When Knowledge Is Not Free: Cost-Aware Evidence Selection in Retrieval-Augmented Generation
Pith reviewed 2026-06-28 15:07 UTC · model grok-4.3
The pith
When evidence sources carry access costs, standard RAG methods prove brittle and fail to improve reliably with larger budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
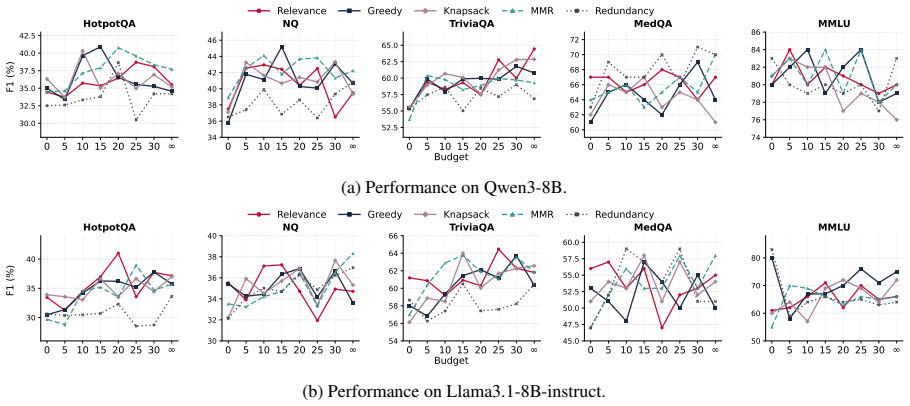
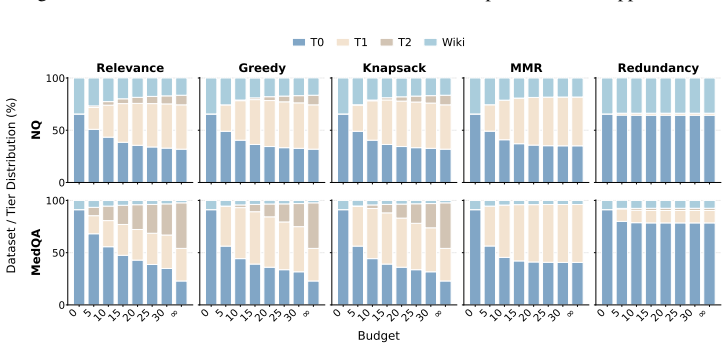
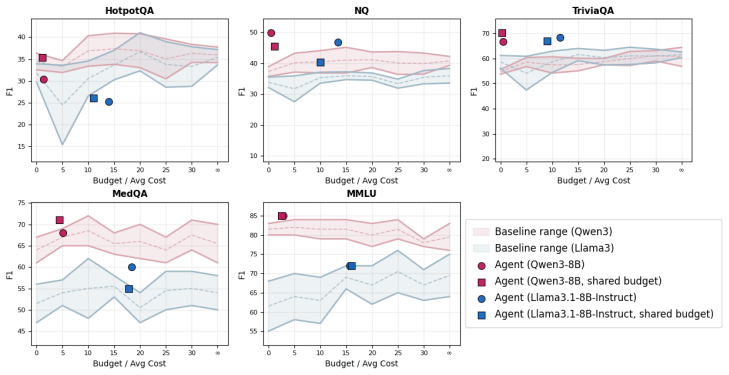
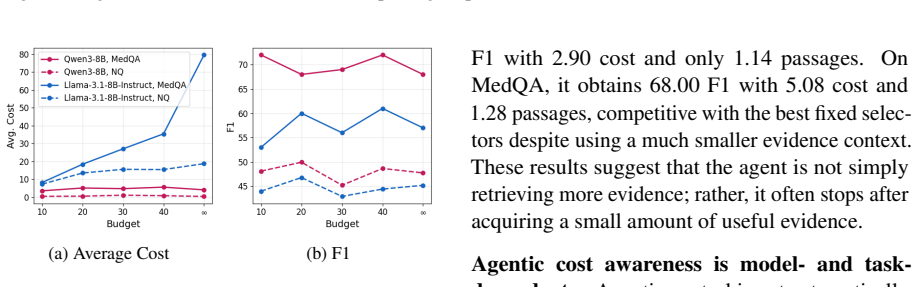
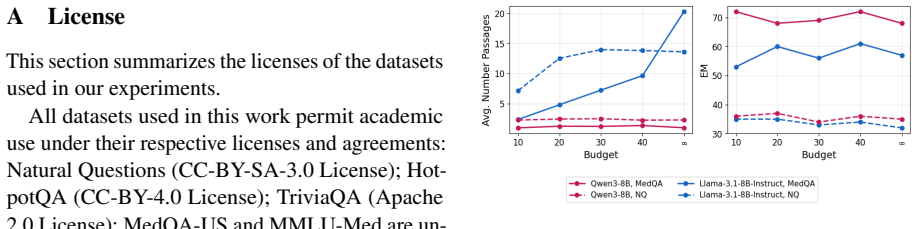
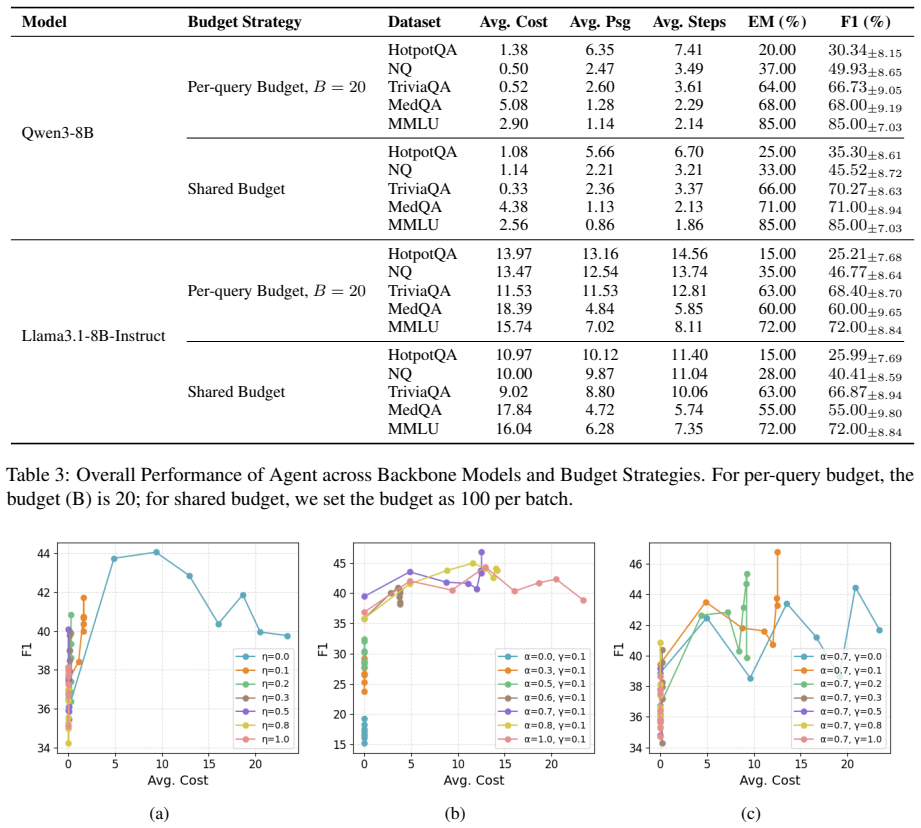
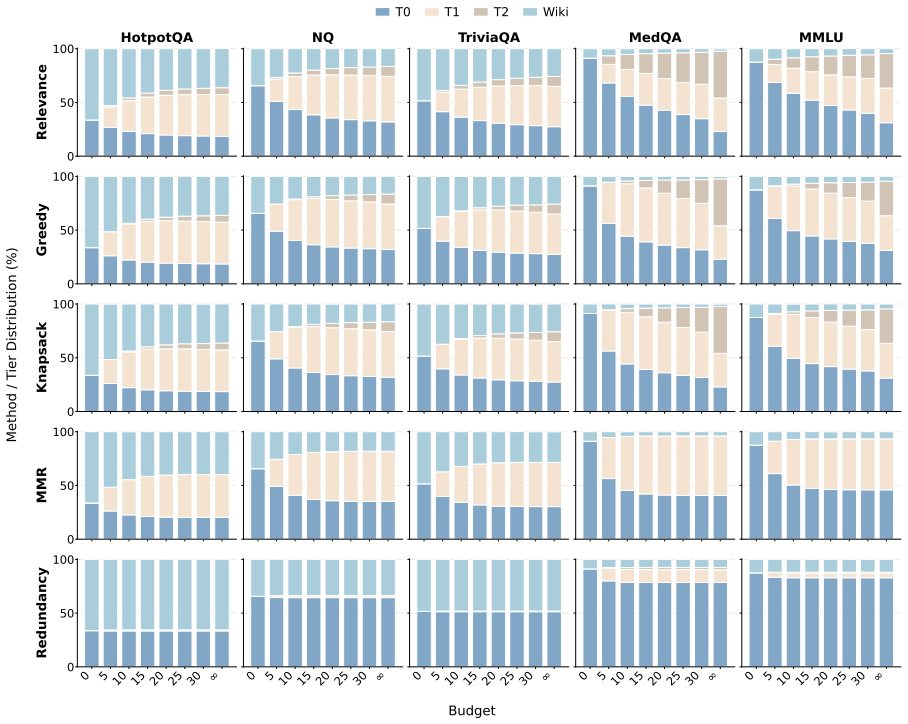
By augmenting evidence collections with access-friction tiers and evaluating under explicit budgets, the work shows that static evidence selectors are brittle—no single fixed strategy dominates across tasks—and that larger budgets do not reliably improve answer quality even when costly evidence is domain-matched. Agentic systems, in which the model itself chooses when to retrieve, which tier to access, and when to stop, demonstrate promise as adaptive controllers, yet their performance stays highly dependent on the underlying model and the specific task.
What carries the argument
The cost-aware RAG setting, where each piece of retrieved evidence receives an explicit access-cost tier and the system must generate answers while respecting a total evidence-access budget.
If this is right
- No single static evidence selector can be trusted to perform best under every task or domain.
- Increasing the evidence budget does not guarantee better answers once cost tiers are enforced.
- Agentic controllers can adapt retrieval decisions dynamically but their reliability varies sharply with model choice and task type.
- Cost-aware evidence acquisition becomes a necessary design consideration for any RAG system intended for real sources.
Where Pith is reading between the lines
- Systems may need cost signals during training or fine-tuning rather than only at inference time to learn efficient acquisition policies.
- Standard QA benchmarks could add cost as an explicit axis alongside accuracy and latency.
- Hybrid static-plus-agentic pipelines might reduce the observed model and task sensitivity.
Load-bearing premise
The assigned access-friction tiers on evidence sources reflect meaningful real-world costs and the chosen QA benchmarks represent situations where managing those costs matters.
What would settle it
A controlled test in which one fixed selector consistently produces the highest answer quality across multiple budget levels, tasks, and domains, or in which answer quality rises steadily as the budget increases even when higher-cost evidence is used.
Figures


read the original abstract
Retrieval-Augmented Generation (RAG) typically assumes that external knowledge is free, but many high-quality sources are paywalled, licensed, restricted, or otherwise costly to access. We introduce cost-aware RAG, a setting where retrieved evidence is assigned access-cost tiers and systems must answer under an explicit evidence-access budget. We instantiate this setting by augmenting MS MARCO v2.1 with access-friction tiers and evaluate budgeted evidence selection across general-domain and domain-specific QA benchmarks. Our results show that static selection is brittle: no fixed selector uniformly dominates, and larger budgets do not reliably improve answer quality, even when costly evidence is domain-matched. We then study agentic cost-aware RAG, where an LLM decides when to retrieve, which tier to access, and when to stop. Agents show strong promise as adaptive evidence-acquisition controllers, but their behavior remains highly model- and task-dependent. These findings suggest that cost-aware evidence acquisition is a central challenge for the next generation of RAG systems. All code and data are available at https://github.com/Mignonmy/Cost-Aware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a cost-aware RAG setting in which retrieved evidence carries explicit access-cost tiers and systems must answer under a budget constraint. By augmenting MS MARCO v2.1 with synthetic access-friction tiers, the authors evaluate static budgeted selectors on general-domain and domain-specific QA benchmarks and report that no fixed selector dominates and that larger budgets do not reliably improve answer quality even when costly evidence is domain-matched. They further examine agentic controllers in which an LLM decides retrieval actions, tier selection, and stopping, finding these agents promising yet highly model- and task-dependent. Code and data are released.
Significance. If the empirical patterns survive more grounded cost models, the work would establish cost-aware evidence acquisition as a central and previously under-examined dimension of practical RAG. The brittleness of static selectors and the model/task sensitivity of agents would motivate new research on adaptive, budget-aware retrieval policies. Public release of code and data is a clear strength that supports reproducibility.
major comments (2)
- [Experimental Setup / Methods] The assignment of access-friction tiers to MS MARCO v2.1 evidence is load-bearing for every claim about selector brittleness and non-monotonic budget scaling. The manuscript must supply the exact procedure (heuristics, data sources, validation) used to create the tiers; without it the reported non-monotonicity and the statement that “costly evidence is domain-matched” cannot be interpreted as properties of real-world cost-aware RAG rather than artifacts of the synthetic tier distribution.
- [Results (budget-scaling experiments)] The central finding that larger budgets do not reliably improve answer quality (even with domain-matched costly evidence) is presented without reported variance across runs, statistical significance tests, or sensitivity analysis to the tier distribution. This weakens the cross-budget and cross-selector claims; the results section should include these diagnostics.
minor comments (2)
- [Abstract] The abstract would be strengthened by naming the concrete QA benchmarks and the primary answer-quality metric(s) used.
- [Agentic cost-aware RAG] The agentic decision space (when to retrieve, which tier to access, when to stop) should be illustrated with pseudocode or a state diagram to make the controller reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the experimental setup and results. We address each major comment below and will revise the manuscript to incorporate the requested details and diagnostics.
read point-by-point responses
-
Referee: [Experimental Setup / Methods] The assignment of access-friction tiers to MS MARCO v2.1 evidence is load-bearing for every claim about selector brittleness and non-monotonic budget scaling. The manuscript must supply the exact procedure (heuristics, data sources, validation) used to create the tiers; without it the reported non-monotonicity and the statement that “costly evidence is domain-matched” cannot be interpreted as properties of real-world cost-aware RAG rather than artifacts of the synthetic tier distribution.
Authors: We agree that the tier assignment procedure is central to interpreting the results and must be described in detail. The current manuscript provides only a high-level description of the augmentation. In the revision we will add a dedicated subsection (in the Experimental Setup) that specifies the exact heuristics, any external data sources consulted, and validation steps used to assign access-friction tiers to MS MARCO v2.1 passages. This addition will allow readers to evaluate whether the observed selector brittleness and non-monotonic budget effects are artifacts of the synthetic distribution or reflect plausible real-world cost structures. revision: yes
-
Referee: [Results (budget-scaling experiments)] The central finding that larger budgets do not reliably improve answer quality (even with domain-matched costly evidence) is presented without reported variance across runs, statistical significance tests, or sensitivity analysis to the tier distribution. This weakens the cross-budget and cross-selector claims; the results section should include these diagnostics.
Authors: We acknowledge that the budget-scaling claims would be more robust with explicit variance reporting, statistical tests, and sensitivity checks. In the revised results section we will add (i) standard deviations or error bars computed over multiple independent runs, (ii) appropriate statistical significance tests for cross-budget and cross-selector comparisons, and (iii) a sensitivity analysis that varies the tier distribution parameters and reports how the non-monotonicity pattern changes. These diagnostics will be included for both the general-domain and domain-specific benchmarks. revision: yes
Circularity Check
No circularity: empirical evaluation of new cost-aware RAG setting
full rationale
The paper introduces cost-aware RAG by augmenting MS MARCO v2.1 with synthetic access-friction tiers and reports empirical results from budgeted selection and agentic controllers on standard QA benchmarks. No equations, predictions, or central claims reduce by construction to prior fitted parameters or self-citation chains; all load-bearing observations are produced by fresh runs on the augmented data. This is self-contained empirical work with no detectable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Galen Andrew and Jianfeng Gao , editor =. Scalable training of L\(. Machine Learning, Proceedings of the Twenty-Fourth International Conference. 2007 , url =. doi:10.1145/1273496.1273501 , timestamp =
-
[5]
doi:10.1017/cbo9780511574931 , isbn = 9780511574931, publisher =
Dan Gusfield , title =. 1997 , url =. doi:10.1017/CBO9780511574931 , isbn =
-
[6]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. CoRR , volume =. 2015 , url =. 1503.06733 , timestamp =
Pith/arXiv arXiv 2015
-
[7]
Rie Kubota Ando and Tong Zhang , title =. J. Mach. Learn. Res. , volume =. 2005 , url =
2005
-
[8]
Factorizing Content and Budget Decisions in Abstractive Summarization of Long Documents
Fonseca, Marcio and Ziser, Yftah and Cohen, Shay B. Factorizing Content and Budget Decisions in Abstractive Summarization of Long Documents. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.426
-
[9]
Narasimhan and Yuan Cao , title =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R. Narasimhan and Yuan Cao , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[10]
DeepNote: Note-Centric Deep Retrieval-Augmented Generation , booktitle =
Ruobing Wang and Qingfei Zhao and Yukun Yan and Daren Zha and Yuxuan Chen and Shi Yu and Zhenghao Liu and Yixuan Wang and Shuo Wang and Xu Han and Zhiyuan Liu and Maosong Sun , editor =. DeepNote: Note-Centric Deep Retrieval-Augmented Generation , booktitle =. 2025 , url =
2025
-
[11]
The Twelfth International Conference on Learning Representations,
Akari Asai and Zeqiu Wu and Yizhong Wang and Avirup Sil and Hannaneh Hajishirzi , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[12]
Xu and Luyu Gao and Zhiqing Sun and Qian Liu and Jane Dwivedi
Zhengbao Jiang and Frank F. Xu and Luyu Gao and Zhiqing Sun and Qian Liu and Jane Dwivedi. Active Retrieval Augmented Generation , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.495 , timestamp =
-
[13]
T urbo RAG : Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text
Lu, Songshuo and Wang, Hua and Rong, Yutian and Chen, Zhi and Tang, Yaohua. T urbo RAG : Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.334
-
[14]
Tri Nguyen and Mir Rosenberg and Xia Song and Jianfeng Gao and Saurabh Tiwary and Rangan Majumder and Li Deng , editor =. Proceedings of the Workshop on Cognitive Computation: Integrating neural and symbolic approaches 2016 co-located with the 30th Annual Conference on Neural Information Processing Systems. 2016 , url =
2016
-
[15]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie. LLaMA: Open and Efficient Foundation Language Models , journal =. 2023 , url =. doi:10.48550/ARXIV.2302.13971 , eprinttype =. 2302.13971 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[16]
Qwen Team , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.09388 , eprinttype =. 2505.09388 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[17]
What Disease does this Patient Have?
Di Jin and Eileen Pan and Nassim Oufattole and Wei. What Disease does this Patient Have?. CoRR , volume =. 2020 , url =. 2009.13081 , timestamp =
arXiv 2020
-
[18]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
Zhilin Yang and Peng Qi and Saizheng Zhang and Yoshua Bengio and William W. Cohen and Ruslan Salakhutdinov and Christopher D. Manning , editor =. HotpotQA:. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018 , pages =. 2018 , url =. doi:10.18653/V1/D18-1259 , timestamp =
-
[19]
Natural questions: A benchmark for question answering research
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav. Natura...
-
[20]
Weld and Luke Zettlemoyer , editor =
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[21]
Benchmarking Retrieval-Augmented Generation for Medicine , booktitle =
Guangzhi Xiong and Qiao Jin and Zhiyong Lu and Aidong Zhang , editor =. Benchmarking Retrieval-Augmented Generation for Medicine , booktitle =. 2024 , url =
2024
-
[22]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang and Mingxin Li and Dingkun Long and Xin Zhang and Huan Lin and Baosong Yang and Pengjun Xie and An Yang and Dayiheng Liu and Junyang Lin and Fei Huang and Jingren Zhou , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.05176 , eprinttype =. 2506.05176 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176 2025
-
[23]
Retrieval-Augmented Generation for Knowledge-Intensive
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , year =
2020
-
[24]
Retrieval Augmented Language Model Pre-Training , booktitle =
Kelvin Guu and Kenton Lee and Zora Tung and Panupong Pasupat and Ming. Retrieval Augmented Language Model Pre-Training , booktitle =. 2020 , url =
2020
-
[25]
Gautier Izacard and Edouard Grave , editor =. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering , booktitle =. 2021 , url =. doi:10.18653/V1/2021.EACL-MAIN.74 , timestamp =
-
[26]
Soyeong Jeong and Jinheon Baek and Sukmin Cho and Sung Ju Hwang and Jong Park , editor =. Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity , booktitle =. 2024 , url =. doi:10.18653/V1/2024.NAACL-LONG.389 , timestamp =
-
[27]
The Thirteenth International Conference on Learning Representations,
Zhenrui Yue and Honglei Zhuang and Aijun Bai and Kai Hui and Rolf Jagerman and Hansi Zeng and Zhen Qin and Dong Wang and Xuanhui Wang and Michael Bendersky , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[28]
Ziting Wang and Haitao Yuan and Wei Dong and Gao Cong and Feifei Li , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2411.00744 , eprinttype =. 2411.00744 , timestamp =
-
[29]
Budget-Constrained Online Retrieval-Augmented Generation: The Chunk-as-a-Service Model
Shawqi Al. Budget-Constrained Online Retrieval-Augmented Generation: The Chunk-as-a-Service Model , journal =. 2026 , url =. doi:10.48550/ARXIV.2604.26981 , eprinttype =. 2604.26981 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.26981 2026
-
[30]
and Zhang, Hao and Stoica, Ion , booktitle =
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph Gonzalez and Hao Zhang and Ion Stoica , editor =. Efficient Memory Management for Large Language Model Serving with PagedAttention , booktitle =. 2023 , url =. doi:10.1145/3600006.3613165 , timestamp =
-
[31]
Fabio Petroni and Aleksandra Piktus and Angela Fan and Patrick Lewis and Majid Yazdani and Nicola De Cao and James Thorne and Yacine Jernite and Vladimir Karpukhin and Jean Maillard and Vassilis Plachouras and Tim Rockt. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techno...
-
[32]
9th International Conference on Learning Representations,
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , title =. 9th International Conference on Learning Representations,. 2021 , url =
2021
-
[33]
Nature Human Behaviour , volume=
Protect our environment from information overload , author=. Nature Human Behaviour , volume=. 2024 , doi =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.