Consistent and Distinctive: LLM Benchmark Efficiency via Maximum Independent Set Prompt Selection on Similarity Graphs
Pith reviewed 2026-06-28 16:54 UTC · model grok-4.3
The pith
Maximum independent set selection on prompt similarity graphs produces consistent LLM benchmark rankings with fewer prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Repeated application of maximum independent set algorithms to similarity graphs of benchmark prompts yields subsets that produce LLM rankings with Kendall's W at least 0.90 in 99.2% of cases, achieving 25-48% prompt reduction at higher thresholds, with ranking divergence from the full benchmark occurring in only 15.95% of configurations.
What carries the argument
Maximum Independent Set (MIS) algorithms applied to similarity graphs built from embedding-space distances between prompts, with edges for distances above a percentile threshold.
If this is right
- LLM rankings remain stable across different random seeds in stochastic MIS solvers.
- Subsets can reduce the number of prompts needed by 25 to 48 percent on average at higher thresholds.
- Most configurations maintain high correlation (rho >= 0.95) with full benchmark rankings.
- Failure modes are concentrated in dense graphs at low thresholds on certain benchmarks like GPQA and IFEval.
Where Pith is reading between the lines
- Similar graph-based reduction could be applied to other evaluation tasks beyond LLMs if embedding similarity correlates with performance correlation.
- Choosing the right percentile threshold is key to balancing reduction and fidelity, suggesting adaptive methods might improve results.
- Future work could explore dynamic thresholds or hybrid selection methods to minimize the 15.95% divergence cases.
Load-bearing premise
Embedding-space distance above a percentile threshold indicates that two prompts will produce correlated model behaviors across LLMs, making them functionally redundant.
What would settle it
An experiment showing that for a selected subset, the ranking of LLMs differs substantially from the full benchmark in a way not explained by the reported 15.95% divergence rate, or that Kendall's W falls below 0.90 in many configurations.
Figures

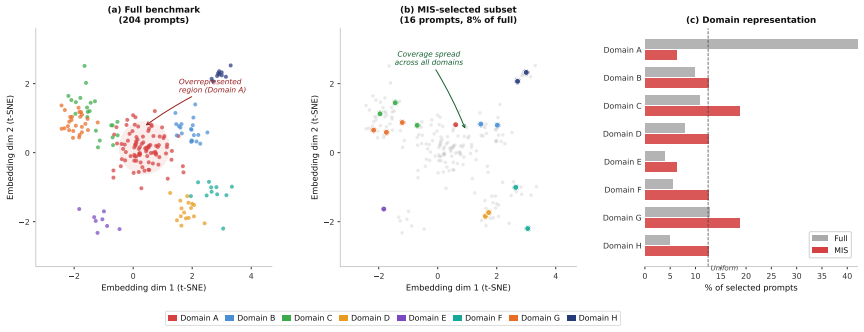
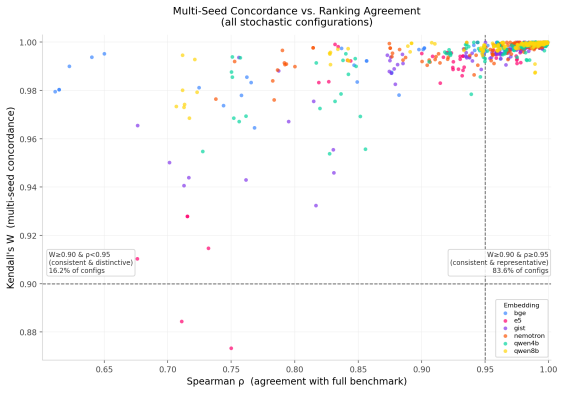
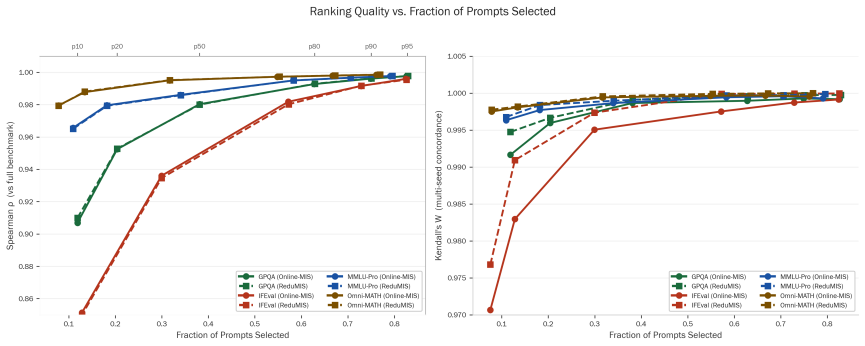
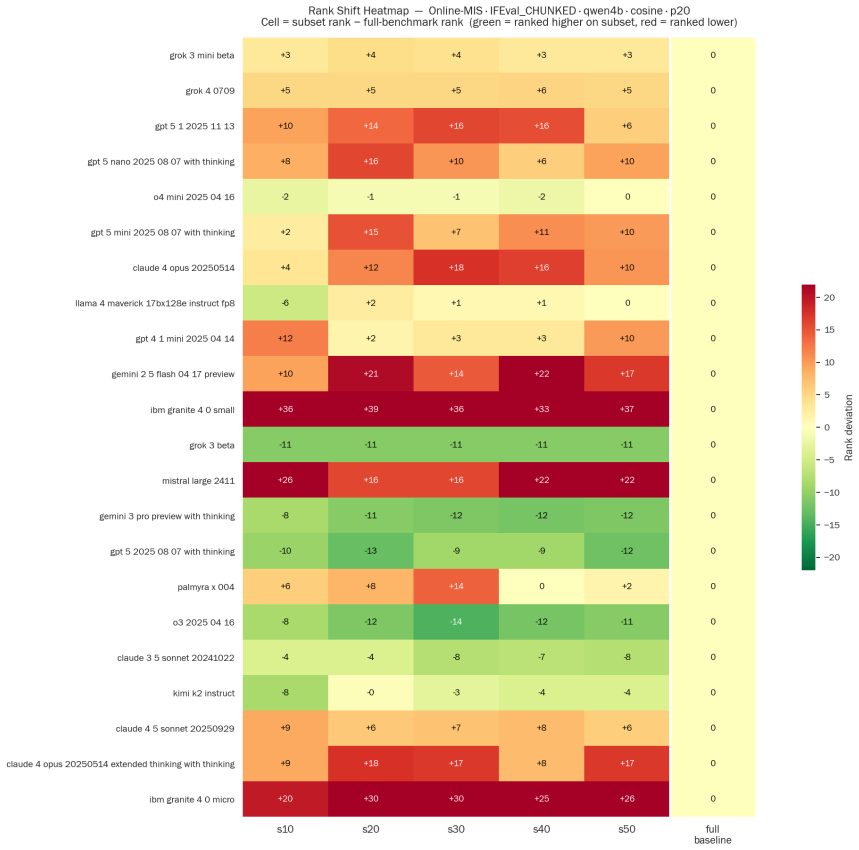
read the original abstract
Evaluating large language models (LLMs) across comprehensive benchmarks is expensive and time-consuming. We propose a graph-based prompt selection framework that models each benchmark as a similarity graph -- nodes are prompts connected if their embedding-space distance falls above a configurable threshold -- and applies Maximum Independent Set (MIS) algorithms to select a maximally diverse, non-redundant subset. We evaluate four MIS solvers (CPLEX, GREEDY, Online-MIS, ReduMIS) across six embedding models, three distance measures, six percentile thresholds, and four benchmarks (GPQA, IFEval, MMLU-Pro, Omni-MATH) covering 66 LLMs. Our central hypothesis -- that repeated selection under different random seeds yields consistent LLM rankings that may also differ from the full-benchmark baseline -- is strongly confirmed: Kendall's $W \geq 0.90$ in 99.2\% of stochastic configurations (mean $W = 0.997 \pm 0.008$), while at higher percentile thresholds selected subsets achieve 25--48\% prompt reduction on average. Ranking divergence from the full benchmark ($\rho < 0.95$) occurs in only 15.95\% of configurations, concentrated at low thresholds ($p_{10}$--$p_{20}$) and benchmarks (GPQA, IFEval), identifying overly dense graphs as the primary failure mode.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes modeling LLM benchmarks as similarity graphs where prompts are nodes connected if their embedding distances exceed a percentile threshold, then using MIS solvers (CPLEX, GREEDY, Online-MIS, ReduMIS) to extract diverse subsets. Across six embedding models, three distance measures, six thresholds, and four benchmarks (GPQA, IFEval, MMLU-Pro, Omni-MATH) with 66 LLMs, it reports that stochastic MIS selections produce highly consistent LLM rankings (Kendall's W ≥ 0.90 in 99.2% of configurations, mean W = 0.997 ± 0.008) while achieving 25–48% prompt reduction at higher thresholds, with ranking divergence from the full benchmark (ρ < 0.95) occurring in only 15.95% of cases, mainly at low thresholds.
Significance. If the embedding-distance proxy for functional redundancy holds, the method offers a practical route to cheaper yet reliable LLM evaluation with explicit failure modes identified. The work earns credit for its large-scale, multi-factor experimental design (four solvers × six embeddings × three distances × six thresholds × four benchmarks) and direct reporting of both consistency metrics and divergence rates, which supports reproducibility of the core empirical claims.
major comments (2)
- [Similarity graph construction and hypothesis statement (abstract and §3)] The central hypothesis and all reported consistency/reduction results rest on the unvalidated premise that embedding-space distance above a percentile threshold indicates functional redundancy (i.e., correlated LLM behavior across the 66 models). No analysis is provided that correlates embedding distances with pairwise Spearman correlations of per-LLM accuracy vectors, leaving open the possibility that high Kendall's W reflects stability of an arbitrary selection process rather than preservation of evaluation signal.
- [Results on ranking divergence] Table/figure reporting ranking divergence (15.95% of configurations with ρ < 0.95) measures agreement between subset and full-benchmark rankings but does not test whether the selected prompts actually preserve the relative ordering that would arise from non-redundant prompts; this makes the claim that divergence is "concentrated at low thresholds" dependent on the same untested proxy.
minor comments (2)
- [Experimental protocol] The exact procedure for handling ties or disconnected components in the MIS solvers should be stated explicitly, as it affects reproducibility of the 99.2% consistency figure.
- [Methodology] Clarify whether the six percentile thresholds are computed per-benchmark or globally, and report the resulting graph densities for each combination.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify a key area for strengthening the validation of our central hypothesis. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Similarity graph construction and hypothesis statement (abstract and §3)] The central hypothesis and all reported consistency/reduction results rest on the unvalidated premise that embedding-space distance above a percentile threshold indicates functional redundancy (i.e., correlated LLM behavior across the 66 models). No analysis is provided that correlates embedding distances with pairwise Spearman correlations of per-LLM accuracy vectors, leaving open the possibility that high Kendall's W reflects stability of an arbitrary selection process rather than preservation of evaluation signal.
Authors: We agree that the manuscript would be strengthened by an explicit validation of the embedding-distance proxy. In the revision we will add a new analysis that computes, for each benchmark, the Spearman correlation between pairwise embedding distances and the corresponding pairwise Spearman correlations of the per-LLM accuracy vectors across the 66 models. We will report these correlations (stratified by embedding model, distance measure, and threshold) and discuss their relationship to the observed Kendall's W values, thereby testing whether the graph construction captures functional redundancy rather than merely producing stable but arbitrary subsets. revision: yes
-
Referee: [Results on ranking divergence] Table/figure reporting ranking divergence (15.95% of configurations with ρ < 0.95) measures agreement between subset and full-benchmark rankings but does not test whether the selected prompts actually preserve the relative ordering that would arise from non-redundant prompts; this makes the claim that divergence is "concentrated at low thresholds" dependent on the same untested proxy.
Authors: We acknowledge that the divergence analysis inherits the same limitation. In the revised manuscript we will integrate the new correlation analysis described above with the existing divergence results. Specifically, we will examine whether configurations exhibiting low embedding-performance correlation are also those showing higher divergence rates, and we will qualify the statement that divergence is concentrated at low thresholds by referencing the strength of the proxy correlation in those regimes. This will provide a more direct link between the proxy validity and the observed divergence patterns. revision: yes
Circularity Check
No circularity: empirical ranking-consistency measurements on input graphs
full rationale
The paper constructs similarity graphs from embedding distances at chosen percentile thresholds, then runs MIS solvers and measures Kendall's W on the resulting LLM rankings across random seeds. These W values and reduction percentages are direct empirical outputs; no equation defines a target quantity in terms of a fitted parameter that is then re-measured, and no self-citation supplies a load-bearing uniqueness theorem or ansatz. The embedding-to-redundancy premise is an unvalidated modeling assumption rather than a definitional loop. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (3)
- percentile threshold p
- embedding model
- distance measure
axioms (2)
- domain assumption Embedding proximity implies functional redundancy for LLM scoring
- standard math MIS solvers produce valid independent sets on the constructed graphs
Reference graph
Works this paper leans on
-
[1]
Anand, R., Aggarwal, D., and Kumar, V. (2017). A comparative analysis of optimization solvers. Journal of Statistics and Management Systems , 20(4):623--635
2017
- [2]
-
[3]
Cenikj, G., Dieter Lang, R., Petrus Engelbrecht, A., Doerr, C., Korošec, P., and Eftimov, T. (2022). SELECTOR: Selecting a Representative Benchmark Suite for Reproducible Statistical Comparison . In Proc. of Genetic and Evolutionary Computation Conference (GECCO)
2022
-
[4]
Cenikj, G., Petelin, G., and Eftimov, T. (2024). Transoptas: Transformer-based algorithm selection for single-objective optimization. In Proceedings of the Genetic and Evolutionary Computation Conference Companion , GECCO '24 Companion, page 403–406, New York, NY, USA. Association for Computing Machinery
2024
- [5]
-
[6]
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. (2021). Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Dahlum, J., Lamm, S., Sanders, P., Schulz, C., Strash, D., and Werneck, R. F. (2016). Accelerating local search for the maximum independent set problem. In 15th International Symposium on Experimental Algorithms SEA , volume 9685 of Lecture Notes in Computer Science , pages 118--133. Springer
2016
-
[8]
Eftimov, T., Petelin, G., Cenikj, G., Kostovska, A., Ispirova, G., Korošec, P., and Bogatinovski, J. (2022). Less is more: Selecting the right benchmarking set of data for time series classification. Expert Systems with Applications , 198:116871
2022
-
[9]
Gao, B., Song, F., Yang, Z., Cai, Z., Miao, Y., Dong, Q., Li, L., Ma, C., Chen, L., Tang, Z., et al. (2025). Omni-math: A universal olympiad level mathematic benchmark for large language models. In International Conference on Learning Representations , volume 2025, pages 100540--100569
2025
-
[10]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. (2024). The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Gururangan, S., Swayamdipta, S., Levy, O., Schwartz, R., Bowman, S., and Smith, N. A. (2018). Annotation artifacts in natural language inference data. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 107--112
2018
-
[12]
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. (2021). Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al. (2023). Mistral 7b. arXiv preprint arXiv:2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Kostovska, A., Cenikj, G., Vermetten, D., Jankovic, A., Nikolikj, A., Skvorc, U., Korosec, P., Doerr, C., and Eftimov, T. (2023). Ps-aas: Portfolio selection for automated algorithm selection in black-box optimization. In International Conference on Automated Machine Learning , pages 11--1. PMLR
2023
-
[15]
Lamm, S., Sanders, P., Schulz, C., Strash, D., and Werneck, R. F. (2017). Finding near-optimal independent sets at scale. J. Heuristics , 23(4):207--229
2017
-
[16]
Landis, J. R. and Koch, G. G. (1977). The measurement of observer agreement for categorical data. biometrics , pages 159--174
1977
-
[17]
Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y., Narayanan, D., Wu, Y., Kumar, A., et al. (2022). Holistic evaluation of language models. arXiv preprint arXiv:2211.09110
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. (2024). Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Mizrahi, M., Kaplan, G., Malkin, D., Dror, R., Shahaf, D., and Stanovsky, G. (2024). State of what art? a call for multi-prompt LLM evaluation. Transactions of the Association for Computational Linguistics , 12:933--949
2024
- [20]
-
[21]
tinybenchmarks: Evaluating LLMs with fewer examples
Polo, F. M., Weber, L., Choshen, L., Sun, Y., Xu, G., and Yurochkin, M. (2024). tinybenchmarks: evaluating llms with fewer examples. arXiv preprint arXiv:2402.14992
-
[22]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y., Dirani, J., Michael, J., and Bowman, S. R. (2023). Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Schilling-Wilhelmi, M., Alampara, N., and Jablonka, K. M. (2025). Lifting the benchmark iceberg with item-response theory. In AI for Accelerated Materials Design-ICLR 2025
2025
- [24]
-
[25]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. (2023). Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [26]
-
[27]
Vivek, R., Ethayarajh, K., Yang, D., and Kiela, D. (2024). Anchor points: Benchmarking models with much fewer examples. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 1576--1601
2024
-
[28]
Wang, L., Yang, N., Huang, X., Jiao, B., Yang, L., Jiang, D., Majumder, R., and Wei, F. (2022). Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Wang, Y., Ma, X., Zhang, G., Ni, Y., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., et al. (2024). Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. Advances in Neural Information Processing Systems , 37:95266--95290
2024
-
[30]
White, C., Dooley, S., Roberts, M., Pal, A., Feuer, B., Jain, S., Shwartz-Ziv, R., Jain, N., Saifullah, K., Naidu, S., et al. (2024). Livebench: A challenging, contamination-free llm benchmark. arXiv preprint arXiv:2406.19314 , 4:2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Xiao, S., Liu, Z., Zhang, P., Muennighoff, N., Lian, D., and Nie, J.-Y. (2024). C-pack: Packed resources for general chinese embeddings. In Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages 641--649
2024
-
[32]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. (2025). Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
E., and Hardt, M
Zhang, G., Dorner, F. E., and Hardt, M. (2026). How benchmark prediction from fewer data misses the mark. Advances in Neural Information Processing Systems , 38:135638--135678
2026
-
[34]
Zhang, Y., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., Xie, P., Yang, A., Liu, D., Lin, J., et al. (2025). Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al. (2023). Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems , 36:46595--46623
2023
-
[36]
Zhou, H., Huang, H., Zhao, Z., Han, L., Wang, H., Chen, K., Yang, M., Bao, W., Dong, J., Xu, B., et al. (2026). Lost in benchmarks? rethinking large language model benchmarking with item response theory. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 40, pages 35085--35093
2026
-
[37]
Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y., Zhou, D., and Hou, L. (2023). Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.