ProductWebGen: Benchmarking Multimodal Product Webpage Generation
Pith reviewed 2026-06-28 17:24 UTC · model grok-4.3
The pith
Editing-based workflows outperform unified multimodal models in webpage instruction following and content appeal on a new 500-sample benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
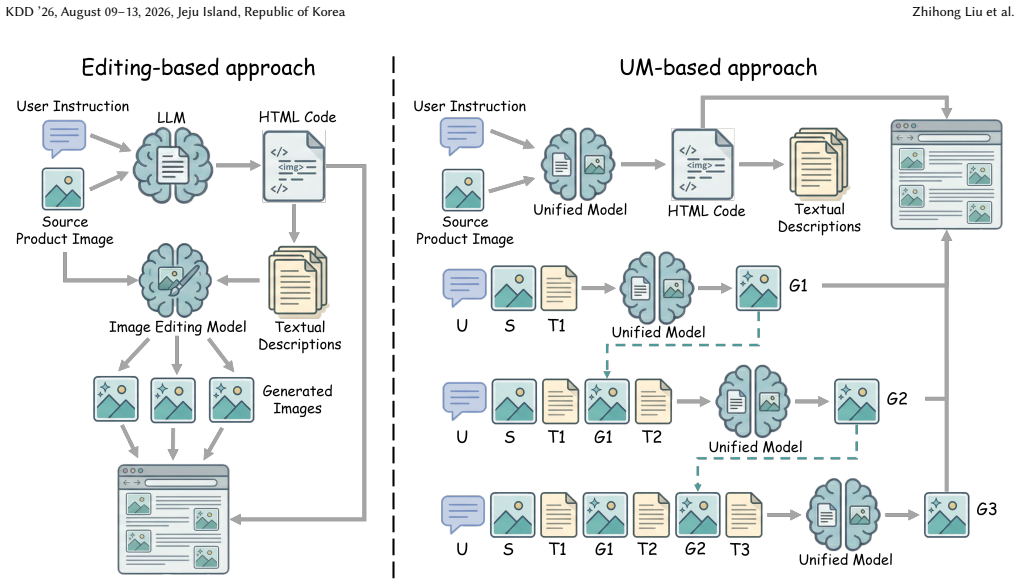
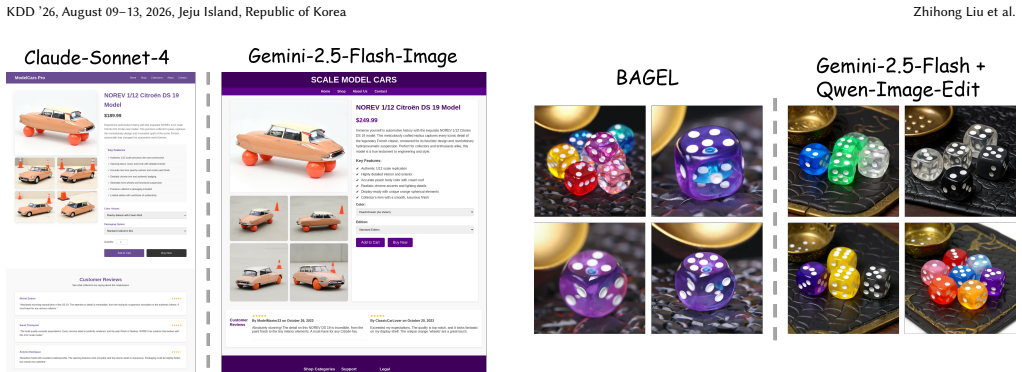
The paper establishes ProductWebGen as a benchmark with 500 samples for the mixed-modality task of generating consistent product showcase webpages from a source image, visual content instructions, and webpage instructions. It defines and compares two evaluation workflows: editing-based, which separates LLM-generated HTML from image-editing-model outputs, and UM-based, which conditions a single unified model on the full multimodal context to produce both. Results indicate editing-based approaches lead in webpage instruction following and content appeal, while UM-based approaches may hold advantages in fulfilling visual content instructions. The work further constructs and validates the Produc
What carries the argument
The two defined workflows for mixed-modality evaluation: editing-based (separate LLM for HTML code and image editing model for visuals) versus UM-based (single unified model generating both code and images conditioned on preceding context).
If this is right
- Editing-based pipelines are preferable when strict adherence to webpage layout instructions and visual appeal are priorities.
- Unified models may be better suited for tasks where precise following of visual content instructions is the main requirement.
- The ProductWebGen-1k dataset can be used to improve open-source unified models through supervised fine-tuning.
- The benchmark framework enables direct comparison of controllability and consistency in multimodal generation for e-commerce uses.
Where Pith is reading between the lines
- Current end-to-end unified models still lag hybrid editing pipelines on tasks needing tight cross-element visual consistency.
- A hybrid system that routes layout code to language models and visuals to editing models could combine the observed strengths of both approaches.
- The benchmark setup could be adapted to test webpage generation for non-product domains such as news articles or event pages.
Load-bearing premise
The 500 test samples and two defined workflows are sufficient to measure and compare the capabilities of multimodal models for real-world product webpage generation.
What would settle it
A unified model scoring higher than editing-based methods on webpage instruction following and content appeal metrics when evaluated on all 500 samples would falsify the reported leading results.
Figures


















read the original abstract
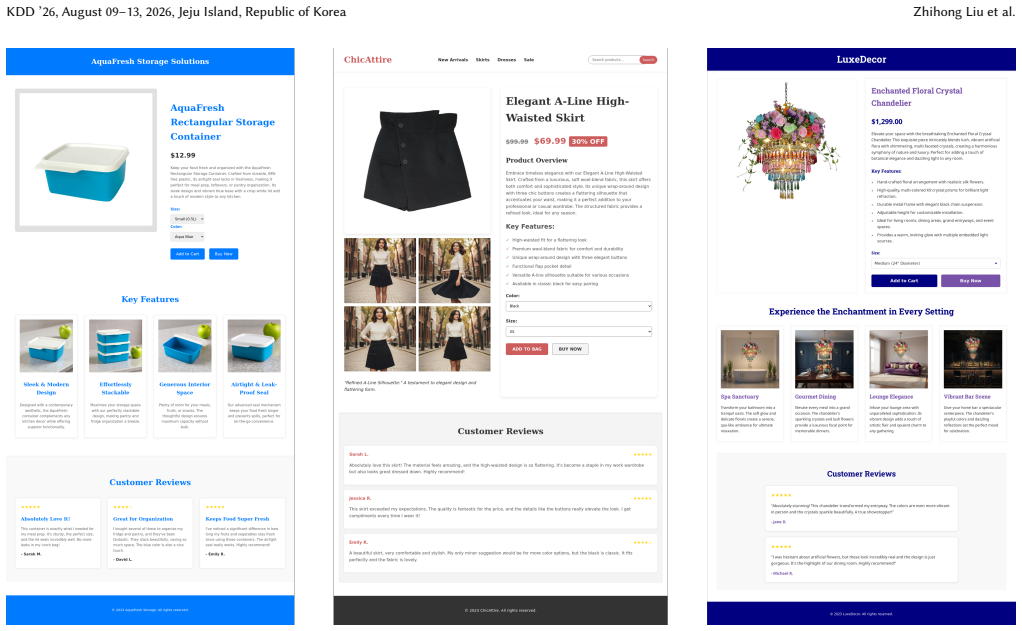
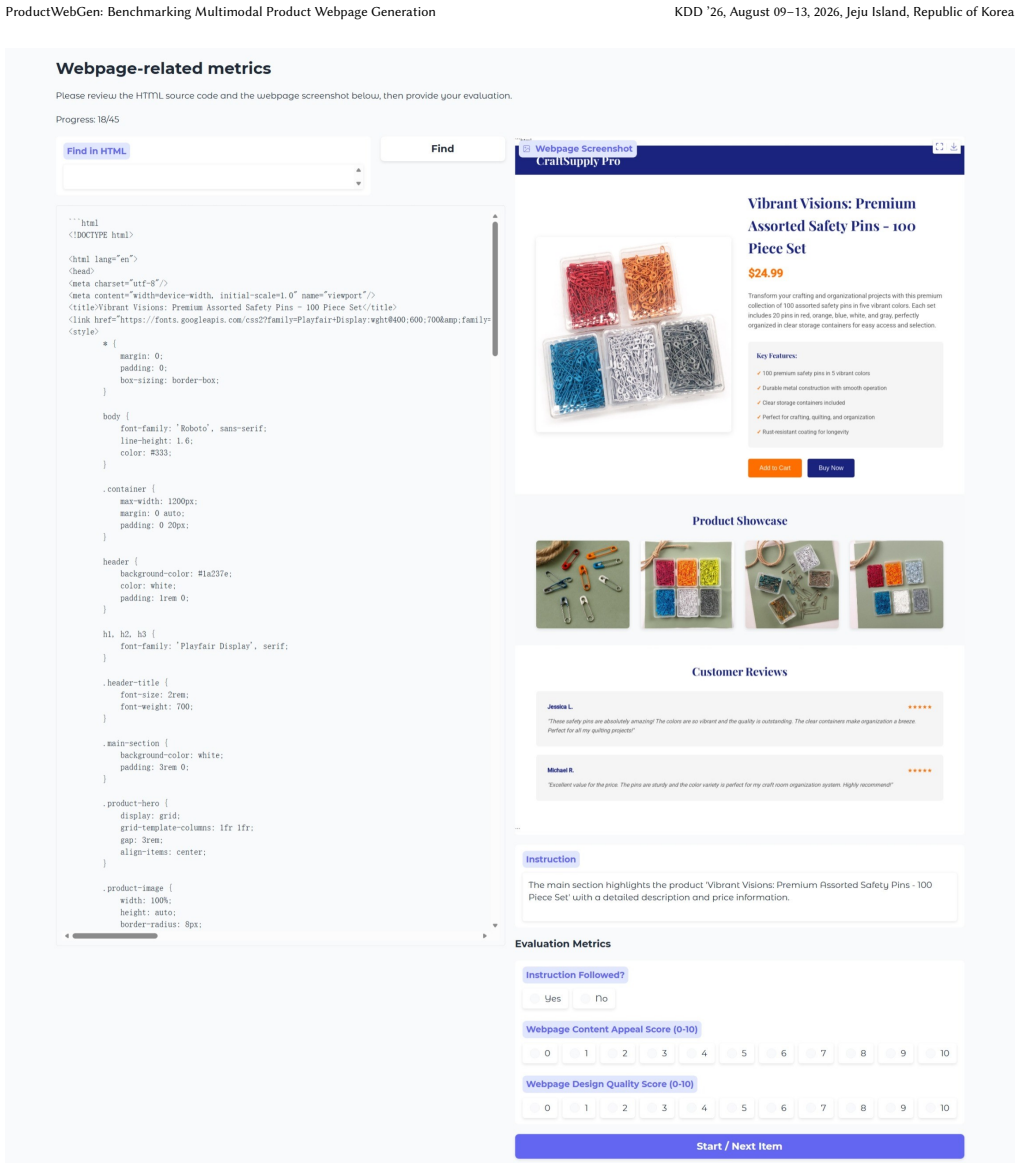
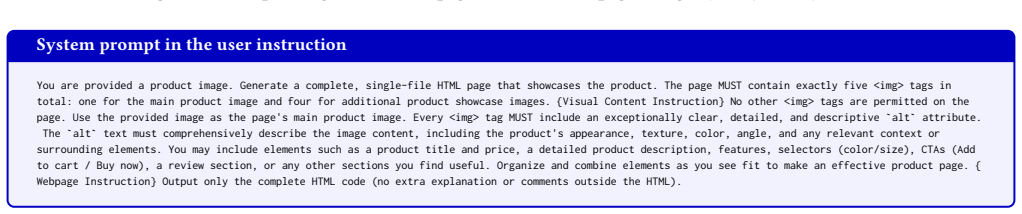
Crafting a product display webpage from a source product image, along with layout and visual content instructions, holds significant practical value for domains such as marketing, advertising, and E-commerce. Intuitively, this task demands strict visual consistency across product displays and high-fidelity instruction following to jointly generate renderable HTML code. These requirements on controllability and instruction-following are closely aligned with the core features of advanced multimodal generative models, such as image editing models and unified models. To this end, this paper introduces ProductWebGen to systematically benchmark the product webpage generation capacities of these models. We organize ProductWebGen with 500 test samples covering 13 product categories; each sample consists of a source image, a visual content instruction, and a webpage instruction. The task is to generate a product showcase webpage including multiple consistent images in accordance with the source image and instructions. Given the mixed-modality input-output nature of the task, we design and systematically compare two workflows for evaluation -- one uses large language models and image editing models to separately generate HTML code and images (editing-based), while the other relies on a single UM to generate both, with image generation conditioned on the preceding multimodal context (UM-based). Empirical results show that editing-based approaches achieve leading results in webpage instruction following and content appeal, while UM-based ones may display more advantages in fulfilling visual content instructions. We also construct a supervised fine-tuning dataset, ProductWebGen-1k, with 1,000 groups of real product images and LLM-generated HTML code. We verify its effectiveness on the open-source UM BAGEL. The data and code are available at https://github.com/SJTU-DENG-Lab/ProductWebGen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ProductWebGen, a benchmark of 500 test samples spanning 13 product categories. Each sample pairs a source product image with a visual content instruction and a webpage instruction; the goal is to produce a renderable HTML webpage containing multiple visually consistent product images. The authors define and compare two evaluation workflows—an editing-based pipeline (LLM-generated HTML plus separate image-editing models) and a UM-based pipeline (single unified multimodal model generating both HTML and images conditioned on multimodal context)—and report that editing-based methods lead on webpage instruction following and content appeal while UM-based methods hold an edge on visual-content instructions. They additionally release the ProductWebGen-1k SFT dataset (1,000 image–HTML pairs) and show its utility when fine-tuning the open-source UM BAGEL.
Significance. If the reported rankings are shown to be statistically robust, the benchmark would supply a concrete, application-oriented testbed for multimodal instruction following and visual consistency in e-commerce settings. The public release of both the 500-sample test set and the 1k SFT corpus, together with code, is a clear positive for reproducibility.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim that editing-based approaches achieve “leading results” in webpage instruction following and content appeal (while UM-based approaches are stronger on visual content instructions) is presented without any reported metrics, baselines, error bars, statistical significance tests, or inter-rater agreement figures for the appeal scores. With only 500 samples, it is impossible to determine whether the observed differences exceed sampling noise or prompt sensitivity.
- [§3] §3 (Benchmark Construction): the evaluation protocol relies on exactly 500 samples across 13 categories yet provides no analysis of category imbalance, variance across the two workflows, or sensitivity to prompt phrasing. These omissions directly affect the reliability of the workflow ranking that constitutes the paper’s primary empirical contribution.
- [§4.2] §4.2 (Workflow Comparison): the description of how HTML generation prompts and image-editing conditioning are standardized across models is absent, leaving open the possibility that implementation details rather than intrinsic model capabilities drive the reported differences.
minor comments (2)
- A dedicated subsection or table summarizing the precise automatic and human metrics (and their scoring rubrics) would improve clarity.
- The GitHub link is given, but the manuscript does not state the exact commit or data-split files used for the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on statistical robustness and methodological transparency. We address each major point below and will revise the manuscript accordingly to strengthen the empirical claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim that editing-based approaches achieve “leading results” in webpage instruction following and content appeal (while UM-based approaches are stronger on visual content instructions) is presented without any reported metrics, baselines, error bars, statistical significance tests, or inter-rater agreement figures for the appeal scores. With only 500 samples, it is impossible to determine whether the observed differences exceed sampling noise or prompt sensitivity.
Authors: We agree that the current presentation lacks sufficient quantitative support and statistical validation. In the revised manuscript we will report the concrete human-evaluation metrics (preference percentages and mean appeal scores), include error bars, conduct statistical significance tests (paired t-tests or bootstrap resampling), and report inter-rater agreement (e.g., Fleiss’ kappa) for the appeal annotations. We will also add a brief discussion of sample-size considerations and any prompt-sensitivity checks already performed. revision: yes
-
Referee: [§3] §3 (Benchmark Construction): the evaluation protocol relies on exactly 500 samples across 13 categories yet provides no analysis of category imbalance, variance across the two workflows, or sensitivity to prompt phrasing. These omissions directly affect the reliability of the workflow ranking that constitutes the paper’s primary empirical contribution.
Authors: We will add an explicit breakdown of the 500-sample category distribution, per-category performance tables with variance statistics for both workflows, and a short sensitivity study that re-runs a subset of prompts with paraphrased instructions to quantify ranking stability. revision: yes
-
Referee: [§4.2] §4.2 (Workflow Comparison): the description of how HTML generation prompts and image-editing conditioning are standardized across models is absent, leaving open the possibility that implementation details rather than intrinsic model capabilities drive the reported differences.
Authors: We will expand §4.2 and add a dedicated appendix subsection that lists the exact HTML-generation prompt templates and the precise image-editing conditioning inputs used for every model, thereby documenting standardization. revision: yes
Circularity Check
No circularity: benchmark construction and direct empirical comparison only
full rationale
The paper introduces ProductWebGen as a 500-sample benchmark across 13 categories and compares editing-based vs. UM-based workflows via direct evaluation on webpage instruction following, content appeal, and visual content instructions. No equations, derivations, parameter fitting, or predictions appear; the SFT dataset ProductWebGen-1k is constructed separately and verified on BAGEL without reducing any claim to its own inputs. All central claims rest on explicit test-set results rather than self-definitional loops, fitted-input renamings, or self-citation chains. This is a standard self-contained benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2025. Introducing Claude 4: Claude Sonnet 4. https://www.anthropic. com/news/claude-4. Accessed: 2025-09-24
2025
-
[2]
Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, et al. 2025. FLUX. 1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space.arXiv e-prints(2025), arXiv–2506
2025
-
[3]
Tony Beltramelli. 2018. pix2code: Generating code from a graphical user inter- face screenshot. InProceedings of the ACM SIGCHI symposium on engineering interactive computing systems
2018
-
[4]
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. 2025. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Jasmine Collins, Shubham Goel, Kenan Deng, Achleshwar Luthra, Leon Xu, Er- han Gundogdu, Xi Zhang, Tomas F Yago Vicente, Thomas Dideriksen, Himanshu Arora, et al. 2022. Abo: Dataset and benchmarks for real-world 3d object un- derstanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 21126–21136
2022
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. 2025. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. 2023. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems36 (2023), 52132–52152
2023
-
[9]
Google. 2025. Introducing Gemini 2.5 Flash Image. https://developers.googleblog. com/en/introducing-gemini-2-5-flash-image/. Accessed: 2025-09-24
2025
-
[10]
Yi Gui, Zhen Li, Yao Wan, Yemin Shi, Hongyu Zhang, Bohua Chen, Yi Su, Dong- ping Chen, Siyuan Wu, Xing Zhou, et al. 2025. Webcode2m: A real-world dataset for code generation from webpage designs. InProceedings of the ACM on Web Conference 2025. 1834–1845
2025
-
[11]
Yi Gui, Yao Wan, Zhen Li, Zhongyi Zhang, Dongping Chen, Hongyu Zhang, Yi Su, Bohua Chen, Xing Zhou, Wenbin Jiang, et al. 2025. UICoPilot: Automating UI synthesis via hierarchical code generation from webpage designs. InProceedings of the ACM on Web Conference 2025. 1846–1855
2025
-
[12]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [13]
- [14]
- [15]
-
[16]
Chao Liao, Liyang Liu, Xun Wang, Zhengxiong Luo, Xinyu Zhang, Wenliang Zhao, Jie Wu, Liang Li, Zhi Tian, and Weilin Huang. 2025. Mogao: An omni foundation model for interleaved multi-modal generation.arXiv preprint arXiv:2505.05472 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [17]
-
[18]
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai Yu, et al. 2025. Janusflow: Har- monizing autoregression and rectified flow for unified multimodal understanding and generation. InProceedings of the Computer Vision and Pattern Recognition Conference. 7739–7751
2025
-
[19]
Yuwei Niu, Munan Ning, Mengren Zheng, Weiyang Jin, Bin Lin, Peng Jin, Ji- aqi Liao, Chaoran Feng, Kunpeng Ning, Bin Zhu, et al . 2025. Wise: A world knowledge-informed semantic evaluation for text-to-image generation.arXiv preprint arXiv:2503.07265(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Xichen Pan, Satya Narayan Shukla, Aashu Singh, Zhuokai Zhao, Shlok Kumar Mishra, Jialiang Wang, Zhiyang Xu, Jiuhai Chen, Kunpeng Li, Felix Juefei-Xu, et al. 2025. Transfer between modalities with metaqueries.arXiv preprint arXiv:2504.06256(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Alex Robinson. 2019. Sketch2code: Generating a website from a paper mockup. arXiv preprint arXiv:1905.13750(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[22]
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang
- [23]
-
[24]
Chameleon Team. 2024. Chameleon: Mixed-modal early-fusion foundation mod- els.arXiv preprint arXiv:2405.09818(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Qwen Team. 2025. Qwen3-VL-235B-A22B-Instruct. https://qwen.ai/ blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef&from=research.latest- advancements-list. Accessed: 2025-11-13
2025
-
[26]
V Team, Wenyi Hong, Wenmeng Yu, et al . 2025. GLM-4.5V and GLM-4.1V- thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [27]
-
[28]
Yuxuan Wan, Chaozheng Wang, Yi Dong, Wenxuan Wang, Shuqing Li, Yintong Huo, and Michael Lyu. 2025. Divide-and-Conquer: Generating UI Code from Screenshots.Proceedings of the ACM on Software Engineering2, FSE (2025), 2099–2122
2025
- [29]
-
[30]
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jin- sheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. 2024. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri. 2024. Self-preference bias in llm-as-a-judge.arXiv preprint arXiv:2410.21819(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng- ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al . 2025. Qwen-image technical report.arXiv preprint arXiv:2508.02324(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. 2025. OmniGen2: Exploration to Advanced Multimodal Generation.arXiv preprint arXiv:2506.18871(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Fan Wu, Cuiyun Gao, Shuqing Li, Xin-Cheng Wen, and Qing Liao. 2025. MLLM- Based UI2Code Automation Guided by UI Layout Information.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 1123–1145
2025
-
[35]
Junfeng Wu, Yi Jiang, Chuofan Ma, Yuliang Liu, Hengshuang Zhao, Zehuan Yuan, Song Bai, and Xiang Bai. 2024. Liquid: Language models are scalable multi-modal generators.arXiv e-prints(2024), arXiv–2412
2024
-
[36]
xAI. 2025. Grok 4. https://x.ai/news/grok-4. Accessed: 2025-09-24
2025
- [37]
-
[38]
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. 2024. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. 2025. Show-o2: Improved Native Unified Multimodal Models.arXiv preprint arXiv:2506.15564(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. 2024. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9556–9567
2024
-
[41]
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. 2025. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
2023
-
[43]
ensuring coherent perspectives
Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. 2025. Trans- fusion: Predict the next token and diffuse images with one multi-modal model. InInternational Conference on Learning Representations, Vol. 2025. 6446–6469. ProductWebGen: Benchmarking Multimodal Produc...
2025
-
[44]
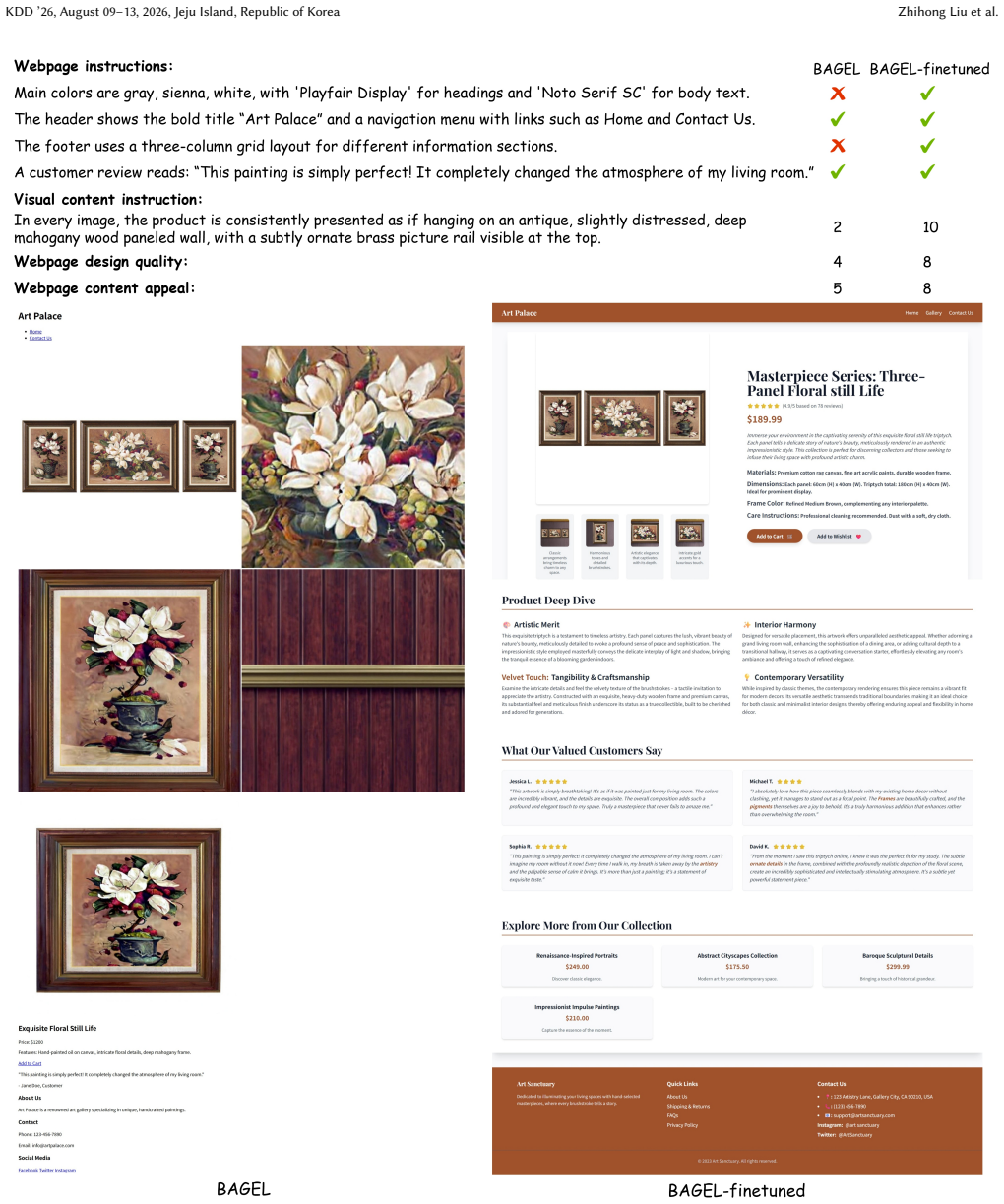
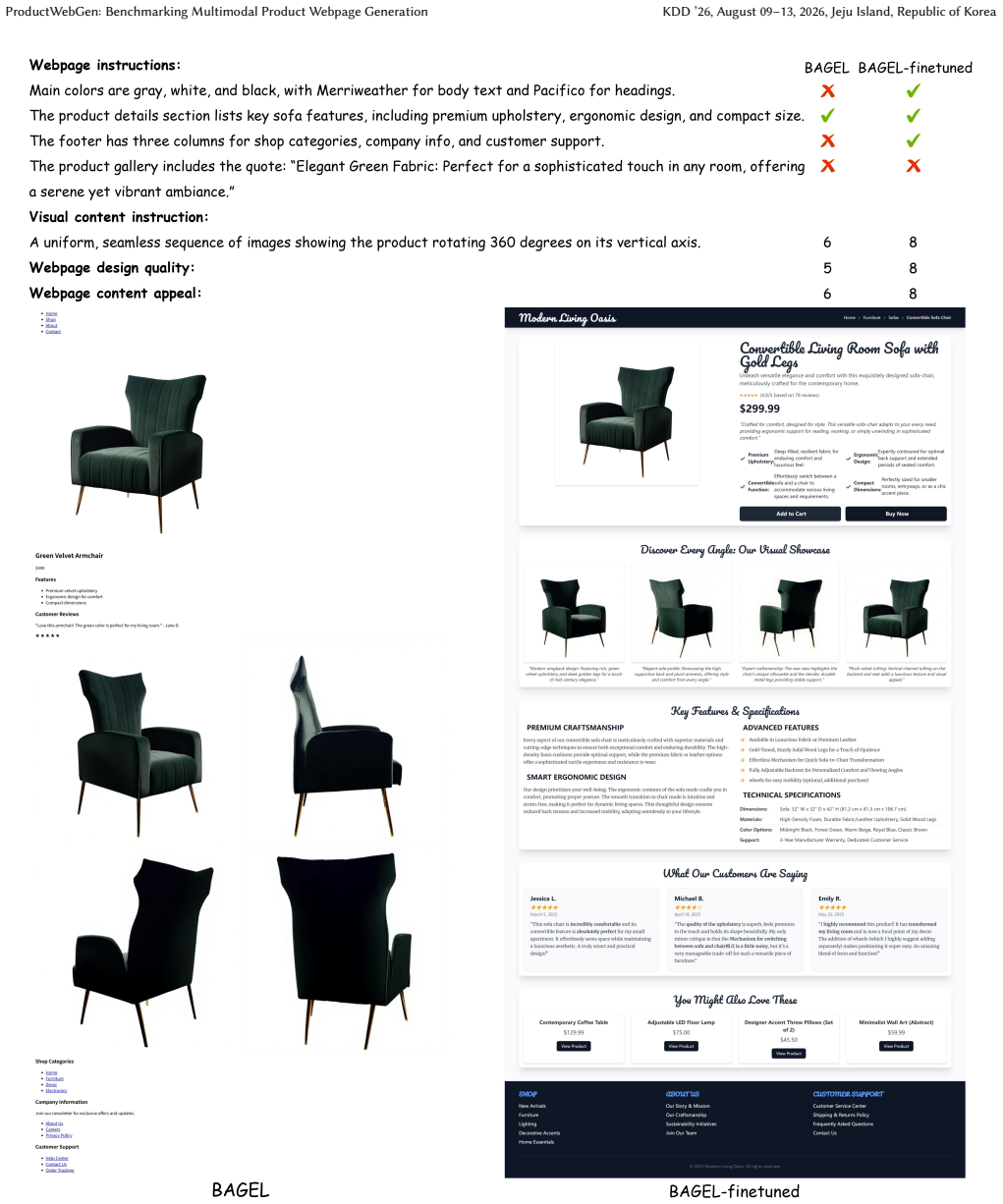
add-to-cart
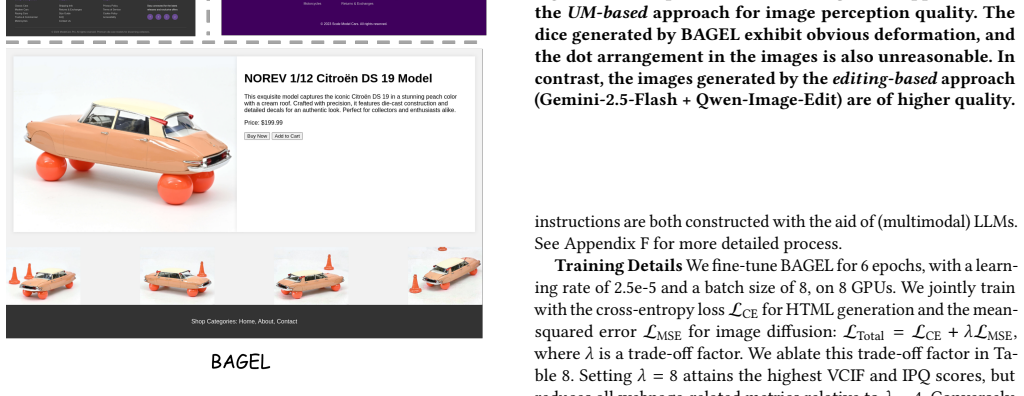
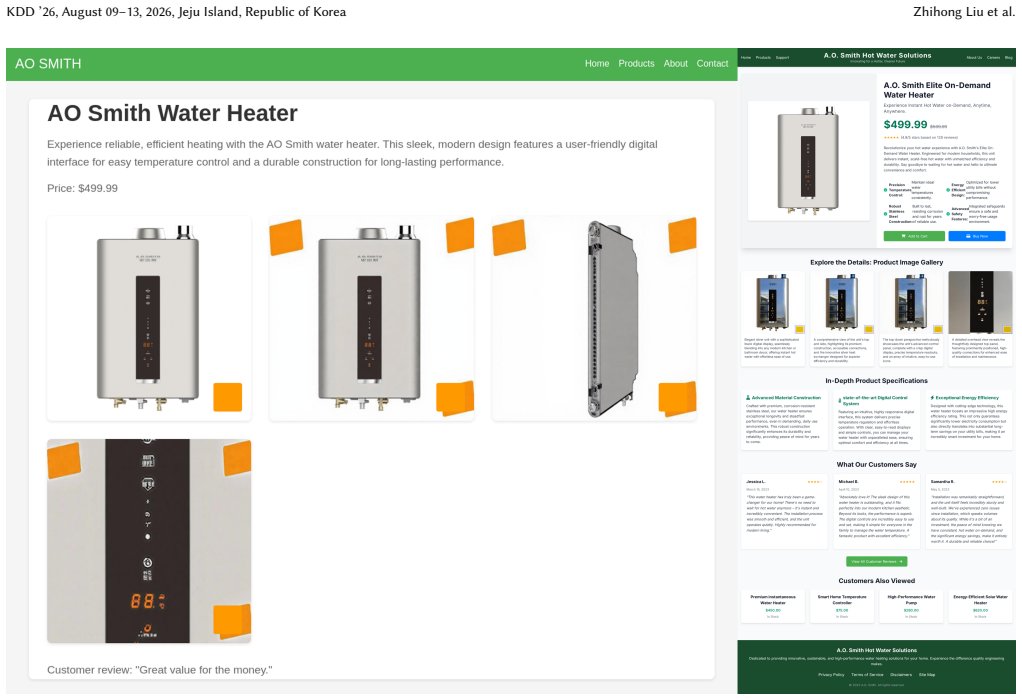
As illustrated in these examples, the original BAGEL often strug- gles with generating renderable HTML code, resulting in disordered layouts, unreasonable image sizes, and a lack of aesthetic appeal. Furthermore, it frequently fails to adhere to the visual content instructions. In contrast, BAGEL-finetuned exhibits a substantial improvement. It generates ...
2026
-
[46]
Focus only on the visual description
Abstract Meaning: Do not explain the purpose or mood. Focus only on the visual description. # Core Task Your entire focus is on the environment around the product. This can be a simple surface, a recurring prop, or a full lifestyle scene. You must be highly creative and specific, moving beyond simple colored backgrounds. # Instruction Crafting Rules
-
[47]
Be Specific: Describe the surface, props, colors, and composition in detail
-
[48]
Be AI-Friendly: Phrase the instruction as a clear description of the final images
-
[49]
across all images,
Emphasize Consistency: Use wording like "across all images," "for each image," "the exact same." # Excellent Examples of Final Instructions * "Across all images, the identical product is presented on a rough, dark slate stone surface, consistently surrounded by a few scattered fresh green moss elements." * "For each image, the product is placed on the exa...
-
[51]
Focus only on the visual description of the graphic element
Abstract Meaning: Do not explain the purpose or mood. Focus only on the visual description of the graphic element. # Core Task Your entire focus is to define the recurring graphic element. You must specify its shape, color, and its position, which must be strictly one of the four corners (top-left, top-right, bottom-left, bottom-right). # Instruction Craf...
-
[52]
**Be Specific:** Clearly state the shape, color (using natural language), and the precise corner location
-
[53]
**Be AI-Friendly:** Phrase the instruction as a clear description of the recurring graphic element in a series of images
-
[54]
in every image,
**Emphasize Consistency:** Use explicit wording like "in every image," "a recurring," "consistently placed in the," "identical." # Excellent Examples of Final Instructions * "For each image in the series, a recurring solid red rectangular block is consistently present in the bottom-left corner." * "A series of images where every image features the identic...
2026
-
[56]
Focus only on the visual description of consistency
Abstract Meaning: Do not explain the purpose or mood. Focus only on the visual description of consistency
-
[57]
# Core Task Your entire focus is to state the two core rules of consistency: the model is identical and the background is identical
Specific Actions/Poses: Do not describe the model's specific poses, angles, actions, or the camera distance. # Core Task Your entire focus is to state the two core rules of consistency: the model is identical and the background is identical. You can be creative and specific in describing a suitable background, but the instruction should not mention any ot...
-
[58]
exact same
**Be Specific:** Your instruction must explicitly mention that the model is the "exact same" and must describe a specific, consistent background (e.g.,' solid neutral gray,' 'a minimalist room setting')
-
[59]
**Be AI-Friendly:** Phrase the instruction as a clear, simple rule for a series of images
-
[60]
the exact same photo-realistic model,
**Emphasize Consistency:** This is the main point. Use explicit wording like "the exact same photo-realistic model," "in every image," "an identical background," "consistently." # Excellent Examples of Final Instructions * "For every image in the series, the exact same photo-realistic model is featured, and each image shares an identical solid, soft gray ...
-
[61]
Lighting: Avoid any mention of lighting, shadows, or illumination
-
[62]
Focus only on the visual description of the product's movement
Abstract Meaning: Do not explain the purpose or mood. Focus only on the visual description of the product's movement. # Core Task Your entire focus is to describe a rotational or tilting view of the product itself against a simple, non-distracting background. The nature of the background is secondary to the motion. # Instruction Crafting Rules
-
[63]
**Be Specific:** Clearly describe the type of rotational movement (e.g., turning on its vertical axis, tilting from top to front)
-
[64]
**Be AI-Friendly:** Phrase the instruction as a clear description of the final images'sequence
-
[65]
a series of images,
**Emphasize Movement:** Use explicit wording like "a series of images," "uniform," "seamless sequence," "incrementally rotated," "smoothly turning." # Excellent Examples of Final Instructions * "A seamless sequence of images showing the product smoothly turning from a direct front view to a 90-degree side view." * "A series of images creating a uniform ro...
2026
-
[66]
An instruction that was included in the input when generating HTML code
-
[67]
yes". - If the HTML code fails to follow the instruction, or only partially follows it, output
The generated HTML code. Your task: Determine if the HTML code fully follows the given instruction. Rules: - If the HTML code clearly and completely follows the instruction, output "yes". - If the HTML code fails to follow the instruction, or only partially follows it, output "no". - Output exactly one word: "yes" or "no" (lowercase, without punctuation, ...
2026
-
[68]
Visual hierarchy & message clarity - Are the main message, headlines, body text, and calls-to-action immediately clear and legible? Is there a distinct visual hierarchy (using size, weight, and style) that guides the user's eye through the content effectively?
-
[69]
Layout & spacing - Are content blocks clearly separated? Is there sufficient whitespace for a clean, uncluttered feel? Are column widths and line lengths optimized for comfortable reading?
-
[70]
Image sizing & cropping - Are the images sized proportionally within the layout and cropped effectively so that important visual content is fully visible ( no awkward edge-cuts or over-cropping), and image scale feels appropriate relative to surrounding elements?
-
[71]
Color harmony / palette cohesion - Are the chosen colors harmonious, consistent, and pleasant together?
-
[72]
- Do NOT output 10 for any criterion unless that aspect is near-professional, exemplary quality
Overall aesthetic appeal - Is the page overall visually attractive, balanced, and polished as a single composition? Rules: - Output ONLY a single integer (0-10) and nothing else (no labels, no explanation, no punctuation) - Use higher scores for visually clear, balanced, and professional-looking designs; use lower scores for cluttered, inconsistent, or vi...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.