Time-Aware Diffusion based on Preference Disentanglement for Generative Recommendation
Pith reviewed 2026-06-28 13:02 UTC · model grok-4.3
The pith
TDPM improves diffusion-based generative recommenders by disentangling user preferences into long-term period and short-term point components for time-aware diffusion on semantic indices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
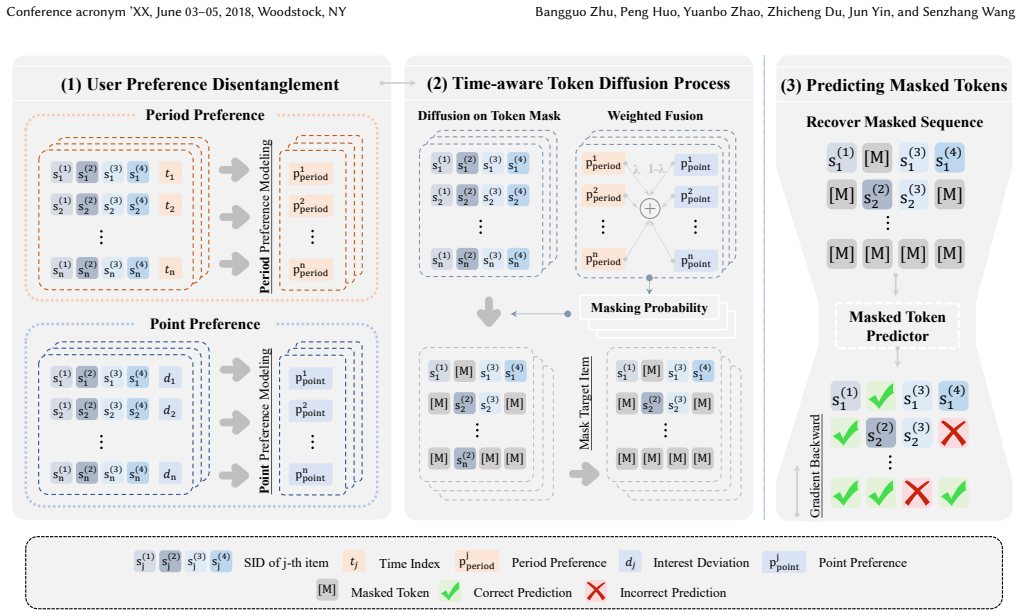
TDPM explicitly integrates the impact of time-evolving user preferences into the diffusion process by disentangling them into period preference, which remains consistent over a long time-span, and point preference, which is triggered by recent focal events.
What carries the argument
Time-aware diffusion process on SID tokens that incorporates disentangled period and point preferences.
If this is right
- Time-aware diffusion on SID tokens outperforms uniform diffusion in generative recommendation tasks.
- Disentangling preferences into period and point components better captures non-stationary user interests.
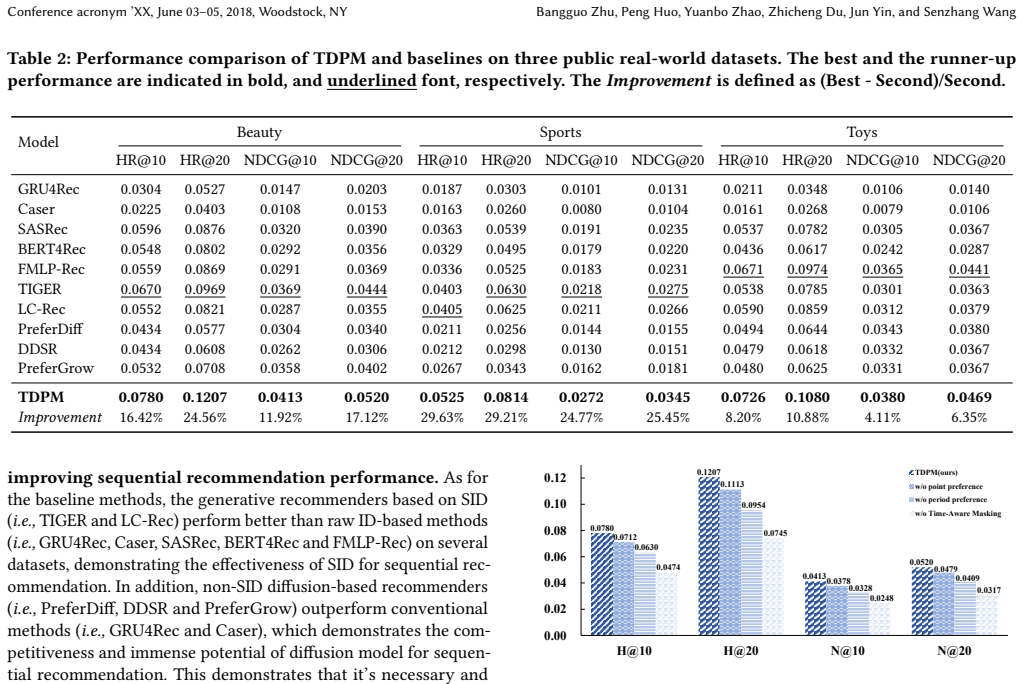
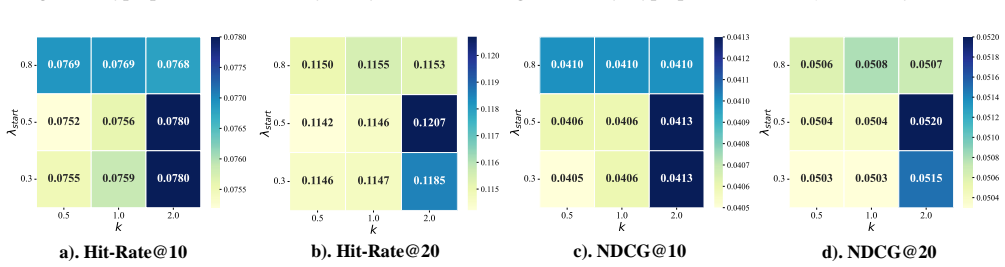
- The framework produces average improvements of up to 29.21% in HR@20 and 25.45% in NDCG@20 on three real-world datasets.
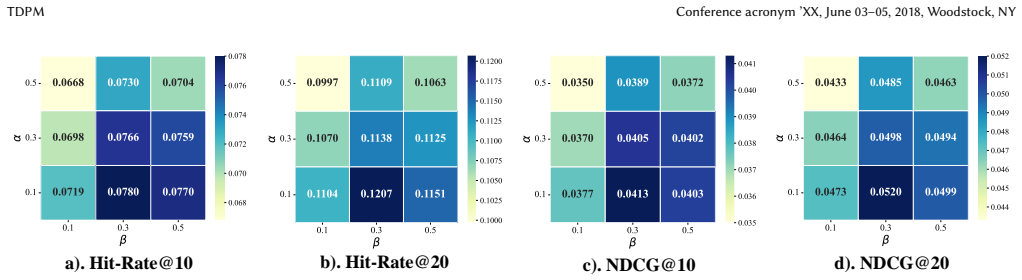
- Ablation results confirm that the time-aware token diffusion component is necessary for the observed gains.
Where Pith is reading between the lines
- The same period-point split could be tested as an add-on to other generative recommendation backbones that use semantic indices.
- The distinction may help sequential recommendation models that currently treat all history as a single sequence.
- Extending the disentanglement to include explicit event signals from external data sources could be a direct next step.
Load-bearing premise
User preferences can be meaningfully and accurately disentangled into a long-term consistent period component and a short-term event-triggered point component that can be directly incorporated into the diffusion process on SID tokens.
What would settle it
If removing the period-point disentanglement from TDPM produces no gain or worse results than uniform diffusion baselines on the same three datasets, the central claim would be falsified.
Figures

read the original abstract
Recently, Generative Recommenders (GRs) have emerged as a transformative recommendation paradigm by replacing traditional item IDs with semantic indices (SIDs). Owing to the exceptional generative capabilities of diffusion models, a few pioneering works explore developing GRs with diffusion architectures as the backbone. However, a fatal limitation of existing diffusion-based GRs is that the diffusion process applies uniformly to all items within the historical interactions. In contrast, the user preference is shaped by multifaceted time-evolving factors and thus exhibits a non-stationary distribution in the temporal aspect. To bridge this gap, this study proposes a novel GR framework, named TDPM, by designing the time-aware diffusion on SID tokens. Specifically, TDPM explicitly integrates the impact of time-evolving user preferences into the diffusion process. In detail, the user preference is disentangled into (i) the period preference, which remains consistent over a long time-span, and (ii) the point preference, which is triggered by recent focal events. Extensive experiments on three public real-world datasets demonstrate the significant superiority of TDPM over the state-of-the-art baselines. TDPM achieves average improvements of up to 29.21% and 25.45% in terms of HR@20 and NDCG@20, respectively. The ablation study further underscores the necessity of time-aware token diffusion in diffusion-based GRs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TDPM, a generative recommender framework that modifies diffusion models operating on semantic item IDs (SIDs) to incorporate time-evolving user preferences. It does so by disentangling preferences into a long-term consistent 'period preference' and a short-term 'point preference' triggered by recent events, then integrating these into the diffusion forward/reverse process. Experiments on three public datasets report average gains of up to 29.21% in HR@20 and 25.45% in NDCG@20 over state-of-the-art baselines, with an ablation study claimed to show the value of the time-aware component.
Significance. If the disentanglement is shown to be identifiable and the time-dependence is not reducible to extra conditioning capacity, the approach could meaningfully extend diffusion-based generative recommenders beyond stationary assumptions. The scale of reported gains on standard metrics suggests potential practical relevance for temporal recommendation tasks, provided the gains are attributable to the claimed mechanism rather than implementation artifacts.
major comments (3)
- [§3] §3 (Method, preference disentanglement): The description of how period and point preferences are extracted and injected into the diffusion process on SID tokens does not specify any identifiability constraint, temporal supervision signal, or separation loss. Without such a mechanism, the two components may function as parallel conditioning vectors whose separation is not enforced, undermining the claim that the diffusion process becomes meaningfully time-dependent.
- [§4] §4 (Experiments, ablation): The ablation study is referenced but does not report controls that would isolate time-awareness, such as randomizing timestamps while keeping model capacity fixed or swapping period/point labels. This leaves open whether the reported metric improvements stem from the time-aware design or from increased parameters/conditioning flexibility.
- [§3.2–3.3] §3.2–3.3 (Diffusion integration): No equations are provided showing how the disentangled preferences modify the forward noise schedule or reverse denoising steps on SID tokens. The central claim that the generative distribution becomes non-stationary therefore rests on an unverified modification to the diffusion process.
minor comments (2)
- [Abstract] The abstract describes the limitation of prior work as 'fatal'; a more measured term such as 'key limitation' would be appropriate for a technical manuscript.
- [§3] Notation for period and point preferences should be introduced with explicit symbols (e.g., p_period and p_point) at first use rather than relying on descriptive phrases alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment below, providing clarifications where the current text may have been insufficient and committing to revisions that strengthen the presentation of the time-aware diffusion mechanism without altering the core claims.
read point-by-point responses
-
Referee: [§3] §3 (Method, preference disentanglement): The description of how period and point preferences are extracted and injected into the diffusion process on SID tokens does not specify any identifiability constraint, temporal supervision signal, or separation loss. Without such a mechanism, the two components may function as parallel conditioning vectors whose separation is not enforced, undermining the claim that the diffusion process becomes meaningfully time-dependent.
Authors: The period preference is computed by aggregating a user's full interaction history over long time windows via a dedicated long-term encoder, while the point preference is computed exclusively from the most recent interactions via a short-term encoder; these representations are then injected at distinct points in the diffusion pipeline (period preference scales the base noise schedule, point preference conditions per-step denoising for recent SIDs). Although an explicit separation loss is not present, the disjoint temporal aggregation provides a natural identifiability constraint. We will revise §3 to explicitly state the extraction procedures, injection points, and the resulting time-dependent conditioning to make this separation unambiguous. revision: yes
-
Referee: [§4] §4 (Experiments, ablation): The ablation study is referenced but does not report controls that would isolate time-awareness, such as randomizing timestamps while keeping model capacity fixed or swapping period/point labels. This leaves open whether the reported metric improvements stem from the time-aware design or from increased parameters/conditioning flexibility.
Authors: The existing ablation removes the disentangled time components entirely while preserving overall model capacity and shows clear degradation, supporting the contribution of the time-aware design. We agree that additional controls (timestamp randomization and label swapping) would further isolate the effect. We will add these experiments to the revised §4 ablation study. revision: yes
-
Referee: [§3.2–3.3] §3.2–3.3 (Diffusion integration): No equations are provided showing how the disentangled preferences modify the forward noise schedule or reverse denoising steps on SID tokens. The central claim that the generative distribution becomes non-stationary therefore rests on an unverified modification to the diffusion process.
Authors: We acknowledge that the current manuscript describes the integration at a high level without the explicit update rules. In the revision we will insert the precise equations in §3.2–3.3: the forward process will be written as q(x_t | x_{t-1}, p_period) with a time-dependent variance schedule modulated by the period preference, and the reverse process as p_θ(x_{t-1} | x_t, p_point) with point-preference conditioning applied to the denoising network for non-stationary generation over SIDs. revision: yes
Circularity Check
No circularity: empirical framework proposal with no load-bearing derivation chain
full rationale
The paper proposes TDPM as a new design that disentangles preferences into period/point components and injects them into SID diffusion. No equations, first-principles derivations, or predictions are shown in the provided text. Claims rest on experimental improvements (HR@20, NDCG@20) rather than any reduction of outputs to fitted inputs or self-citations by construction. The method is presented as an architectural choice validated externally on datasets, satisfying the self-contained criterion with no identifiable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Towards psychology-aware preference construction in recommender systems: Overview and research issues.Journal of Intelligent Information Systems, 57(3):467–489, 2021
Müslüm Atas, Alexander Felfernig, Seda Polat-Erdeniz, Andrei Popescu, Thi Ngoc Trang Tran, and Mathias Uta. Towards psychology-aware preference construction in recommender systems: Overview and research issues.Journal of Intelligent Information Systems, 57(3):467–489, 2021
2021
-
[2]
Structured denoising diffusion models in discrete state-spaces.Ad- vances in neural information processing systems, 34:17981–17993, 2021
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Ad- vances in neural information processing systems, 34:17981–17993, 2021
2021
-
[3]
A review of modern recommender systems using generative models (gen-recsys)
Yashar Deldjoo, Zhankui He, Julian McAuley, Anton Korikov, Scott Sanner, Arnau Ramisa, René Vidal, Maheswaran Sathiamoorthy, Atoosa Kasirzadeh, and Silvia Milano. A review of modern recommender systems using generative models (gen-recsys). InProceedings of the 30th ACM SIGKDD conference on Knowledge Discovery and Data Mining, pages 6448–6458, 2024
2024
-
[4]
Bert: Pre- training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre- training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[5]
Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5)
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM conference on recommender systems, pages 299–315, 2022
2022
-
[6]
Generative adversarial nets
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014
2014
-
[7]
Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering
Ruining He and Julian McAuley. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. Inproceedings of the 25th international conference on world wide web, pages 507–517, 2016
2016
-
[8]
Session-based Recommendations with Recurrent Neural Networks
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[9]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[11]
Universal language model fine-tuning for text classification
Jeremy Howard and Sebastian Ruder. Universal language model fine-tuning for text classification. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 328–339, 2018
2018
-
[12]
Fading to grow: Growing preference ratios via preference fading discrete diffusion for recommendation.Advances in Neural Information Processing Systems, 38:135766–135804, 2026
Guoqing Hu, An Zhang, Shuchang Liu, Wenyu Mao, Jiancan Wu, Xun Yang, Xiang Li, Lantao Hu, Han Li, Kun Gai, et al. Fading to grow: Growing preference ratios via preference fading discrete diffusion for recommendation.Advances in Neural Information Processing Systems, 38:135766–135804, 2026
2026
-
[13]
Self-attentive sequential recommenda- tion
Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommenda- tion. In2018 IEEE international conference on data mining (ICDM), pages 197–206. IEEE, 2018
2018
-
[14]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[15]
Large language models for generative recommendation: A survey and visionary discussions
Lei Li, Yongfeng Zhang, Dugang Liu, and Li Chen. Large language models for generative recommendation: A survey and visionary discussions. InProceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024), pages 10146–10159, 2024
2024
-
[16]
Residual denoising diffusion models
Jiawei Liu, Qiang Wang, Huijie Fan, Yinong Wang, Yandong Tang, and Liangqiong Qu. Residual denoising diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2773–2783, 2024
2024
-
[17]
Preference diffusion for recommendation
Shuo Liu, An Zhang, Guoqing Hu, Hong Qian, and Tat-seng Chua. Preference diffusion for recommendation. InInternational Conference on Learning Represen- tations, volume 2025, pages 79844–79881, 2025
2025
-
[18]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Hierarchical gating networks for sequential recommendation
Chen Ma, Peng Kang, and Xue Liu. Hierarchical gating networks for sequential recommendation. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 825–833, 2019
2019
-
[20]
Using external knowledge to enhance user preferences for better sequential recommendation.Expert Systems with Applications, page 129261, 2025
Yubin Ma, Zhihong Zheng, Xuan Zhang, Zhi Jin, Weiyi Shang, Wei Cai, Chen Gao, and Linyu Li. Using external knowledge to enhance user preferences for better sequential recommendation.Expert Systems with Applications, page 129261, 2025
2025
-
[21]
Improving language understanding by generative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018
2018
-
[22]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems, 36:10299–10315, 2023
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al. Recommender systems with generative retrieval.Advances in Neural Information Processing Systems, 36:10299–10315, 2023
2023
-
[23]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[24]
Masked diffusion for generative recommendation.arXiv preprint arXiv:2511.23021, 2025
Kulin Shah, Bhuvesh Kumar, Neil Shah, and Liam Collins. Masked diffusion for generative recommendation.arXiv preprint arXiv:2511.23021, 2025
-
[25]
Teng Shi, Chenglei Shen, Weijie Yu, Shen Nie, Chongxuan Li, Xiao Zhang, Ming He, Yan Han, and Jun Xu. Llada-rec: Discrete diffusion for parallel semantic id generation in generative recommendation.arXiv preprint arXiv:2511.06254, 2025
-
[26]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInterna- tional conference on machine learning, pages 2256–2265. pmlr, 2015
2015
-
[27]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[28]
Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management, pages 1441–1450, 2019
2019
-
[29]
Personalized top-n sequential recommendation via con- volutional sequence embedding
Jiaxi Tang and Ke Wang. Personalized top-n sequential recommendation via con- volutional sequence embedding. InProceedings of the eleventh ACM international conference on web search and data mining, pages 565–573, 2018
2018
-
[30]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Xlnet4rec: Modeling user’s long-term and short-term interests in e-commerce recommender systems
Namarta Vij. Xlnet4rec: Modeling user’s long-term and short-term interests in e-commerce recommender systems. Master’s thesis, University of Windsor (Canada), 2023
2023
-
[32]
Breaking determinism: Fuzzy modeling of sequential recommendation using discrete state space diffusion model.Advances in Neural Information Processing Systems, 37:22720–22744, 2024
Wenjia Xie, Hao Wang, Luankang Zhang, Rui Zhou, Defu Lian, and Enhong Chen. Breaking determinism: Fuzzy modeling of sequential recommendation using discrete state space diffusion model.Advances in Neural Information Processing Systems, 37:22720–22744, 2024
2024
-
[33]
Geodiff: A geometric diffusion model for molecular conformation generation
Minkai Xu, Lantao Yu, Yang Song, Chence Shi, Stefano Ermon, and Jian Tang. Geodiff: A geometric diffusion model for molecular conformation generation. arXiv preprint arXiv:2203.02923, 2022
-
[34]
Diffusion models: A comprehen- sive survey of methods and applications.ACM computing surveys, 56(4):1–39, 2023
Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Wentao Zhang, Bin Cui, and Ming-Hsuan Yang. Diffusion models: A comprehen- sive survey of methods and applications.ACM computing surveys, 56(4):1–39, 2023
2023
-
[35]
Unleash llms potential for sequential recommendation by coordinating dual dynamic index mechanism
Jun Yin, Zhengxin Zeng, Mingzheng Li, Hao Yan, Chaozhuo Li, Weihao Han, Jianjin Zhang, Ruochen Liu, Hao Sun, Weiwei Deng, et al. Unleash llms potential for sequential recommendation by coordinating dual dynamic index mechanism. InProceedings of the ACM on Web Conference 2025, pages 216–227, 2025
2025
-
[36]
Echoes in Filter Bubble: Diagnosing and Curing Popularity Bias in Generative Recommenders
Jun Yin, Bangguo Zhu, Peng Huo, Ruochen Liu, Hao Chen, Senzhang Wang, Shirui Pan, and Chengqi Zhang. Echoes in filter bubble: Diagnosing and curing popularity bias in generative recommenders.arXiv preprint arXiv:2605.16825, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Adapting large language models by integrating collaborative semantics for recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. Adapting large language models by integrating collaborative semantics for recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE), pages 1435–1448. IEEE, 2024
2024
-
[39]
Filter-enhanced mlp is all you need for sequential recommendation
Kun Zhou, Hui Yu, Wayne Xin Zhao, and Ji-Rong Wen. Filter-enhanced mlp is all you need for sequential recommendation. InProceedings of the ACM web conference 2022, pages 2388–2399, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.