Neural Networks Provably Learn Spectral Representations for Group Composition
Pith reviewed 2026-06-28 11:44 UTC · model grok-4.3
The pith
Lifting gradient flow to the Fourier domain makes each neuron in a two-layer network converge to one irreducible group representation on composition tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Lifting the projected gradient flow to the Fourier domain shows that training is governed by Riemannian gradient ascent on a representation-theoretic energy functional. Under random initialization this flow drives each neuron to converge almost surely toward a single irreducible representation, while the cross-layer Fourier coefficients achieve a rotational rank-one alignment. The same account explains feature learning and produces a low-rank compression phenomenon for matrix-valued group representations. For Abelian groups random initialization promotes uniform diversification across nontrivial representations and induces Haar-uniform phases that jointly approximate the indicator via majori
What carries the argument
The Fourier-domain lifting of the projected gradient flow, which converts the original dynamics into Riemannian gradient ascent on a representation-theoretic energy functional.
If this is right
- Each neuron converges almost surely to a single irreducible representation of the group.
- Cross-layer Fourier coefficients achieve rotational rank-one alignment.
- A low-rank compression occurs for the matrix-valued group representations.
- For Abelian groups the process produces uniform diversification across nontrivial representations together with Haar-uniform phases.
- Both phase alignment and representation competition converge at exponential rates and the group indicator is recovered by majority vote.
Where Pith is reading between the lines
- The same Fourier-lifting technique could be applied to other algebraic structures to predict which features networks will discover.
- Networks trained on data with hidden group symmetry may exhibit the same neuron-to-irrep alignment, offering a diagnostic for internal representations.
- The low-rank compression suggests that group-equivariant layers could be parameterized more efficiently by retaining only the dominant Fourier modes.
- Numerical checks on small groups would directly test whether the predicted rank-one alignment appears in practice.
Load-bearing premise
Transforming the projected gradient flow into the Fourier domain captures the essential training dynamics without adding unaccounted approximations or constraints.
What would settle it
Train the network on the symmetric group S3, extract the Fourier coefficients of the hidden-layer neurons, and check whether they fail to concentrate on single irreps or whether the cross-layer alignment deviates from rank one.
Figures






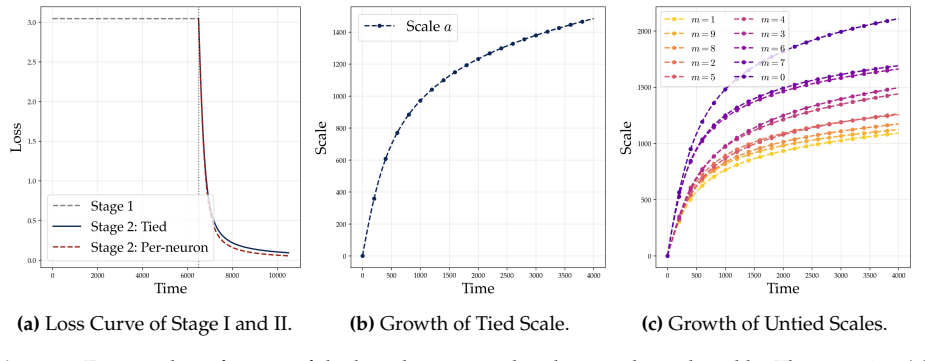

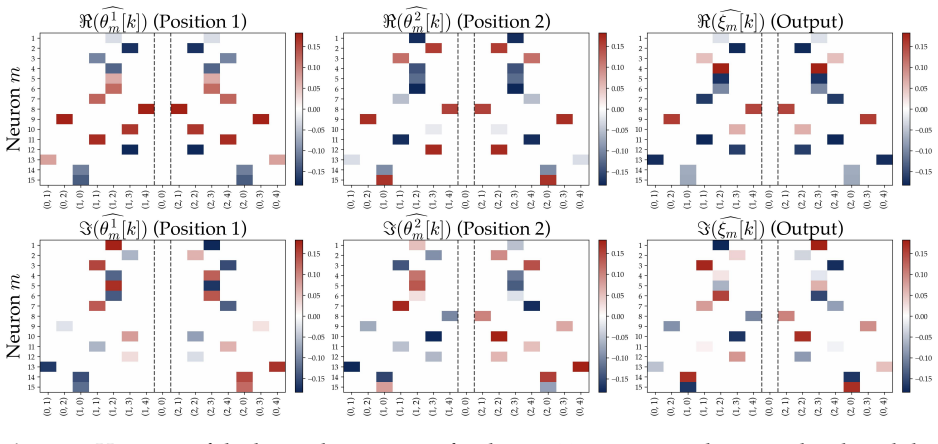

read the original abstract
Understanding how structured internal structure emerges during neural network training is central to the study of deep learning. We investigate this phenomenon through the group composition task, where a two-layer neural network is trained to predict $g_1 \star g_2$ for elements of a finite group $G$. By lifting the projected gradient flow to the Fourier domain, we demonstrate that the training dynamics are governed by a Riemannian gradient ascent on a representation-theoretic energy functional. We prove that, under random initialization, this flow drives each neuron to converge almost surely toward a single irreducible representation, while the cross-layer Fourier coefficients achieve a rotational rank-one alignment. This framework provides a representation-theoretic account of feature learning and characterizes a novel low-rank compression phenomenon for matrix-valued group representations. Moreover, for Abelian groups, we provide a complete population-level description: random initialization promotes uniform diversification across nontrivial representations and induces Haar-uniform phases, jointly approximating the indicator via a majority-vote mechanism. We further prove that both phase alignment and representation competition emerge with exponential convergence rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies two-layer neural networks trained on the finite-group composition task (predict g1 ⋆ g2). By lifting projected gradient flow to the Fourier domain, it claims the dynamics reduce exactly to Riemannian gradient ascent on a representation-theoretic energy; under random initialization this yields almost-sure convergence of each neuron to a single irreducible representation, rotational rank-one alignment of cross-layer Fourier coefficients, a low-rank compression phenomenon, and—for Abelian groups—a complete population-level characterization with uniform diversification, Haar-uniform phases, majority-vote approximation of the indicator, and exponential convergence rates.
Significance. If the lifting is exact and the convergence statements hold, the work supplies a representation-theoretic account of feature learning and a novel compression result for matrix-valued group representations. The explicit exponential-rate claims and the Abelian-group population description would be notable contributions to the theory of structured feature emergence.
major comments (1)
- The central claim that the projected gradient flow, once lifted to the Fourier domain, becomes exactly a Riemannian gradient ascent on the representation-theoretic energy functional (without residual terms arising from the projection) is load-bearing for every convergence and alignment result. For non-Abelian groups the irreps are matrix-valued; the projection onto the network parameter manifold need not commute with the Fourier transform, so it is unclear whether the lifted dynamics remain exactly the claimed Riemannian flow or acquire additional constraints or approximation errors.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the centrality of the exact lifting argument. We address the single major comment below.
read point-by-point responses
-
Referee: The central claim that the projected gradient flow, once lifted to the Fourier domain, becomes exactly a Riemannian gradient ascent on the representation-theoretic energy functional (without residual terms arising from the projection) is load-bearing for every convergence and alignment result. For non-Abelian groups the irreps are matrix-valued; the projection onto the network parameter manifold need not commute with the Fourier transform, so it is unclear whether the lifted dynamics remain exactly the claimed Riemannian flow or acquire additional constraints or approximation errors.
Authors: We agree that exactness of the lift is essential. In the manuscript (Section 3 and Appendix B), the projected gradient flow is written in coordinates that are already the Fourier coefficients of the weight matrices. Because the discrete Fourier transform on a finite group is a unitary change of basis (with respect to the standard Euclidean inner product on the parameter space), it is an isometry; the orthogonal projection onto the Stiefel manifold of each layer therefore commutes with the transform and produces no residual terms. For non-Abelian groups the same argument applies entrywise to the matrix-valued Fourier coefficients: each irrep block evolves independently under its own Riemannian metric induced by the Frobenius inner product, and the projection remains block-diagonal in the Fourier basis. We will add an explicit lemma (new Lemma 3.2) and a short remark after Equation (7) in the revision to make this commutation explicit and to address the matrix-valued case directly. revision: yes
Circularity Check
No circularity: derivation applies representation theory to gradient flow without reduction to inputs
full rationale
The paper's chain begins with the group composition task and projected gradient flow on a two-layer network, then lifts the dynamics to the Fourier domain over the finite group G to obtain a Riemannian gradient ascent on a representation-theoretic energy. From random initialization it derives almost-sure convergence of neurons to single irreps and rank-one alignment of cross-layer coefficients. These steps invoke standard finite-group representation theory and Riemannian optimization; no equation equates a claimed prediction to a fitted parameter by construction, no self-citation supplies a load-bearing uniqueness theorem, and no ansatz is smuggled via prior work. The analysis remains self-contained against external benchmarks of representation theory and optimization, yielding a score of 0.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Fourier analysis on finite groups lifts the gradient flow to a Riemannian structure on representation space
- domain assumption Network weights are initialized randomly
Reference graph
Works this paper leans on
-
[1]
2013 , publisher=
Global stability of dynamical systems , author=. 2013 , publisher=
2013
-
[2]
Advances in Neural Information Processing Systems , volume =
High-dimensional Asymptotics of Feature Learning: How One Gradient Step Improves the Representation , author =. Advances in Neural Information Processing Systems , volume =
-
[3]
Advances in Neural Information Processing Systems , volume =
Neural network learns low-dimensional polynomials with SGD near the information-theoretic limit , author =. Advances in Neural Information Processing Systems , volume =. 2024 , doi =
2024
-
[4]
International Conference on Learning Representations , year =
Can Neural Networks Achieve Optimal Computational-statistical Tradeoff? An Analysis on Single-Index Model , author =. International Conference on Learning Representations , year =
-
[5]
Foundations of Computational Mathematics , year =
Learning Time-Scales in Two-Layers Neural Networks , author =. Foundations of Computational Mathematics , year =
-
[6]
Proceedings of Thirty Fifth Conference on Learning Theory , series =
Neural Networks can Learn Representations with Gradient Descent , author =. Proceedings of Thirty Fifth Conference on Learning Theory , series =. 2022 , publisher =
2022
-
[7]
2024 , eprint =
Repetita Iuvant: Data Repetition Allows SGD to Learn High-Dimensional Multi-Index Functions , author =. 2024 , eprint =
2024
-
[8]
Advances in Neural Information Processing Systems , year =
Emergence and scaling laws in SGD learning of shallow neural networks , author =. Advances in Neural Information Processing Systems , year =
-
[9]
Advances in Neural Information Processing Systems , volume =
Can SGD Learn Recurrent Neural Networks with Provable Generalization? , author =. Advances in Neural Information Processing Systems , volume =
-
[10]
International Conference on Learning Representations , year =
A Theoretical Analysis on Feature Learning in Neural Networks: Emergence from Inputs and Advantage over Fixed Features , author =. International Conference on Learning Representations , year =
-
[11]
Advances in Neural Information Processing Systems , volume =
Provable Guarantees for Neural Networks via Gradient Feature Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[12]
International Conference on Learning Representations , year=
Exact Solutions to the Nonlinear Dynamics of Learning in Deep Linear Neural Networks , author=. International Conference on Learning Representations , year=
-
[13]
International Conference on Learning Representations , year=
Gradient Descent Maximizes the Margin of Homogeneous Neural Networks , author=. International Conference on Learning Representations , year=
-
[14]
Advances in Neural Information Processing Systems , volume=
Noether's Learning Dynamics: Role of Symmetry Breaking in Neural Networks , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
arXiv preprint arXiv:2201.02177 , year=
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets , author=. arXiv preprint arXiv:2201.02177 , year=
-
[16]
International Conference on Learning Representations , year=
Progress Measures for Grokking via Mechanistic Interpretability , author=. International Conference on Learning Representations , year=
-
[17]
Advances in Neural Information Processing Systems , year=
Towards Understanding Grokking: An Effective Theory of Representation Learning , author=. Advances in Neural Information Processing Systems , year=
-
[18]
Proceedings of the 41st International Conference on Machine Learning , series=
Why Do You Grok? A Theoretical Analysis on Grokking Modular Addition , author=. Proceedings of the 41st International Conference on Machine Learning , series=
-
[19]
International Conference on Learning Representations , year=
Grokking at the Edge of Numerical Stability , author=. International Conference on Learning Representations , year=
-
[20]
Proceedings of the 42nd International Conference on Machine Learning , series=
Emergence in Non-neural Models: Grokking Modular Arithmetic via Average Gradient Outer Product , author=. Proceedings of the 42nd International Conference on Machine Learning , series=
-
[21]
Proceedings of the 40th International Conference on Machine Learning , series=
A Toy Model of Universality: Reverse Engineering how Networks Learn Group Operations , author=. Proceedings of the 40th International Conference on Machine Learning , series=
-
[22]
Proceedings of the 41st International Conference on Machine Learning , series=
Grokking Group Multiplication with Cosets , author=. Proceedings of the 41st International Conference on Machine Learning , series=
-
[23]
International Conference on Learning Representations , year=
Towards a Unified and Verified Understanding of Group-Operation Networks , author=. International Conference on Learning Representations , year=
-
[24]
Proceedings of the 33rd International Conference on Machine Learning , series=
Group Equivariant Convolutional Networks , author=. Proceedings of the 33rd International Conference on Machine Learning , series=
-
[25]
Proceedings of the 35th International Conference on Machine Learning , series=
On the Generalization of Equivariance and Convolution in Neural Networks to the Action of Compact Groups , author=. Proceedings of the 35th International Conference on Machine Learning , series=
-
[26]
Proceedings of the 38th International Conference on Machine Learning , series=
A Practical Method for Constructing Equivariant Multilayer Perceptrons for Arbitrary Matrix Groups , author=. Proceedings of the 38th International Conference on Machine Learning , series=
-
[27]
Advances in Neural Information Processing Systems , year=
A General Framework for Equivariant Neural Networks on Reductive Lie Groups , author=. Advances in Neural Information Processing Systems , year=
-
[28]
arXiv preprint arXiv:2104.13478 , year=
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges , author=. arXiv preprint arXiv:2104.13478 , year=
-
[29]
Proceedings of Thirty Seventh Conference on Learning Theory , series=
Harmonics of Learning: Universal Fourier Features Emerge in Invariant Networks , author=. Proceedings of Thirty Seventh Conference on Learning Theory , series=
-
[30]
Proceedings of the 41st International Conference on Machine Learning , series=
Emergent Equivariance in Deep Ensembles , author=. Proceedings of the 41st International Conference on Machine Learning , series=
-
[31]
Advances in Neural Information Processing Systems , year=
MatrixNet: Learning over Symmetry Groups using Learned Group Representations , author=. Advances in Neural Information Processing Systems , year=
-
[32]
Journal of Machine Learning Research , volume=
Causal Abstraction: A Theoretical Foundation for Mechanistic Interpretability , author=. Journal of Machine Learning Research , volume=
-
[33]
Transactions on Machine Learning Research , year=
Mechanistic Interpretability for AI Safety -- A Review , author=. Transactions on Machine Learning Research , year=
-
[34]
2013 , publisher=
Differential equations and dynamical systems , author=. 2013 , publisher=
2013
-
[35]
2005 , publisher=
Riemannian geometry and geometric analysis , author=. 2005 , publisher=
2005
-
[36]
1999 , publisher=
Fourier analysis on finite groups and applications , author=. 1999 , publisher=
1999
-
[37]
1977 , publisher=
Linear representations of finite groups , author=. 1977 , publisher=
1977
-
[38]
arXiv preprint arXiv:2309.15111 , year=
Sgd finds then tunes features in two-layer neural networks with near-optimal sample complexity: A case study in the xor problem , author=. arXiv preprint arXiv:2309.15111 , year=
-
[39]
Advances in Neural Information Processing Systems , volume=
Hidden progress in deep learning: Sgd learns parities near the computational limit , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Journal of the American statistical association , volume=
Probability inequalities for sums of bounded random variables , author=. Journal of the American statistical association , volume=. 1963 , publisher=
1963
-
[41]
Mathematical programming , volume=
First-order methods almost always avoid strict saddle points , author=. Mathematical programming , volume=. 2019 , publisher=
2019
-
[42]
arXiv preprint arXiv:1607.06450 , year=
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
-
[43]
Conference on Learning Theory , pages=
The merged-staircase property: a necessary and nearly sufficient condition for sgd learning of sparse functions on two-layer neural networks , author=. Conference on Learning Theory , pages=. 2022 , organization=
2022
-
[44]
Proceedings of the National Academy of Sciences , volume=
A mean field view of the landscape of two-layer neural networks , author=. Proceedings of the National Academy of Sciences , volume=. 2018 , publisher=
2018
-
[45]
Advances in Neural Information Processing Systems , volume=
When do neural networks outperform kernel methods? , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
Journal of Machine Learning Research , volume=
The implicit bias of gradient descent on separable data , author=. Journal of Machine Learning Research , volume=
-
[47]
arXiv preprint arXiv:2602.03655 , year=
Sequential Group Composition: A Window into the Mechanics of Deep Learning , author=. arXiv preprint arXiv:2602.03655 , year=
-
[48]
arXiv preprint arXiv:2506.06489 , year=
Alternating gradient flows: A theory of feature learning in two-layer neural networks , author=. arXiv preprint arXiv:2506.06489 , year=
-
[49]
IEEE transactions on pattern analysis and machine intelligence , volume=
Representation learning: A review and new perspectives , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2013 , publisher=
2013
-
[50]
arXiv preprint arXiv:1804.08838 , year=
Measuring the intrinsic dimension of objective landscapes , author=. arXiv preprint arXiv:1804.08838 , year=
-
[51]
arXiv preprint arXiv:2010.15327 , year=
Do wide and deep networks learn the same things? uncovering how neural network representations vary with width and depth , author=. arXiv preprint arXiv:2010.15327 , year=
arXiv 2010
-
[52]
arXiv preprint arXiv:2602.16849 , year=
On the Mechanism and Dynamics of Modular Addition: Fourier Features, Lottery Ticket, and Grokking , author=. arXiv preprint arXiv:2602.16849 , year=
-
[53]
arXiv preprint arXiv:2604.21691 , year=
There Will Be a Scientific Theory of Deep Learning , author=. arXiv preprint arXiv:2604.21691 , year=
-
[54]
arXiv preprint arXiv:2509.21519 , year=
Provable Scaling Laws of Feature Emergence from Learning Dynamics of Grokking , author=. arXiv preprint arXiv:2509.21519 , year=
-
[55]
arXiv preprint arXiv:2511.07378 , year=
Transformers Provably Learn Chain-of-Thought Reasoning with Length Generalization , author=. arXiv preprint arXiv:2511.07378 , year=
-
[56]
arXiv preprint arXiv:2410.01779 , year=
Composing Global Optimizers to Reasoning Tasks via Algebraic Objects in Neural Nets , author=. arXiv preprint arXiv:2410.01779 , year=
-
[57]
Advances in Neural Information Processing Systems , volume=
Intrinsic dimension of data representations in deep neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning , author=. Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers) , pages=
-
[59]
arXiv preprint arXiv:2605.05683 , year=
Spectral Lens: Activation and Gradient Spectra as Diagnostics of LLM Optimization , author=. arXiv preprint arXiv:2605.05683 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.