Attention Calibration for Position-Fair Dense Information Retrieval
Pith reviewed 2026-06-28 12:27 UTC · model grok-4.3
The pith
Inference-time attention calibration with one default configuration reduces positional bias in dense retrieval across models and languages while preserving overall effectiveness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A single attention calibration setting (B=128, lambda=0.5, 50 percent layer depth) improves the harmonic mean of nDCG@10 across positional groups on FineWeb-PosQ for all three tested models and both pooling architectures; the identical setting reduces the Position Sensitivity Index on the PosIR benchmark in all sixteen length-quartile by model by retrieval-setting combinations while preserving or improving aggregate nDCG@10.
What carries the argument
Inference-time attention calibration extended with a strength coefficient lambda that interpolates between the original and fully calibrated attention distributions.
If this is right
- The configuration works without per-model retuning and applies to both <s>-pooled and last-token-pooled architectures.
- It transfers unchanged to a multilingual, multi-domain benchmark covering ten languages and thirty-one domains.
- It lowers the Position Sensitivity Index in every length-quartile by model by retrieval-setting slice examined.
- Aggregate nDCG@10 is preserved or improved alongside the fairness gain.
- Partial calibration (lambda=0.5) outperforms full calibration on the fairness-effectiveness trade-off.
Where Pith is reading between the lines
- The method could be applied to other inference-time biases such as length or domain preference without retraining.
- Combining the calibration with existing query rewriting or reranking stages might yield additive fairness gains.
- The approach may prove useful for very long passages where position effects are stronger.
- Releasing the extended codebase allows direct replication on new embedding models and languages.
Load-bearing premise
The positional bias observed on the constructed SQuAD-PosQ, FineWeb-PosQ, and PosIR datasets reflects the bias present in real-world dense retrieval applications.
What would settle it
Running the same default configuration on an independently constructed retrieval test set whose documents follow a different length and domain distribution and measuring whether position sensitivity drops while nDCG@10 stays flat or rises.
Figures

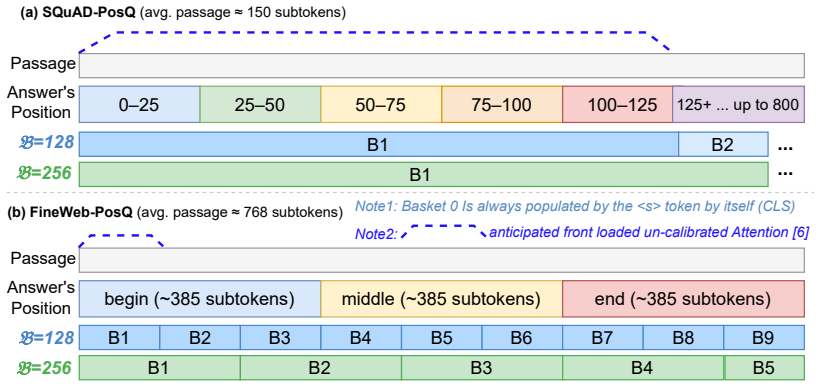
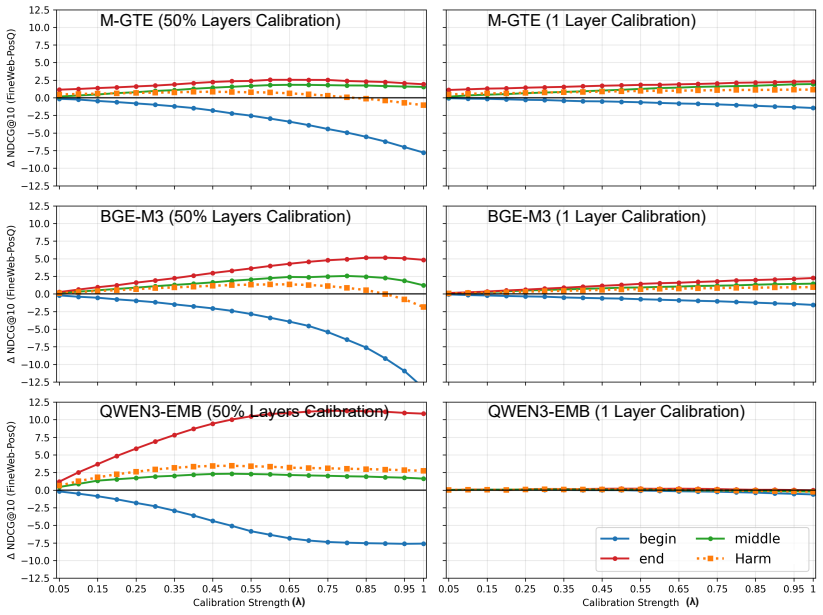
read the original abstract
Dense retrieval models exhibit positional bias: retrieval effectiveness degrades when relevant information appears later in a passage (Zeng et al., 2025). We ask whether this bias can be reduced at inference time, without retraining and without sacrificing overall retrieval effectiveness. To this end, we adapt inference-time attention calibration (Schuhmacher et al., 2026) to downstream retrieval and extend it with a strength coefficient lambda that interpolates between the original and fully calibrated attention distributions. Across three embedding models on SQuAD-PosQ and FineWeb-PosQ, we examine how basket size, calibrated layer set, and strength affect the trade-off between positional fairness and retrieval effectiveness, finding that partial calibration frequently outperforms full calibration. A single configuration (B=128, lambda=0.5, 50% layer depth) improves the harmonic mean of nDCG@10 across positional groups on FineWeb-PosQ for all three models without per-model tuning, and applies to both <s>-pooled and last-token-pooled architectures. This default configuration transfers without modification to PosIR, which spans 10 languages and 31 domains, reducing the Position Sensitivity Index in all 16 length-quartile x model x retrieval-setting combinations, while preserving or improving aggregate nDCG@10. We release our extended codebase at https://github.com/impresso/fair-sentence-transformers
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper adapts inference-time attention calibration (with an added strength coefficient lambda) to dense retrieval models to mitigate positional bias at inference time without retraining. It reports that a single default configuration (B=128, lambda=0.5, 50% layer depth) improves the harmonic mean of nDCG@10 across positional groups on FineWeb-PosQ for three models (both <s>- and last-token-pooled), and transfers without modification to the multilingual PosIR benchmark (10 languages, 31 domains), reducing the Position Sensitivity Index in all 16 length-quartile × model × retrieval-setting combinations while preserving or improving aggregate nDCG@10. Code is released.
Significance. If the empirical claims hold, the work supplies a practical, training-free intervention for position fairness in dense IR that uses a single transferable configuration across models, pooling methods, languages, and domains. The open release of the extended codebase is a clear strength for reproducibility.
major comments (1)
- [Abstract] Abstract and evaluation description: The central claim that the default configuration reduces positional bias 'without introducing new unintended biases' and transfers to PosIR rests on the assumption that bias measured after controlled relevant-content placement in SQuAD-PosQ, FineWeb-PosQ, and PosIR matches bias arising in organic queries and passages. No cross-validation against real retrieval traces or production logs is reported; this is load-bearing for the applicability claim.
Simulated Author's Rebuttal
We thank the referee for highlighting this important methodological point regarding the generalizability of our controlled benchmarks. We address the concern directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: The central claim that the default configuration reduces positional bias 'without introducing new unintended biases' and transfers to PosIR rests on the assumption that bias measured after controlled relevant-content placement in SQuAD-PosQ, FineWeb-PosQ, and PosIR matches bias arising in organic queries and passages. No cross-validation against real retrieval traces or production logs is reported; this is load-bearing for the applicability claim.
Authors: We agree that our evaluation is based on synthetically constructed positional variants (SQuAD-PosQ, FineWeb-PosQ) and the PosIR benchmark, which also uses controlled relevant-content placement across languages and domains. These datasets allow isolation of positional effects and measurement of the Position Sensitivity Index, but they do not constitute organic query-passage distributions from production systems. No cross-validation against real retrieval logs is present in the manuscript. We will revise the abstract and evaluation description to remove or qualify any implication of 'without introducing new unintended biases' and add an explicit limitations paragraph acknowledging that applicability to organic settings remains an assumption pending future validation on production traces. This constitutes a partial revision. revision: partial
Circularity Check
No circularity; empirical application of prior method evaluated on held-out benchmarks
full rationale
The paper adapts an existing inference-time attention calibration procedure (cited to Schuhmacher et al. 2026) and reports empirical results on constructed datasets using standard held-out metrics (nDCG@10, harmonic mean across positional groups, Position Sensitivity Index). No derivation chain reduces a claimed prediction or first-principles result to fitted parameters or self-defined quantities by construction. The central claims concern transfer of a fixed configuration (B=128, lambda=0.5, 50% depth) across models and datasets; these are measured outcomes, not quantities forced by the paper's own inputs or self-citations. Self-citation to the method source is present but not load-bearing for any circular reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- lambda =
0.5
- B =
128
axioms (1)
- domain assumption Attention calibration developed for a different task transfers to dense retrieval without loss of effectiveness or introduction of new biases.
Reference graph
Works this paper leans on
-
[1]
An Empirical Study of Position Bias in Modern Information Retrieval
Zeng, Ziyang and Zhang, Dun and Li, Jiacheng and Zoupanxiang and Zhou, Yudong and Yang, Yuqing. An Empirical Study of Position Bias in Modern Information Retrieval. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.271
-
[2]
2026 , eprint=
Information Representation Fairness in Long-Document Embeddings: The Peculiar Interaction of Positional and Language Bias , author=. 2026 , eprint=
2026
-
[3]
2025 , publisher =
Minhas, Bhavnick AND Nigam, Shreyash , title =. 2025 , publisher =
2025
-
[4]
The Thirteenth International Conference on Learning Representations , year=
NNsight and NDIF: Democratizing Access to Open-Weight Foundation Model Internals , author=. The Thirteenth International Conference on Learning Representations , year=
-
[5]
Chen, Jianlyu and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng. M 3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.137
-
[6]
Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Wen and Dai, Ziqi and Tang, Jialong and Lin, Huan and Yang, Baosong and Xie, Pengjun and Huang, Fei and Zhang, Meishan and Li, Wenjie and Zhang, Min. mGTE : Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval. Proceedings of the 2024 Conference on Empiri...
-
[7]
2025 , eprint=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
Quantifying Positional Biases in Text Embedding Models , author=. 2025 , eprint=
2025
-
[9]
L ong E mbed: Extending Embedding Models for Long Context Retrieval
Zhu, Dawei and Wang, Liang and Yang, Nan and Song, Yifan and Wu, Wenhao and Wei, Furu and Li, Sujian. L ong E mbed: Extending Embedding Models for Long Context Retrieval. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.47
-
[10]
Fayyaz, Mohsen and Modarressi, Ali and Schuetze, Hinrich and Peng, Nanyun , editor =. Collapse of Dense Retrievers:. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month =. 2025 , address =. doi:10.18653/v1/2025.acl-long.447 , pages =
-
[11]
Found in the middle: Calibrating Positional Attention Bias Improves Long Context Utilization
Hsieh, Cheng-Yu and Chuang, Yung-Sung and Li, Chun-Liang and Wang, Zifeng and Le, Long and Kumar, Abhishek and Glass, James and Ratner, Alexander and Lee, Chen-Yu and Krishna, Ranjay and Pfister, Tomas. Found in the middle: Calibrating Positional Attention Bias Improves Long Context Utilization. Findings of the Association for Computational Linguistics: A...
-
[12]
Cumulated gain-based evaluation of IR techniques , year =
J\". Cumulated gain-based evaluation of IR techniques , year =. doi:10.1145/582415.582418 , journal =
-
[13]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , url =
Dao, Tri and Fu, Dan and Ermon, Stefano and Rudra, Atri and R\'. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , url =. Advances in Neural Information Processing Systems , editor =
-
[14]
2026 , eprint=
PosIR: Position-Aware Heterogeneous Information Retrieval Benchmark , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.