Fixing FOLIO and MALLS: Verified Annotations and an LLM-assisted Framework to Focus Human Relabeling
Pith reviewed 2026-06-28 14:27 UTC · model grok-4.3
The pith
Incorrect FOL formalizations affect 39% of FOLIO and 36% of MALLS entries, and corrections improve LLM accuracy by 9 to 22 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
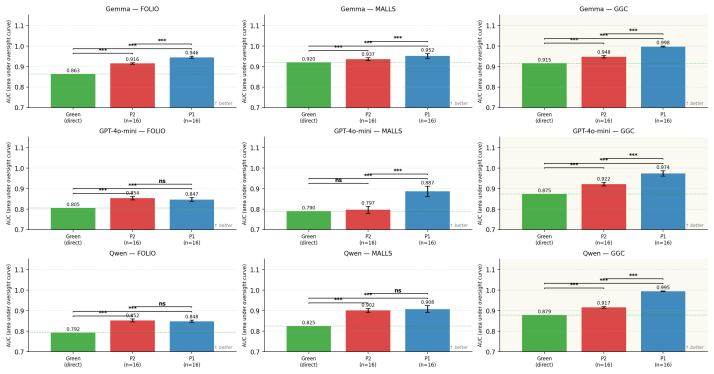
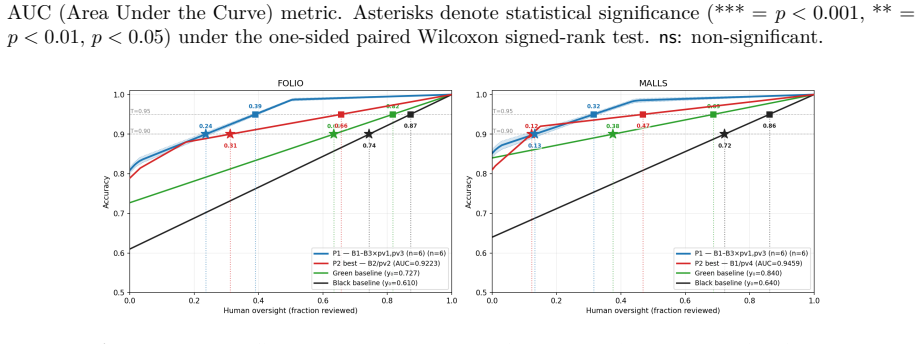
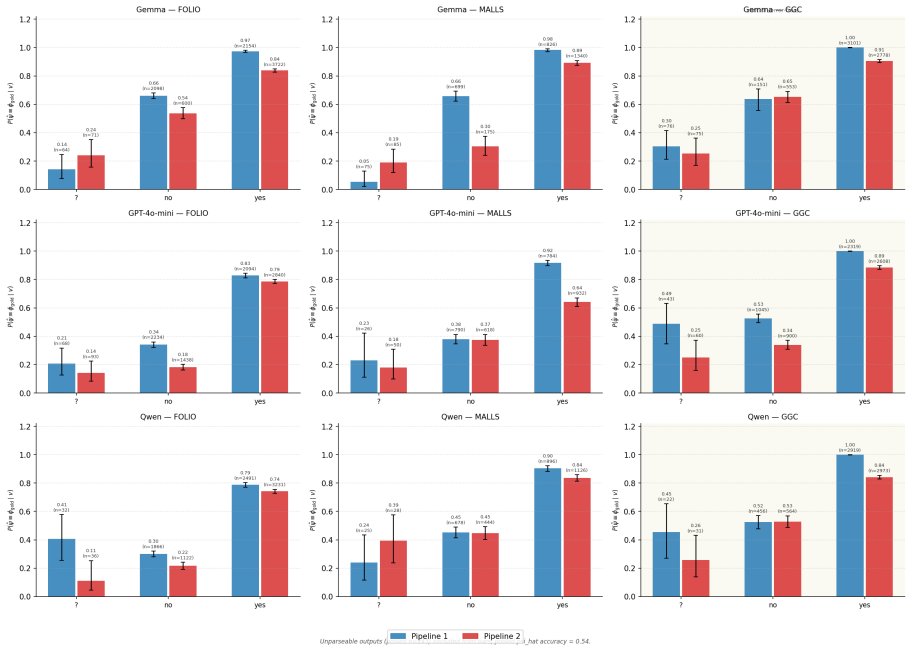
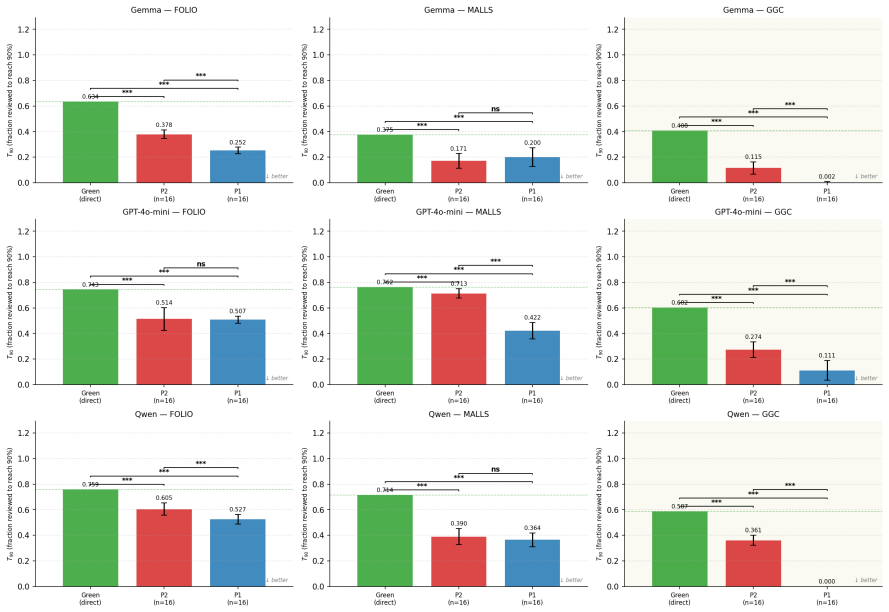
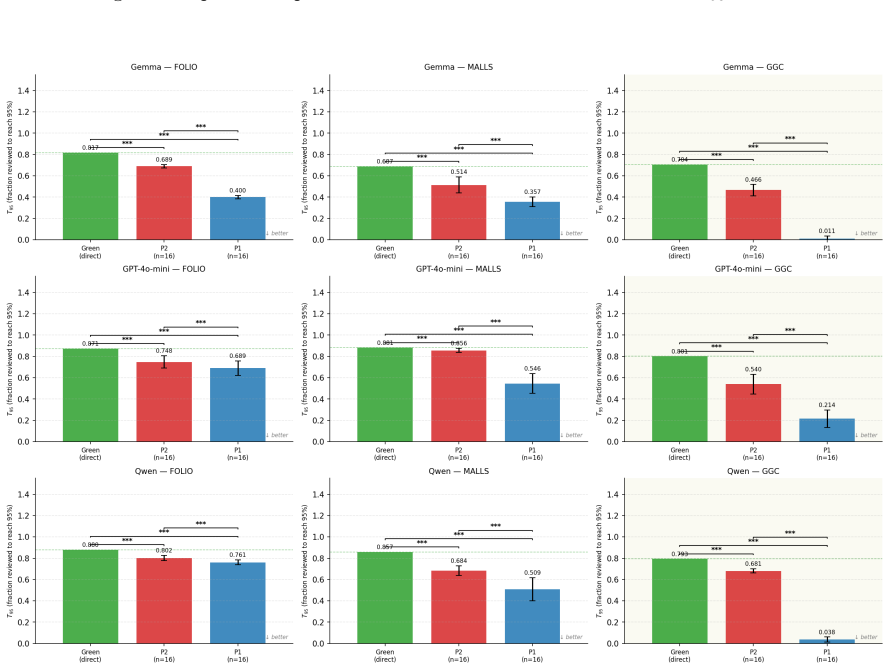
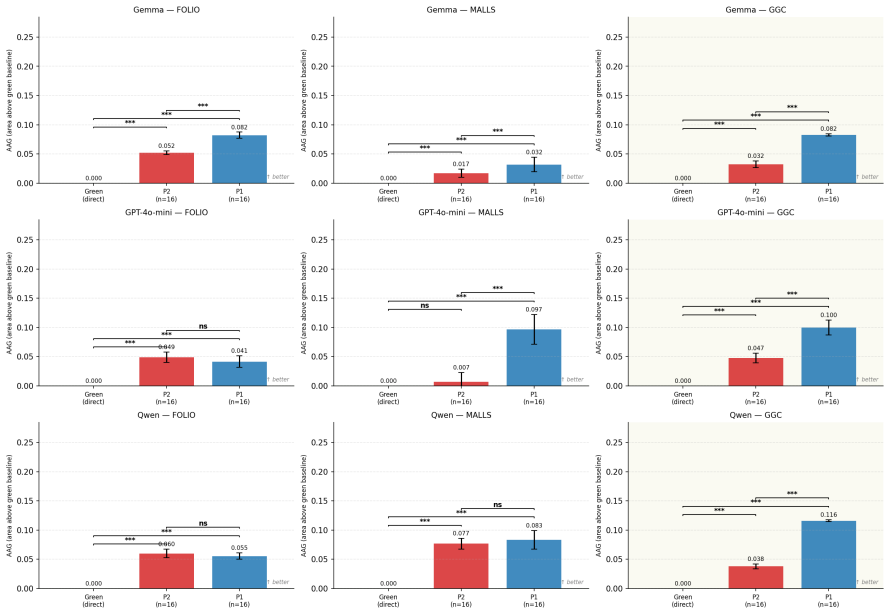
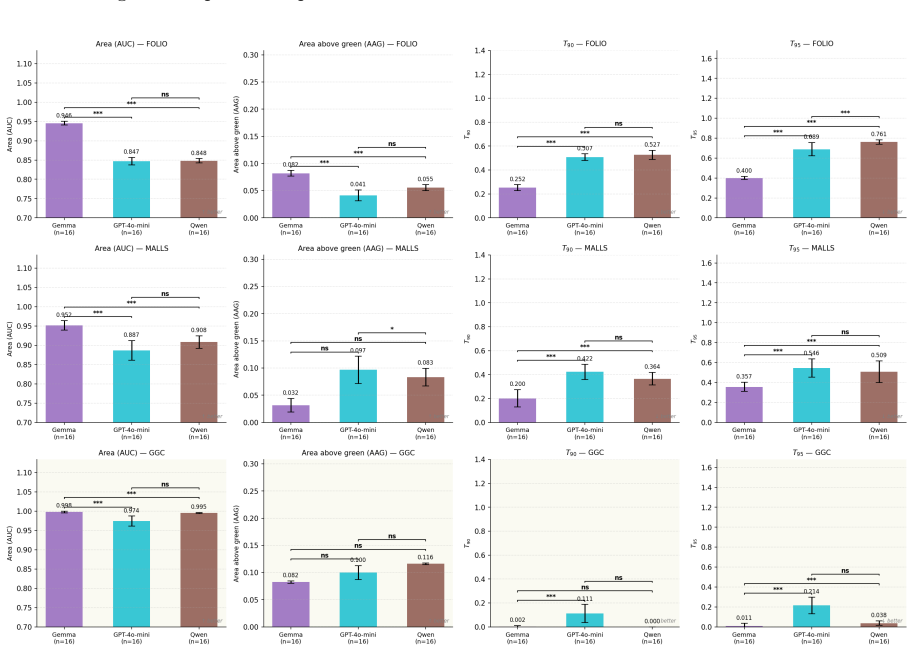
Systematic human inspection shows that approximately 39% of FOLIO entries and 36% of sampled MALLS entries have incorrect FOL formalizations as ground truth, accompanied by 16.4% and 48% ambiguous natural-language sentences plus 8.4% incorrect NLI labels in FOLIO; the corrected ground truths raise accuracy for Gemma 4 31B-it, Qwen3-30B-A3B, and GPT-4o-mini by 9 to 22 points, while an LLM-based framework prioritizes error-prone instances so that reviewers reach 90% dataset accuracy after examining under 24% of the data.
What carries the argument
An LLM-based framework that scores instances for likely annotation errors and directs human reviewers to the highest-risk subset first.
If this is right
- All prior model comparisons and leaderboard rankings on FOLIO and MALLS must be recomputed with the corrected labels.
- Neurosymbolic systems trained or evaluated on these datasets inherit the original label noise and require re-testing.
- The targeted-review approach cuts the human labor required to produce high-accuracy NL-to-FOL data by more than two-thirds.
- Any new NL-to-FOL benchmark should incorporate the same inspection step before release.
Where Pith is reading between the lines
- Un-audited NL-to-FOL or NLI datasets in other domains are likely to contain comparable fractions of label errors.
- The prioritization logic could be transferred to improve efficiency in other annotation-heavy tasks such as semantic parsing or program synthesis.
- Public release of the verified annotations creates a reusable reference that future work can treat as a cleaner baseline.
Load-bearing premise
The human inspection process correctly and consistently identifies incorrect FOL formalizations and ambiguities without systematic bias or new errors introduced during correction.
What would settle it
An independent team re-inspecting a random sample of the released corrections and reporting disagreement rates above 10% on the FOL labels would indicate that the reported error rates and accuracy gains rest on unreliable fixes.
Figures




read the original abstract
Accurate translation from Natural Language to First-Order Logic (NL-to-FOL) underpins neurosymbolic AI systems and Natural Language Inference (NLI), making the quality of NL-to-FOL benchmarks essential -- yet these datasets have never been rigorously audited. Our first contribution is to present a systematic human inspection of the validation split of \textsf{FOLIO} and a subset of \textsf{MALLS} test instances, finding that approximately 39% and 36% of entries, respectively, contain incorrect FOL formalizations (i.e., ground truth labels), with additional rates of ambiguous NL sentences (16.4% and 48%) and incorrect NLI labels in \textsf{FOLIO} (8.4%). Our second contribution is to develop and release corrected ground truths for such datasets, showing that annotation errors distort model evaluation on a reference benchmark task: testing three state-of-the-art LLMs (Gemma~4 31B-it, Qwen3-30B-A3B, and GPT-4o-mini) with the corrected ground truths yields accuracy gains from +9 to +22 percentage points. Motivated by these findings, we propose an LLM-based framework to support humans in manual reviewing NL-to-FOL datasets. By directing reviewers toward the most error-prone instances, we empirically show that it is possible to achieve 90% dataset accuracy after reviewing fewer than 24% of instances, compared to over 70% required by unguided review. We release all human-verified annotations and the code for our framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits the validation split of FOLIO and a subset of MALLS for NL-to-FOL translation quality via systematic human inspection, reporting ~39% and ~36% incorrect FOL formalizations (ground truth labels), plus 16.4%/48% ambiguous NL sentences and 8.4% incorrect NLI labels in FOLIO. It releases corrected annotations, shows that re-evaluating three LLMs (Gemma-4 31B-it, Qwen3-30B-A3B, GPT-4o-mini) on the corrected labels yields +9 to +22 pp accuracy gains, and proposes an LLM-assisted framework that directs human review to error-prone instances, achieving 90% dataset accuracy after reviewing <24% of instances versus >70% for unguided review.
Significance. If the human-verified corrections hold, the work demonstrates that annotation errors in prominent NL-to-FOL benchmarks materially distort model evaluations and supplies both corrected data and a practical prioritization framework that reduces human effort. Releasing the verified annotations and framework code strengthens reproducibility and enables follow-on auditing in neurosymbolic AI.
major comments (3)
- [Abstract and §3] Abstract and §3 (Human Inspection): The central numerical claims (39%/36% incorrect FOL, 16.4%/48% ambiguous, 8.4% wrong NLI) rest entirely on the authors' human inspection, yet the manuscript supplies no information on inspection protocol, number of annotators, inter-annotator agreement statistics, adjudication procedure for disagreements, or selection criteria for the MALLS subset. This directly undermines the load-bearing error-rate statistics and the downstream accuracy-gain results.
- [§4] §4 (Model Evaluation): The reported +9 to +22 pp accuracy gains are computed by comparing LLM performance on the original versus the authors' corrected labels. Without an independent validation of the corrections (e.g., blind re-annotation or external expert review), it is impossible to distinguish genuine error fixes from systematic shifts introduced by the inspection process itself.
- [§5] §5 (LLM-assisted Framework): The claim that the framework reaches 90% accuracy after reviewing <24% of instances depends on the same unvalidated human judgments used to define the 'error-prone' instances; any bias in the initial inspection propagates into the prioritization model and the reported efficiency gains.
minor comments (1)
- [Abstract] The abstract states results from human inspection but does not reference any supplementary material or appendix that might contain the missing protocol details; if such material exists, it should be explicitly cited in the main text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The concerns about transparency in the human inspection process and validation of corrections are well-taken. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Human Inspection): The central numerical claims (39%/36% incorrect FOL, 16.4%/48% ambiguous, 8.4% wrong NLI) rest entirely on the authors' human inspection, yet the manuscript supplies no information on inspection protocol, number of annotators, inter-annotator agreement statistics, adjudication procedure for disagreements, or selection criteria for the MALLS subset. This directly undermines the load-bearing error-rate statistics and the downstream accuracy-gain results.
Authors: We agree that the current description of the inspection process is insufficient. In the revised manuscript we will expand §3 with a dedicated subsection that specifies the annotation protocol, number of annotators and their qualifications, the guidelines provided to them, inter-annotator agreement statistics, the procedure used to resolve disagreements, and the exact selection criteria applied to the MALLS subset. These additions will make the reported error rates fully reproducible. revision: yes
-
Referee: [§4] §4 (Model Evaluation): The reported +9 to +22 pp accuracy gains are computed by comparing LLM performance on the original versus the authors' corrected labels. Without an independent validation of the corrections (e.g., blind re-annotation or external expert review), it is impossible to distinguish genuine error fixes from systematic shifts introduced by the inspection process itself.
Authors: We acknowledge that the manuscript does not include an independent blind re-annotation by external experts. The corrections were produced through systematic logical comparison of each FOL formula against its NL premise by the authors. In revision we will add an explicit limitations paragraph in §4 that discusses the possibility of systematic bias, reports any internal consistency checks performed, and stresses that the full set of corrected annotations is released publicly so that the community can perform independent verification. We maintain that the observed accuracy gains are driven by the removal of clear logical mismatches, but we will present this as an acknowledged limitation rather than a fully externally validated result. revision: partial
-
Referee: [§5] §5 (LLM-assisted Framework): The claim that the framework reaches 90% accuracy after reviewing <24% of instances depends on the same unvalidated human judgments used to define the 'error-prone' instances; any bias in the initial inspection propagates into the prioritization model and the reported efficiency gains.
Authors: We agree that the framework evaluation inherits the same human judgments used to label errors. In the revision we will clarify in §5 how the prioritization model was trained (on features derived from the inspected data), provide additional ablation results that isolate the contribution of the LLM component, and add a discussion of how inspection bias could affect the reported efficiency numbers. We will also release the framework code and the full set of model predictions so that others can re-evaluate the prioritization under alternative label sets. revision: yes
Circularity Check
Empirical audit reports direct observations with no self-referential reductions
full rationale
The paper reports error rates (39%/36% incorrect FOL, etc.) and LLM accuracy gains (+9 to +22 pp) obtained via systematic human inspection of existing dataset instances followed by direct re-evaluation of models on the resulting corrected labels. These quantities are produced by external annotation and testing steps rather than any equation, fitted parameter, or self-citation chain that reduces the outputs to the inputs by construction. No self-definitional, fitted-input-called-prediction, or ansatz-smuggling patterns appear in the abstract or described contributions. The LLM-assisted framework is a separate proposal and does not alter the reported statistics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators can reliably determine whether a given FOL formula is a correct formalization of a natural language sentence
Reference graph
Works this paper leans on
-
[1]
13th International Conference on Intelligent Computer Mathematics (CICM) , series =
Christian Szegedy , title =. 13th International Conference on Intelligent Computer Mathematics (CICM) , series =. 2020 , doi =
2020
-
[2]
2024 , url =
Long Hei Matthew Lam and others , title =. 2024 , url =
2024
-
[4]
Cox and Robert Dale , title =
Dave Barker-Plummer and Richard J. Cox and Robert Dale , title =. 2011 , isbn =
2011
-
[5]
CoRR , volume =
Dalrymple, David "davidad" and Skalse, Joar and Bengio, Yoshua and Russel, Stuart and Tegmark, Max and Seshia, Sanjit and Omohundro, Steve and Szegedy, Christian and Goldhaber, Ben and Ammann, Nora and Abate, Alessandro and Halpern, Joe and Barrett, Clark and Zhao, Ding and Zhi-Xuan, Tan and Wing, Jeannette and Tenenbaum, Joshua , title =. CoRR , volume =...
2024
-
[6]
and Dale, Robert , booktitle=
Barker-Plummer, Dave and Cox, Richard J. and Dale, Robert , booktitle=. Student translations of natural language into logic:
-
[7]
Cox and Robert Dale , year=
Dave Barker-Plummer and Richard J. Cox and Robert Dale , year=. Tarski’s
-
[8]
Deshmukh, Jyotirmoy and Kantaros, Yiannis , title =
Wang, Jun and Sundarsingh, David Smith and V. Deshmukh, Jyotirmoy and Kantaros, Yiannis , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.21022 , eprinttype =. 2504.21022 , timestamp =
-
[9]
Apurwa Yadav and Aarshil Patel and Manan Shah , title =. 2021 , url =. doi:10.1016/J.AIOPEN.2021.05.001 , timestamp =
-
[10]
Lei Xu and others , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.06774 , eprinttype =. 2510.06774 , timestamp =
-
[11]
Advancing Natural Language Formalization to First Order Logic with Fine-tuned LLMs
Vossel, Felix and Mossakowski, Till and Gehrke, Björn , biburl =. Advancing Natural Language Formalization to First Order Logic with Fine-tuned LLMs. , url =. CoRR , keywords =
-
[12]
Soviet physics
Binary codes capable of correcting deletions, insertions, and reversals , author=. Soviet physics. Doklady , year=
-
[13]
arXiv preprint arXiv:2405.02318 , year=
Autoformalizing Natural Language to First-Order Logic: A Case Study in Logical Fallacy Detection , author=. arXiv preprint arXiv:2405.02318 , year=
-
[14]
QA - N at V er: Question Answering for Natural Logic-based Fact Verification
Aly, Rami and others. QA - N at V er: Question Answering for Natural Logic-based Fact Verification. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.521
-
[15]
Jin, Zhijing and others. Logical Fallacy Detection. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.532
-
[16]
Yujun Zhou and others , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.04810 , eprinttype =. 2506.04810 , timestamp =
-
[17]
2024 , url =
Andrea Brunello and others , title =. 2024 , url =
2024
-
[18]
Lee, Hyemin S
Ryu, Hyun and Kim, Gyeongman and S. Lee, Hyemin S. and Yang, Eunho , title =. 2025 , url =
2025
-
[19]
Complexity Parameters for First-Order Classes , booktitle =
Marta Arias and Roni Khardon , editor =. Complexity Parameters for First-Order Classes , booktitle =. 2003 , url =. doi:10.1007/978-3-540-39917-9\_4 , timestamp =
-
[20]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,
Fengxiang Cheng and others , title =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,. 2025 , url =. doi:10.24963/IJCAI.2025/1155 , timestamp =
-
[21]
Lovish Madaan and others , title =. 2025 , url =. doi:10.18653/V1/2025.NAACL-LONG.466 , timestamp =
-
[22]
ICLR 2024 Workshop on Secure and Trustworthy Large Language Models , year=
Enhancing and Evaluating Logical Reasoning Abilities of Large Language Models , author=. ICLR 2024 Workshop on Secure and Trustworthy Large Language Models , year=
2024
-
[23]
NeurIPS 2022, November 28 - December 9, 2022 , year =
Yuhuai Wu and others , title =. NeurIPS 2022, November 28 - December 9, 2022 , year =
2022
-
[24]
Jundong Xu and others , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.720 , timestamp =
-
[25]
Benjamin Callewaert and others , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2501.14540 , eprinttype =. 2501.14540 , timestamp =
-
[26]
Few-Shot Natural Language to First-Order Logic Translation via Code Generation , booktitle =
Junnan Liu , editor =. Few-Shot Natural Language to First-Order Logic Translation via Code Generation , booktitle =. 2025 , url =. doi:10.18653/V1/2025.NAACL-LONG.547 , timestamp =
-
[28]
Xin Quan and others , title =. 2024 , url =. doi:10.18653/V1/2024.EMNLP-MAIN.172 , timestamp =
-
[29]
1990 , url=
Events in the Semantics of English: A Study in Subatomic Semantics , author=. 1990 , url=
1990
-
[30]
Christopher Hahn and others , title =. CoRR , volume =. 2022 , url =. doi:10.48550/ARXIV.2206.01962 , eprinttype =. 2206.01962 , timestamp =
-
[31]
Parsing the WSJ Using CCG and Log-Linear Models
Clark, Stephen and Curran, James R. Parsing the WSJ Using CCG and Log-Linear Models. ACL -04. 2004. doi:10.3115/1218955.1218969
-
[32]
2015 , url =
Johan Bos , title =. 2015 , url =
2015
-
[33]
Yu Pei and others , title =. Trans. Assoc. Comput. Linguistics , volume =. 2025 , url =. doi:10.1162/TACL.A.41 , timestamp =
-
[34]
GCAT 2023 , year=
Data and Knowledge Engineering for Legal Precedents Using First-Order Predicate Logic , author=. GCAT 2023 , year=
2023
-
[35]
Towards Advanced Mathematical Reasoning for LLM s via First-Order Logic Theorem Proving
Cao, Chuxue and others. Towards Advanced Mathematical Reasoning for LLM s via First-Order Logic Theorem Proving. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.628
-
[36]
Grammar-Constrained Decoding Makes Large Language Models Better Logical Parsers
Raspanti, Federico and others. Grammar-Constrained Decoding Makes Large Language Models Better Logical Parsers. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track). 2025. doi:10.18653/v1/2025.acl-industry.34
-
[37]
Tam, Zhi Rui and others. Let Me Speak Freely? A Study On The Impact Of Format Restrictions On Large Language Model Performance. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2024. doi:10.18653/v1/2024.emnlp-industry.91
-
[39]
SEMANTiCS 2025, Vienna, Austria, September 3-5, 2025 , series =
Alexander Beiser and others , title =. SEMANTiCS 2025, Vienna, Austria, September 3-5, 2025 , series =. 2025 , url =
2025
-
[40]
Mihir Parmar and others , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.739 , timestamp =
-
[41]
Into The Limits of Logic: Alignment Methods for Formal Logical Reasoning
Lopez-Ponce, FernandoFrancisco and Bel-Enguix, Gemma. Into The Limits of Logic: Alignment Methods for Formal Logical Reasoning. MathNLP 2025. 2025. doi:10.18653/v1/2025.mathnlp-main.8
-
[42]
Diagnosing the First-Order Logical Reasoning Ability Through L ogic NLI
Tian, Jidong and others. Diagnosing the First-Order Logical Reasoning Ability Through L ogic NLI. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.303
-
[43]
Thatikonda, Ramya Keerthy and Han, Jiuzhou and Buntine, Wray and Shareghi, Ehsan , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2409.16461 , eprinttype =. 2409.16461 , timestamp =
-
[44]
2025 , url =
Chengwen Qi and others , title =. 2025 , url =
2025
-
[45]
NeurIPS 2023, December 10 - 16, 2023 , year =
Ye, Xi and Chen, Qiaochu and Dillig, Isil and Durrett, Greg , title =. NeurIPS 2023, December 10 - 16, 2023 , year =
2023
-
[46]
Generating Predicate Logic Expressions from Natural Language , year=
Levkovskyi, Oleksii and Li, Wei , booktitle=. Generating Predicate Logic Expressions from Natural Language , year=
-
[47]
Educational Data Mining , year=
Dimensions of Difficulty in Translating Natural Language into First-Order Logic , author=. Educational Data Mining , year=
-
[48]
Singh, Hrituraj and Aggarwal, Milan and Krishnamurthy, Balaji , title =. CoRR , volume =. 2020 , url =. 2002.06544 , timestamp =
arXiv 2020
-
[49]
Parsing Natural Language into Propositional and First-Order Logic with Dual Reinforcement Learning
Lu, Xuantao and others. Parsing Natural Language into Propositional and First-Order Logic with Dual Reinforcement Learning. Proceedings of the 29th International Conference on Computational Linguistics. 2022
2022
-
[50]
Findings of the Association for Computational Linguistics:
Akshay Chaturvedi and Nicholas Asher , title =. Findings of the Association for Computational Linguistics:. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-EMNLP.390 , timestamp =
-
[51]
Faithful Chain-of-Thought Reasoning
Lyu, Qing and others. Faithful Chain-of-Thought Reasoning. Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.ijcnlp-main.20
-
[52]
Qingchuan Li and others , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.21779 , eprinttype =. 2410.21779 , timestamp =
-
[53]
Olausson, Theo and Gu, Alex and Lipkin, Ben and Zhang, Cedegao and Solar-Lezama, Armando and Tenenbaum, Joshua and Levy, Roger , title =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.313 , timestamp =
-
[54]
Peizhang Shao and others , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.07748 , eprinttype =. 2507.07748 , timestamp =
-
[55]
Bowen Jiang and others , title =. 2025 , url =. doi:10.18653/V1/2025.NAACL-LONG.186 , timestamp =
-
[56]
Laura Orynbay and others , title =. Frontiers Comput. Sci. , volume =. 2025 , url =. doi:10.3389/FCOMP.2024.1486581 , timestamp =
-
[57]
Findings of the Association for Computational Linguistics:
Pan, Liangming and Albalak, Alon and Wang, Xinyi and Yang Wang, William , title =. Findings of the Association for Computational Linguistics:. 2023 , url =. doi:10.18653/V1/2023.FINDINGS-EMNLP.248 , timestamp =
-
[58]
Shashank Kirtania and others , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2407.02514 , eprinttype =. 2407.02514 , timestamp =
-
[59]
Logic-Thinker: Teaching Large Language Models to Think more Logically
Wen, Chengyao and others. Logic-Thinker: Teaching Large Language Models to Think more Logically. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.696
-
[60]
Koushik Viswanadha and others , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.18383 , eprinttype =. 2506.18383 , timestamp =
-
[61]
Fangzhi Xu and others , title =. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.707 , timestamp =
-
[62]
2025 , url =
Ruikang Hu and others , title =. 2025 , url =
2025
-
[63]
Hannah Bansal and others , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.17377 , eprinttype =. 2509.17377 , timestamp =
-
[64]
Zhaofeng Wu and others , title =. 2024 , url =. doi:10.18653/V1/2024.NAACL-LONG.102 , timestamp =
-
[65]
Findings of the Association for Computational Linguistics:
Oyvind Tafjord and others , title =. Findings of the Association for Computational Linguistics:. 2021 , url =. doi:10.18653/V1/2021.FINDINGS-ACL.317 , timestamp =
-
[66]
Transformers as Soft Reasoners over Language , booktitle =
Peter Clark and others , editor =. Transformers as Soft Reasoners over Language , booktitle =. 2020 , url =. doi:10.24963/IJCAI.2020/537 , timestamp =
-
[67]
Debargha Ganguly and others , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2409.17270 , eprinttype =. 2409.17270 , timestamp =
-
[68]
Findings of the Association for Computational Linguistics:
Simeng Han and others , title =. Findings of the Association for Computational Linguistics:. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-EMNLP.966 , timestamp =
-
[69]
Qianxi He and others , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.19907 , eprinttype =. 2502.19907 , timestamp =
-
[70]
Shokhrukh Ibragimov and others , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.14180 , eprinttype =. 2502.14180 , timestamp =
-
[71]
Navapat Nananukul and others , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.01530 , eprinttype =. 2510.01530 , timestamp =
-
[72]
2025 , eprint=
From Hypothesis to Premises: LLM-based Backward Logical Reasoning with Selective Symbolic Translation , author=. 2025 , eprint=
2025
-
[73]
Yue Zhang and others , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.21281 , eprinttype =. 2505.21281 , timestamp =
-
[74]
Ontology learning towards expressiveness: A survey , journal =
Pauline Armary and others , keywords =. Ontology learning towards expressiveness: A survey , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.cosrev.2024.100693 , url =
-
[75]
Rick Du and others , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2404.14991 , eprinttype =. 2404.14991 , timestamp =
-
[76]
Zhengkun Di and others , title =. Knowl. Based Syst. , volume =. 2025 , url =. doi:10.1016/J.KNOSYS.2025.114140 , timestamp =
-
[77]
arXiv preprint arXiv:2509.24765 , year=
From Ambiguity to Verdict: A Semiotic-Grounded Multi-Perspective Agent for LLM Logical Reasoning , author=. arXiv preprint arXiv:2509.24765 , year=
-
[78]
2024 , eprint=
uto val: Autonomous Assessment of LLMs in Formal Synthesis and Interpretation Tasks , author=. 2024 , eprint=
2024
-
[79]
Learning First-Order Logic Rules for Argumentation Mining
Sun, Yang and others. Learning First-Order Logic Rules for Argumentation Mining. ACL 2025. 2025. doi:10.18653/v1/2025.acl-long.691
-
[80]
Transformer models for translating natural language sentences into formal logical expressions , school=
Deveci, İbrahim Ethem , year=. Transformer models for translating natural language sentences into formal logical expressions , school=
-
[81]
Samuele Germiniani and others , title =. 2025 , url =. doi:10.1109/ACCESS.2025.3551607 , timestamp =
-
[82]
Ali Mohammadjafari and others , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.01066 , eprinttype =. 2410.01066 , timestamp =
-
[83]
Ke Weng and others , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.23486 , eprinttype =. 2505.23486 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.