CRAM-ER: Error-Resilient Spintronic Computational Random Access Memory for Scalable In-Memory Computation
Pith reviewed 2026-06-28 11:49 UTC · model grok-4.3
The pith
A hybrid spintronic-CRAM plus CMOS adder-tree design with error-aware fine-tuning makes probabilistic MRAM errors manageable for reliable in-memory matrix-vector multiplications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The CRAM-ER architecture enables scalable in-memory matrix-vector multiplications by using a hybrid spintronic-CRAM plus CMOS adder-tree to mitigate device-level probabilistic errors, together with error-aware model fine-tuning and fine-grained error correction, resulting in near-lossless accuracy on DNN benchmarks while reducing latency by up to two orders of magnitude and improving energy efficiency over CPU/GPU plus high-bandwidth DRAM.
What carries the argument
The hybrid spintronic-CRAM + CMOS adder-tree architecture combined with error-aware model fine-tuning that absorbs and corrects probabilistic MRAM switching errors during in-situ logic.
If this is right
- Matrix-vector multiplications become feasible inside CRAM with high area and energy efficiency despite device errors.
- DNN models reach near-lossless accuracy through the combination of hardware mitigation and model fine-tuning.
- CRAM-based accelerators achieve up to two orders of magnitude lower latency than conventional memory-bound designs.
- Energy efficiency and energy-delay product exceed those of CPU or GPU paired with high-bandwidth DRAM.
Where Pith is reading between the lines
- The error-mitigation pattern could be reused for other memory technologies that exhibit probabilistic write behavior.
- Larger models might need adjustments to the fine-grained correction step to prevent the adder tree from becoming a new bottleneck.
- If the hybrid overhead stays modest, the approach could be tested on mixed-precision workloads beyond the evaluated DNNs.
Load-bearing premise
That the hybrid hardware and software co-design can keep error mitigation costs low enough in area and energy that they do not offset the gains from in-memory operation at scale.
What would settle it
Implementing the hybrid CRAM-ER on DNN benchmarks and measuring either accuracy loss well above a few percent or latency and energy numbers that fail to beat CPU/GPU baselines by the claimed margins.
Figures

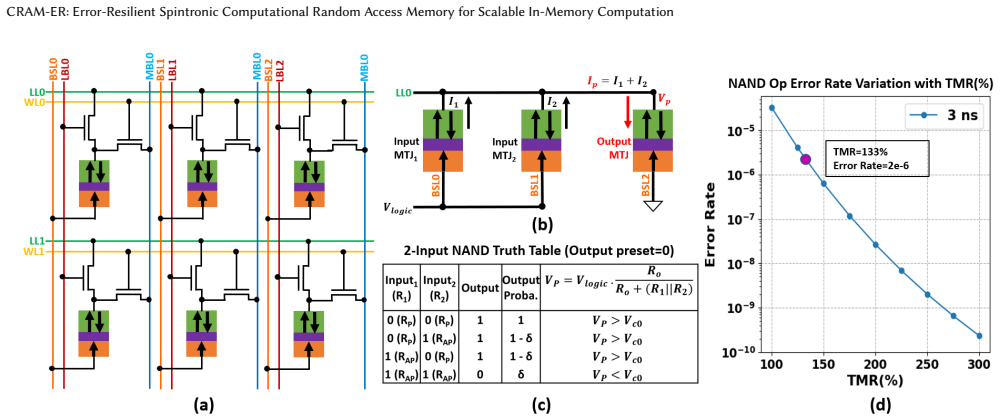
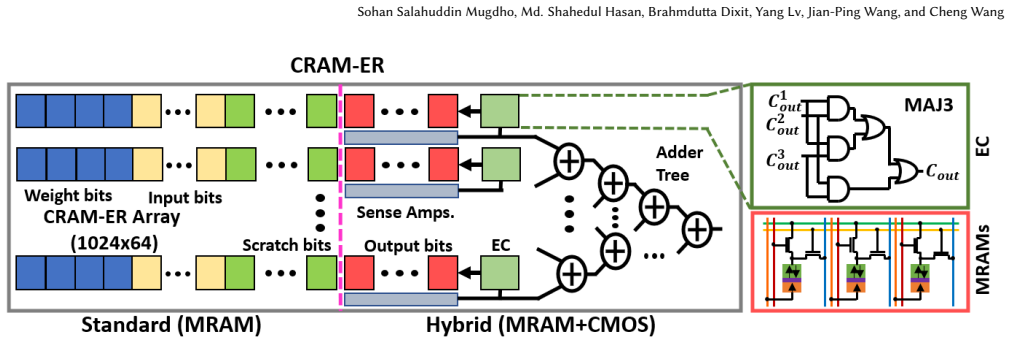
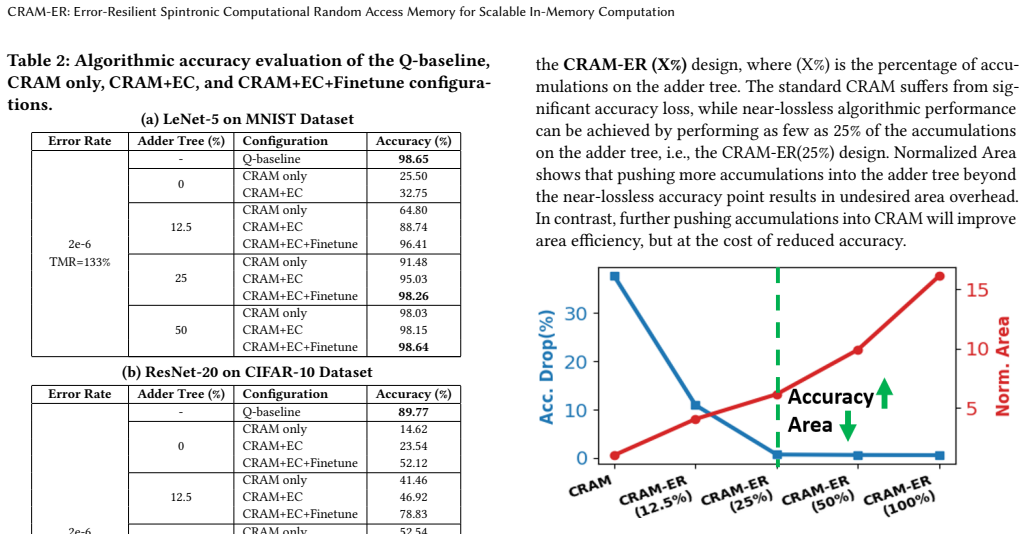
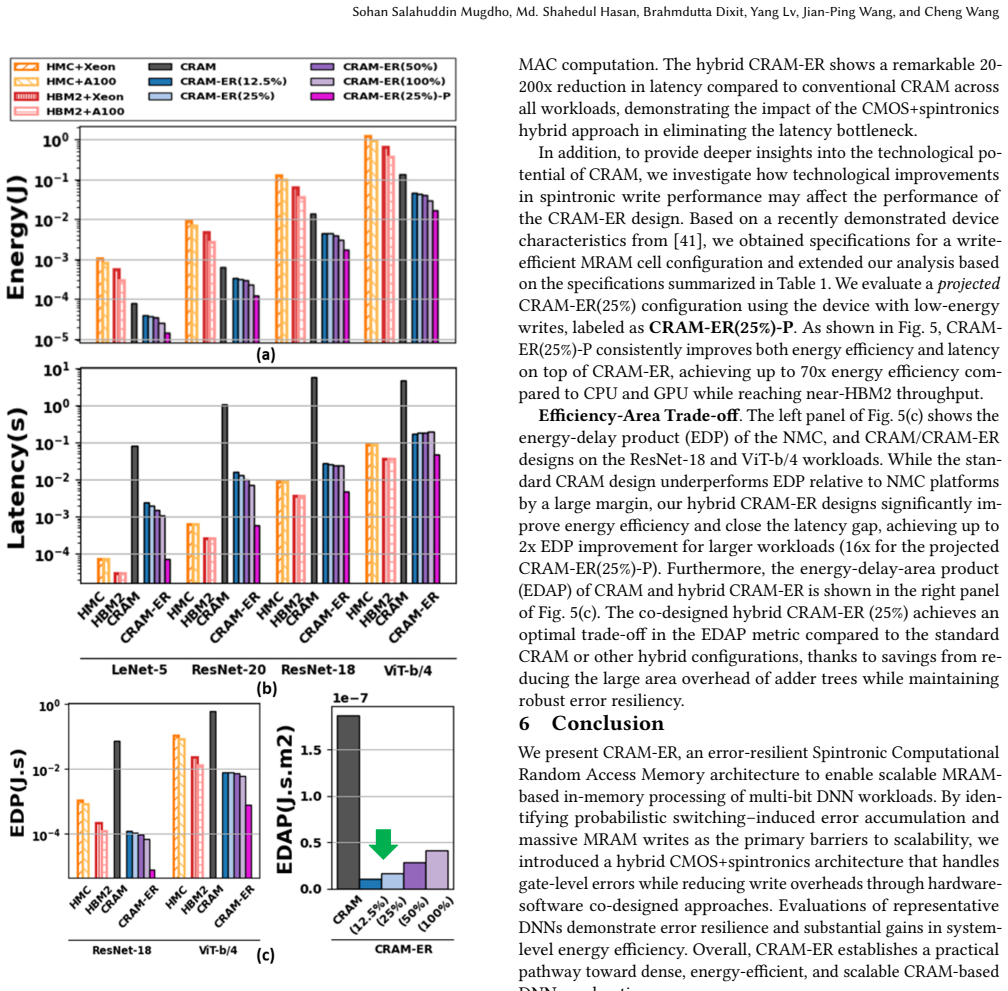
read the original abstract
Deep neural networks (DNNs) have achieved state-of-the-art performance across diverse domains. However, typical Von Neumann compute paradigms face severe memory bottlenecks. Emerging near-memory and compute-in-memory approaches alleviate this but incur significant peripheral overhead. Computational Random Access Memory (CRAM) based on MRAM enables in-situ logic without peripheral overhead, offering a dense, energy-efficient solution. However, probabilistic MRAM switching induces gate-level errors that limit the scalability and reliability of CRAM for accelerating DNN. Moreover, the large number of sequential MRAM writes severely constrains CRAM throughput. To address these challenges, we propose an error-resilient CRAM (CRAM-ER) architecture for scalable in-memory matrix-vector multiplications (MVMs). Our error-aware hardware-software co-design framework leverages a hybrid spintronic-CRAM + CMOS adder-tree architecture to mitigate the impact of device-level errors, demonstrating MVM functionality with high area and energy efficiency. We further develop an error-aware model fine-tuning and fine-grained error correction for enhanced error resilience. Evaluations of the CMOS+spintronic hybrid architecture on DNN benchmarks show near-lossless accuracy while reducing CRAM latency by up to 2 orders of magnitude, outperforming CPU/GPU+high-bandwidth DRAM in both energy efficiency and energy-delay product.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CRAM-ER, an error-resilient spintronic CRAM architecture for in-memory matrix-vector multiplications in DNNs. It introduces a hybrid spintronic-CRAM + CMOS adder-tree design, combined with error-aware model fine-tuning and fine-grained error correction, to mitigate probabilistic MRAM switching errors. The central claim is that this co-design achieves near-lossless accuracy on DNN benchmarks while reducing CRAM latency by up to two orders of magnitude and improving energy efficiency and energy-delay product over CPU/GPU + high-bandwidth DRAM baselines.
Significance. If the quantitative claims on error mitigation and performance hold with supporting models and data, the work would be significant for advancing reliable compute-in-memory using MRAM-based CRAM, addressing both error resilience and throughput limitations in a hybrid hardware-software framework.
major comments (3)
- [Abstract / Evaluations] Abstract and evaluations description: the headline claims of near-lossless accuracy and up to 100x latency reduction rest on the hybrid adder-tree plus fine-tuning successfully suppressing device errors, yet no error-rate model, no quantitative overhead breakdown versus baseline CRAM, and no scaling data for large MVMs are supplied, leaving the central performance and accuracy assertions without visible derivation or results.
- [Hybrid spintronic-CRAM + CMOS adder-tree] Hybrid architecture section: the assumption that the CMOS adder-tree mitigates probabilistic MRAM errors at acceptable area/energy cost is load-bearing for both the accuracy and EDP claims, but no concrete error-probability model, correction-overhead calculation, or array-size scaling analysis is provided to test whether mitigation cost grows with MVM dimension.
- [Error-aware model fine-tuning and fine-grained error correction] Error-aware fine-tuning and correction: the manuscript states these techniques enhance resilience, but supplies no benchmark details, no comparison of accuracy with/without correction, and no analysis of whether fine-grained correction introduces new bottlenecks that would undermine the claimed latency gains.
minor comments (1)
- [Abstract] The abstract refers to 'evaluations' and 'DNN benchmarks' without naming the networks, datasets, or error rates used; adding these specifics would improve clarity even if full results are in later sections.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript on the CRAM-ER architecture. We address each major comment below and indicate the revisions we will make to address the identified gaps in supporting details and analysis.
read point-by-point responses
-
Referee: [Abstract / Evaluations] Abstract and evaluations description: the headline claims of near-lossless accuracy and up to 100x latency reduction rest on the hybrid adder-tree plus fine-tuning successfully suppressing device errors, yet no error-rate model, no quantitative overhead breakdown versus baseline CRAM, and no scaling data for large MVMs are supplied, leaving the central performance and accuracy assertions without visible derivation or results.
Authors: We agree that the central claims would be more robustly supported by explicit presentation of the underlying models and data. The submitted manuscript summarizes results without fully detailing the error-rate model, overhead breakdowns, or scaling analysis in the evaluations section. We will revise by adding a dedicated subsection that derives the performance and accuracy claims from the probabilistic MRAM error model, provides quantitative overhead comparisons versus baseline CRAM, and includes scaling results for large MVM dimensions. revision: yes
-
Referee: [Hybrid spintronic-CRAM + CMOS adder-tree] Hybrid architecture section: the assumption that the CMOS adder-tree mitigates probabilistic MRAM errors at acceptable area/energy cost is load-bearing for both the accuracy and EDP claims, but no concrete error-probability model, correction-overhead calculation, or array-size scaling analysis is provided to test whether mitigation cost grows with MVM dimension.
Authors: The referee is correct that the hybrid architecture's viability depends on demonstrating acceptable mitigation costs. The current manuscript does not supply the requested concrete models or calculations. In revision we will expand the hybrid architecture section to include an explicit error-probability model based on MRAM device characteristics, overhead calculations for the CMOS adder-tree, and scaling analysis across MVM dimensions to show how costs behave as array size increases. revision: yes
-
Referee: [Error-aware model fine-tuning and fine-grained error correction] Error-aware fine-tuning and correction: the manuscript states these techniques enhance resilience, but supplies no benchmark details, no comparison of accuracy with/without correction, and no analysis of whether fine-grained correction introduces new bottlenecks that would undermine the claimed latency gains.
Authors: We acknowledge that the manuscript would be strengthened by providing the missing evaluation details for the software techniques. The current text asserts benefits without the requested benchmark specifics, with/without comparisons, or bottleneck analysis. We will revise the relevant section to include benchmark details, accuracy comparisons with and without the fine-tuning and correction methods, and an assessment of any latency impact from the fine-grained correction to confirm it does not offset the reported gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes a hybrid spintronic-CRAM + CMOS architecture with error-aware fine-tuning for DNN acceleration. All performance claims (near-lossless accuracy, 100x latency reduction, EDP gains) are presented as outcomes of external device models, benchmark evaluations, and co-design simulations rather than any internal equations, fitted parameters, or self-citations that reduce the results to the inputs by construction. No derivation steps match the enumerated circularity patterns; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Probabilistic MRAM switching induces gate-level errors that limit CRAM scalability
Reference graph
Works this paper leans on
-
[1]
Shaahin Angizi, Zhezhi He, et al. 2019. Accelerating Deep Neural Networks in Processing-in-Memory Platforms: Analog or Digital Approach?. In2019 IEEE Computer Society Annual Symposium on VLSI (ISVLSI). 197–202. doi:10.1109/ ISVLSI.2019.00044
arXiv 2019
-
[2]
Shaahin Angizi, Jiao Sun, Wei Zhang, and Deliang Fan. 2019. GraphS: A Graph Processing Accelerator Leveraging SOT-MRAM. In2019 Design, Automation & Test in Europe Conference & Exhibition (DATE). 378–383. doi:10.23919/DATE.2019. 8715270
-
[3]
Yu-Der Chih, Po-Hao Lee, et al. 2021. 16.4 An 89TOPS/W and 16.3TOPS/mm2 All-Digital SRAM-Based Full-Precision Compute-In Memory Macro in 22nm for Machine-Learning Edge Applications. In2021 IEEE International Solid-State CRAM-ER: Error-Resilient Spintronic Computational Random Access Memory for Scalable In-Memory Computation Circuits Conference (ISSCC), Vo...
-
[4]
Harms, et al
Zamshed Chowdhury, Jonathan D. Harms, et al . 2018. Efficient In-Memory Processing Using Spintronics.IEEE Computer Architecture Letters17, 1 (2018)
2018
-
[5]
Chowdhury, Hüsrev Cilasun, et al
Zamshed I. Chowdhury, Hüsrev Cilasun, et al . 2024. On Gate Flip Errors in Computing-In-Memory. In2024 Design, Automation & Test in Europe Conference & Exhibition (DATE). 1–6. doi:10.23919/DATE58400.2024.10546875
-
[6]
Ki Chul Chun, Hui Zhao, et al . 2013. A Scaling Roadmap and Performance Evaluation of In-Plane and Perpendicular MTJ Based STT-MRAMs for High- Density Cache Memory.IEEE Journal of Solid-State Circuits48, 2 (2013), 598–610
2013
-
[7]
Hüsrev Cılasun, Salonik Resch, et al. 2024. On Error Correction for Nonvolatile Processing-In-Memory. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). 678–692. doi:10.1109/ISCA59077.2024.00055
-
[8]
Sapat- nekar, and Ulya Karpuzcu
Hüsrev Cılasun, Salonik Resch, Zamshed Iqbal Chowdhury, Erin Olson, Masoud Zabihi, Zhengyang Zhao, Thomas Peterson, Jian-Ping Wang, Sachin S. Sapat- nekar, and Ulya Karpuzcu. 2020. CRAFFT: High Resolution FFT Accelerator In Spintronic Computational RAM. In2020 57th ACM/IEEE Design Automation Conference (DAC). 1–6. doi:10.1109/DAC18072.2020.9218673
-
[9]
Xiangyu Dong, Cong Xu, Yuan Xie, and Norman P. Jouppi. 2012. NVSim: A Circuit-Level Performance, Energy, and Area Model for Emerging Nonvolatile Memory.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems31, 7 (2012), 994–1007
2012
-
[10]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiao- hua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, G Heigold, S Gelly, et al. 2020. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations
2020
-
[11]
Charles Eckert, Xiaowei Wang, Jingcheng Wang, Arun Subramaniyan, Ravi Iyer, Dennis Sylvester, David Blaaauw, and Reetuparna Das. 2018. Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks. In2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA). 383–396. doi:10.1109/ISCA.2018.00040
-
[12]
2023.22FDX®-EXT Technology Design Manual Rev
GlobalFoundries. 2023.22FDX®-EXT Technology Design Manual Rev. 1.0_4.1. https://gf.com/technology-platforms/fdx-fd-soi/
2023
-
[13]
Kshemal K Gupte, Sohan Salahuddin Mugdho, Cheng Huang, and Cheng Wang
-
[14]
Scalable and robust multi-bit spintronic synapses for analog in-memory computing.npj Unconventional Computing3, 1 (2026), 8
2026
-
[15]
Phatak, Cheng Wang, and Supratik Guha
Wilfried Haensch, Anand Raghunathan, Kaushik Roy, Bhaswar Chakrabarti, Charudatta M. Phatak, Cheng Wang, and Supratik Guha. 2023. Compute in- Memory with Non-Volatile Elements for Neural Networks: A Review from a Co-Design Perspective.Advanced Materials35, 37 (2023), 2204944. doi:10.1002/ adma.202204944
2023
-
[16]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
2016
-
[17]
R Heindl, William H Rippard, and Others. 2011. Validity of the thermal activation model for spin-transfer torque switching in magnetic tunnel junctions.Journal of Applied Physics109, 7 (2011)
2011
-
[18]
Intel Corporation. 2020. Intel®AVX-512 Architectural Performance Report (APP Metrics). https://cdrdv2-public.intel.com/840270/APP-for-Intel-Xeon- Processors.pdf. Accessed: 2025-11-15
2020
-
[19]
Intel Corporation. 2023. 4th Gen Intel®Xeon®Scalable Processor DL Boost AMX Deep-Learning Performance
2023
-
[20]
Intel Corporation. 2023. Intel®Xeon®Platinum 8480+ Processor Product Specifi- cations. https://www.intel.com/content/www/us/en/products/sku/231746/intel- xeon-platinum-8480-processor-105m-cache-2-00-ghz/specifications.html. Ac- cessed: 2025-11-15
2023
-
[21]
Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. (2009)
2009
-
[22]
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning.nature 521, 7553 (2015), 436–444
2015
-
[23]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. 2002. Gradient- based learning applied to document recognition.Proc. IEEE86, 11 (2002), 2278– 2324
2002
-
[24]
Yann LeCun, Corinna Cortes, and Christopher J. C. Burges. 1998. MNIST hand- written digit database
1998
-
[25]
Shuangchen Li, Dimin Niu, et al. 2017. DRISA: a DRAM-based Reconfigurable In-Situ Accelerator(MICRO-50 ’17). Association for Computing Machinery, New York, NY, USA, 288–301. doi:10.1145/3123939.3123977
-
[26]
Yang Lv, Brandon R Zink, Robert P Bloom, Hüsrev Cılasun, Pravin Khanal, Salonik Resch, Zamshed Chowdhury, Ali Habiboglu, Weigang Wang, Sachin S Sapatnekar, et al. 2024. Experimental demonstration of magnetic tunnel junction- based computational random-access memory.npj Unconventional Computing1, 1 (2024), 3
2024
-
[27]
Rogers, Weiwei Zhao, Yiyu Shi, and Cheng Wang
Sohan Salahuddin Mugdho, Yuanbo Guo, Ethan G. Rogers, Weiwei Zhao, Yiyu Shi, and Cheng Wang. 2025. FairXbar: Improving the Fairness of Deep Neural Networks with Non-Ideal in-Memory Computing Hardware. In2025 Design, Automation & Test in Europe Conference (DATE). 1–7. doi:10.23919/DATE64628. 2025.10993038
-
[28]
Sohan Salahuddin Mugdho, Kshemal K. Gupte, Md. Shahedul Hasan, and Cheng Wang. 2025. Area-Efficient Heterogeneous MRAM for High-Performing AI Acceleration. In2025 Cross-Disciplinary Conference on Memory-Centric Computing (CCMCC). 1–13. doi:10.1109/CCMCC67628.2025.11380744
-
[29]
Avilash Mukherjee, Kumar Saurav, et al. 2021. A case for emerging memories in DNN accelerators. In2021 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 938–941
2021
-
[30]
NCSU EDA Group. 2008. FreePDK45: An open-source 45nm process design kit. https://eda.ncsu.edu/freepdk/freepdk45/
2008
-
[31]
Mike O’Connor, Niladrish Chatterjee, and Others. 2017. Fine-grained DRAM: Energy-efficient DRAM for extreme bandwidth systems. InProceedings of the 50th Annual IEEE/ACM MICRO. 41–54
2017
-
[32]
J Thomas Pawlowski. 2011. Hybrid memory cube (HMC). In2011 IEEE Hot chips 23 symposium (HCS). IEEE, 1–24
2011
-
[33]
Salonik Resch, S. Karen Khatamifard, et al . 2020. MOUSE: Inference In Non- volatile Memory for Energy Harvesting Applications. In2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). 400–414. doi:10.1109/MICRO50266.2020.00042
-
[34]
Max Roser. 2022. The brief history of artificial intelligence: the world has changed fast — what might be next?Our World in Data(2022). https://ourworldindata.org/brief-history-of-ai
2022
-
[35]
Satyabrata Sarangi and Bevan Baas. 2021. DeepScaleTool: A tool for the accurate estimation of technology scaling in the deep-submicron era. InIEEE International Symposium on Circuits and Systems (ISCAS)
2021
-
[36]
Vivek Seshadri, Donghyuk Lee, et al. 2017. Ambit: in-memory accelerator for bulk bitwise operations using commodity DRAM technology. InProceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture(Cambridge, Massachusetts)(MICRO-50 ’17). Association for Computing Machinery, New York, NY, USA, 273–287. doi:10.1145/3123939.3124544
-
[37]
Stanley Williams, and Vivek Srikumar
Ali Shafiee, Anirban Nag, Naveen Muralimanohar, Rajeev Balasubramonian, John Paul Strachan, Miao Hu, R. Stanley Williams, and Vivek Srikumar. 2016. ISAAC: a convolutional neural network accelerator with in-situ analog arithmetic in crossbars. InProceedings of the 43rd International Symposium on Computer Architecture(Seoul, Republic of Korea)(ISCA ’16). IE...
2016
-
[38]
Gian Singh and Sarma Vrudhula. 2025. A Scalable and Energy-Efficient Processing-in-Memory Architecture for Gen-AI.IEEE JETCAS15, 2 (2025), 285–298
2025
-
[39]
Linghao Song, Xuehai Qian, Hai Li, and Yiran Chen. 2017. PipeLayer: A Pipelined ReRAM-Based Accelerator for Deep Learning. In2017 IEEE HPCA. doi:10.1109/ HPCA.2017.55
2017
-
[40]
Zahra Mehdizadeh Taheri, Sayed Masoud Sayedi, and Mohammad Hossein Moaiy- eri. 2025. Spintronic Content Addressable Memory With Integrated Boolean Logic and Arithmetic Functions.IEEE Access13 (2025), 49076–49091. doi:10. 1109/ACCESS.2025.3551411
arXiv 2025
-
[41]
Weier Wan, Rajkumar Kubendran, et al. 2022. A compute-in-memory chip based on resistive random-access memory.Nature608, 7923 (2022), 504–512
2022
-
[42]
Wilson, Jon Gorchon, Charles-Henri Lambert, Sayeef Salahuddin, and Jeffrey Bokor
Yang Yang, Richard B. Wilson, Jon Gorchon, Charles-Henri Lambert, Sayeef Salahuddin, and Jeffrey Bokor. 2017. Ultrafast magnetization reversal by picosec- ond electrical pulses.Science Advances3, 11 (2017), e1603117. doi:10.1126/sciadv. 1603117
-
[43]
Kentaro Yoshioka, Shimpei Ando, Satomi Miyagi, Yung-Chin Chen, and Wenlun Zhang. 2024. A review of SRAM-based compute-in-memory circuits.Japanese Journal of Applied Physics(2024)
2024
-
[44]
Masoud Zabihi, Zamshed Iqbal Chowdhury, et al. 2019. In-Memory Processing on the Spintronic CRAM: From Hardware Design to Application Mapping.IEEE Trans. Comput.68, 8 (2019), 1159–1173
2019
-
[45]
Masoud Zabihi, Zhengyang Zhao, et al. 2019. Using spin-Hall MTJs to build an energy-efficient in-memory computation platform. In20th International Sympo- sium on Quality Electronic Design (ISQED). IEEE, 52–57
2019
-
[46]
Zhizhen Zhong, Mingran Yang, et al. 2023. Lightning: A reconfigurable photonic- electronic smartnic for fast and energy-efficient inference. InProceedings of the ACM SIGCOMM 2023 Conference. 452–472
2023
-
[47]
Brandon R. Zink, Marc D. Riedel, Ulya R. Karpuzcu, and Jian-Ping Wang. 2024. A Comparison Study of Spin-Transfer Torque- and Spin-Orbit Torque-Based Sto- chastic Computing Using Computational Random Access Memory (SC-CRAM). IEEE Transactions on Magnetics60, 5 (2024), 1–15. doi:10.1109/TMAG.2023. 3326076
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.