World-Task Factorization for Robot Learning
Pith reviewed 2026-06-28 14:50 UTC · model grok-4.3
The pith
Separating world factors from task factors is the most fundamental factorization for robot policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
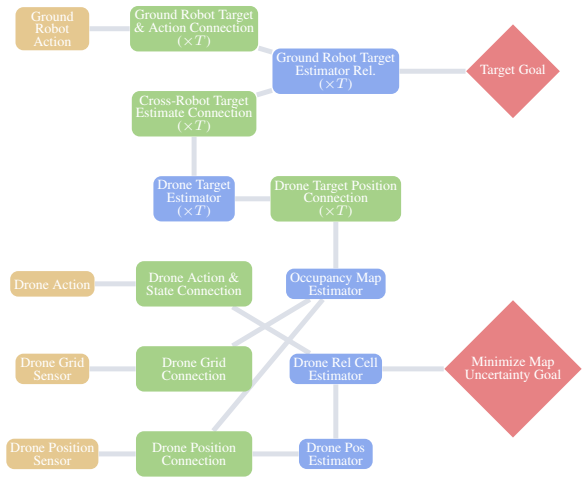
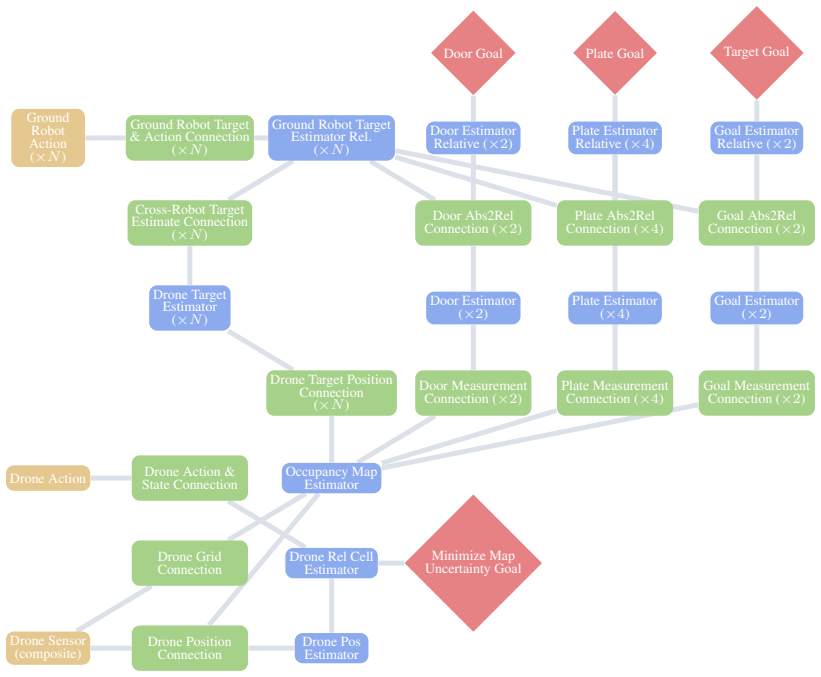
World factors are properties of the embodied system and the environment that exist independently of intent; task factors are defined by the task's logic over what the world admits. Bayesian model evidence shows this asymmetry aligns with the data-generating process, maintains high likelihood through an analytical world model, and reduces the Occam razor's penalty on task parameters. The factorization is instantiated by pairing AICON, a differentiable graph of recursive estimators and interconnections, with a compact learned policy that modulates gradient paths; gradients carry world structure through the graph and task structure through costs.
What carries the argument
World-task factorization, instantiated by an analytical differentiable graph of recursive estimators paired with a compact learned policy that modulates gradient paths.
If this is right
- Policies generalize structurally to new combinations of constraints, teammates, and environments.
- Task learning remains low-dimensional while the world model stays fixed and compositional.
- Zero-shot generalization occurs to out-of-distribution configurations without retraining.
- Policies transfer directly to real hardware without additional adaptation.
Where Pith is reading between the lines
- The same split could apply to other embodied control problems where generative structure and objectives are distinct.
- Hybrid analytical-learned systems may scale better than pure end-to-end learning when environments have stable physics.
- The gradient interface may break when task costs produce gradients that conflict with the world model's estimator assumptions.
Load-bearing premise
Gradients can carry world structure through the graph and task structure through costs without the learned policy entangling the two factors.
What would settle it
An experiment in which the world model is altered and the compact task policy must be retrained to maintain performance, or in which an end-to-end policy matches the generalization and transfer results.
Figures
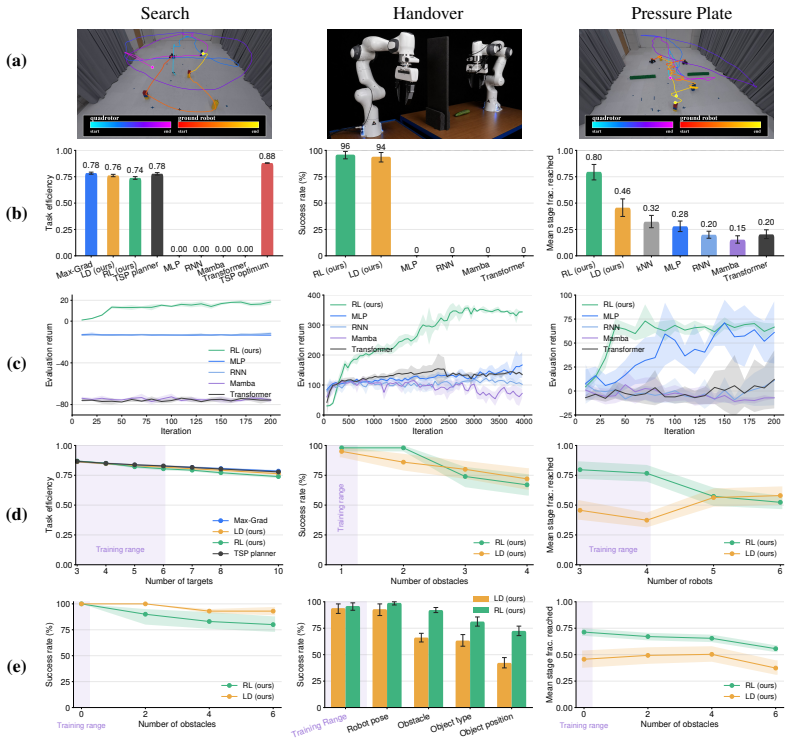

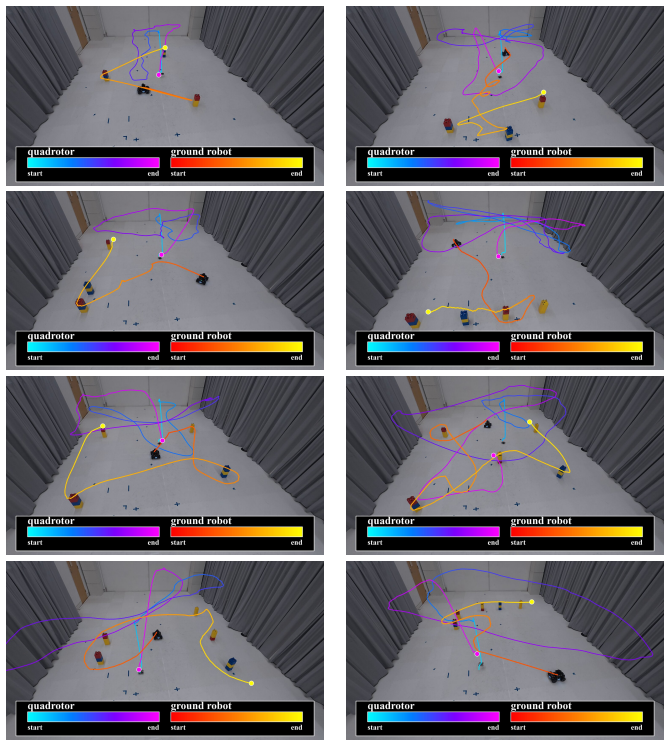
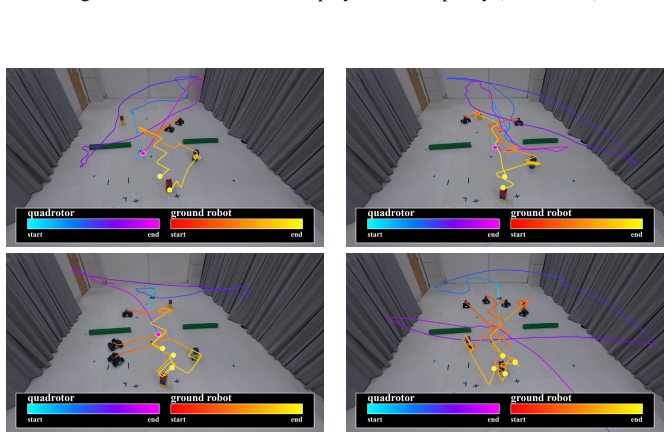
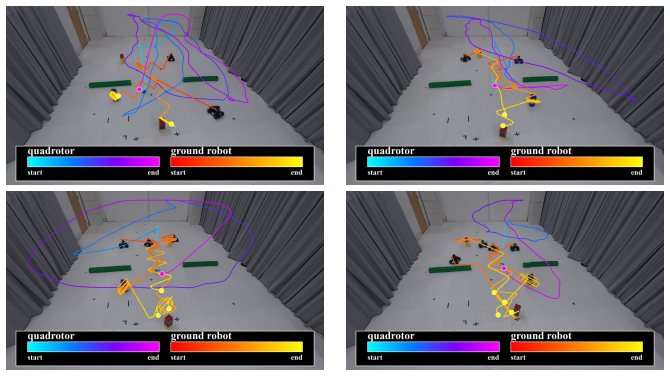
read the original abstract
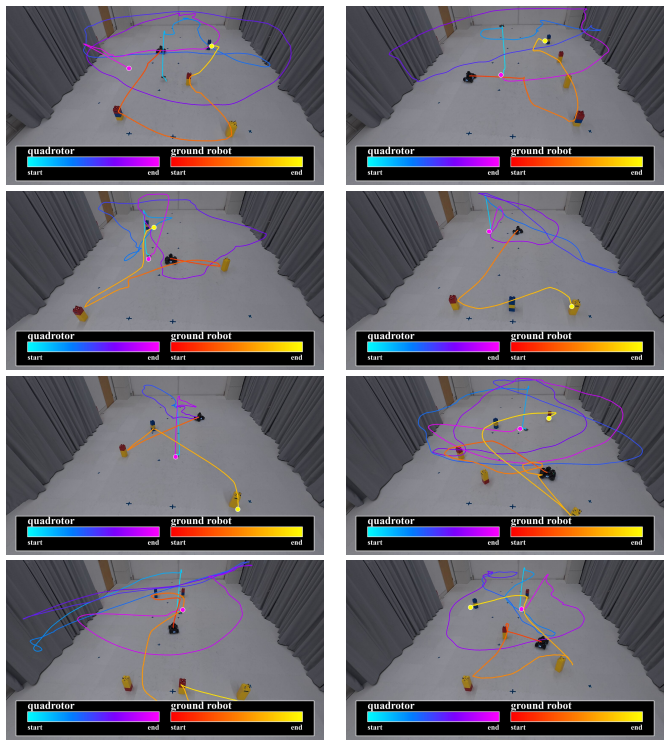
Robot learning must produce policies that generalize to new combinations of constraints, teammates, and environments. To achieve this, we must structurally factor the policy, which is a choice that dictates what generalizes, what requires retraining, and what remains entangled. Existing methods span a wide spectrum, from expecting structure to emerge from data scaling, to hand-designing it via hierarchies, skill libraries or learned specializations. In this paper, we study what we argue is the most fundamental factorization in robotics: separating the world from the task. We investigate the conditions under which this factorization is principled. World factors are properties of the embodied system and the environment; they exist independently of intent. Task factors are defined by the task's logic over what the world admits. We formalize this asymmetry through Bayesian model evidence: it aligns with the data-generating process, maintains high likelihood through an analytical world model, and reduces the Occam razor's penalty on task parameters. We instantiate this factorization by pairing AICON, a differentiable graph of recursive estimators and interconnections that is compositional, operates without task-specific data, and propagates cost gradients to actuators, with a compact, learned policy that modulates gradient paths. Gradients serve as the interface between the two factors: they carry world structure through the graph and task structure through costs, enabling low-dimensional learning while preserving structural generalization. We test the world/task factorization across three problems that encompass heterogeneous robots, environments, task logic and sensorimotor modalities. Our framework outperforms end-to-end baselines and analytical heuristics in all settings, generalizes zero-shot to out-of-distribution configurations, and transfers to real hardware without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the most fundamental factorization in robotics is separating world factors (embodied system and environment properties independent of intent) from task factors (task logic over what the world admits). This is justified via Bayesian model evidence for alignment with the data-generating process, high likelihood via an analytical world model, and reduced Occam penalty on task parameters. The factorization is instantiated by pairing the AICON differentiable graph of recursive estimators with a compact learned policy, using gradients as the interface that carries world structure through the graph and task structure through costs. Experiments across three heterogeneous problems report outperformance over end-to-end baselines and analytical heuristics, zero-shot generalization to out-of-distribution configurations, and direct hardware transfer without retraining.
Significance. If the gradient-based interface preserves the claimed separation without entanglement, the approach would offer a principled route to structural generalization and low-dimensional task learning while retaining analytical world models, potentially improving sample efficiency and transfer in robotics. The reported zero-shot generalization and hardware transfer, if robust, would strengthen the case for this factorization over purely data-driven or hand-designed alternatives.
major comments (3)
- [Abstract (instantiation paragraph)] Abstract (instantiation paragraph): the claim that 'gradients serve as the interface: they carry world structure through the graph and task structure through costs' is load-bearing for the structural generalization and Occam-penalty-reduction arguments, yet no derivation is supplied showing that gradient flow through the recursive estimators and interconnections of AICON preserves the world/task separation once task costs are attached; if back-propagation mixes information via shared state variables, the factorization benefits would not materialize.
- [Formalization of the factorization] The Bayesian model-evidence justification is presented as aligning with the data-generating process and reducing the Occam penalty on task parameters, but lacks an explicit derivation or external benchmark demonstrating that the factorization is not merely a modeling choice; this circularity risk directly affects whether the claimed principled status holds.
- [Experiments] The empirical section states outperformance and zero-shot generalization across three problems without reported error bars, statistical tests, or exclusion criteria for the baselines, making it impossible to assess whether the results support the central claim that the factorization enables the observed benefits.
minor comments (2)
- [Methods] Notation for AICON components (recursive estimators, interconnections) is introduced without a clear diagram or pseudocode in the methods, hindering reproducibility of the gradient interface.
- [Abstract] The abstract refers to 'three problems that encompass heterogeneous robots, environments, task logic and sensorimotor modalities' but does not list the specific problems or modalities until later; a table summarizing them would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and will incorporate revisions to strengthen the formal arguments and empirical reporting.
read point-by-point responses
-
Referee: [Abstract (instantiation paragraph)] Abstract (instantiation paragraph): the claim that 'gradients serve as the interface: they carry world structure through the graph and task structure through costs' is load-bearing for the structural generalization and Occam-penalty-reduction arguments, yet no derivation is supplied showing that gradient flow through the recursive estimators and interconnections of AICON preserves the world/task separation once task costs are attached; if back-propagation mixes information via shared state variables, the factorization benefits would not materialize.
Authors: We agree that an explicit derivation of separation preservation under gradient flow is required to support the load-bearing claim. The current manuscript relies on the compositional structure of AICON and the separation of world parameters (in the graph) from task costs (in the modulator), but does not derive non-entanglement through shared states. In revision we will add a dedicated subsection deriving that the recursive estimator structure and gradient interface maintain the factorization, including analysis of information flow through shared variables. revision: yes
-
Referee: [Formalization of the factorization] The Bayesian model-evidence justification is presented as aligning with the data-generating process and reducing the Occam penalty on task parameters, but lacks an explicit derivation or external benchmark demonstrating that the factorization is not merely a modeling choice; this circularity risk directly affects whether the claimed principled status holds.
Authors: The justification in the manuscript applies standard Bayesian model evidence to the world-task asymmetry by noting alignment with the data-generating process (world factors independent of intent) and the resulting Occam penalty reduction on task parameters. While this follows directly from the definitions, we acknowledge the absence of a self-contained derivation or external benchmark leaves room for a circularity concern. We will expand the formalization section with an explicit step-by-step derivation of the evidence terms and include a small-scale synthetic benchmark comparing factorized versus unfactorized model evidence on controlled data. revision: yes
-
Referee: [Experiments] The empirical section states outperformance and zero-shot generalization across three problems without reported error bars, statistical tests, or exclusion criteria for the baselines, making it impossible to assess whether the results support the central claim that the factorization enables the observed benefits.
Authors: The referee correctly identifies that the experimental reporting omits error bars, statistical tests, and explicit baseline exclusion criteria. These omissions limit the strength of the empirical claims. In the revision we will rerun all experiments with at least five random seeds, report means and standard deviations, add paired statistical tests (e.g., Wilcoxon or t-tests with corrections), and document baseline selection and exclusion criteria in a dedicated experimental protocol subsection. revision: yes
Circularity Check
No significant circularity; factorization presented as modeling choice justified by alignment argument
full rationale
The paper claims the world-task factorization is principled because Bayesian model evidence shows alignment with the data-generating process, high likelihood via an analytical world model, and reduced Occam penalty on task parameters. This is an explicit argument for the modeling choice rather than a derived prediction or first-principles result that reduces to its inputs by construction. The instantiation pairs AICON with a learned policy using gradients as interface, but the provided text contains no equations, fitted parameters renamed as predictions, or self-citations whose load-bearing content collapses to unverified prior claims by the same authors. No uniqueness theorem, ansatz smuggling, or renaming of known results is exhibited. The derivation chain is therefore self-contained as a structural modeling decision supported by the stated Bayesian rationale.
Axiom & Free-Parameter Ledger
invented entities (1)
-
AICON differentiable graph
no independent evidence
Reference graph
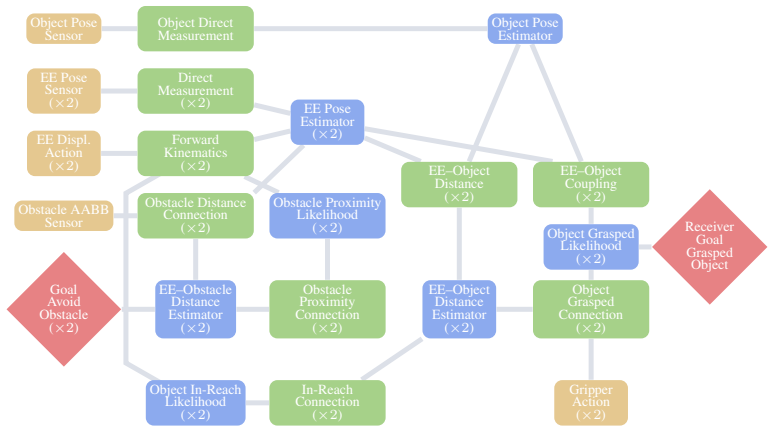
Works this paper leans on
-
[1]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, 2023
2023
-
[2]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. π0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[3]
P. W. Battaglia, J. B. Hamrick, V . Bapst, A. Sanchez-Gonzalez, V . Zambaldi, M. Malinowski, A. Tacchetti, D. Raposo, A. Santoro, R. Faulkner, et al. Relational inductive biases, deep learning, and graph networks.arXiv preprint arXiv:1806.01261, 2018
Pith/arXiv arXiv 2018
-
[4]
R. S. Sutton, D. Precup, and S. Singh. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 112(1-2):181–211, 1999
1999
-
[5]
Devin, A
C. Devin, A. Gupta, T. Darrell, P. Abbeel, and S. Levine. Learning modular neural network policies for multi-task and multi-robot transfer. InIEEE International Conference on Robotics and Automation, pages 2169–2176, 2017
2017
-
[6]
Brohan, Y
A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julian, et al. Do as I can, not as I say: Grounding language in robotic affordances. In Conference on Robot Learning, pages 287–318, 2023
2023
-
[7]
Mengers and O
V . Mengers and O. Brock. No plan but everything under control: Robustly solving sequential tasks with dynamically composed gradient descent. InIEEE International Conference on Robotics and Automation, pages 90–96, 2025
2025
-
[8]
N. D. Ratliff, J. Issac, D. Kappler, S. Birchfield, and D. Fox. Riemannian motion policies.arXiv preprint arXiv:1801.02854, 2018
Pith/arXiv arXiv 2018
-
[9]
Li, C.-A
A. Li, C.-A. Cheng, M. A. Rana, M. Xie, K. Van Wyk, N. Ratliff, and B. Boots. RMP2: A structured composable policy class for robot learning.Robotics: Science and Systems, 2021
2021
-
[10]
Pantic, I
M. Pantic, I. Meijer, R. B ¨ahnemann, N. Alatur, O. Andersson, C. Cadena, R. Siegwart, and L. Ott. Obstacle avoidance using raycasting and Riemannian motion policies at khz rates for mavs. InIEEE International Conference on Robotics and Automation, pages 1666–1672, 2023. 9
2023
-
[11]
Van Wyk, M
K. Van Wyk, M. Xie, A. Li, M. A. Rana, B. Babich, B. Peele, Q. Wan, I. Akinola, B. Sun- daralingam, D. Fox, et al. Geometric fabrics: Generalizing classical mechanics to capture the physics of behavior.IEEE Robotics and Automation Letters, 7(2):3202–3209, 2022
2022
-
[12]
Merva, S
T. Merva, S. Bakker, M. Spahn, D. Zhao, I. Virgala, and J. Alonso-Mora. Globally-guided geometric fabrics for reactive mobile manipulation in dynamic environments.IEEE Robotics and Automation Letters, 2025
2025
-
[13]
O. Khatib. Real-time obstacle avoidance for manipulators and mobile robots.The International Journal of Robotics Research, 5(1):90–98, 1986
1986
-
[14]
S. Calinon. Gaussians on Riemannian manifolds: Applications for robot learning and adaptive control.IEEE Robotics & Automation Magazine, 27(2):33–45, 2020
2020
-
[15]
M. A. Rana, A. Li, H. Ravichandar, M. Mukadam, S. Chernova, D. Fox, B. Boots, and N. Ratliff. Learning reactive motion policies in multiple task spaces from human demonstrations. In Conference on Robot Learning, pages 1457–1468. PMLR, 2020
2020
-
[16]
S. Gruffaz and J. Sassen. Riemannian metric learning: Closer to you than you imagine.arXiv preprint arXiv:2503.05321, 2025
arXiv 2025
-
[17]
Braun, N
M. Braun, N. Jaquier, L. Rozo, and T. Asfour. Riemannian flow matching policy for robot motion learning. InIEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5144–5151, 2024
2024
-
[18]
H. Ding, N. Jaquier, J. Peters, and L. Rozo. Fast and robust visuomotor riemannian flow matching policy.IEEE Transactions on Robotics, pages 5327–5343, 2025
2025
-
[19]
Tennenholtz and S
G. Tennenholtz and S. Mannor. Uncertainty estimation using riemannian model dynamics for offline reinforcement learning.Advances in Neural Information Processing Systems, 35: 19008–19021, 2022
2022
-
[20]
Y . Wang, R. Sagawa, and Y . Yoshiyasu. A hierarchical robot learning framework for manipulator reactive motion generation via multi-agent reinforcement learning and riemannian motion policies.IEEE Access, 11:126979–126994, 2023
2023
-
[21]
Alhousani, M
N. Alhousani, M. Saveriano, I. Sevinc, T. Abdulkuddus, H. Kose, and F. J. Abu-Dakka. Ge- ometric reinforcement learning for robotic manipulation.IEEE Access, 11:111492–111505, 2023
2023
-
[22]
C. Tang, B. Abbatematteo, J. Hu, R. Chandra, R. Mart ´ın-Mart´ın, and P. Stone. Deep rein- forcement learning for robotics: A survey of real-world successes.Annual Review of Control, Robotics, and Autonomous Systems, 8(1):153–188, 2025
2025
-
[23]
Hoeller, N
D. Hoeller, N. Rudin, D. Sako, and M. Hutter. ANYmal parkour: Learning agile navigation for quadrupedal robots.Science Robotics, 9(88):eadi7566, 2024
2024
-
[24]
T. Lin, Y . Zhang, Q. Li, H. Qi, B. Yi, S. Levine, and J. Malik. Learning visuotactile skills with two multifingered hands. InIEEE International Conference on Robotics and Automation, pages 5637–5643, 2025
2025
-
[25]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. OpenVLA: An open-source vision-language-action model. In Conference on Robot Learning, 2024
2024
-
[26]
Bacon, J
P.-L. Bacon, J. Harb, and D. Precup. The option-critic architecture. InProceedings of the AAAI Conference on Artificial Intelligence, volume 31, 2017. 10
2017
-
[27]
Shazeer, A
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. V . Le, G. E. Hinton, and J. Dean. Outra- geously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations, 2017
2017
-
[28]
Andreas, M
J. Andreas, M. Rohrbach, T. Darrell, and D. Klein. Neural module networks. InIEEE Conference on Computer Vision and Pattern Recognition, pages 39–48, 2016
2016
-
[29]
S. Dempe. Bilevel optimization: theory, algorithms, applications and a bibliography. InBilevel optimization: advances and next challenges, pages 581–672. Springer, 2020
2020
-
[30]
R. Liu, J. Gao, J. Zhang, D. Meng, and Z. Lin. Investigating bi-level optimization for learning and vision from a unified perspective: A survey and beyond.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(12):10045–10067, 2021
2021
-
[31]
Z. Hu, D. Shishika, X. Xiao, and X. Wang. Bi-cl: A reinforcement learning framework for robots coordination through bi-level optimization. InIEEE/RSJ International Conference on Intelligent Robots and Systems, pages 581–586, 2024
2024
-
[32]
S. Das, D. Chiu, Z. Huang, L. Lindemann, and G. S. Sukhatme. Latent activation editing: Inference-time refinement of learned policies for safer multirobot navigation.arXiv preprint arXiv:2509.20623, 2025
Pith/arXiv arXiv 2025
-
[33]
Schmied, M
T. Schmied, M. Hofmarcher, F. Paischer, R. Pascanu, and S. Hochreiter. Learning to modulate pre-trained models in RL.Advances in Neural Information Processing Systems, 36:38231– 38265, 2023
2023
-
[34]
N. O. Lambert, D. S. Drew, J. Yaconelli, S. Levine, R. Calandra, and K. S. Pister. Low-level control of a quadrotor with deep model-based reinforcement learning.IEEE Robotics and Automation Letters, 4(4):4224–4230, 2019
2019
-
[35]
Carlucho, M
I. Carlucho, M. De Paula, and G. G. Acosta. An adaptive deep reinforcement learning approach for MIMO PID control of mobile robots.ISA Transactions, 102:280–294, 2020
2020
-
[36]
L. Yang, B. Werner, M. de Sa, and A. D. Ames. CBF-RL: Safety filtering reinforcement learning in training with control barrier functions.arXiv preprint arXiv:2510.14959, 2025
Pith/arXiv arXiv 2025
-
[37]
Zhang, A
D. Zhang, A. Loquercio, J. Tang, T.-H. Wang, J. Malik, and M. W. Mueller. A learning-based quadcopter controller with extreme adaptation.IEEE Transactions on Robotics, 41:3948–3964, 2025
2025
-
[38]
C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kaelbling, and T. Lozano-P´erez. Integrated task and motion planning.Annual review of control, robotics, and autonomous systems, 4(1):265–293, 2021
2021
-
[39]
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg. Daydreamer: World models for physical robot learning. InConference on robot learning, pages 2226–2240. PMLR, 2023
2023
-
[40]
LeCun et al
Y . LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62(1):1–62, 2022
2022
-
[41]
B. Hou, G. Li, J. Jia, T. An, X. Guo, S. Leng, H. Geng, Y . Ze, T. Harada, P. Torr, et al. World model for robot learning: A comprehensive survey.arXiv preprint arXiv:2605.00080, 2026
Pith/arXiv arXiv 2026
-
[42]
D. J. MacKay. Bayesian interpolation.Neural Computation, 4(3):415–447, 1992
1992
-
[43]
D. J. MacKay.Information theory, inference, and learning algorithms. Cambridge University Press, 2003
2003
-
[44]
C. M. Bishop.Pattern recognition and machine learning. Springer, 2006. 11
2006
-
[45]
V . Mengers and O. Brock. Riding the shifting potential: When reactive control suffices for multi-goal behavior.arXiv preprint arXiv:2605.27314, 2026
Pith/arXiv arXiv 2026
-
[46]
D´esid´eri
J.-A. D´esid´eri. Multiple-gradient descent algorithm (MGDA) for multiobjective optimization. Comptes Rendus Math´ematique, 350(5–6):313–318, 2012
2012
-
[47]
Fliege and B
J. Fliege and B. F. Svaiter. Steepest descent methods for multicriteria optimization.Mathematical Methods of Operations Research, 51(3):479–494, 2000
2000
-
[48]
D. L. Applegate, R. E. Bixby, V . Chv´atal, and W. J. Cook. The traveling salesman problem: a computational study. InThe traveling salesman problem. Princeton university press, 2011
2011
-
[49]
D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Learning representations by back-propagating errors.Nature, 323(6088):533–536, 1986
1986
-
[50]
J. L. Elman. Finding structure in time.Cognitive Science, 14(2):179–211, 1990
1990
-
[51]
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2024
Pith/arXiv arXiv 2024
-
[52]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[53]
Bettini, R
M. Bettini, R. Kortvelesy, J. Blumenkamp, and A. Prorok. VMAS: A vectorized multi-agent simulator for collective robot learning. InInternational Symposium on Distributed Autonomous Robotic Systems, pages 42–56. Springer, 2022
2022
-
[54]
A. Bou, M. Bettini, S. Dittert, V . Kumar, S. Sodhani, X. Yang, G. De Fabritiis, and V . Moens. TorchRL: A data-driven decision-making library for PyTorch. InInternational Conference on Learning Representations, volume 2024, pages 1778–1811, 2024. 12 A AICON’s background AICON (Active InterCONnect) [7] is the framework we use to instantiate the world fact...
2024
-
[55]
A normalized index idr = (2r+ 1)/(2N) that provides a unique, order- agnostic label in (0,1)
Robot identifier. A normalized index idr = (2r+ 1)/(2N) that provides a unique, order- agnostic label in (0,1) . The identifiers arerandomly permutedat the start of every episode so that the policy cannot memorize a fixed mapping between identifiers and roles; instead it must learn to coordinate based on positions. 2.Proprioceptive state. The robot’s own ...
-
[56]
Global task state visible to all robots
Shared context. Global task state visible to all robots. In pressure plate, it encompasses the positions and status of both pressure plates, the door position and open/closed flag, and the goal position. In the cooperative-search task the shared context instead contains the ground-robot position, the occupancy and target grids (flattened), and a sensor-no...
-
[57]
AICON gradient features. For each of the P gradient paths (goals) in the AICON graph the first two components of the Jacobian ∇p agk are included, providing the direction of steepest cost decrease for each candidate sub-goal. The policy processes the stacked robot features through a Transformer encoder followed by two task-specific heads: • Robot branch.A...
-
[58]
A scalar index id∈ {0,1} providing a unique identifier for each robot, respectively
Robot identifier. A scalar index id∈ {0,1} providing a unique identifier for each robot, respectively
-
[59]
Local and teammate end-effector pose estimates, object and obstacle pose estimates and distances w.r.t
AICON graph state. Local and teammate end-effector pose estimates, object and obstacle pose estimates and distances w.r.t. end-effectors poses, grasp likelihoods, and in-reach likelihoods
-
[60]
Per-candidate gradient features and their null spaces for the paths exposed by the handover graph
AICON gradient features. Per-candidate gradient features and their null spaces for the paths exposed by the handover graph
-
[61]
giver”), while the second robot (the “receiver
Validity mask. A binary mask that suppresses unavailable candidate directions before action selection. The graph exposes seven candidate directions per arm: three real AICON gradient paths and four nullspace directions derived from the current steepest gradient. The joint selector receives the two arm-wise inputs and outputs an action in {1, . . . ,7}2; t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.