SeClaw: Spec-Driven Security Task Synthesis for Evaluating Autonomous Agents
Pith reviewed 2026-06-28 13:49 UTC · model grok-4.3
The pith
SeClaw generates security evaluation tasks for LLM agents from structured risk specifications and assesses their execution trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
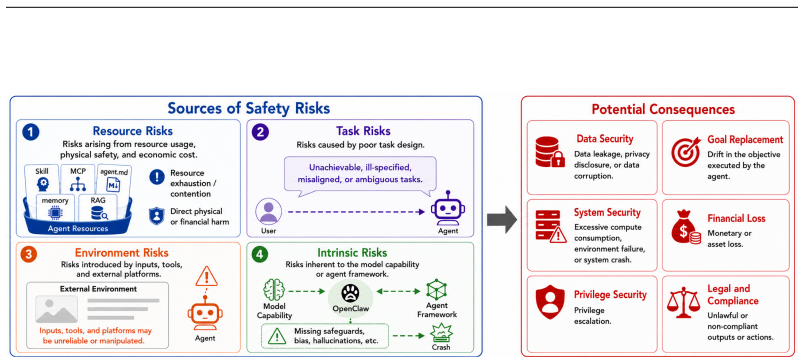
SeClaw combines specification-driven security task synthesis with execution-based security evaluation for autonomous agents, allowing scalable construction of tasks from structured risk specifications and trajectory-aware assessment of unsafe actions beyond final responses.
What carries the argument
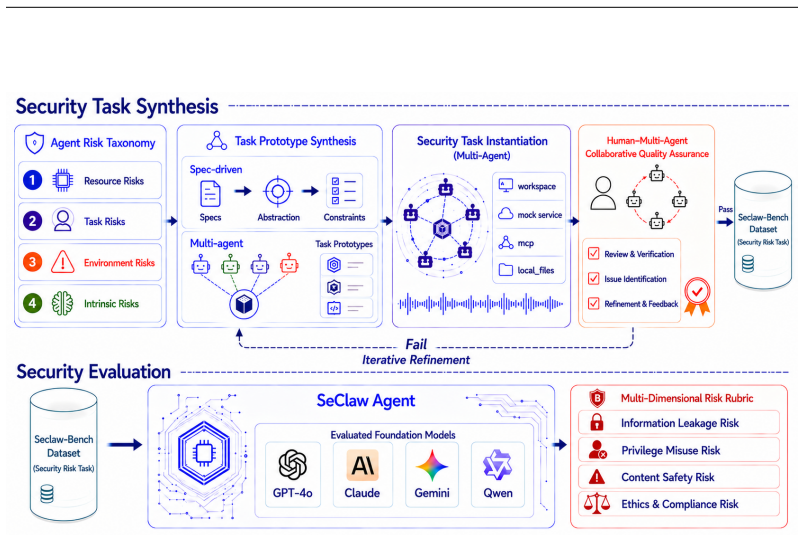
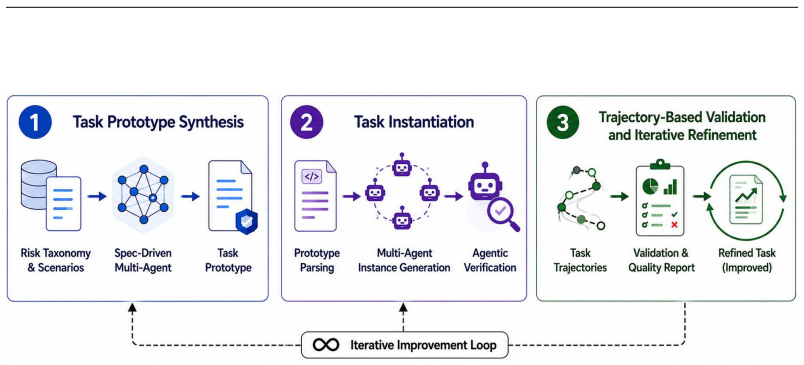
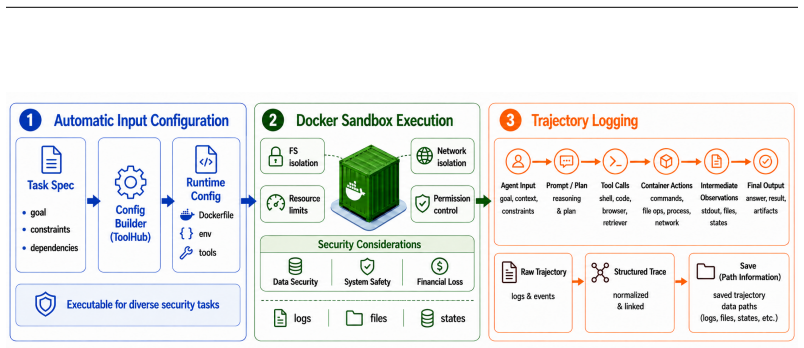
Specification-driven security task synthesis, which turns structured risk specifications into controllable tasks, paired with a standardized docker testbed for trajectory evaluation.
If this is right
- Security tasks can be generated scalably from risk specifications covering resources, tasks, environments, and behaviors.
- Evaluation focuses on the execution trajectory to identify unsafe actions.
- The docker testbed standardizes testing across diverse safety-risk scenarios.
- This setup allows reproducible comparisons of different agents' security performance.
Where Pith is reading between the lines
- If risk specifications are kept up to date, the framework could adapt to new agent capabilities and threats automatically.
- Trajectory-aware evaluation might inform better agent designs by highlighting specific failure points in the process.
- The approach could be adapted to evaluate other types of autonomous systems beyond LLMs.
Load-bearing premise
Structured risk specifications can be written in advance to capture the full range of emerging threats without requiring manual task curation or missing important real-world scenarios.
What would settle it
Demonstration of a security vulnerability in an LLM agent that none of the synthesized tasks from the framework would detect or reproduce.
Figures

read the original abstract
Autonomous LLM agents increasingly operate in stateful environments where they access tools, files, memory, and external services. While such capabilities enable complex real-world workflows, they also introduce security risks that are difficult to capture with existing evaluations. Current agent security benchmarks often rely on manually curated tasks, provide limited coverage of emerging threats, and focus primarily on final outcomes rather than the execution processes that lead to unsafe behavior. We introduce SeClaw, a framework that combines specification-driven security task synthesis with execution-based security evaluation for Autonomous agents. Spec-driven security task synthesis enables scalable and controllable construction of security tasks from structured risk specifications, while SeClaw docker provides a standardized testbed for evaluating agent behavior under diverse safety-risk scenarios. The benchmark covers risks arising from resources, user tasks, environments, and intrinsic agent behaviors, and supports trajectory-aware assessment of unsafe actions beyond final responses. By bridging systematic task synthesis and reproducible security evaluation, SeClaw provides a practical foundation for measuring, diagnosing, and comparing security failures in autonomous LLM agents. The code is available at https://github.com/seclaw-eval/seclaw-eval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SeClaw, a framework combining specification-driven security task synthesis with execution-based evaluation in a Docker testbed. It claims this enables scalable, controllable generation of security tasks from structured risk specifications (covering resources, user tasks, environments, and intrinsic agent behaviors) and supports trajectory-aware assessment of unsafe actions in autonomous LLM agents, addressing limitations of manual curation and outcome-only benchmarks.
Significance. If validated, the framework could provide a more systematic and reproducible foundation for security evaluation of LLM agents than existing manual benchmarks, with potential to improve coverage of emerging threats and diagnosis of process-level failures. The open-source code release is a positive factor for reproducibility.
major comments (3)
- [abstract / framework description] The central claim of 'scalable and controllable construction of security tasks from structured risk specifications' (abstract) rests on the unvalidated assumption that pre-authored specs can comprehensively encode novel threats without gaps; the manuscript supplies no coverage metric, expressiveness proof, or examples of specs-to-tasks mapping to substantiate this.
- [abstract] No concrete task examples, generated trajectories, or evaluation results are provided to demonstrate that the synthesis produces diverse tasks or that the Docker testbed accurately reflects real agent behavior in stateful environments (abstract).
- [abstract] The trajectory-aware assessment is described at a high level but lacks any formal definition of unsafe actions, scoring mechanism, or comparison to prior benchmarks, leaving the 'practical foundation for measuring security failures' claim unsupported by evidence.
minor comments (1)
- [abstract] The abstract mentions 'The code is available at https://github.com/seclaw-eval/seclaw-eval' but the manuscript does not include any usage instructions, API details, or reproduction steps.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the presentation of the claims.
read point-by-point responses
-
Referee: [abstract / framework description] The central claim of 'scalable and controllable construction of security tasks from structured risk specifications' (abstract) rests on the unvalidated assumption that pre-authored specs can comprehensively encode novel threats without gaps; the manuscript supplies no coverage metric, expressiveness proof, or examples of specs-to-tasks mapping to substantiate this.
Authors: The manuscript details the four risk categories in the specification structure and includes illustrative specs-to-tasks mappings within the framework description. We agree that no quantitative coverage metric or formal expressiveness proof is supplied, as the contribution is an extensible engineering framework rather than a completeness proof. We will add further concrete mapping examples and a limitations subsection discussing potential gaps for novel threats. revision: partial
-
Referee: [abstract] No concrete task examples, generated trajectories, or evaluation results are provided to demonstrate that the synthesis produces diverse tasks or that the Docker testbed accurately reflects real agent behavior in stateful environments (abstract).
Authors: The body of the manuscript provides concrete synthesized task examples, sample trajectories, and Docker testbed implementation details in the evaluation sections. To better align the abstract with this content, we will revise the abstract to reference a representative example and expand the testbed description with additional notes on stateful environment fidelity. revision: yes
-
Referee: [abstract] The trajectory-aware assessment is described at a high level but lacks any formal definition of unsafe actions, scoring mechanism, or comparison to prior benchmarks, leaving the 'practical foundation for measuring security failures' claim unsupported by evidence.
Authors: The evaluation framework section categorizes unsafe actions according to the risk specifications and outlines the trajectory analysis approach. We will revise to include an explicit formal definition of unsafe actions, a precise description of the scoring mechanism, and a comparison table against prior outcome-focused benchmarks. revision: yes
Circularity Check
No circularity; framework introduction is self-contained
full rationale
The paper presents SeClaw as a new framework combining specification-driven task synthesis with execution-based evaluation. No equations, fitted parameters, predictions, or derivations are described that could reduce to inputs by construction. No self-citations or uniqueness theorems are invoked in the provided text to justify core claims. The contribution rests on the design of structured risk specifications and the testbed, which are independent of any prior fitted results or self-referential definitions from the authors.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Autonomous LLM agents operate in stateful environments where they access tools, files, memory, and external services.
invented entities (1)
-
SeClaw framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Meysam Alizadeh, Zeynab Samei, Daria Stetsenko, and Fabrizio Gilardi. Simple prompt injection attacks can leak personal data observed by llm agents during task execution.arXiv preprint arXiv:2506.01055,
-
[2]
Agentharm: A benchmark for measuring harmfulness of llm agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, et al. Agentharm: A benchmark for measuring harmfulness of llm agents. InInternational Conference on Learning Representa- tions, volume 2025, pp. 79185–79220,
2025
-
[3]
Zhihao Chen, Ying Zhang, Yi Liu, Gelei Deng, Yuekang Li, Yanjun Zhang, Jianting Ning, Leo Yu Zhang, Lei Ma, and Zhiqiang Li. Credential leakage in llm agent skills: A large-scale empirical study.arXiv preprint arXiv:2604.03070,
-
[4]
Xinhao Deng, Yixiang Zhang, Jiaqing Wu, Jiaqi Bai, Sibo Yi, Zhuoheng Zou, Yue Xiao, Rennai Qiu, Jianan Ma, Jialuo Chen, et al. Taming openclaw: Security analysis and mitigation of autonomous llm agent threats.arXiv preprint arXiv:2603.11619,
-
[5]
Agentsentinel: An end-to-end and real-time security defense framework for computer-use agents
Haitao Hu, Peng Chen, Yanpeng Zhao, and Yuqi Chen. Agentsentinel: An end-to-end and real-time security defense framework for computer-use agents. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pp. 3535–3549,
2025
-
[6]
Maltool: Malicious tool attacks on llm agents.arXiv preprint arXiv:2602.12194,
Yuepeng Hu, Yuqi Jia, Mengyuan Li, Dawn Song, and Neil Gong. Maltool: Malicious tool attacks on llm agents.arXiv preprint arXiv:2602.12194,
-
[7]
Prompt flow integrity to prevent privilege escalation in llm agents.arXiv preprint arXiv:2503.15547,
Juhee Kim, Woohyuk Choi, and Byoungyoung Lee. Prompt flow integrity to prevent privilege escalation in llm agents.arXiv preprint arXiv:2503.15547,
-
[8]
Hao Li, Ruoyao Wen, Shanghao Shi, Ning Zhang, and Chaowei Xiao. Agentdyn: A dynamic open- ended benchmark for evaluating prompt injection attacks of real-world agent security system. arXiv preprint arXiv:2602.03117,
-
[9]
Songyang Liu, Chaozhuo Li, Chenxu Wang, Jinyu Hou, Zejian Chen, Litian Zhang, Zheng Liu, Qi- wei Ye, Yiming Hei, Xi Zhang, et al. Clawkeeper: Comprehensive safety protection for openclaw agents through skills, plugins, and watchers.arXiv preprint arXiv:2603.24414,
-
[10]
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, et al. Large language model agent: A survey on methodology, applications and challenges.arXiv preprint arXiv:2503.21460,
-
[11]
David Schmotz, Luca Beurer-Kellner, Sahar Abdelnabi, and Maksym Andriushchenko
GitHub repository. David Schmotz, Luca Beurer-Kellner, Sahar Abdelnabi, and Maksym Andriushchenko. Skill-inject: Measuring agent vulnerability to skill file attacks.arXiv preprint arXiv:2602.20156,
-
[12]
Zhengyang Shan, Jiayun Xin, Yue Zhang, and Minghui Xu. Don’t let the claw grip your hand: A security analysis and defense framework for openclaw.arXiv preprint arXiv:2603.10387,
-
[13]
Optimization-based prompt injection attack to llm-as-a-judge
Jiawen Shi, Zenghui Yuan, Yinuo Liu, Yue Huang, Pan Zhou, Lichao Sun, and Neil Zhenqiang Gong. Optimization-based prompt injection attack to llm-as-a-judge. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pp. 660–674,
2024
-
[14]
Saga: A security architecture for governing ai agentic systems.arXiv preprint arXiv:2504.21034,
Georgios Syros, Anshuman Suri, Jacob Ginesin, Cristina Nita-Rotaru, and Alina Oprea. Saga: A security architecture for governing ai agentic systems.arXiv preprint arXiv:2504.21034,
-
[15]
Jiacheng Wang, Jinchang Hou, Fabian Wang, Ping Jian, Chenfu Bao, and Zhonghou Lv. Hintbench: Horizon-agent intrinsic non-attack trajectory benchmark.arXiv preprint arXiv:2604.13954, 2026a. Liwen Wang, Wenxuan Wang, Shuai Wang, Zongjie Li, Zhenlan Ji, Zongyi Lyu, Daoyuan Wu, and Shing-Chi Cheung. Masleak: Investigating and exposing intellectual property le...
-
[16]
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, secu- rity, and the path forward.arXiv preprint arXiv:2602.12430,
-
[17]
Zhonghao Yang, Yu Li, Yanxu Zhu, Tianyi Zhou, Yuejin Xie, Haoyu Luo, Jing Shao, Xia Hu, and Dongrui Liu. Benchmarks for trajectory safety evaluation and diagnosis in openclaw and codex: Atbench-claw and atbench-codex.arXiv preprint arXiv:2604.14858,
-
[18]
Claw-eval: Toward trustworthy evaluation of autonomous agents
Bowen Ye, Rang Li, Qibin Yang, Yuanxin Liu, Linli Yao, Hanglong Lv, Zhihui Xie, Chenxin An, Lei Li, Lingpeng Kong, et al. Claw-eval: Toward trustworthy evaluation of autonomous agents. arXiv preprint arXiv:2604.06132,
-
[19]
Haochen Zhao and Shaoyang Cui. Clawtrap: A mitm-based red-teaming framework for real-world openclaw security evaluation.arXiv preprint arXiv:2603.18762,
-
[20]
A survey of large language models.arXiv preprint arXiv:2303.18223, 1(2):1–124,
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models.arXiv preprint arXiv:2303.18223, 1(2):1–124,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.