Low-Resource Safety Failures Are Action Failures, Not Representation Failures
Pith reviewed 2026-06-28 16:57 UTC · model grok-4.3
The pith
Low-resource safety failures are failures to act on present harmfulness representations, not missing representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
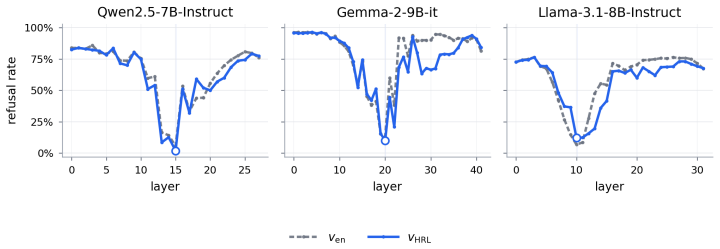
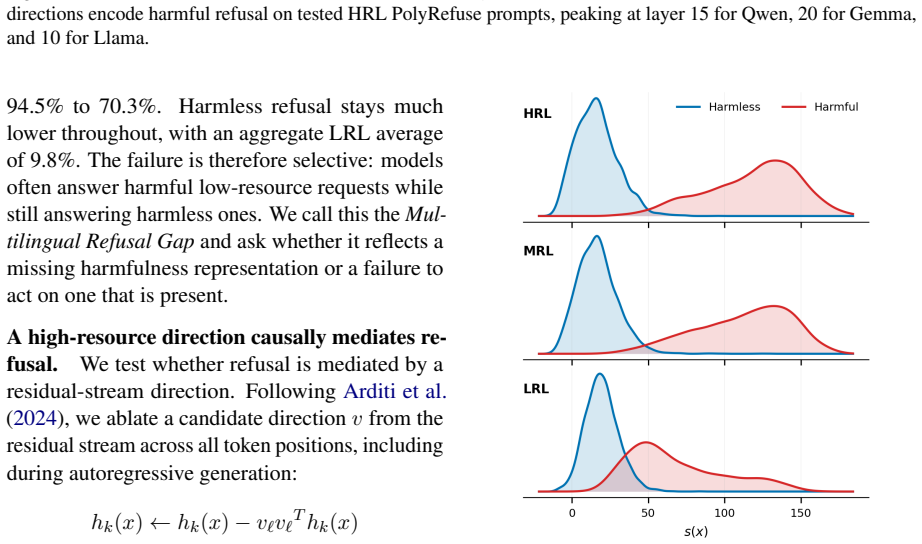
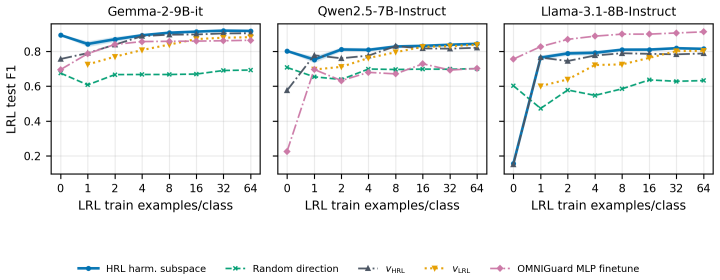
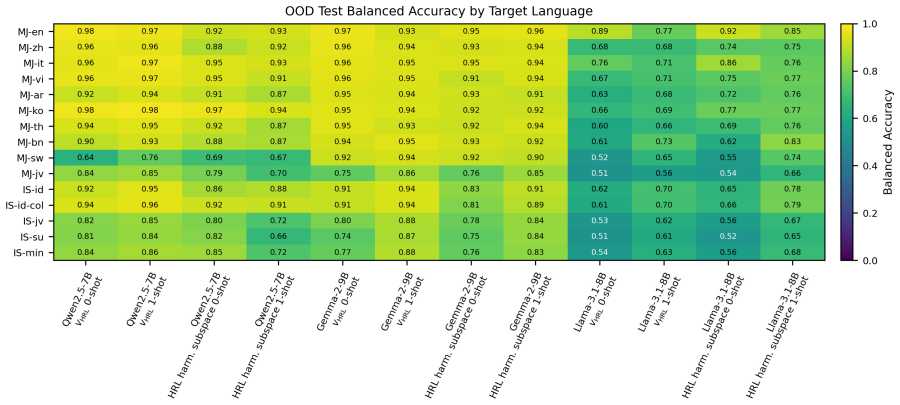
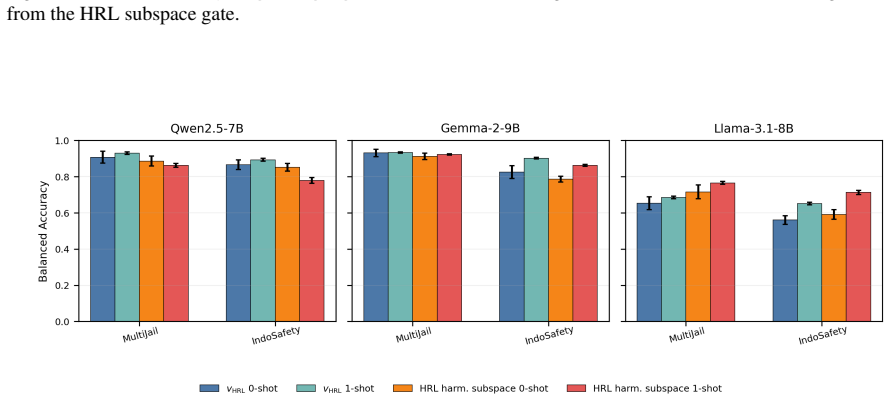
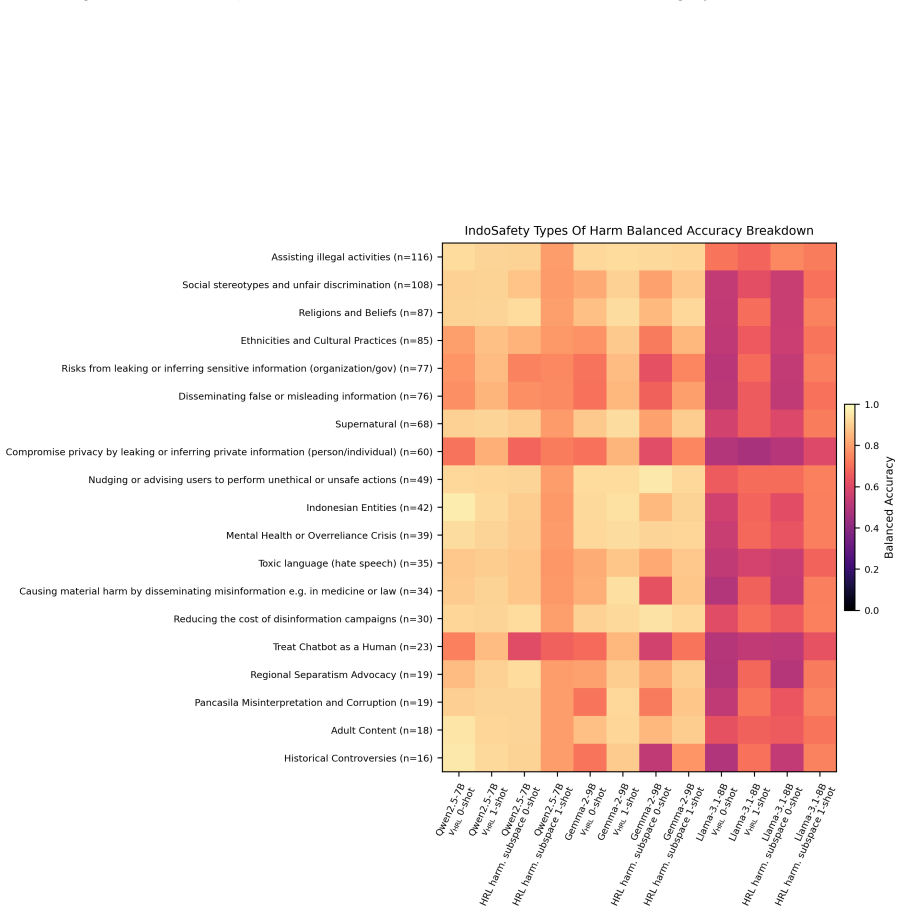
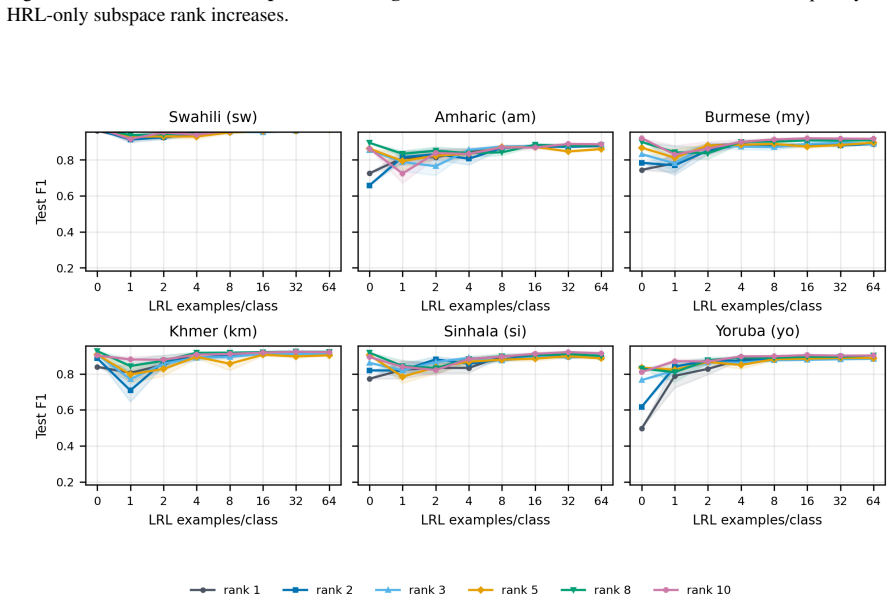
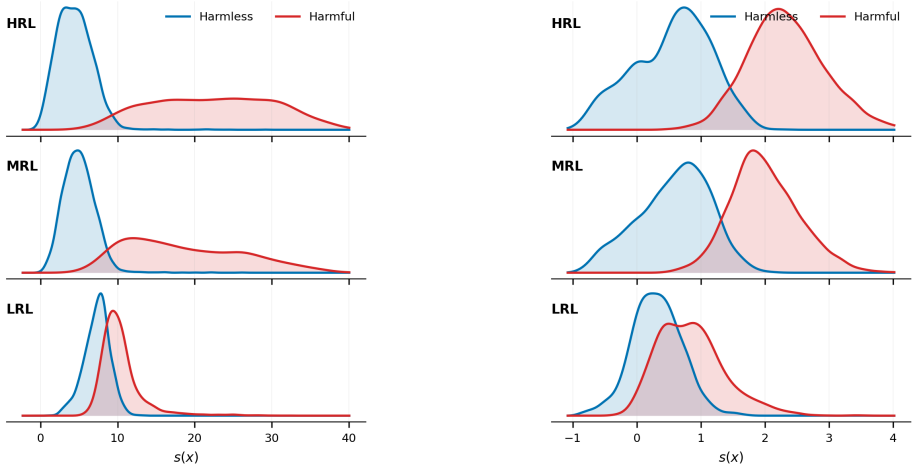
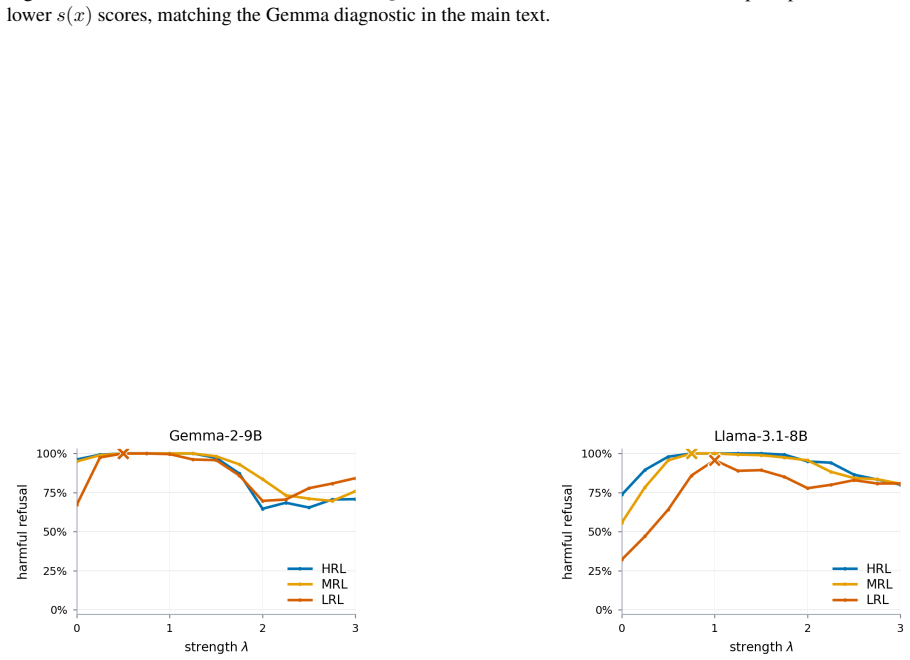
The harmfulness direction extracted from high-resource activations linearly separates harmful from harmless low-resource prompts nearly as well as high-resource ones. The relevant representation is present. Yet harmful refusal drops from 87.9% to 43.9%. The model fails to convert the representation into refusal. What fails to transfer is calibration of the safety decision, not the underlying representation. The authors exploit this by recalibrating, rather than retraining, a high-resource gate: a low-rank logistic readout with its decision threshold reset using as few as 1 to 4 target-language examples per class.
What carries the argument
A low-rank logistic readout gate built on the high-resource harmfulness direction, with its decision threshold reset on minimal target-language examples to route between refusal steering and direction ablation.
If this is right
- Recalibrating the gate raises mean refusal selectivity from 33.6 to 54.5 across the tested models.
- The recalibrated gate preserves MMLU utility while improving cross-lingual refusal.
- Adaptive steering methods such as AdaSteer and CAST inherit the same calibration failure and can be repaired by the same threshold reset.
- Some low-resource safety failures can be repaired by recalibrating existing representations rather than learning new ones.
Where Pith is reading between the lines
- The same representation-versus-calibration split may appear in other alignment dimensions such as bias or truthfulness, suggesting minimal-example recalibration as a general repair strategy.
- If the pattern holds, multilingual safety alignment could shift from expensive full retraining to lightweight threshold tuning on small target-language sets.
- Testing whether the harmfulness direction continues to separate prompts after the model is further fine-tuned on low-resource data would clarify whether the representation remains stable.
Load-bearing premise
Linear separability of harmful and harmless prompts in low-resource activations shows the representation is present and could drive refusal if only the decision threshold were adjusted.
What would settle it
If resetting the decision threshold of the high-resource harmfulness direction on 1-4 low-resource examples per class produces no increase in harmful refusal rates relative to the uncalibrated baseline, the claim that the failure is one of calibration would be falsified.
Figures










read the original abstract
Safety alignment learned in high-resource languages transfers poorly to low-resource languages. Models refuse harmful prompts in English but fail to refuse when the same prompts are translated into Swahili or Burmese. Adaptive steering methods like AdaSteer and CAST inherit this failure cross-lingually. We diagnose where transfer breaks down. Across Qwen2.5-7B, Gemma-2-9B, and Llama-3.1-8B on 23 languages, the harmfulness direction extracted from high-resource activations linearly separates harmful from harmless low-resource prompts nearly as well as high-resource ones. The relevant representation is present. Yet harmful refusal drops from 87.9% to 43.9%. The model fails to convert the representation into refusal. What fails to transfer is calibration of the safety decision, not the underlying representation. We exploit this by recalibrating, rather than retraining, a high-resource gate: a low-rank logistic readout with its decision threshold reset using as few as 1 to 4 target-language examples per class. The gate routes between refusal steering and harmfulness-direction ablation, substantially raising mean refusal selectivity ($\Delta$ = harmful $-$ harmless refusal) from 33.6 for the strongest adapted baseline to 54.5 while preserving MMLU utility. These results suggest that some low-resource safety failures can be repaired by recalibrating existing representations rather than learning new ones. Our code is released: https://github.com/rashadaziz/low-resource-safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that low-resource safety failures in LLMs (refusal rates dropping from 87.9% in high-resource to 43.9% in low-resource languages) are action/calibration failures rather than representation failures. Across Qwen2.5-7B, Gemma-2-9B, and Llama-3.1-8B on 23 languages, a harmfulness direction extracted from high-resource activations linearly separates harmful vs. harmless low-resource prompts nearly as well as high-resource ones. The authors exploit this by recalibrating a low-rank logistic readout (with decision threshold reset on 1-4 target-language examples per class) to route between refusal steering and harmfulness-direction ablation, raising mean refusal selectivity from 33.6 (strongest adapted baseline) to 54.5 while preserving MMLU. Code is released.
Significance. If the diagnosis holds, the result indicates that safety representations can transfer cross-lingually even when refusal behavior does not, enabling efficient repair via recalibration of existing components rather than new training. Consistent patterns across three models and 23 languages, plus the public code release, are strengths that support verifiability and potential impact on multilingual safety alignment.
major comments (2)
- [Abstract and §4 (linear separation experiments)] Abstract and experimental sections on linear separation: The central claim that 'the relevant representation is present' is grounded in the transferred harmfulness direction achieving high linear separation on low-resource activations. However, this remains a correlational readout result; the manuscript does not report whether causal interventions (activation steering or ablation along the same direction) in low-resource settings produce refusal-rate changes whose magnitude or sign match the high-resource case. Without this, the separation could be an incidental correlate of prompt distribution rather than the operative representation used by the model, which is load-bearing for the 'action failure, not representation failure' diagnosis.
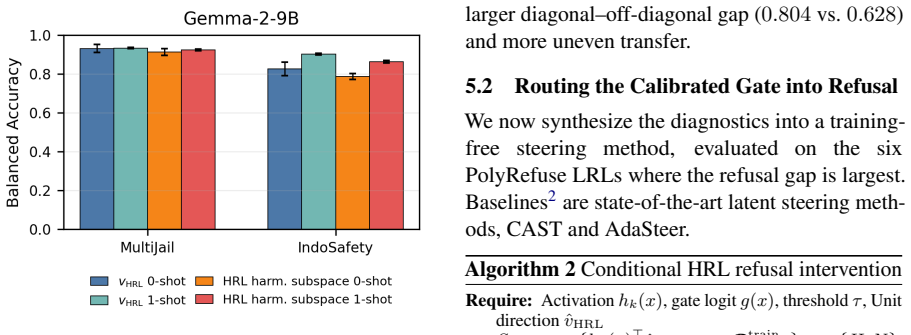
- [§5 (recalibration and selectivity results)] Results on recalibration (reported Δ from 33.6 to 54.5): The practical improvement relies on fitting a low-rank logistic readout and threshold to the small set of target-language examples. While the separation metric is presented as independent, the dependence of the selectivity gain on these fitted parameters (free parameters noted in the stress-test) should be quantified via ablation of the fitting procedure itself to isolate the contribution of recalibration.
minor comments (2)
- [Methods and results sections] The exact criteria for selecting the 23 languages, the precise definitions of all baselines (including the 'strongest adapted baseline'), and whether error bars or statistical tests accompany the refusal rates and selectivity metrics are not fully specified in the text; adding these would improve replicability.
- [§3 (methods)] Notation for the harmfulness direction and the low-rank logistic readout could be introduced with an equation or explicit definition early in the paper to aid readers in following the transfer and recalibration arguments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the positive assessment of the paper's significance, consistency across models, and code release. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §4 (linear separation experiments)] Abstract and experimental sections on linear separation: The central claim that 'the relevant representation is present' is grounded in the transferred harmfulness direction achieving high linear separation on low-resource activations. However, this remains a correlational readout result; the manuscript does not report whether causal interventions (activation steering or ablation along the same direction) in low-resource settings produce refusal-rate changes whose magnitude or sign match the high-resource case. Without this, the separation could be an incidental correlate of prompt distribution rather than the operative representation used by the model, which is load-bearing for the 'action failure, not representation failure' diagnosis.
Authors: We agree that linear separability alone is correlational and that explicit causal evidence would more directly support the claim that the transferred direction is the operative representation. The manuscript does apply the direction causally in §5 via the recalibrated gate (routing between refusal steering and harmfulness-direction ablation) and shows resulting gains in low-resource refusal selectivity. However, we did not report a direct comparison of intervention effect sizes (refusal-rate deltas) between high- and low-resource settings along this direction. We will add this analysis in the revision, including magnitude and sign comparisons, to address the concern. revision: yes
-
Referee: [§5 (recalibration and selectivity results)] Results on recalibration (reported Δ from 33.6 to 54.5): The practical improvement relies on fitting a low-rank logistic readout and threshold to the small set of target-language examples. While the separation metric is presented as independent, the dependence of the selectivity gain on these fitted parameters (free parameters noted in the stress-test) should be quantified via ablation of the fitting procedure itself to isolate the contribution of recalibration.
Authors: We agree that the selectivity improvement depends on the fitted readout and threshold, and that an ablation isolating this contribution would clarify the role of recalibration. We will add an ablation that fixes the logistic parameters and threshold to their high-resource values (no target-language fitting) and reports the resulting low-resource selectivity, thereby quantifying the incremental gain from the 1-4 examples. revision: yes
Circularity Check
No circularity: linear separability is an independent empirical measurement, not a fitted prediction or self-definition.
full rationale
The paper's central diagnostic claim—that the harmfulness representation is present in low-resource activations because the transferred high-resource direction separates harmful vs. harmless prompts nearly as well as in high-resource—rests on a direct linear probe evaluation, which is a measurement rather than a derivation that reduces to the conclusion by construction. The subsequent recalibration method fits a low-rank logistic readout and threshold on 1-4 target examples to produce an improved gate, but this is presented as an applied fix, not as evidence for the representation-presence diagnosis itself. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core separation result. The refusal-rate drop (87.9% to 43.9%) is reported as an observed failure mode independent of the probe. The derivation chain is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- safety decision threshold =
reset using 1-4 examples per class
- low-rank logistic readout parameters
axioms (1)
- domain assumption Linear separability of harmful versus harmless prompts in the extracted activation direction indicates that the underlying safety representation is present and can be acted upon once the decision threshold is properly calibrated.
Reference graph
Works this paper leans on
-
[1]
Training language models to follow instructions with human feedback
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems 35 (NeurIPS 2022) , year =. 2203.02155 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and Chen, Carol and Olsson, Catherine and Olah, Christopher and Hernandez, Danny and Drain, Dawn and Ganguli, Deep and Li, Dustin and Tran-Johnson, Eli and Perez, Ethan an...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and Bikel, Dan and Blecher, Lukas and Ferrer, Cristian Canton and Chen, Moya and Cucurull, Guillem and Esiobu, David and Fernandes, Jude and Fu, Jeremy and Fu, Wenyi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
2024 , eprint =
The. 2024 , eprint =
2024
-
[5]
2023 , eprint =
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth. 2023 , eprint =
2023
-
[6]
Penedo, Guilherme and Malartic, Quentin and Hesslow, Daniel and Cojocaru, Ruxandra and Cappelli, Alessandro and Alobeidli, Hamza and Pannier, Baptiste and Almazrouei, Ebtesam and Launay, Julien , booktitle =. The. 2023 , url =. 2306.01116 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , url =. 2304.01373 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and Presser, Shawn and Leahy, Connor , year =. The. 2101.00027 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Groeneveld, Dirk and Beltagy, Iz and Walsh, Pete and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya Harsh and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong and Arora, Shane and Atkinson, David and Authur, Russell and Chandu, Khyathi Raghavi and Cohan, Arman and Dumas, Jennifer and Elazar, Yanai and Gu, Yuling and Hessel, Jack...
-
[10]
Dolma: An Open Corpus of Three Trillion Tokens for Language Model Pretraining Research , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , url =. doi:10.18653/v1/2024.acl-long.840 , eprint =
-
[11]
Unsupervised Cross-lingual Representation Learning at Scale
Unsupervised Cross-lingual Representation Learning at Scale , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =. 2020 , url =. doi:10.18653/v1/2020.acl-main.747 , eprint =
-
[12]
Proceedings of the Twelfth Language Resources and Evaluation Conference , pages =
Wenzek, Guillaume and Lachaux, Marie-Anne and Conneau, Alexis and Chaudhary, Vishrav and Guzm. Proceedings of the Twelfth Language Resources and Evaluation Conference , pages =. 2020 , url =. 1911.00359 , archiveprefix =
-
[13]
2025 , eprint=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. 2025 , eprint=
2025
-
[14]
R. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages =. 2024 , url =. doi:10.18653/v1/2024.naacl-long.301 , eprint =
-
[15]
The Twelfth International Conference on Learning Representations , year =
Multilingual Jailbreak Challenges in Large Language Models , author =. The Twelfth International Conference on Learning Representations , year =. 2310.06474 , archiveprefix =
-
[16]
Azmi, Muhammad Falensi and Al Kautsar, Muhammad Dehan and Wicaksono, Alfan Farizki and Koto, Fajri , booktitle =. 2025 , address =. doi:10.18653/v1/2025.emnlp-main.465 , pages =
-
[17]
Low-Resource Languages Jailbreak GPT-4
Yong, Zheng-Xin and Menghini, Cristina and Bach, Stephen H. , booktitle =. Low-Resource Languages Jailbreak. 2023 , url =. 2310.02446 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Findings of the Association for Computational Linguistics: ACL 2024 , pages =
All Languages Matter: On the Multilingual Safety of Large Language Models , author =. Findings of the Association for Computational Linguistics: ACL 2024 , pages =. 2024 , url =. doi:10.18653/v1/2024.findings-acl.349 , eprint =
-
[19]
The Language Barrier: Dissecting Safety Challenges of
Shen, Lingfeng and Tan, Weiting and Chen, Sihao and Chen, Yunmo and Zhang, Jingyu and Xu, Haoran and Zheng, Boyuan and Koehn, Philipp and Khashabi, Daniel , booktitle =. The Language Barrier: Dissecting Safety Challenges of. 2024 , url =. doi:10.18653/v1/2024.findings-acl.156 , eprint =
-
[20]
Yong, Zheng Xin and Ermis, Beyza and Fadaee, Marzieh and Bach, Stephen and Kreutzer, Julia , booktitle =. The State of Multilingual. 2025 , url =. doi:10.18653/v1/2025.emnlp-main.800 , eprint =
-
[21]
2025 , eprint =
Kumar, Priyanshu and Jain, Devansh and Yerukola, Akhila and Jiang, Liwei and Beniwal, Himanshu and Hartvigsen, Thomas and Sap, Maarten , booktitle =. 2025 , eprint =
2025
-
[22]
Verma, Sahil and Hines, Keegan and Bilmes, Jeff and Siska, Charlotte and Zettlemoyer, Luke and Gonen, Hila and Singh, Chandan , booktitle =. 2025 , pages =. doi:10.18653/v1/2025.emnlp-main.819 , url =
-
[23]
Zhang, Zekai and Guo, Yiduo and Lin, Jiuheng and Quan, Shanghaoran and Zhang, Huishuai and Zhao, Dongyan , booktitle =. 2025 , address =. doi:10.18653/v1/2025.findings-emnlp.62 , url =
-
[24]
Align Once, Benefit Multilingually: Enforcing Multilingual Consistency for
Bu, Yuyan and Liu, Xiaohao and Ren, Zhaoxing and Yang, Yaodong and Dai, Juntao , booktitle =. Align Once, Benefit Multilingually: Enforcing Multilingual Consistency for. 2026 , url =. 2602.16660 , archiveprefix =
-
[25]
LASA: Language-Agnostic Semantic Alignment at the Semantic Bottleneck for LLM Safety
Yang, Junxiao and Liu, Haoran and Tu, Jinzhe and Cheng, Jiale and Zhang, Zhexin and Cui, Shiyao and Weng, Jiaqi and Tao, Jialing and Xue, Hui and Wang, Hongning and Qiu, Han and Huang, Minlie , year =. 2604.12710 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
2026 , eprint=
Multilingual Safety Alignment Via Sparse Weight Editing , author=. 2026 , eprint=
2026
-
[27]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =
Soteria: Language-Specific Functional Parameter Steering for Multilingual Safety Alignment , author =. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =. 2025 , url =. doi:10.18653/v1/2025.findings-emnlp.497 , eprint =
-
[28]
Zhao, Weixiang and Hu, Yulin and Deng, Yang and Wu, Tongtong and Zhang, Wenxuan and Guo, Jiahe and Zhang, An and Zhao, Yanyan and Qin, Bing and Chua, Tat-Seng and Liu, Ting , booktitle =. 2025 , url =. doi:10.18653/v1/2025.acl-long.1149 , eprint =
-
[29]
The Thirteenth International Conference on Learning Representations , year =
Programming Refusal with Conditional Activation Steering , author =. The Thirteenth International Conference on Learning Representations , year =. 2409.05907 , archiveprefix =
-
[30]
Refusal in Language Models Is Mediated by a Single Direction
Refusal in Language Models Is Mediated by a Single Direction , author =. Advances in Neural Information Processing Systems 37 (NeurIPS 2024) , year =. 2406.11717 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Zhao, Jiachen and Huang, Jing and Wu, Zhengxuan and Bau, David and Shi, Weiyan , booktitle =. 2025 , url =. 2507.11878 , archiveprefix =
-
[32]
Zhao, Weixiang and Guo, Jiahe and Hu, Yulin and Deng, Yang and Zhang, An and Sui, Xingyu and Han, Xinyang and Zhao, Yanyan and Qin, Bing and Chua, Tat-Seng and Liu, Ting , editor =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2025.emnlp-main.1248 , pages =
-
[33]
Marshall, Thomas and Scherlis, Adam and Belrose, Nora , year =. Refusal in. 2411.09003 , archiveprefix =
-
[34]
Proceedings of the 42nd International Conference on Machine Learning , pages =
The Geometry of Refusal in Large Language Models: Concept Cones and Representational Independence , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , url =. 2502.17420 , archiveprefix =
-
[35]
Pan, Wenbo and Liu, Zhichao and Chen, Qiguang and Zhou, Xiangyang and Yu, Haining and Jia, Xiaohua , booktitle =. The Hidden Dimensions of. 2025 , url =. 2502.09674 , archiveprefix =
-
[36]
2026 , eprint =
There Is More to Refusal in Large Language Models than a Single Direction , author =. 2026 , eprint =
2026
-
[37]
Advances in Neural Information Processing Systems 38 (NeurIPS 2025) , year =
Refusal Direction Is Universal Across Safety-Aligned Languages , author =. Advances in Neural Information Processing Systems 38 (NeurIPS 2025) , year =. 2505.17306 , archiveprefix =
-
[38]
Singh, Shivalika and Romanou, Angelika and Fourrier, Cl. Global. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2025 , url =. doi:10.18653/v1/2025.acl-long.919 , eprint =
-
[39]
2023 , eprint =
Universal and Transferable Adversarial Attacks on Aligned Language Models , author =. 2023 , eprint =
2023
-
[40]
Catastrophic Jailbreak of Open-source LLMs via Exploiting Generation
Huang, Yangsibo and Gupta, Samyak and Xia, Mengzhou and Li, Kai and Chen, Danqi , booktitle =. Catastrophic Jailbreak of Open-source. 2024 , url =. 2310.06987 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
2023 , url =
Mazeika, Mantas and Zou, Andy and Mu, Norman and Phan, Long and Wang, Zifan and Yu, Chunru and Khoja, Adam and Jiang, Fengqing and O'Gara, Aidan and Sakhaee, Ellie and Xiang, Zhen and Rajabi, Arezoo and Hendrycks, Dan and Poovendran, Radha and Li, Bo and Forsyth, David , booktitle =. 2023 , url =
2023
-
[42]
, year =
Taori, Rohan and Gulrajani, Ishaan and Zhang, Tianyi and Dubois, Yann and Li, Xuechen and Guestrin, Carlos and Liang, Percy and Hashimoto, Tatsunori B. , year =. GitHub repository , howpublished =
-
[43]
The Hidden Space of Safety: Understanding Preference-Tuned
Verma, Nikhil and Bharadwaj, Manasa , year =. The Hidden Space of Safety: Understanding Preference-Tuned. 2504.02708 , archiveprefix =
-
[44]
Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers
Wendler, Chris and Veselovsky, Veniamin and Monea, Giovanni and West, Robert , booktitle =. Do Llamas Work in. 2024 , url =. doi:10.18653/v1/2024.acl-long.820 , eprint =
-
[45]
Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2025 , url =. doi:10.18653/v1/2025.acl-long.1536 , eprint =
-
[46]
The Thirteenth International Conference on Learning Representations , year =
The Semantic Hub Hypothesis: Language Models Share Semantic Representations Across Languages and Modalities , author =. The Thirteenth International Conference on Learning Representations , year =. 2411.04986 , archiveprefix =
-
[47]
On the Non-Identifiability of Steering Vectors in Large Language Models , author =. 2026 , url =. 2602.06801 , archiveprefix =
-
[48]
2026 , eprint =
The Truthfulness Spectrum Hypothesis , author =. 2026 , eprint =
2026
-
[49]
2026 , eprint =
The Assistant Axis: Situating and Stabilizing the Default Persona of Language Models , author =. 2026 , eprint =
2026
-
[50]
Transformer Circuits Thread , year =
A Mathematical Framework for Transformer Circuits , author =. Transformer Circuits Thread , year =
-
[51]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =. 2023 , address =. doi:10.18653/v1/2023.emnlp-main.153 , pages =. 2303.16634 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.emnlp-main.153 2023
-
[52]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph and Stoica, Ion , booktitle =. Judging. 2023 , url =. 2306.05685 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.