Echoes in Filter Bubble: Diagnosing and Curing Popularity Bias in Generative Recommenders
Pith reviewed 2026-06-30 19:40 UTC · model grok-4.3
The pith
Generative recommenders develop popularity bias from token-level optimization flaws and uniform item tokenization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
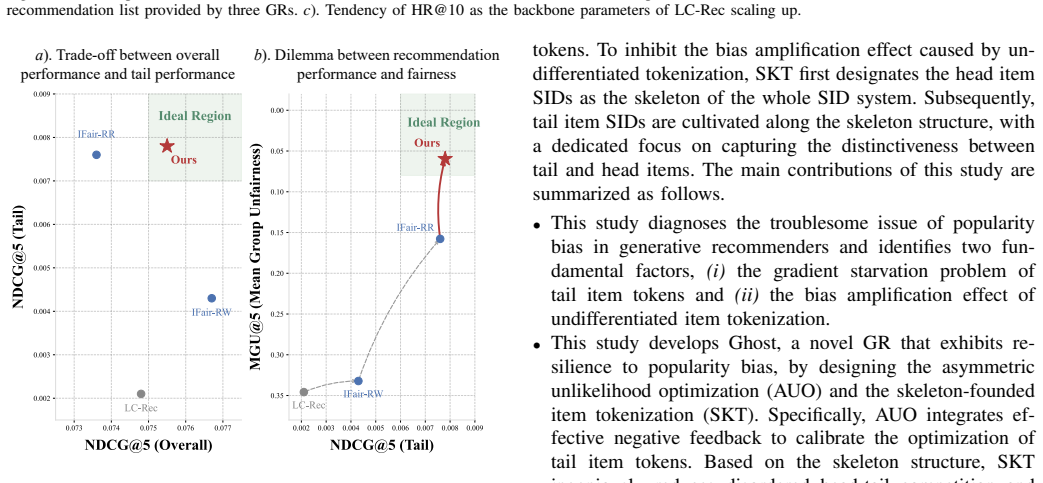
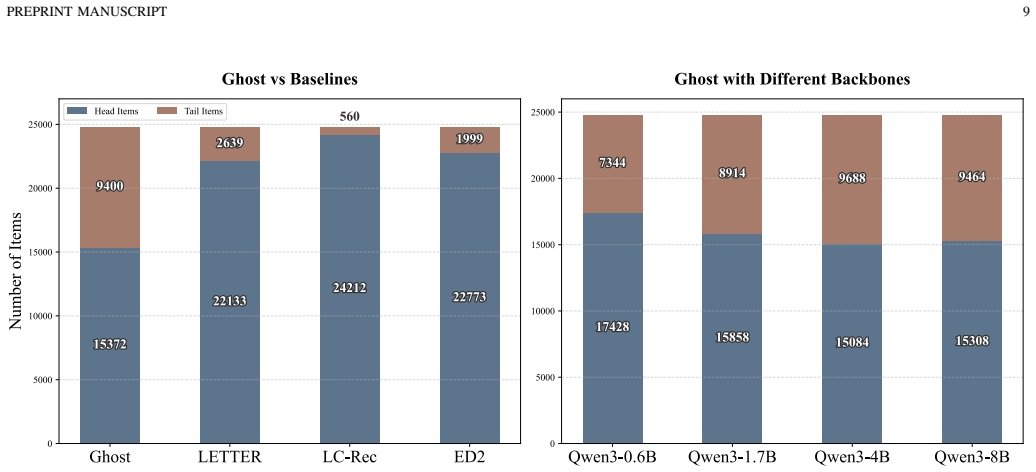
The severe popularity bias in generative recommenders emerges from the confluence of a token-level optimization flaw and the undifferentiated property of item tokenization. Ghost addresses these by using asymmetric unlikelihood optimization together with skeleton-founded tokenization, which substantially alleviates the bias and promotes fairer recommendations across multiple datasets while incurring only slight degradation to overall recommendation utility.
What carries the argument
Asymmetric unlikelihood optimization paired with skeleton-founded tokenization inside the Ghost generative recommender, which corrects the identified token-level flaw and undifferentiated encoding.
If this is right
- Ghost produces measurably fairer item exposure distributions than prior debiasing methods on the same generative architecture.
- The fixes incur only minor losses in standard ranking metrics such as recall or NDCG.
- The approach works across three different recommendation datasets against multiple strong baselines.
- Fairness gains come directly from changing the optimization and tokenization steps rather than post-hoc re-ranking.
Where Pith is reading between the lines
- Similar token-level optimization issues may appear in other generative models that output ranked lists, such as language-model-based search systems.
- The skeleton-founded tokenization idea could be tested on non-recommendation generative tasks where frequency bias distorts outputs.
- If the two flaws prove general, existing generative recommenders could be patched without full retraining by swapping only the optimization and tokenization modules.
Load-bearing premise
That the token-level optimization flaw and undifferentiated item tokenization are the main causes of popularity bias rather than other aspects of the generative framework.
What would settle it
A controlled run in which the two proposed fixes are applied yet popularity bias metrics remain unchanged or worsen.
Figures










read the original abstract
Recently, Generative Recommenders (GRs), characterized by a unified end-to-end framework, have exhibited astonishing potential in transforming the recommendation paradigm. Despite their effectiveness, we recognize that GRs are still susceptible to the long-standing issue of popularity bias that has pervaded the recommendation community. Although a few studies have attempted to extend traditional debiasing methods to GRs, their effectiveness is marginal, and the fundamental reason why GRs suffer from popularity bias remains under-explored. To bridge this gap, this study focuses on two core aspects in GRs: the optimization of generative framework and the item tokenization based on semantic index. Based on theoretical analyses, we identify that the severe popularity bias emerges from the confluence of a token-level optimization flaw and the undifferentiated property of item tokenization. Accordingly, this study develops a novel generative recommender system, called Ghost, by designing the asymmetric unlikelihood optimization and the skeleton-founded tokenization. Extensive empirical evaluations across three datasets, alongside multiple SOTA baselines, reveal that Ghost substantially alleviates popularity bias and promotes fairer recommendations, while incurring slight degradation to the overall recommendation utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that popularity bias in Generative Recommenders arises from the combination of a token-level optimization flaw and undifferentiated item tokenization based on semantic indices. It proposes the Ghost system, which introduces asymmetric unlikelihood optimization and skeleton-founded tokenization to mitigate the bias. Experiments across three datasets against multiple SOTA baselines show Ghost substantially reduces popularity bias and improves fairness while incurring only slight degradation in overall recommendation utility.
Significance. If the theoretical diagnosis and empirical results hold, the work offers a principled, targeted intervention for bias in an emerging class of end-to-end generative recommenders rather than extending ad-hoc traditional debiasing techniques. The explicit acknowledgment of the utility-fairness trade-off and the multi-dataset evaluation are strengths that increase the result's credibility and potential impact on the field.
minor comments (2)
- [Abstract] Abstract: the phrase 'theoretical analyses' is used to ground the root-cause diagnosis but receives no high-level outline; adding one sentence summarizing the key steps of the analysis would improve accessibility without lengthening the abstract.
- [Methodology] The manuscript introduces 'Ghost' as a novel system but does not explicitly contrast its two proposed components against the exact formulations of prior GR optimization and tokenization methods; a short comparative table in the methodology section would clarify the novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive recommendation for minor revision. The assessment correctly captures the core contributions regarding the diagnosis of popularity bias in generative recommenders and the proposed Ghost framework.
Circularity Check
No significant circularity detected
full rationale
The paper's derivation begins with theoretical analyses of token-level optimization and item tokenization properties, identifies them as root causes of popularity bias, and proposes Ghost with asymmetric unlikelihood optimization plus skeleton-founded tokenization. No equations or steps reduce by construction to fitted inputs renamed as predictions, no self-definitional loops appear, and no load-bearing self-citations or uniqueness theorems imported from the same authors are invoked to force the result. The central claim remains independent of its own outputs, with explicit acknowledgment of the utility-bias trade-off. This is the common case of a self-contained empirical and analytical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Theoretical analyses showing the causes of popularity bias in GRs
invented entities (1)
-
Ghost system
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Time-Aware Diffusion based on Preference Disentanglement for Generative Recommendation
TDPM is a diffusion-based generative recommender that disentangles user preferences into period and point components to enable time-aware diffusion on semantic indices, reporting up to 29% gains on HR@20 and NDCG@20 o...
Reference graph
Works this paper leans on
-
[1]
Deep interest network for click-through rate prediction,
G. Zhou, C. Song, X. Zhu, Y . Fan, H. Zhu, X. Ma, Y . Yan, J. Jin, H. Li, and K. Gai, “Deep interest network for click-through rate prediction,” inProceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018
2018
-
[2]
Deep neural networks for youtube recommendations,
P. Covington, J. Adams, and E. Sargin, “Deep neural networks for youtube recommendations,” inProceedings of the ACM Conference on Recommender Systems, 2016
2016
-
[3]
Deepinf: Social influence prediction with deep learning,
J. Qiu, J. Tang, H. Ma, Y . Dong, K. Wang, and J. Tang, “Deepinf: Social influence prediction with deep learning,” inProceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018
2018
-
[4]
Recommender systems with generative retrieval,
S. Rajput, N. Mehta, A. Singh, R. H. Keshavan, T. Vu, L. Heldt, L. Hong, Y . Tay, V . Q. Tran, J. Samost, M. Kula, E. H. Chi, and M. Sathiamoorthy, “Recommender systems with generative retrieval,” inProceedings of the International Conference on Neural Information Processing Systems, 2023
2023
-
[5]
Adapt- ing large language models by integrating collaborative semantics for recommendation,
B. Zheng, Y . Hou, H. Lu, Y . Chen, W. X. Zhao, and M. Chen, “Adapt- ing large language models by integrating collaborative semantics for recommendation,” inProceedings of the IEEE International Conference on Data Engineering, 2024
2024
-
[6]
Learnable item tokenization for generative recommendation,
W. Wang, H. Bao, X. Lin, J. Zhang, Y . Li, F. Feng, S.-K. Ng, and T.-S. Chua, “Learnable item tokenization for generative recommendation,” in Proceedings of the ACM International Conference on Information and Knowledge Management, 2024
2024
-
[7]
Unleash llms potential for sequential recommendation by coordinating dual dynamic index mechanism,
J. Yin, Z. Zeng, M. Li, H. Yan, C. Li, W. Han, J. Zhang, R. Liu, H. Sun, W. Deng, F. Sun, Q. Zhang, S. Pan, and S. Wang, “Unleash llms potential for sequential recommendation by coordinating dual dynamic index mechanism,” inProceedings of the ACM on Web Conference, 2025
2025
-
[8]
Multimodal quantitative language for generative recommendation,
J. Zhai, Z.-F. Mai, C.-D. Wang, F. Yang, X. Zheng, H. Li, and Y . Tian, “Multimodal quantitative language for generative recommendation,” in Proceedings of the International Conference on Learning Representa- tions, 2025
2025
-
[9]
Lightgcn: Simplifying and powering graph convolution network for recommenda- tion,
X. He, K. Deng, X. Wang, Y . Li, Y . Zhang, and M. Wang, “Lightgcn: Simplifying and powering graph convolution network for recommenda- tion,” inProceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, 2020
2020
-
[10]
Self-attentive sequential recommenda- tion,
W.-C. Kang and J. McAuley, “Self-attentive sequential recommenda- tion,” inProceedings of the IEEE International Conference on Data Mining, 2018
2018
-
[11]
Neural discrete representation learning,
A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural discrete representation learning,” inProceedings of the International Conference on Neural Information Processing Systems, 2017
2017
-
[12]
Autoregressive image generation using residual quantization,
D. Lee, C. Kim, S. Kim, M. Cho, and W.-S. Han, “Autoregressive image generation using residual quantization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[13]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wanget al., “Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,”Nature, vol. 645, pp. 633–638, 2025
2025
-
[14]
Llama: Open and efficient foundation language models,
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, and F. Azhar, “Llama: Open and efficient foundation language models,” 2023
2023
-
[15]
Improving language understanding by generative pre-training,
A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” 2018
2018
-
[16]
How do recommendation models amplify popularity bias? an analysis from the spectral perspective,
S. Lin, C. Gao, J. Chen, S. Zhou, B. Hu, Y . Feng, C. Chen, and C. Wang, “How do recommendation models amplify popularity bias? an analysis from the spectral perspective,” inProceedings of the ACM International Conference on Web Search and Data Mining, 2025
2025
-
[17]
Model-agnostic counterfactual reasoning for eliminating popularity bias in recommender system,
T. Wei, F. Feng, J. Chen, Z. Wu, J. Yi, and X. He, “Model-agnostic counterfactual reasoning for eliminating popularity bias in recommender system,” inProceedings of the ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021
2021
-
[18]
Popularity- opportunity bias in collaborative filtering,
Z. Zhu, Y . He, X. Zhao, Y . Zhang, J. Wang, and J. Caverlee, “Popularity- opportunity bias in collaborative filtering,” inProceedings of the ACM International Conference on Web Search and Data Mining, 2021
2021
-
[19]
Item-side fairness of large language model-based recommendation system,
M. Jiang, K. Bao, J. Zhang, W. Wang, Z. Yang, F. Feng, and X. He, “Item-side fairness of large language model-based recommendation system,” inProceedings of the ACM Web Conference, 2024
2024
-
[20]
Causally debiased time-aware recommendation,
L. Wang, C. Ma, X. Wu, Z. Qiu, Y . Zheng, and X. Chen, “Causally debiased time-aware recommendation,” inProceedings of the ACM Web Conference, 2024
2024
-
[21]
A model-agnostic popularity debias training framework for click-through rate prediction in recommender system,
F. Zhang and Q. Shen, “A model-agnostic popularity debias training framework for click-through rate prediction in recommender system,” in Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023
2023
-
[22]
Personalised reranking of paper recommendations using paper content and user behavior,
X. Li, Y . Chen, B. Pettit, and M. D. Rijke, “Personalised reranking of paper recommendations using paper content and user behavior,”ACM Transactions on Information Systems, vol. 37, no. 3, pp. 1–23, 2019
2019
-
[23]
Enhancing recommendation diversity by re-ranking with large language models,
D. Carraro and D. Bridge, “Enhancing recommendation diversity by re-ranking with large language models,”ACM Transactions on Recom- mender Systems, vol. 4, no. 2, pp. 1–40, 2025
2025
-
[24]
Miettinen,Nonlinear multiobjective optimization
K. Miettinen,Nonlinear multiobjective optimization. Springer Science & Business Media, 1999, vol. 12
1999
-
[25]
Multi-task learning with user preferences: Gradient descent with controlled ascent in pareto optimization,
D. Mahapatra and V . Rajan, “Multi-task learning with user preferences: Gradient descent with controlled ascent in pareto optimization,” in Proceedings of the International Conference on Machine Learning, 2020
2020
-
[26]
Neural collaborative filtering,
X. He, L. Liao, H. Zhang, L. Nie, X. Hu, and T.-S. Chua, “Neural collaborative filtering,” inProceedings of the International Conference on World Wide Web, 2017
2017
-
[27]
Towards fair large language model-based recommender systems with- out costly retraining,
J. Li, H. Gu, S. Wang, Q. Zhang, S. Yu, C. Wang, X. Xu, and F. Chen, “Towards fair large language model-based recommender systems with- out costly retraining,” inProceedings of the ACM Web Conference, 2026
2026
-
[28]
Bringing reasoning to generative recommendation through the lens of cascaded ranking,
X. Lin, P. Liu, W. Wang, Y . Hu, C. Xu, F. Feng, Q. Wang, and T.-S. Chua, “Bringing reasoning to generative recommendation through the lens of cascaded ranking,” inProceedings of the ACM Web Conference, 2026
2026
-
[29]
Qarm: Quantitative alignment multi-modal recommendation at kuaishou,
X. Luo, J. Cao, T. Sun, J. Yu, R. Huang, W. Yuan, H. Lin, Y . Zheng, S. Wang, Q. Hu, C. Qiu, J. Zhang, X. Zhang, Z. Yan, J. Zhang, S. Zhang, M. Wen, Z. Liu, and G. Zhou, “Qarm: Quantitative alignment multi-modal recommendation at kuaishou,” inProceedings of the ACM International Conference on Information and Knowledge Management, 2025
2025
-
[30]
Mitigating popularity bias in recommendation with unbalanced interactions: A gra- dient perspective,
W. Ren, L. Wang, K. Liu, R. Guo, L. E. Peng, and Y . Fu, “Mitigating popularity bias in recommendation with unbalanced interactions: A gra- dient perspective,” inProceedings of the IEEE International Conference on Data Mining, 2022
2022
-
[31]
Gradient starvation: A learning proclivity in neural networks,
M. Pezeshki, O. Kaba, Y . Bengio, A. C. Courville, D. Precup, and G. La- joie, “Gradient starvation: A learning proclivity in neural networks,” inProceedings of the International Conference on Neural Information Processing Systems, 2021
2021
-
[32]
Neural text generation with unlikelihood training,
S. Welleck, I. Kulikov, S. Roller, E. Dinan, K. Cho, and J. Weston, “Neural text generation with unlikelihood training,” inProceedings of the International Conference on Learning Representations, 2020
2020
-
[33]
Implicit unlikelihood train- ing: Improving neural text generation with reinforcement learning,
E. Lagutin, D. Gavrilov, and P. Kalaidin, “Implicit unlikelihood train- ing: Improving neural text generation with reinforcement learning,” in Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, 2021
2021
-
[34]
Generative recommendation with semantic ids: A practi- tioner’s handbook,
C. M. Ju, L. Collins, L. Neves, B. Kumar, L. Y . Wang, T. Zhao, and N. Shah, “Generative recommendation with semantic ids: A practi- tioner’s handbook,” inProceedings of the ACM International Conference on Information and Knowledge Management, 2025
2025
-
[35]
Bias and debias in recommender system: A survey and future directions,
J. Chen, H. Dong, X. Wang, F. Feng, M. Wang, and X. He, “Bias and debias in recommender system: A survey and future directions,”ACM Transactions on Information Systems, vol. 41, no. 3, pp. 1–39, 2023
2023
-
[36]
Recommendations as treatments: Debiasing learning and evaluation,
T. Schnabel, A. Swaminathan, A. Singh, N. Chandak, and T. Joachims, “Recommendations as treatments: Debiasing learning and evaluation,” inProceedings of the International Conference on Machine Learning, 2016
2016
-
[37]
Causal inference in recommender systems: A survey and future directions,
C. Gao, Y . Zheng, W. Wang, F. Feng, X. He, and Y . Li, “Causal inference in recommender systems: A survey and future directions,” ACM Transactions on Information Systems,, vol. 42, no. 4, pp. 1–32, 2024
2024
-
[38]
Causal intervention for leveraging popularity bias in recommendation,
Y . Zhang, F. Feng, X. He, T. Wei, C. Song, G. Ling, and Y . Zhang, “Causal intervention for leveraging popularity bias in recommendation,” inProceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, 2021
2021
-
[39]
An algorithm for vector quantizer design,
Y . Linde, A. Buzo, and R. Gray, “An algorithm for vector quantizer design,”IEEE Transactions on communications, vol. 28, no. 1, pp. 84– 95, 1980
1980
-
[40]
Taming transformers for high- resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high- resolution image synthesis,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2021, pp. 12 873– 12 883
2021
-
[41]
Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering,
R. He and J. McAuley, “Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering,” inProceedings of the International Conference on World Wide Web, 2016
2016
-
[42]
Sinkhorn distances: lightspeed computation of optimal transport,
M. Cuturi, “Sinkhorn distances: lightspeed computation of optimal transport,” inProceedings of the International Conference on Neural Information Processing Systems, vol. 2, 2013, pp. 2292–2300. PREPRINT MANUSCRIPT 12
2013
-
[43]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huanget al., “Qwen2 technical report,”arXiv preprint arXiv:2407.10671, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Qwen2.5: A party of foundation models,
Q. Team, “Qwen2.5: A party of foundation models,” September 2024. [Online]. Available: https://qwenlm.github.io/blog/qwen2.5/
2024
-
[45]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inProceedings of the International Conference on Learning Represen- tations, 2015
2015
-
[47]
Openonerec technical report.arXiv preprint arXiv:2512.24762, 2025a
G. Zhou, H. Bao, J. Huang, J. Deng, J. Zhang, J. She, K. Cai, L. Ren, L. Ren, Q. Luoet al., “Openonerec technical report,”arXiv preprint arXiv:2512.24762, 2025
-
[48]
Sprec: Self- play to debias llm-based recommendation,
C. Gao, R. Chen, S. Yuan, K. Huang, Y . Yu, and X. He, “Sprec: Self- play to debias llm-based recommendation,” inProceedings of the ACM on Web Conference, 2025. PREPRINT MANUSCRIPT 13 APPENDIXA NOTATION The notations and corresponding descriptions are summarized in Table IV. TABLE IV SUMMARY OFMATHEMATICAL ANDMODELNOTATIONS Symbol Description Symbol Descr...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.