Inference Cost Attacks for Retrieval-Augmented Large Language Models
Pith reviewed 2026-06-28 16:53 UTC · model grok-4.3
The pith
Poisoning external knowledge bases forces retrieval-augmented LLMs to consume up to 13 times more tokens per query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
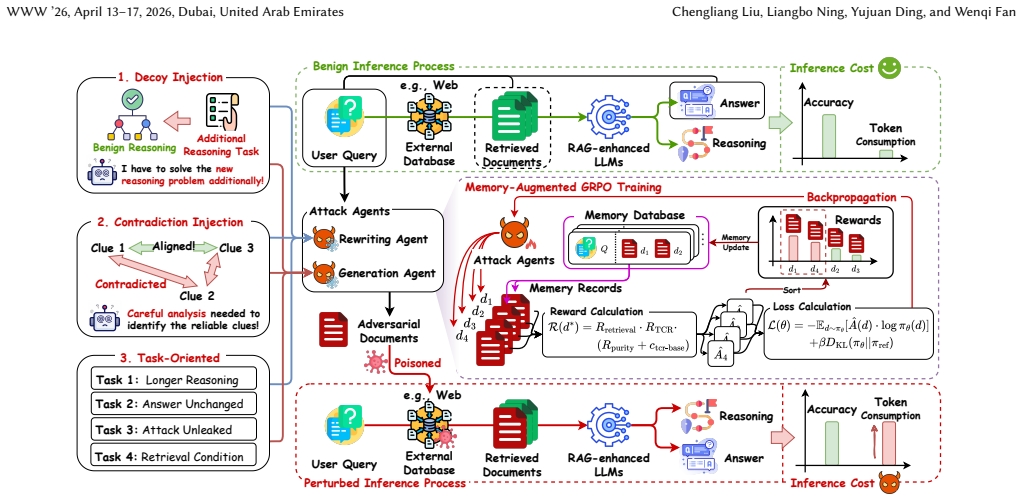
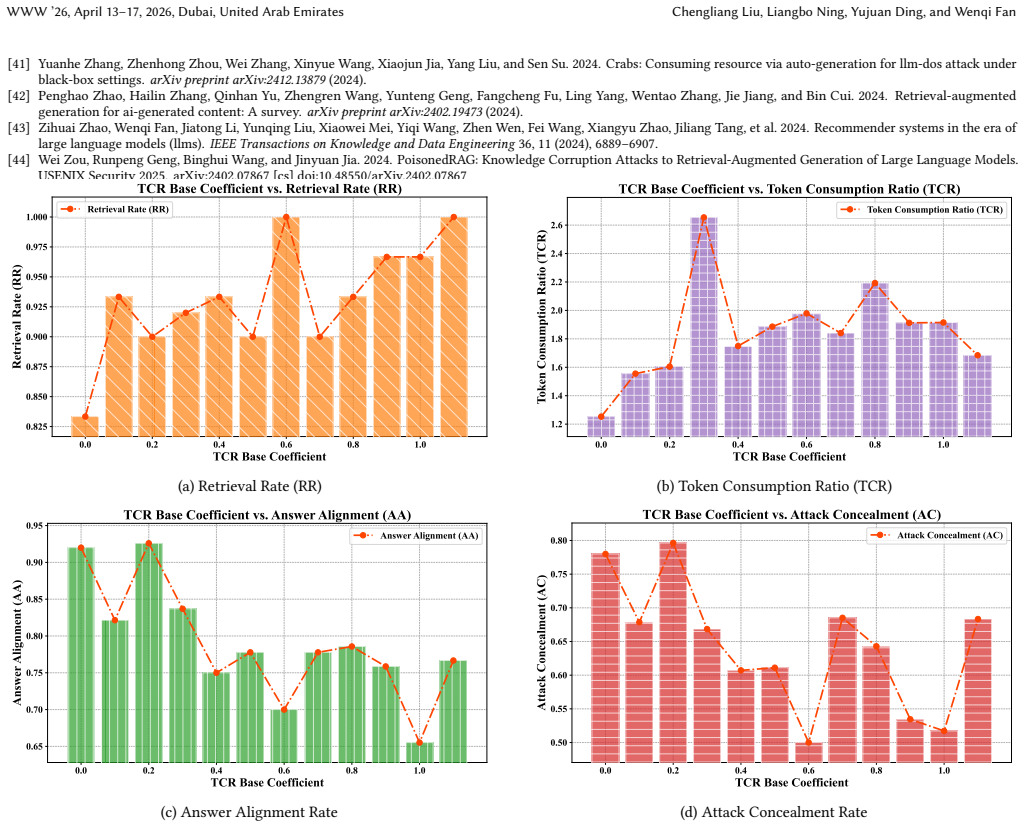
The Retrieval-Augmented Inference Cost Attack succeeds by injecting malicious documents into external knowledge corpora; these documents are retrieved at inference time and trigger abnormally high token counts during generation, reaching a maximum increase of 13.12 times with success rates exceeding 90 percent and without any loss in answer integrity. The attack is realized through the CREEP framework, which deploys LLM agents fine-tuned by Memory-Augmented Group Relative Policy Optimization to generate documents that are semantically aligned for retrieval yet computationally burdensome.
What carries the argument
CREEP (Computational Resource Exhaustion via External Poisoning), a framework that uses LLM agents and memory-augmented reinforcement learning to automatically generate malicious documents that remain retrievable while forcing higher token consumption.
If this is right
- RAG systems that rely on untrusted external data become exposed to cost-based resource exhaustion.
- Attack effectiveness holds across multiple real-world datasets while preserving output correctness.
- Existing RAG pipelines require additional checks on retrieved content beyond semantic relevance.
- The same poisoning approach could be adapted to target other retrieval-dependent generation pipelines.
Where Pith is reading between the lines
- Widespread adoption of this attack would raise the operating cost of public RAG services that ingest open web content.
- Document filtering or provenance verification mechanisms would directly test the practical reach of the attack.
- Similar cost-inflation tactics might apply to retrieval components in non-LLM systems such as search engines or recommendation engines.
Load-bearing premise
Malicious documents can be inserted into external knowledge bases and will be retrieved by the RAG pipeline without detection or filtering.
What would settle it
Run identical queries against a RAG system before and after the knowledge base is seeded with the generated malicious documents and measure whether token consumption increases by the reported factor.
Figures

read the original abstract
Retrieval-Augmented Generation (RAG)-enhanced LLM systems, while powerful, introduce substantial inference costs due to the inclusion of an extra multi-stage pipeline that dynamically retrieves and synthesizes information from external knowledge sources. This high operational cost exposes a critical vulnerability to Inference Cost Attacks (ICAs). However, existing ICAs often rely on the impractical assumption of direct prompt manipulation. We argue that a more feasible and potent threat to RAG-enhanced LLM systems arises from poisoning external knowledge bases (e.g., web knowledge from the Internet). In this work, we introduce the Retrieval-Augmented Inference Cost Attack (RA-ICA), a novel attacking paradigm that targets the computational cost of RAG-enhanced LLM systems by injecting malicious documents into external knowledge corpus. To operationalize this attack, we propose Computational Resource Exhaustion via External Poisoning (CREEP), a novel framework that leverages LLM agents to automatically craft malicious documents that are both semantically relevant for retrieval and potent for inducing an abnormal increase in token consumption during the inference phase. To enhance the attack's effectiveness, we introduce Memory-Augmented Group Relative Policy Optimization (MA-GRPO), a novel reinforcement learning algorithm that fine-tunes the agents by learning from a dynamic memory of historical best adversarial documents. Extensive experiments across three real-world datasets demonstrate that RA-ICA increases token consumption by up to 13.12 times with an over 90% success rate, without degrading the integrity of the generated answer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Retrieval-Augmented Inference Cost Attacks (RA-ICA) can be mounted against RAG-enhanced LLMs by injecting malicious documents into external knowledge bases. These documents are automatically generated by the CREEP framework, which uses LLM agents fine-tuned via the proposed Memory-Augmented Group Relative Policy Optimization (MA-GRPO) algorithm. Experiments on three real-world datasets reportedly show up to 13.12× increase in token consumption with >90% success rate while preserving answer integrity.
Significance. If the empirical results hold under realistic conditions, the work would be significant for highlighting a cost-based attack vector on RAG systems that does not require direct prompt access. The introduction of MA-GRPO as a memory-augmented RL method for crafting retrieval-potent adversarial documents is a technical contribution worth noting. The quantitative claims across multiple datasets provide concrete numbers that could motivate defenses, though the practical impact depends on the untested injection assumption.
major comments (2)
- [Threat Model and Experiments] The central claim of practical viability (13.12× token increase and >90% success) rests on the assumption that CREEP-generated documents can be injected into external/open-web KBs and retrieved without detection. The experiments use simulated/controlled datasets; no evaluation is provided of evasion against content filters, edit rate limits, or trusted-source prioritization. This is load-bearing for the threat model and should be addressed with either additional experiments or explicit scope limitations.
- [Abstract and § Experiments] Abstract and results reporting: quantitative claims (13.12× tokens, >90% success) are stated without accompanying details on baselines, statistical tests, variance across runs, or ablation of MA-GRPO components. The full experimental section must include these to allow assessment of whether the gains are attributable to the proposed method.
minor comments (1)
- [Introduction] Acronyms RA-ICA, CREEP, and MA-GRPO should be expanded on first use in the main text for readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Threat Model and Experiments] The central claim of practical viability (13.12× token increase and >90% success) rests on the assumption that CREEP-generated documents can be injected into external/open-web KBs and retrieved without detection. The experiments use simulated/controlled datasets; no evaluation is provided of evasion against content filters, edit rate limits, or trusted-source prioritization. This is load-bearing for the threat model and should be addressed with either additional experiments or explicit scope limitations.
Authors: We agree that the practical threat model depends on successful injection and retrieval. Our experiments deliberately focus on the core attack effectiveness (token inflation and success rate) under the assumption that the malicious documents are retrieved, which is consistent with the stated threat model of poisoning external KBs. We do not claim robustness against all possible defenses. In the revision we will add an explicit Limitations subsection that states the attack is conditional on retrieval success and does not evaluate evasion against content filters or trusted-source mechanisms. This directly implements the suggested scope limitation without requiring new experiments outside the paper's current scope. revision: yes
-
Referee: [Abstract and § Experiments] Abstract and results reporting: quantitative claims (13.12× tokens, >90% success) are stated without accompanying details on baselines, statistical tests, variance across runs, or ablation of MA-GRPO components. The full experimental section must include these to allow assessment of whether the gains are attributable to the proposed method.
Authors: We acknowledge that the current experimental reporting is insufficient for full reproducibility and attribution. The revised manuscript will expand the Experiments section to include: (1) explicit baseline comparisons (random document injection, non-RL poisoning, and simpler heuristic methods), (2) statistical significance testing (paired t-tests or Wilcoxon signed-rank tests with p-values), (3) variance reported as mean ± standard deviation across at least five independent runs, and (4) ablation studies isolating the contribution of the memory-augmented component and the group-relative optimization in MA-GRPO. These additions will be placed in the main experimental results and an appendix for completeness. revision: yes
Circularity Check
No circularity: purely empirical attack evaluation with no derivations or self-referential predictions.
full rationale
The paper introduces RA-ICA, CREEP, and MA-GRPO as new constructs and evaluates them via experiments on three datasets, reporting measured token increases and success rates. No equations, fitted parameters, or predictions are defined in terms of themselves; results are direct experimental observations rather than reductions of inputs. No load-bearing self-citations or uniqueness theorems appear in the provided text. The work is self-contained as an empirical demonstration.
Axiom & Free-Parameter Ledger
free parameters (1)
- MA-GRPO training hyperparameters
axioms (2)
- domain assumption External knowledge bases can be poisoned via document injection without immediate detection
- domain assumption LLM agents can reliably generate documents that are both retrievable and token-intensive
invented entities (3)
-
RA-ICA
no independent evidence
-
CREEP
no independent evidence
-
MA-GRPO
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chanwoo Choi, Jinsoo Kim, Sukmin Cho, Soyeong Jeong, and Buru Chang. 2025. The RAG Paradox: A Black-Box Attack Exploiting Unintentional Vulnerabilities in Retrieval-Augmented Generation Systems. arXiv:2502.20995 [cs] doi:10.48550/arXiv.2502.20995
-
[2]
DeepSeek. 2025. DeepSeek-R1 Update: Deeper Thinking, Stronger Reasoning. https://api-docs.deepseek.com/zh-cn/news/news250528. Accessed: 2025-10-06
2025
- [3]
-
[4]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’24). Association for Computing Machinery, New York, NY, USA, 6491–6501. doi...
-
[5]
Luciano Floridi. 2023. AI as agency without intelligence: On ChatGPT, large language models, and other generative models.Philosophy & technology36, 1 (2023), 15
2023
-
[6]
Google Cloud Platform. 2025. Generative AI samples for Google Cloud. https://github.com/GoogleCloudPlatform/generative-ai. Accessed: 2025-09-26
2025
-
[7]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring Mathematical Problem Solving with the MATH Dataset.arXiv preprint arXiv:2103.03874(2021). https://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models. ICLR1, 2 (2022), 3
2022
-
[9]
Mikhail Isaev, Nic McDonald, and Richard Vuduc. 2023. Scaling infrastructure to support multi-trillion parameter LLM training. InArchitecture and System Support for Transformer Models (ASSYST@ ISCA 2023)
2023
-
[10]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised Dense Information Retrieval with Contrastive Learning. arXiv:2112.09118 [cs.IR] https://arxiv.org/abs/2112.09118
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [11]
- [12]
-
[13]
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 7969–7992
2023
-
[14]
Leslie Pack Kaelbling, Michael L Littman, and Andrew W Moore. 1996. Reinforcement learning: A survey.Journal of artificial intelligence research4 (1996), 237–285
1996
-
[15]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. 2017. Adam: A Method for Stochastic Optimization. arXiv:1412.6980 [cs.LG] https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [16]
-
[17]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics7 (2019), 453–466
2019
-
[18]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[19]
Dazhen Li, Siru Xia, Ling Gui, Shiyang Cheng, Yuxuan Zhang, Bailin Wang, Haotian Qi, Jian Han, Yushi He, Qipeng Ma, Jing Zhang, Zhiyong Yang, Yuu Zhou, Jin Shang, Jian-Guang Mao, Lidong Wang, and Xia Zou. 2024. LiveCodeBench: A Challenge for Real-Time Human-Level Coding Competition.arXiv preprint arXiv:2403.07974(2024). https://arxiv.org/abs/2403.07974
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Jiatong Li, Yunqing Liu, Wenqi Fan, Xiao-Yong Wei, Hui Liu, Jiliang Tang, and Qing Li. 2024. Empowering molecule discovery for molecule-caption translation with large language models: A chatgpt perspective.IEEE transactions on knowledge and data engineering36, 11 (2024), 6071–6083
2024
-
[21]
Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, et al. 2024. Mobilellm: Optimizing sub-billion parameter language models for on-device use cases. InForty-first International Conference on Machine Learning
2024
-
[22]
Alejandro Lozano, Scott L Fleming, Chia-Chun Chiang, and Nigam Shah. 2023. Clinfo. ai: An open-source retrieval-augmented large language model system for answering medical questions using scientific literature. InPacific Symposium on Biocomputing 2024. World Scientific, 8–23
2023
- [23]
- [24]
-
[25]
Microsoft. 2025. What is Azure AI Search? https://learn.microsoft.com/en-us/azure/search/search-what-is-azure-search. Accessed: 2025-09-26
2025
-
[26]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. Ms marco: A human-generated machine reading comprehension dataset. (2016)
2016
-
[27]
Liangbo Ning, Ziran Liang, Zhuohang Jiang, Haohao Qu, Yujuan Ding, Wenqi Fan, Xiao-yong Wei, Shanru Lin, Hui Liu, Philip S Yu, et al. 2025. A survey of webagents: Towards next-generation ai agents for web automation with large foundation models. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 6140–6150
2025
-
[28]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
2024
-
[29]
David Patterson, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. 2021. Carbon emissions and large neural network training.arXiv preprint arXiv:2104.10350(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. 2024. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling
2024
-
[31]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Ilia Shumailov, Yiren Zhao, Daniel Bates, Nicolas Papernot, Robert Mullins, and Ross Anderson. 2021. Sponge examples: Energy-latency attacks on neural networks. In2021 IEEE European symposium on security and privacy (EuroS&P). IEEE, 212–231
2021
- [33]
-
[34]
Vectara. 2025. Grounded Generation overview. https://docs.vectara.com/docs/learn/grounded-generation/grounded-generation-overview. Accessed: 2025-09-26
2025
-
[35]
Ante Wang, Linfeng Song, Ge Xu, and Jinsong Su. 2023. Domain adaptation for conversational query production with the rag model feedback. InFindings of the Association for Computational Linguistics: EMNLP 2023. 9129–9141
2023
- [36]
- [37]
-
[38]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering.arXiv preprint arXiv:1809.09600(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Mohammad Shoeybi, and Bryan Catanzaro. 2024. Rankrag: Unifying context ranking with retrieval- augmented generation in llms.Advances in Neural Information Processing Systems37 (2024), 121156–121184
2024
-
[40]
Jingtao Zhan, Jiaxin Mao, Yiqun Liu, Jiafeng Guo, Min Zhang, and Shaoping Ma. 2021. Optimizing dense retrieval model training with hard negatives. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 1503–1512. WWW ’26, April 13–17, 2026, Dubai, United Arab Emirates Chengliang Liu, Liangbo Ning...
2021
- [41]
-
[42]
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. 2024. Retrieval-augmented generation for ai-generated content: A survey.arXiv preprint arXiv:2402.19473(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, et al. 2024. Recommender systems in the era of large language models (llms).IEEE Transactions on Knowledge and Data Engineering36, 11 (2024), 6889–6907
2024
-
[44]
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. 2024. PoisonedRAG: Knowledge Corruption Attacks to Retrieval-Augmented Generation of Large Language Models. USENIX Security 2025. arXiv:2402.07867 [cs] doi:10.48550/arXiv.2402.07867 /uni00000013/uni00000011/uni00000013/uni00000013/uni00000011/uni00000015/uni00000013/uni00000011/uni00000017/uni00000013/...
-
[45]
Ground Truth Answer
Treat the "Ground Truth Answer" as absolute truth. [...]
-
[46]
Ground Truth Answer
DO NOT evaluate the "Ground Truth Answer". [...]
-
[47]
[...] [
Your judgment depends ONLY on semantic equivalence. [...] [... Further instructions, rules, and examples omitted for brevity. ...] Now, please judge the answer based on the question and the ground truth answer: Question: {question} Ground Truth Answer: {ground_truth} Generated Answer: {generated_answer} Response: B.2 Document Manipulation Prompts Direct-R...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.