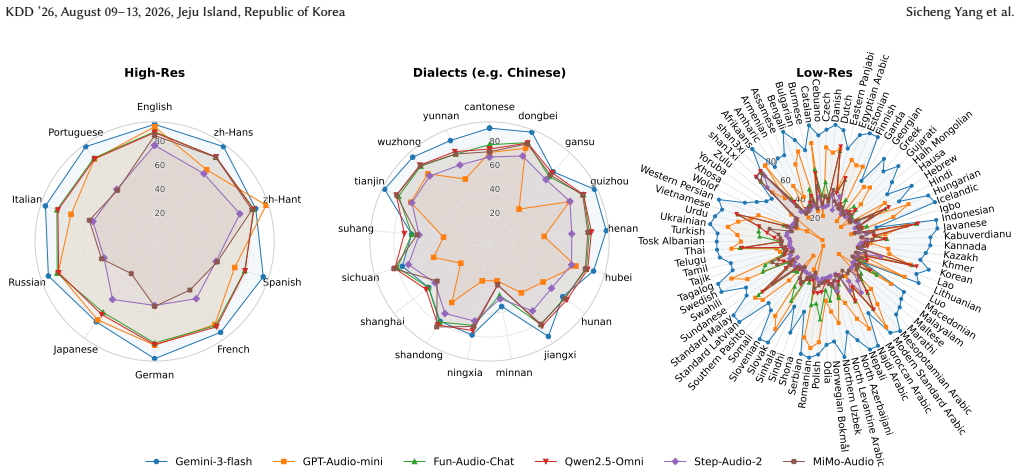
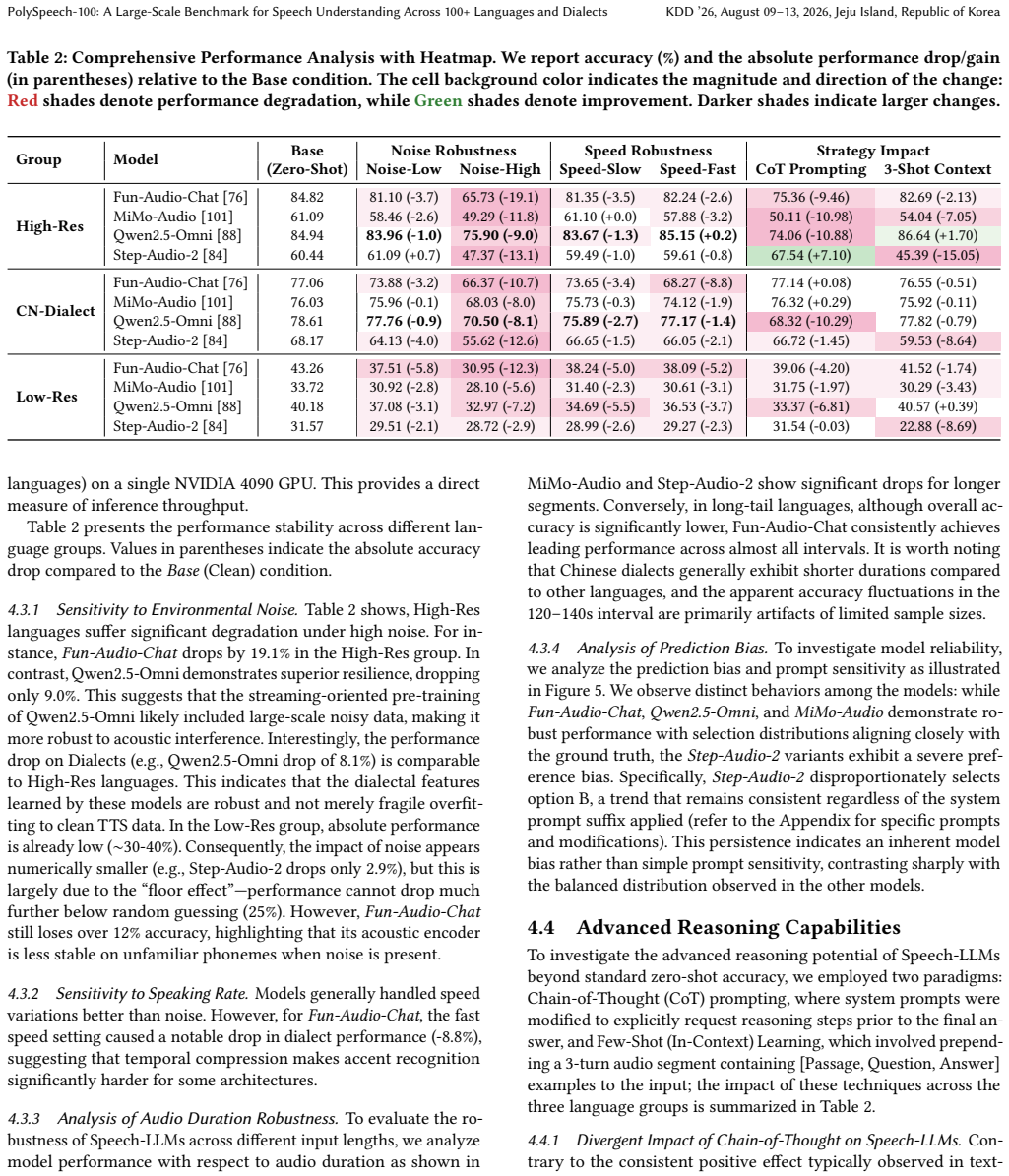
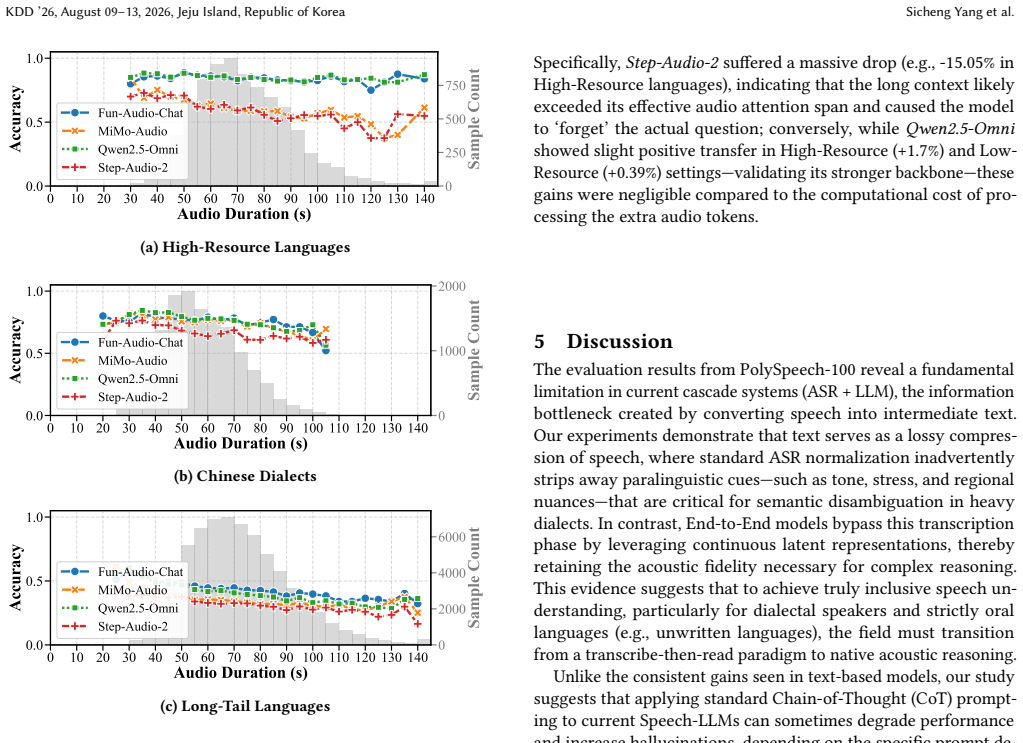
PolySpeech-100 is a benchmark for native-level speech comprehension across 110 linguistic variants that uses a hybrid construction pipeline to combine gold-standard human recordings with instruction-driven synthetic speech. Evaluation of 22 models shows open-source E2E models outperform cascade ASR-plus-LLM systems on heavy dialects because direct audio processing retains prosodic features and paralinguistic cues lost in transcription; open-source models exhibit catastrophic degradation on low-resource languages while commercial models remain robust; and chain-of-thought prompting degrades performance under standard zero-shot settings, indicating a modality alignment gap.
What carries the argument
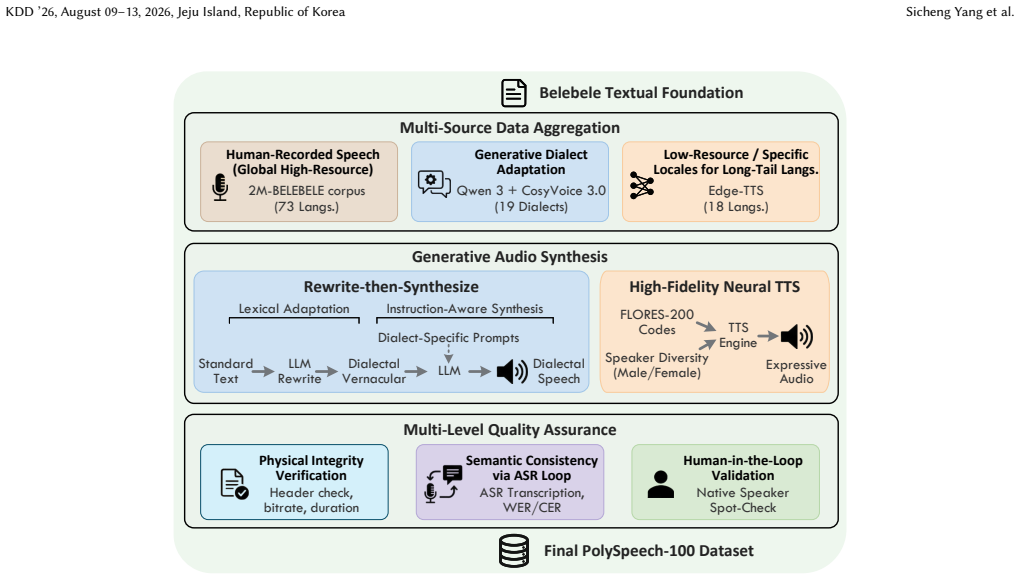
The hybrid construction pipeline that augments human recordings with synthetic speech to reach 110 variants while targeting native-level semantic comprehension.
If this is right
- Direct audio input is required to capture dialect-specific intonation and stress that text transcription discards.
- Open-source speech models need targeted improvements for low-resource languages to close the gap with commercial systems.
- Standard chain-of-thought prompting should be avoided in zero-shot speech understanding tasks because it reduces accuracy.
- Future model development must prioritize architectures that align audio and language modalities without relying on intermediate text.
- Benchmarks limited to high-resource languages and ASR miss critical failure modes in real-world multilingual use.
Where Pith is reading between the lines
- Training regimes that explicitly optimize for prosody retention could widen the advantage of E2E models on dialects.
- The observed degradation on low-resource languages suggests that scaling laws for speech may require language-specific data balancing rather than uniform scaling.
- If the modality alignment gap persists, hybrid systems may need separate audio-native reasoning heads instead of borrowing from text LLMs.
- Public release of the benchmark data allows direct testing of whether new models close the low-resource gap without synthetic artifacts.
Load-bearing premise
The synthetic speech added to human recordings accurately represents native comprehension without introducing artifacts that change how models rank against each other.
What would settle it
If re-running the same models on an all-human-recorded subset of the same tasks reverses the ranking between E2E and cascade systems on dialects, the claim that direct audio processing is the decisive factor would not hold.
Figures






read the original abstract
While End-to-End (E2E) Speech-Large Language Models (Speech-LLMs) are rapidly evolving, their evaluation methodologies remain limited to the era of simple transcription. Existing benchmarks suffer from three critical limitations: a pronounced bias towards high-resource languages, a focus on low-level recognition (ASR) rather than semantic reasoning, and a neglect of regional dialects. To bridge this gap, we introduce PolySpeech-100, a massive-scale benchmark designed to assess `native-level' speech comprehension across 110 linguistic variants. We employ a novel hybrid construction pipeline that augments gold-standard human recordings with instruction-driven synthetic speech, allowing us to cover 19 distinct Chinese dialects and over 80 low-resource languages. Extensive evaluation of 22 state-of-the-art models (including Gemini-3, GPT-Audio, and Qwen2.5-Omni) yields pivotal insights. First, we demonstrate that open-source E2E models outperform Cascade (ASR+LLM) systems on heavy dialects, proving that direct audio processing preserves critical paralinguistic cues and prosodic features (e.g., intonation, stress) that are often lost in standard transcription. Second, we reveal a significant performance gap: while commercial models maintain robustness, open-source models suffer catastrophic degradation on low-resource languages. Finally, counter-intuitively, we observe that under standard zero-shot settings, Chain-of-Thought prompting frequently degrades speech understanding performance for most evaluated models, revealing a potential modality alignment gap in current architectures. PolySpeech-100 establishes a rigorous standard for the next generation of inclusive, omni-capable Speech-LLMs. The data, demo, and code are publicly available at https://github.com/YoungSeng/PolySpeech-100.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PolySpeech-100, a benchmark for native-level speech comprehension across 110 linguistic variants (19 Chinese dialects + 80+ low-resource languages). It employs a hybrid construction pipeline combining gold-standard human recordings with instruction-driven synthetic speech, evaluates 22 models (including commercial and open-source E2E Speech-LLMs and cascades), and reports three main findings: open-source E2E models outperform ASR+LLM cascades on heavy dialects because direct audio processing preserves paralinguistic and prosodic cues; commercial models are robust while open-source models show catastrophic degradation on low-resource languages; and Chain-of-Thought prompting degrades zero-shot performance, suggesting a modality alignment gap. Data, demo, and code are released publicly.
Significance. If the benchmark construction is shown to be free of systematic artifacts, the work would be significant for highlighting performance gaps in current Speech-LLMs on underrepresented languages and dialects, and for providing evidence that E2E architectures can retain prosodic information lost in transcription-based cascades. The public release of the dataset and evaluation code is a clear strength that enables reproducibility and follow-on work.
major comments (1)
- [Abstract / Benchmark Construction] Abstract (hybrid construction pipeline) and associated methods: The headline claims that E2E models outperform cascades on heavy dialects (due to preserved paralinguistic cues) and that open-source models suffer catastrophic degradation on low-resource languages rest on the assumption that instruction-driven synthetic speech faithfully represents native prosody, intonation, and stress without introducing artifacts that differentially impact E2E audio encoders versus ASR components in cascades. No validation (e.g., prosodic feature comparisons, human perceptual tests, or ablation on synthesis quality per dialect/language) is described to support this; if synthesis quality varies systematically, the reported gaps could be benchmark artifacts rather than model properties.
minor comments (2)
- Clarify the exact total (110 variants vs. title's 100+) and provide a breakdown table of human vs. synthetic portions per language group.
- [Abstract] The abstract states 'native-level' comprehension but does not define the metric or human baseline used to establish this threshold.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on PolySpeech-100. The major comment highlights an important aspect of benchmark validity regarding the synthetic speech component. We address this point below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Benchmark Construction] Abstract (hybrid construction pipeline) and associated methods: The headline claims that E2E models outperform cascades on heavy dialects (due to preserved paralinguistic cues) and that open-source models suffer catastrophic degradation on low-resource languages rest on the assumption that instruction-driven synthetic speech faithfully represents native prosody, intonation, and stress without introducing artifacts that differentially impact E2E audio encoders versus ASR components in cascades. No validation (e.g., prosodic feature comparisons, human perceptual tests, or ablation on synthesis quality per dialect/language) is described to support this; if synthesis quality varies systematically, the reported gaps could be benchmark artifacts rather than model properties.
Authors: We agree that explicit validation of the synthetic speech is necessary to rule out systematic artifacts. The hybrid pipeline prioritizes gold-standard human recordings where available and uses instruction-driven synthesis only to extend coverage to underrepresented variants; however, the original submission did not report prosodic analyses, perceptual tests, or per-language synthesis ablations. In the revised version we will add: (1) quantitative comparison of prosodic features (F0, duration, energy, rhythm) between synthetic and human speech on a stratified sample of 10 dialects/languages; (2) human perceptual ratings (naturalness, intelligibility, prosodic fidelity) collected from native speakers; and (3) an ablation that evaluates model performance on the human-recorded subset alone versus the full hybrid set. These additions will directly test whether the reported E2E advantages and degradation patterns persist when synthesis quality is controlled. revision: yes
Circularity Check
No significant circularity; benchmark evaluations are externally grounded
full rationale
The paper presents a new benchmark constructed via a hybrid human+synthetic pipeline and reports empirical results from evaluating 22 independent external models (Gemini-3, GPT-Audio, Qwen2.5-Omni, etc.). No equations, fitted parameters, or derived quantities are defined in terms of the target claims. No self-citations are invoked to justify uniqueness or load-bearing premises. All headline observations (E2E vs cascade gaps on dialects, open-source degradation on low-resource languages, CoT degradation) are presented as direct measurements against third-party systems and are therefore falsifiable outside the paper's own data construction. This matches the default expectation of a non-circular empirical benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Inclusion AI, Biao Gong, Cheng Zou, et al. 2025. Ming-Omni: A Unified Mul- timodal Model for Perception and Generation.CoRRabs/2506.09344 (2025). https://doi.org/10.48550/arXiv.2506.09344
-
[2]
Keyu An, Qian Chen, Chong Deng, et al . 2024. FunAudioLLM: Voice Un- derstanding and Generation Foundation Models for Natural Interaction Be- tween Humans and LLMs.CoRRabs/2407.04051 (2024). arXiv:2407.04051 doi:10.48550/ARXIV.2407.04051
-
[3]
Philip Anastassiou, Jiawei Chen, Jitong Chen, et al. 2024. Seed-TTS: A Family of High-Quality Versatile Speech Generation Models.CoRRabs/2406.02430 (2024). arXiv:2406.02430 doi:10.48550/ARXIV.2406.02430
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.02430 2024
-
[4]
Rosana Ardila, Megan Branson, Kelly Davis, et al . 2020. Common Voice: A Massively-Multilingual Speech Corpus. InLanguage Resources and Evaluation Conference, LREC 2020. European Language Resources Association, 4218–4222. https://aclanthology.org/2020.lrec-1.520/
2020
-
[5]
Siddhant Arora, Kai-Wei Chang, Chung-Ming Chien, et al . 2025. On The Landscape of Spoken Language Models: A Comprehensive Survey.CoRR abs/2504.08528 (2025). arXiv:2504.08528 doi:10.48550/ARXIV.2504.08528
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.08528 2025
-
[6]
Lucas Bandarkar, Davis Liang, Benjamin Muller, et al. 2024. The Belebele Bench- mark: a Parallel Reading Comprehension Dataset in 122 Language Variants. In Meeting of the Association for Computational Linguistics, ACL 2024. Association for Computational Linguistics, 749–775. doi:10.18653/V1/2024.ACL-LONG.44
-
[7]
Martijn Bartelds, Nay San, Bradley McDonnell, et al . 2023. Making More of Little Data: Improving Low-Resource Automatic Speech Recognition Using Data Augmentation. InMeeting of the Association for Computational Linguistics, ACL
2023
-
[8]
Association for Computational Linguistics, 715–729. doi:10.18653/V1/2023. ACL-LONG.42
-
[9]
Emanuele Bastianelli, Andrea Vanzo, Pawel Swietojanski, et al. 2020. SLURP: A Spoken Language Understanding Resource Package. In2020 Conference on Em- pirical Methods in Natural Language Processing. Association for Computational Linguistics, 7252–7262. doi:10.18653/V1/2020.EMNLP-MAIN.588
-
[10]
Hui Bu, Jiayu Du, Xingyu Na, et al. 2017. AISHELL-1: An Open-Source Mandarin Speech Corpus and A Speech Recognition Baseline.CoRRabs/1709.05522 (2017). arXiv:1709.05522 http://arxiv.org/abs/1709.05522
Pith/arXiv arXiv 2017
-
[11]
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, et al. 2008. IEMOCAP: interactive emotional dyadic motion capture database.Lang. Resour. Evaluation42, 4 (2008), 335–359. doi:10.1007/S10579-008-9076-6
-
[12]
ByteDance Seed Team. 2026. Introducing Seed Full-Duplex Speech LLM: Attentive Listening, Robust Interference Suppression, Enabling More Natural Interaction. https://seed.bytedance.com/en/blog/introducing-seed-full-duplex- speech-llm-attentive-listening-robust-interference-suppression-enabling- more-natural-interaction. Project Page: https://seed.bytedance...
2026
-
[13]
Guoguo Chen, Shuzhou Chai, Guan-Bo Wang, et al . 2021. GigaSpeech: An Evolving, Multi-Domain ASR Corpus with 10, 000 Hours of Transcribed Audio. In22nd Annual Conference of the International Speech Communication Association, Interspeech 2021. ISCA, 3670–3674. doi:10.21437/INTERSPEECH.2021-1965
-
[14]
Hongjie Chen, Zehan Li, Guangmin Xia, et al. 2024. Telespeechpt: Large-scale chinese multi-dialect and multi-accent speech pre-training. InNational Confer- ence on Man-Machine Speech Communication. 183–190
2024
-
[15]
Junjie Chen, Yao Hu, Junjie Li, et al. 2025. FireRedChat: A Pluggable, Full-Duplex Voice Interaction System with Cascaded and Semi-Cascaded Implementations. CoRRabs/2509.06502 (2025). arXiv:2509.06502 doi:10.48550/ARXIV.2509.06502
-
[16]
Qian Chen, Yafeng Chen, Yanni Chen, et al. 2025. MinMo: A Multimodal Large Language Model for Seamless Voice Interaction.CoRRabs/2501.06282 (2025). arXiv:2501.06282 doi:10.48550/ARXIV.2501.06282
-
[17]
Wenxi Chen, Ziyang Ma, Ruiqi Yan, et al . 2025. SLAM-Omni: Timbre- Controllable Voice Interaction System with Single-Stage Training. InFindings of the Association for Computational Linguistics, ACL 2025, Vol. ACL 2025. As- sociation for Computational Linguistics, 2262–2282. https://aclanthology.org/ 2025.findings-acl.115/
2025
-
[18]
Yiming Chen, Xianghu Yue, Chen Zhang, et al. 2024. VoiceBench: Benchmarking LLM-Based Voice Assistants.CoRRabs/2410.17196 (2024). arXiv:2410.17196 doi:10.48550/ARXIV.2410.17196
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.17196 2024
-
[19]
Ziqi Chen, Gongyu Chen, Yihua Wang, et al . 2025. DiaMoE-TTS: A Unified IPA-Based Dialect TTS Framework with Mixture-of-Experts and Parameter- Efficient Zero-Shot Adaptation.CoRRabs/2509.22727 (2025). arXiv:2509.22727 doi:10.48550/ARXIV.2509.22727
-
[20]
Yunfei Chu, Jin Xu, Qian Yang, et al . 2024. Qwen2-Audio Technical Report. CoRRabs/2407.10759 (2024). arXiv:2407.10759 doi:10.48550/ARXIV.2407.10759
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.10759 2024
-
[21]
Christopher Cieri, David Graff, Owen Kimball, et al . [n. d.].Fisher English Training Speech Part 1 Speech. doi:10.35111/da4a-se30 KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Sicheng Yang et al
-
[22]
Alexis Conneau, Min Ma, Simran Khanuja, et al . 2022. FLEURS: FEW-Shot Learning Evaluation of Universal Representations of Speech. InIEEE Spoken Language Technology Workshop, SLT 2022. IEEE, 798–805. doi:10.1109/SLT54892. 2023.10023141
-
[23]
Costa-jussà, Bokai Yu, Pierre Andrews, et al
Marta R. Costa-jussà, Bokai Yu, Pierre Andrews, et al . 2025. 2M-BELEBELE: Highly Multilingual Speech and American Sign Language Comprehension Dataset Download PDF. InFindings of the Association for Computational Lin- guistics, ACL 2025, Vol. ACL 2025. Association for Computational Linguistics, 10893–10904. https://aclanthology.org/2025.findings-acl.569/
2025
-
[24]
Junbo Cui, Bokai Xu, Chongyi Wang, et al . 2026. MiniCPM-o 4.5: Towards Real-Time Full-Duplex Omni-Modal Interaction.CoRRabs/2604.27393 (2026). arXiv:2604.27393 doi:10.48550/ARXIV.2604.27393
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.27393 2026
-
[25]
Wenqian Cui, Dianzhi Yu, Xiaoqi Jiao, et al. 2025. Recent Advances in Speech Language Models: A Survey. InMeeting of the Association for Computational Linguistics, ACL 2025. Association for Computational Linguistics, 13943–13970. https://aclanthology.org/2025.acl-long.682/
2025
-
[26]
Yuhang Dai, Ziyu Zhang, Shuai Wang, et al. 2025. WenetSpeech-Chuan: A Large- Scale Sichuanese Corpus with Rich Annotation for Dialectal Speech Processing. CoRRabs/2509.18004 (2025). arXiv:2509.18004 doi:10.48550/ARXIV.2509.18004
-
[27]
Alexandre Défossez, Laurent Mazaré, Manu Orsini, et al. 2024. Moshi: a speech- text foundation model for real-time dialogue.CoRRabs/2410.00037 (2024). arXiv:2410.00037 doi:10.48550/ARXIV.2410.00037
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.00037 2024
-
[28]
Kaustubh Deshpande, Ved Sirdeshmukh, Johannes Baptist Mols, et al . 2025. MultiChallenge: A Realistic Multi-Turn Conversation Evaluation Benchmark Challenging to Frontier LLMs. InFindings of the Association for Computational Linguistics, ACL 2025, Vol. ACL 2025. Association for Computational Linguistics, 18632–18702. https://aclanthology.org/2025.findings...
2025
-
[29]
Xinhan Di, Zihao Chen, Yunming Liang, et al . 2024. Bailing-TTS: Chinese Dialectal Speech Synthesis Towards Human-like Spontaneous Representation. CoRRabs/2408.00284 (2024). arXiv:2408.00284 doi:10.48550/ARXIV.2408.00284
-
[30]
Seungheon Doh, Keunwoo Choi, Jongpil Lee, et al. 2023. LP-MusicCaps: LLM- Based Pseudo Music Captioning. InInternational Society for Music Information Retrieval Conference, ISMIR 2023. 409–416. doi:10.5281/ZENODO.10265311
-
[31]
Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. 2020. Clotho: an Audio Captioning Dataset. In2020 IEEE International Conference on Acoustics. IEEE, 736–740. doi:10.1109/ICASSP40776.2020.9052990
-
[32]
Jiayu Du, Xingyu Na, Xuechen Liu, et al . 2018. AISHELL-2: Transforming Mandarin ASR Research Into Industrial Scale.CoRRabs/1808.10583 (2018). arXiv:1808.10583 http://arxiv.org/abs/1808.10583
Pith/arXiv arXiv 2018
-
[33]
Zhihao Du, Changfeng Gao, Yuxuan Wang, et al . 2025. CosyVoice 3: To- wards In-the-wild Speech Generation via Scaling-up and Post-training.CoRR abs/2505.17589 (2025). arXiv:2505.17589 doi:10.48550/ARXIV.2505.17589
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.17589 2025
-
[34]
Qingkai Fang, Shoutao Guo, Yan Zhou, et al . 2025. LLaMA-Omni: Seamless Speech Interaction with Large Language Models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025. OpenReview.net. https: //openreview.net/forum?id=PYmrUQmMEw
2025
-
[35]
Qingkai Fang, Yan Zhou, Shoutao Guo, et al. 2025. LLaMA-Omni2: LLM-based Real-time Spoken Chatbot with Autoregressive Streaming Speech Synthesis. CoRRabs/2505.02625 (2025). arXiv:2505.02625 doi:10.48550/ARXIV.2505.02625
-
[36]
Yuan Gong, Jin Yu, and James R. Glass. 2022. Vocalsound: A Dataset for Improving Human Vocal Sounds Recognition. InIEEE International Confer- ence on Acoustics, Speech and Signal Processing, ICASSP 2022. IEEE, 151–155. doi:10.1109/ICASSP43922.2022.9746828
-
[37]
Google DeepMind. 2025. Gemini 3 Flash Model Card. https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf
2025
-
[38]
Jack Hong, Shilin Yan, Jiayin Cai, et al. 2025. WorldSense: Evaluating Real-world Omnimodal Understanding for Multimodal LLMs.CoRRabs/2502.04326 (2025). arXiv:2502.04326 doi:10.48550/ARXIV.2502.04326
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.04326 2025
-
[39]
Chien-Yu Huang, Ke-Han Lu, Shih-Heng Wang, et al. 2024. Dynamic-Superb: Towards a Dynamic, Collaborative, and Comprehensive Instruction-Tuning Benchmark For Speech. InIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2024. IEEE, 12136–12140. doi:10.1109/ICASSP48485. 2024.10448257
-
[40]
Andrew J. Hunt and Alan W. Black. 1996. Unit selection in a concatenative speech synthesis system using a large speech database. In1996 IEEE International Conference on Acoustics. IEEE Computer Society, 373–376. doi:10.1109/ICASSP. 1996.541110
-
[41]
Katsumi Ibaraki and David Chiang. 2025. Frustratingly Easy Data Augmentation for Low-Resource ASR.CoRRabs/2509.15373 (2025). arXiv:2509.15373 doi:10. 48550/ARXIV.2509.15373
arXiv 2025
-
[42]
Shengpeng Ji, Yifu Chen, Minghui Fang, et al . 2024. WavChat: A Survey of Spoken Dialogue Models.CoRRabs/2411.13577 (2024). arXiv:2411.13577 doi:10. 48550/ARXIV.2411.13577
arXiv 2024
-
[43]
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, et al . 2019. Audio- Caps: Generating Captions for Audios in The Wild. In2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 119–132. doi:10.18653/V1/N19-1011
-
[44]
Jiyeon Kim, Mehul Kumar, Dhananjaya Gowda, et al. 2021. Semi-Supervised Transfer Learning for Language Expansion of End-to-End Speech Recognition Models to Low-Resource Languages. InIEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2021. IEEE, 984–988. doi:10.1109/ASRU51503. 2021.9688019
-
[45]
KimiTeam, Ding Ding, Zeqian Ju, et al . 2025. Kimi-Audio Technical Report. CoRRabs/2504.18425 (2025). arXiv:2504.18425 doi:10.48550/ARXIV.2504.18425
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.18425 2025
-
[46]
Chia-Hsuan Li, Szu-Lin Wu, Chi-Liang Liu, et al. 2018. Spoken SQuAD: A Study of Mitigating the Impact of Speech Recognition Errors on Listening Comprehen- sion. In19th Annual Conference of the International Speech Communication Associ- ation, Interspeech 2018. ISCA, 3459–3463. doi:10.21437/INTERSPEECH.2018-1714
-
[47]
Guojian Li, Chengyou Wang, Hongfei Xue, et al . 2025. Easy Turn: Integrat- ing Acoustic and Linguistic Modalities for Robust Turn-Taking in Full-Duplex Spoken Dialogue Systems.CoRRabs/2509.23938 (2025). arXiv:2509.23938 doi:10.48550/ARXIV.2509.23938
-
[48]
Longhao Li, Zhao Guo, Hongjie Chen, et al. 2025. WenetSpeech-Yue: A Large- scale Cantonese Speech Corpus with Multi-dimensional Annotation.CoRR abs/2509.03959 (2025). arXiv:2509.03959 doi:10.48550/ARXIV.2509.03959
-
[49]
Tianpeng Li, Jun Liu, Tao Zhang, et al . 2025. Baichuan-Audio: A Unified Framework for End-to-End Speech Interaction.CoRRabs/2502.17239 (2025). arXiv:2502.17239 doi:10.48550/ARXIV.2502.17239
-
[50]
Xuechen Li, Tianyi Zhang, Yann Dubois, et al. 2023. AlpacaEval: An Automatic Evaluator of Instruction-following Models
2023
-
[51]
Yizhi Li, Ge Zhang, Yinghao Ma, et al . 2024. OmniBench: Towards The Future of Universal Omni-Language Models.CoRRabs/2409.15272 (2024). arXiv:2409.15272 doi:10.48550/ARXIV.2409.15272
-
[52]
Zhanxun Liu, Yifan Duan, Mengmeng Wang, et al. 2025. X-Talk: On the Un- derestimated Potential of Modular Speech-to-Speech Dialogue System.CoRR abs/2512.18706 (2025). arXiv:2512.18706 doi:10.48550/ARXIV.2512.18706
-
[53]
Ziyang Ma, Yinghao Ma, Yanqiao Zhu, et al . 2025. MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix.CoRR abs/2505.13032 (2025). arXiv:2505.13032 doi:10.48550/ARXIV.2505.13032
-
[54]
Ziyang Ma, Guanrou Yang, Wenxi Chen, et al. 2026. SLAM-LLM: A Modular, Open-Source Multimodal Large Language Model Framework and Best Practice for Speech, Language, Audio and Music Processing.IEEE Journal of Selected Topics in Signal Processing(2026)
2026
-
[55]
Xinhao Mei, Chutong Meng, Haohe Liu, et al . 2024. WavCaps: A ChatGPT- Assisted Weakly-Labelled Audio Captioning Dataset for Audio-Language Mul- timodal Research.IEEE ACM Trans. Audio Speech Lang. Process.32 (2024), 3339–3354. doi:10.1109/TASLP.2024.3419446
-
[56]
Yangyang Meng, Jinpeng Li, Guodong Lin, et al. 2025. Dolphin: A Large-Scale Au- tomatic Speech Recognition Model for Eastern Languages.CoRRabs/2503.20212 (2025). arXiv:2503.20212 doi:10.48550/ARXIV.2503.20212
-
[57]
OpenAI. 2024. GPT-4o System Card.CoRRabs/2410.21276 (2024). arXiv:2410.21276 doi:10.48550/ARXIV.2410.21276
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.21276 2024
-
[58]
OpenAI. 2025. gpt-audio-mini. https://platform.openai.com/docs/models/gpt- audio-mini
2025
-
[59]
Vassil Panayotov, Guoguo Chen, Daniel Povey, et al . 2015. Librispeech: An ASR corpus based on public domain audio books. In2015 IEEE International Conference on Acoustics. IEEE, 5206–5210. doi:10.1109/ICASSP.2015.7178964
-
[60]
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, et al. 2019. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations. In Conference of the Association for Computational Linguistics, ACL 2019. Associa- tion for Computational Linguistics, 527–536. doi:10.18653/V1/P19-1050
-
[61]
Vineel Pratap, Andros Tjandra, Bowen Shi, et al. 2024. Scaling Speech Tech- nology to 1, 000+ Languages.J. Mach. Learn. Res.25 (2024), 97:1–97:52. https://jmlr.org/papers/v25/23-1318.html
2024
-
[62]
Vineel Pratap, Qiantong Xu, Anuroop Sriram, et al. 2020. MLS: A Large-Scale Multilingual Dataset for Speech Research. In21st Annual Conference of the International Speech Communication Association, Interspeech 2020. ISCA, 2757–
2020
-
[63]
doi:10.21437/INTERSPEECH.2020-2826
-
[64]
Alec Radford, Jong Wook Kim, Tao Xu, et al. 2023. Robust Speech Recognition via Large-Scale Weak Supervision. InInternational Conference on Machine Learning, ICML 2023, Vol. 202. PMLR, 28492–28518. https://proceedings.mlr.press/v202/ radford23a.html
2023
-
[65]
Rajarshi Roy, Jonathan Raiman, Sang-Gil Lee, et al. 2026. PersonaPlex: Voice and Role Control for Full Duplex Conversational Speech Models.CoRR abs/2602.06053 (2026). arXiv:2602.06053 doi:10.48550/ARXIV.2602.06053
-
[66]
Shulan Ruan, Huijie Liu, Zhao Chen, Bin Feng, Kun Zhang, Caleb Chen Cao, Enhong Chen, and Lei Chen. 2025. CPWS: Confident programmatic weak supervision for high-quality data labeling.ACM Transactions on Information Systems43, 4 (2025), 1–26
2025
-
[67]
Sakshi, Utkarsh Tyagi, Sonal Kumar, et al
S. Sakshi, Utkarsh Tyagi, Sonal Kumar, et al. 2025. MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark. InThe Thirteenth International Conference on Learning Representations, ICLR 2025. OpenReview.net. https: //openreview.net/forum?id=TeVAZXr3yv
2025
-
[68]
Jun Shi, Shulan Ruan, Ziqi Zhu, Minfan Zhao, Hong An, Xudong Xue, and Bing Yan. 2024. Predictive accuracy-based active learning for medical image PolySpeech-100: A Large-Scale Benchmark for Speech Understanding Across 100+ Languages and Dialects KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea segmentation. InProceedings of the Thirty-Third Int...
2024
-
[69]
Qundong Shi, Jie Zhou, Biyuan Lin, et al . 2026. UltraEval-Audio: A Unified Framework for Comprehensive Evaluation of Audio Foundation Models.arXiv preprint arXiv:2601.01373(2026)
arXiv 2026
-
[70]
Xian Shi, Qiangze Feng, and Lei Xie. 2020. The ASRU 2019 Mandarin-English Code-Switching Speech Recognition Challenge: Open Datasets, Tracks, Methods and Results.CoRRabs/2007.05916 (2020). arXiv:2007.05916 https://arxiv.org/ abs/2007.05916
arXiv 2020
-
[71]
Xian Shi, Xiong Wang, Zhifang Guo, et al. 2026. Qwen3-ASR Technical Report. arXiv preprint arXiv:2601.21337(2026)
Pith/arXiv arXiv 2026
-
[72]
Shuzheng Si, Wentao Ma, Haoyu Gao, et al. 2023. SpokenWOZ: A Large-Scale Speech-Text Benchmark for Spoken Task-Oriented Dialogue Agents. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023. http://papers.nips.cc/ paper_files/paper/2023/hash/7b16688a2b053a1b01474ab5c78ce662-Abstract- Data...
2023
-
[73]
StepFun. 2026. StepAudio 2.5 TTS: Contextual TTS. https://platform.stepfun. com/docs/zh/guides/models/stepaudio-2.5-tts
2026
-
[74]
Tianxiang Sun, Xiaotian Zhang, Zhengfu He, et al . 2024. MOSS: An Open Conversational Large Language Model.Mach. Intell. Res.21, 5 (2024), 888–905. doi:10.1007/S11633-024-1502-8
-
[75]
Zhiyuan Tang, Dong Wang, Yanguang Xu, et al. 2021. KeSpeech: An Open Source Speech Dataset of Mandarin and Its Eight Subdialects. InNeural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021. https://datasets-benchmarks-proceedings.neurips.cc/paper/ 2021/hash/0336dcbab05b9d5ad24f4333c7658a0e-Abstract-round2.html
2021
-
[76]
Llama Team. 2024. The Llama 3 Herd of Models.CoRRabs/2407.21783 (2024). arXiv:2407.21783 doi:10.48550/ARXIV.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[77]
Qwen Team. 2026. Qwen3.5-Omni Technical Report.CoRRabs/2604.15804 (2026). arXiv:2604.15804 doi:10.48550/ARXIV.2604.15804
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.15804 2026
-
[78]
Tongyi Fun Team, Qian Chen, Luyao Cheng, et al . 2025. Fun-Audio-Chat Technical Report.CoRRabs/2512.20156 (2025). arXiv:2512.20156 doi:10.48550/ ARXIV.2512.20156
arXiv 2025
-
[79]
Zeyue Tian, Binxin Yang, Zhaoyang Liu, et al. 2026. Audio-Omni: Extending Multi-modal Understanding to Versatile Audio Generation and Editing.CoRR abs/2604.10708 (2026). arXiv:2604.10708 doi:10.48550/ARXIV.2604.10708
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.10708 2026
-
[80]
Changhan Wang, Morgane Rivière, Ann Lee, et al. 2021. VoxPopuli: A Large- Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation. InMeeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021. Association for Computat...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.