SegTune: Structured and Fine-Grained Control for Song Generation
Pith reviewed 2026-06-28 16:44 UTC · model grok-4.3
The pith
SegTune applies local musical prompts to specific song segments via temporal broadcasting in a diffusion transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
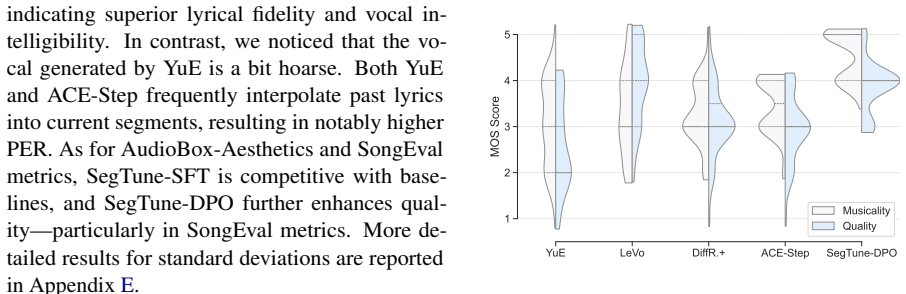
SegTune is a Diffusion Transformer framework that achieves structured controllability by letting segment prompts be broadcast to their corresponding time windows, with global prompts preserving coherence across the song. An LLM-based duration predictor produces sentence-level timestamps in LyRiCs format to support precise lyric-to-music alignment. A large-scale pipeline assembles songs with aligned lyrics and prompts, and new metrics assess segment alignment plus vocal consistency. The resulting model outperforms prior baselines on measures of musicality and controllability.
What carries the argument
Temporal broadcasting of segment prompts to aligned time windows inside the Diffusion Transformer, paired with an LLM duration predictor that supplies sentence timestamps.
If this is right
- Users can direct different musical features, such as instrumentation or mood, in different parts of one song.
- Lyric timing becomes more reliable because the duration predictor supplies explicit sentence-level boundaries.
- New metrics make it possible to quantify how well local control is actually achieved.
- Global style remains consistent even when local descriptions change across segments.
Where Pith is reading between the lines
- The same broadcasting idea could be tested on other sequential media, such as controlling emotion shifts within generated speech.
- Combining the segment mechanism with stronger LLMs might allow a single high-level story to be turned into a full song with automatically chosen section prompts.
- Real-time editing interfaces could let users revise only one segment's prompt and regenerate just that portion without restarting the whole track.
- The approach may reduce the need for post-processing steps that current systems use to fix timing or style drift.
Load-bearing premise
Broadcasting each segment prompt to its time window will keep the song coherent and the LLM will supply timestamps accurate enough for good lyric alignment.
What would settle it
Run a controlled test generating songs from deliberately conflicting adjacent segment prompts and check whether human coherence ratings and the new alignment metrics fall below those of global-prompt baselines.
Figures


read the original abstract
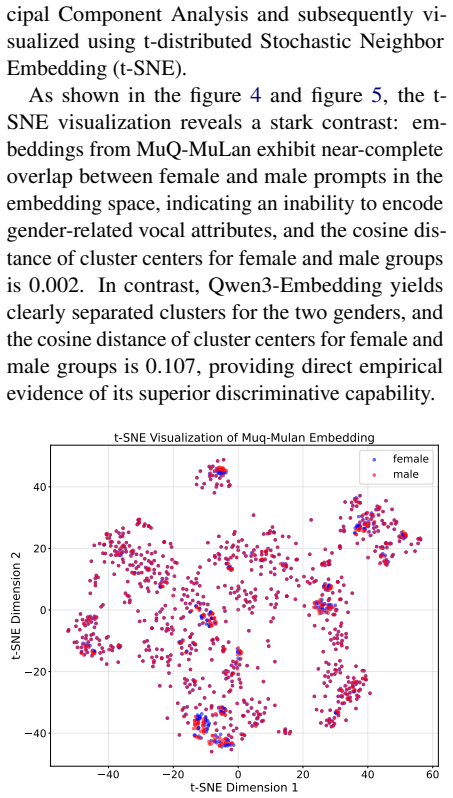
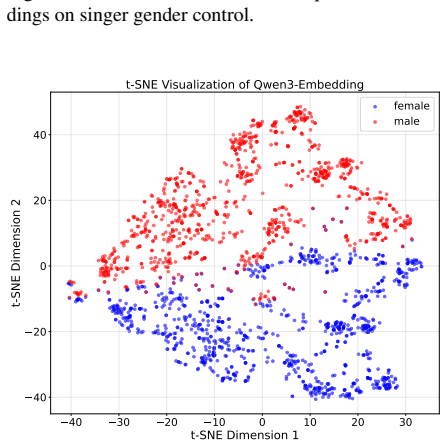
Recent advances in neural song generation have enabled high-quality synthesis from lyrics and global textual prompts. However, most systems fail to model temporally varying attributes of songs, severely limiting fine-grained control over musical structure and dynamics. To address this, we propose SegTune, a Diffusion Transformer-based framework enabling structured and fine-grained controllability by allowing users or large language models (LLMs) to specify local musical descriptions aligned to song segments. These segment prompts are temporally broadcast to corresponding time windows, while global prompts ensure stylistic coherence. To support precise lyric-to-music alignment, we introduce an LLM-based duration predictor that autoregressively generates sentence-level timestamps in LyRiCs format. We further construct a large-scale data pipeline for high-quality song collection with aligned lyrics and prompts, and propose new metrics to evaluate segment alignment and vocal consistency. Experiments demonstrate that SegTune outperforms existing baselines in both musicality and controllability. Visit our project page (https://github.com/KlingAIResearch/SegTune) for codes and more generated songs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SegTune, a Diffusion Transformer-based framework for song generation from lyrics and textual prompts. It enables fine-grained control by allowing segment prompts (specified by users or LLMs) to be temporally broadcast to corresponding time windows while global prompts maintain stylistic coherence. An LLM-based duration predictor autoregressively generates sentence-level timestamps in LyRiCs format to support lyric-to-music alignment. The work also describes a large-scale data pipeline for collecting aligned songs and proposes new metrics for segment alignment and vocal consistency. Experiments are claimed to show outperformance over baselines in musicality and controllability.
Significance. If the experimental claims hold with proper validation, the work would advance controllable neural audio generation by addressing the common limitation of modeling temporally varying song attributes. The segment-prompt broadcasting mechanism and LLM duration predictor offer a structured approach to fine-grained control that could be broadly applicable. The data pipeline and proposed metrics for alignment/consistency would also provide useful resources for the field.
major comments (2)
- [Abstract] Abstract: the central claim that 'Experiments demonstrate that SegTune outperforms existing baselines in both musicality and controllability' supplies no quantitative results, error bars, baseline details, or experimental methodology, rendering the claim unevaluable from the provided information.
- [Abstract] Abstract: no quantitative validation (e.g., timestamp MAE, alignment F1) or ablation (broadcast vs. non-broadcast, predictor vs. ground-truth durations) is reported for the LLM-based duration predictor or the temporal broadcast of segment prompts; these mechanisms are load-bearing for the controllability claims.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying ways to strengthen the abstract. We agree that the abstract should better substantiate its claims with quantitative information drawn from the experiments. Below we respond point by point and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Experiments demonstrate that SegTune outperforms existing baselines in both musicality and controllability' supplies no quantitative results, error bars, baseline details, or experimental methodology, rendering the claim unevaluable from the provided information.
Authors: We acknowledge that the abstract, standing alone, does not supply the requested quantitative details. The full manuscript reports these results in the Experiments section (including tables with baseline comparisons, musicality and controllability scores, and alignment metrics). In the revised version we will condense the most salient quantitative findings—e.g., relative improvements and key metric values—into the abstract so that the claim becomes directly evaluable. revision: yes
-
Referee: [Abstract] Abstract: no quantitative validation (e.g., timestamp MAE, alignment F1) or ablation (broadcast vs. non-broadcast, predictor vs. ground-truth durations) is reported for the LLM-based duration predictor or the temporal broadcast of segment prompts; these mechanisms are load-bearing for the controllability claims.
Authors: The Experiments section already presents quantitative results for the duration predictor (including timestamp-level metrics) and for the segment-prompt broadcasting mechanism. However, these details are not summarized in the abstract. We will revise the abstract to include concise references to the validation metrics and to the ablation-style comparisons that support the controllability claims. revision: yes
Circularity Check
No circularity: empirical proposal with no derivation chain
full rationale
The paper describes an architectural framework (Diffusion Transformer with segment prompts, LLM duration predictor, data pipeline) and reports experimental outperformance on musicality/controllability metrics. No equations, first-principles derivations, or predictions are present that could reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems. The central claims rest on empirical comparisons rather than self-referential fitting or renaming. This is the expected outcome for a standard ML systems paper; independent grounding via experiments is present even if validation details for subcomponents are limited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InICASSP 2024 - 2024 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 1206–1210
Musicldm: Enhancing novelty in text-to-music generation using beat-synchronous mixup strategies. InICASSP 2024 - 2024 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 1206–1210. Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. 2023. Simple and controlla...
2024
-
[2]
Jukebox: A Generative Model for Music
Jukebox: A generative model for music.arXiv preprint arXiv:2005.00341. Zach Evans, Julian D. Parker, CJ Carr, Zachary Zukowski, Josiah Taylor, and Jordi Pons. 2024a. Long-form music generation with latent diffusion. In Proceedings of the 25th International Society for Mu- sic Information Retrieval Conference, ISMIR 2024, San Francisco, California, USA and...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[3]
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Sys- tems. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High- resolution image synthesis with latent diffusion mod- els. InIEEE/CVF Conference on Computer Vision and Pattern...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Maskgct: Zero-shot text-to- speech with masked generative codec transformer,
Maskgct: Zero-shot text-to-speech with masked generative codec transformer.arXiv preprint arXiv:2409.00750. Shih-Lun Wu, Chris Donahue, Shinji Watanabe, and Nicholas J. Bryan. 2024. Music controlnet: Mul- tiple time-varying controls for music generation. IEEE/ACM Trans. Audio, Speech and Lang. Proc., 32:2692–2703. Jin Xu, Zhifang Guo, Hangrui Hu, and Yunf...
-
[5]
Analyze the lyrics and the song descrip- tion below
-
[6]
For each line of lyrics, estimate a reason- able singing duration. Base your estimation jointly on: • The intrinsic characteristics of the line itself (e.g., length, phrasing, complex- ity) • The overall song attributes; • The structural flow of the song, includ- ing instrumental breaks, natural pauses, and transitions
-
[7]
Below are the target global song description and lyrics
Return: Output a complete ‘.lrc‘ style list with timestamps. Below are the target global song description and lyrics. Please follow the instructions above and return the completed .lrc file directly. Song Description This pop rock ballad features a male vocal- ist delivering an emotional and uplifting melody. The mood is warm and introspec- tive, with a g...
-
[8]
Describe the details about genre, mood, feeling, ambience, and other notable features of the music
-
[9]
Describe the singer’s vocal characteris- tics, including gender, age range, vocal timbre, pitch range, and other notable features of the singer
-
[10]
Keep the descripiton within 1-4 sen- tences
-
[11]
It is not compulsory to provide all details, but do not hallucinate
Only provide details you are confident about. It is not compulsory to provide all details, but do not hallucinate. Prompt for Segment Caption Generation You are a helpful AI assistant. Describe the song segment as part of a complete piece of song in vivid detail according to what you hear. Generate the descripiton using the following rules:
-
[12]
Include the instrumentation, rhythm and melody style, mood, emotional’s impact, intensity and change
-
[13]
Mention any notable singing and play- ing techniques that occur and dynamic changes of the song
-
[14]
Keep the descripiton within 1-3 sen- tences
-
[15]
It is not compulsory to provide all details, but do not hallucinate
Only provide details you are confident about. It is not compulsory to provide all details, but do not hallucinate. Table 4: Objective metrics averaged across 150 generated tracks per system, with mean±standard deviation. Model CE↑CU↑PC↑PQ↑Coh↑Mem↑NVBP↑CSS↑OM↑ YuE 7.16±.60 7.66±.23 6.27±1.54 8.09±.14 3.51±.35 3.27±.38 3.22±.34 3.26±.38 3.22±.36 LeV o 7.43±...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.