Zero-Shot 3D Question Answering via Hierarchical View-to-Token Transportation
Pith reviewed 2026-06-28 10:51 UTC · model grok-4.3
The pith
KeyVT selects task-relevant views and tokens via optimal transport to enable zero-shot 3D question answering from 2D VLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
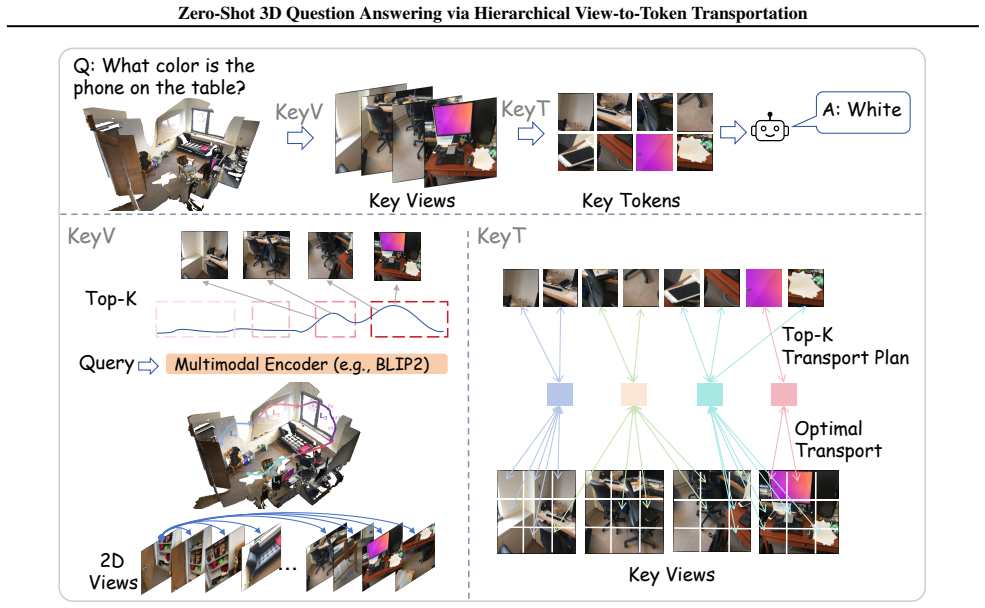
The paper claims that a hierarchical method called KeyVT produces better input context for zero-shot 3D question answering by first scoring candidate views on both semantic content and geometric position, then solving an optimal transport problem to extract a compact set of representative tokens whose distribution matches the distribution of all patches across the chosen views; this yields large gains over other tuning-free baselines and reaches accuracy levels close to methods that train on 3D data.
What carries the argument
KeyVT, the hierarchical view-to-token transportation procedure that scores views with pixel features plus camera parameters and then minimizes optimal transport distance between view-token and key-token distributions.
If this is right
- The chosen views remain spatially consistent across different questions.
- The final key tokens cover the feature distribution of the selected views with fewer total tokens.
- Zero-shot performance on three common 3D QA benchmarks rises substantially over prior tuning-free methods.
- Accuracy becomes comparable to approaches that require training on labeled 3D data.
- The same view-and-token selection can be used with any pre-trained 2D VLM without modification.
Where Pith is reading between the lines
- The same optimal-transport reduction could be applied to other 3D tasks such as captioning or visual grounding that also face token-budget limits.
- Camera parameters might prove useful for view selection in any multi-view 3D pipeline that projects to 2D images.
- The two-stage hierarchy suggests that separate selection at view and token levels can be swapped into existing 2D-to-3D pipelines without retraining the underlying VLM.
- If the transport cost is computed in a different embedding space, the method might adapt to models whose features are not aligned with the original VLM.
Load-bearing premise
That ranking views by pixel features and camera parameters produces spatially consistent, task-relevant selections, and that the tokens chosen by minimizing optimal transport distance still contain every 3D detail required to answer the question.
What would settle it
Running the method on one of the three standard benchmarks and finding that accuracy drops below existing tuning-free baselines when the optimal-transport budget is set to the same token count.
Figures





read the original abstract
Recently, zero-shot 3D scene understanding via 2D Vision-Language Models (VLMs) has gained increasing research interest due to their promising spatial reasoning capabilities. Typically, multiple 2D views are sampled from a 3D point cloud and fed into pre-trained VLMs to answer a given question. This paradigm highlights the critical role of input context quality and raises the challenge of retaining as many task-relevant 3D details as possible under a limited input budget. We propose \texttt{KeyVT}, a hierarchical approach for input context collection at both the view and token levels. Specifically, we combine pixel features with camera parameters and assess view importance based on both semantic content and geometric position, resulting in spatially consistent and task-relevant views. Furthermore, we address redundancy among patches across selected views by identifying representative tokens under the optimal transport (OT) framework, where view tokens and key tokens are formulated as two discrete distributions in the embedding space. These key tokens are expected to cover all view features by minimizing the OT distance. We evaluate our framework on three widely used benchmarks, demonstrating significant improvements over existing tuning-free methods and performance comparable to training-based approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KeyVT, a hierarchical zero-shot method for 3D question answering that first selects a subset of 2D views from a point cloud by scoring them on pixel features combined with camera parameters, then applies an optimal transport (OT) formulation to extract a compact set of representative tokens from the selected views. These tokens are fed to a pre-trained VLM to answer the query. The abstract claims that the resulting views are spatially consistent and task-relevant and that the OT step minimizes redundancy while retaining necessary 3D details, yielding significant gains over tuning-free baselines and performance comparable to training-based methods on three benchmarks.
Significance. If the view-scoring and OT token selection can be shown to produce query-appropriate inputs under a fixed token budget, the framework would provide a practical, training-free route to improve context quality for 3D VLM reasoning. The absence of any parameter fitting or self-referential evaluation is a methodological strength.
major comments (2)
- [Abstract] Abstract: the claim that the selected views are 'task-relevant' is not supported by the described procedure, which scores views using only pixel features and camera parameters; no conditioning on the question text is mentioned. Without question-specific guidance, the selected views may omit details required for the particular reasoning task, directly weakening the asserted improvements over tuning-free baselines.
- [Abstract] Abstract: the central performance claims rest on the assertion that minimizing OT distance between view tokens and key tokens 'cover[s] all view features' while retaining 'all necessary 3D details under a limited input budget,' yet no supporting derivation, ablation, or quantitative verification of information retention is supplied in the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the selected views are 'task-relevant' is not supported by the described procedure, which scores views using only pixel features and camera parameters; no conditioning on the question text is mentioned. Without question-specific guidance, the selected views may omit details required for the particular reasoning task, directly weakening the asserted improvements over tuning-free baselines.
Authors: We agree that the view selection scores views using pixel features and camera parameters without explicit conditioning on the question text. The phrase 'task-relevant' was intended to convey that semantic content from pixel features captures elements generally useful for 3D QA tasks, combined with geometric consistency. However, this wording risks implying question-specific selection. We will revise the abstract to state 'resulting in spatially consistent views with high semantic and geometric relevance' and qualify the claim accordingly. revision: yes
-
Referee: [Abstract] Abstract: the central performance claims rest on the assertion that minimizing OT distance between view tokens and key tokens 'cover[s] all view features' while retaining 'all necessary 3D details under a limited input budget,' yet no supporting derivation, ablation, or quantitative verification of information retention is supplied in the provided text.
Authors: The referee correctly notes that the abstract asserts coverage of view features and retention of 3D details via OT without a derivation, ablation, or quantitative verification in the abstract text. While the full manuscript describes the OT formulation and reports empirical improvements, we acknowledge the need for stronger support. We will add an ablation study quantifying the effect of OT token selection on feature coverage and information retention in the revised experiments section. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a proposed algorithmic method (KeyVT) for hierarchical view/token selection via pixel features, camera parameters, and OT distance minimization, followed by benchmark evaluations. No self-definitional steps, fitted parameters renamed as predictions, load-bearing self-citations, or imported uniqueness theorems appear in the provided text. The derivation chain consists of independent design choices evaluated externally and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
European Conference on Computer Vision , pages=
Instruction tuning-free visual token complement for multimodal llms , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[4]
The Tenth International Conference on Learning Representations,
Dongsheng Wang and Dandan Guo and He Zhao and Huangjie Zheng and Korawat Tanwisuth and Bo Chen and Mingyuan Zhou , title =. The Tenth International Conference on Learning Representations,
-
[5]
M. J. Kearns , title =
-
[6]
Improving Sparse Autoencoder with Dynamic Attention
Improving Sparse Autoencoder with Dynamic Attention , author=. arXiv preprint arXiv:2604.14925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[8]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[9]
Suppressed for Anonymity , author=
-
[10]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[11]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[12]
Forty-second International Conference on Machine Learning,
Fengyun Wang and Sicheng Yu and Jiawei Wu and Jinhui Tang and Hanwang Zhang and Qianru Sun , title =. Forty-second International Conference on Machine Learning,
-
[13]
Zhou Yu and Xuecheng Ouyang and Zhenwei Shao and Meng Wang and Jun Yu , title =
-
[14]
Yuanhan Zhang and Jinming Wu and Wei Li and Bo Li and Zejun Ma and Ziwei Liu and Chunyuan Li , title =. Trans. Mach. Learn. Res. , year =
-
[15]
CoRR , volume =
Shuai Bai and Yuxuan Cai and Ruizhe Chen and Keqin Chen and Xionghui Chen and Zesen Cheng and Lianghao Deng and Wei Ding and Chang Gao and Chunjiang Ge and Wenbin Ge and Zhifang Guo and Qidong Huang and Jie Huang and Fei Huang and Binyuan Hui and Shutong Jiang and Zhaohai Li and Mingsheng Li and Mei Li and Kaixin Li and Zicheng Lin and Junyang Lin and Xue...
2025
-
[16]
Chengyue Wu and Xiaokang Chen and Zhiyu Wu and Yiyang Ma and Xingchao Liu and Zizheng Pan and Wen Liu and Zhenda Xie and Xingkai Yu and Chong Ruan and Ping Luo , title =
-
[17]
Reid , title =
Jiajun Deng and Tianyu He and Li Jiang and Tianyu Wang and Feras Dayoub and Ian D. Reid , title =
-
[18]
3D-LLM: Injecting the 3D World into Large Language Models , booktitle =
Yining Hong and Haoyu Zhen and Peihao Chen and Shuhong Zheng and Yilun Du and Zhenfang Chen and Chuang Gan , editor =. 3D-LLM: Injecting the 3D World into Large Language Models , booktitle =
-
[19]
Sijin Chen and Xin Chen and Chi Zhang and Mingsheng Li and Gang Yu and Hao Fei and Hongyuan Zhu and Jiayuan Fan and Tao Chen , title =
-
[20]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
RetLLM: Training and Data-Free MLLMs for Multimodal Information Retrieval , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[21]
Advances in Neural Information Processing Systems , volume=
Chat-scene: Bridging 3d scene and large language models with object identifiers , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Goucher and Adam Perelman and Aditya Ramesh and Aidan Clark and AJ Ostrow and Akila Welihinda and Alan Hayes and Alec Radford and Aleksander Madry and Alex Baker
Aaron Hurst and Adam Lerer and Adam P. Goucher and Adam Perelman and Aditya Ramesh and Aidan Clark and AJ Ostrow and Akila Welihinda and Alan Hayes and Alec Radford and Aleksander Madry and Alex Baker. GPT-4o System Card , journal =. 2024 , eprinttype =
2024
-
[23]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Mm-spatial: Exploring 3d spatial understanding in multimodal llms , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[24]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence , author=. arXiv preprint arXiv:2505.23747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
BOLT: Boost Large Vision-Language Model Without Training for Long-form Video Understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[26]
arXiv preprint arXiv:2506.22139 (2025) 8, 9, 14
Q-Frame: Query-aware Frame Selection and Multi-Resolution Adaptation for Video-LLMs , author=. arXiv preprint arXiv:2506.22139 , year=
-
[27]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Adaptive keyframe sampling for long video understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[28]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Video-3d llm: Learning position-aware video representation for 3d scene understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[29]
arXiv preprint arXiv:2510.02262 (2025) 4
From Frames to Clips: Training-free Adaptive Key Clip Selection for Long-Form Video Understanding , author=. arXiv preprint arXiv:2510.02262 , year=
-
[30]
arXiv preprint arXiv:2511.00141 , year=
Floc: Facility location-based efficient visual token compression for long video understanding , author=. arXiv preprint arXiv:2511.00141 , year=
-
[31]
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Longvu: Spatiotemporal adaptive compression for long video-language understanding , author=. arXiv preprint arXiv:2410.17434 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Videotree: Adaptive tree-based video representation for llm reasoning on long videos , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[33]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Llava-prumerge: Adaptive token reduction for efficient large multimodal models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[34]
European Conference on Computer Vision , pages=
Text-conditioned resampler for long form video understanding , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[35]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Multi-granular spatio-temporal token merging for training-free acceleration of video llms , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[36]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Patchct: Aligning patch set and label set with conditional transport for multi-label image classification , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[37]
Advances in Neural Information Processing Systems , volume=
Tuning multi-mode token-level prompt alignment across modalities , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Computer Vision -
Runsen Xu and Xiaolong Wang and Tai Wang and Yilun Chen and Jiangmiao Pang and Dahua Lin , title =. Computer Vision -
-
[39]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[40]
Computer Vision -
Ziyu Zhu and Zhuofan Zhang and Xiaojian Ma and Xuesong Niu and Yixin Chen and Baoxiong Jia and Zhidong Deng and Siyuan Huang and Qing Li , title =. Computer Vision -
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Bridging the gap between 2d and 3d visual question answering: A fusion approach for 3d vqa , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[42]
Advances in Neural Information Processing Systems , volume=
3d-llm: Injecting the 3d world into large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,
Dejie Yang and Zhu Xu and Wentao Mo and Qingchao Chen and Siyuan Huang and Yang Liu , title =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,
-
[44]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Vision-language pre-training with object contrastive learning for 3d scene understanding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Context-aware alignment and mutual masking for 3d-language pre-training , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
3d-vista: Pre-trained transformer for 3d vision and text alignment , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[47]
arXiv preprint arXiv:2405.10370 , year=
Grounded 3d-llm with referent tokens , author=. arXiv preprint arXiv:2405.10370 , year=
-
[48]
Computer Vision -
Sha Zhang and Di Huang and Jiajun Deng and Shixiang Tang and Wanli Ouyang and Tong He and Yanyong Zhang , title =. Computer Vision -
-
[49]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
3d-llava: Towards generalist 3d lmms with omni superpoint transformer , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[50]
Advances in neural information processing systems , volume=
Sinkhorn distances: Lightspeed computation of optimal transport , author=. Advances in neural information processing systems , volume=
-
[51]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Scannet: Richly-annotated 3d reconstructions of indoor scenes , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[52]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Scannet++: A high-fidelity dataset of 3d indoor scenes , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[53]
ARKitScenes: A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data , author=. arXiv preprint arXiv:2111.08897 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Sqa3d: Sit- uated question answering in 3d scenes.arXiv preprint arXiv:2210.07474, 2022
Sqa3d: Situated question answering in 3d scenes , author=. arXiv preprint arXiv:2210.07474 , year=
-
[55]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Thinking in space: How multimodal large language models see, remember, and recall spaces , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[56]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Cider: Consensus-based image description evaluation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[57]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[58]
Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments , author=. Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
-
[59]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[60]
FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
Fastvggt: Training-free acceleration of visual geometry transformer , author=. arXiv preprint arXiv:2509.02560 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[62]
LLaVA-OneVision: Easy Visual Task Transfer
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
2008 , publisher=
Optimal transport: old and new , author=. 2008 , publisher=
2008
-
[65]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[66]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[67]
arXiv preprint arXiv:2509.16087 , year=
See&Trek: Training-Free Spatial Prompting for Multimodal Large Language Model , author=. arXiv preprint arXiv:2509.16087 , year=
-
[68]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Divprune: Diversity-based visual token pruning for large multimodal models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[69]
proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Scanqa: 3d question answering for spatial scene understanding , author=. proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[70]
Bo Li and Yuanhan Zhang and Dong Guo and Renrui Zhang and Feng Li and Hao Zhang and Kaichen Zhang and Peiyuan Zhang and Yanwei Li and Ziwei Liu and Chunyuan Li , title =. Trans. Mach. Learn. Res. , year =
-
[71]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Flexible Frame Selection for Efficient Video Reasoning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[72]
The Thirteenth International Conference on Learning Representations,
Sicheng Yu and Chengkai Jin and Huanyu Wang and Zhenghao Chen and Sheng Jin and Zhongrong Zuo and Xiaolei Xu and Zhenbang Sun and Bingni Zhang and Jiawei Wu and Hao Zhang and Qianru Sun , title =. The Thirteenth International Conference on Learning Representations,
-
[73]
CoRR , volume =
Hosu Lee and Junho Kim and Hyunjun Kim and Yong Man Ro , title =. CoRR , volume =. 2025 , url =
2025
-
[74]
Findings of the Association for Computational Linguistics,
Linli Yao and Haoning Wu and Kun Ouyang and Yuanxing Zhang and Caiming Xiong and Bei Chen and Xu Sun and Junnan Li , title =. Findings of the Association for Computational Linguistics,
-
[75]
CoRR , volume =
Sara Ghazanfari and Francesco Croce and Nicolas Flammarion and Prashanth Krishnamurthy and Farshad Khorrami and Siddharth Garg , title =. CoRR , volume =. 2025 , doi =
2025
-
[76]
arXiv preprint arXiv:2507.02001 , year=
Temporal Chain of Thought: Long-Video Understanding by Thinking in Frames , author=. arXiv preprint arXiv:2507.02001 , year=
-
[77]
arXiv preprint arXiv:2501.02885 , year=
Mdp3: A training-free approach for list-wise frame selection in video-llms , author=. arXiv preprint arXiv:2501.02885 , year=
-
[78]
Xi Tang and Jihao Qiu and Lingxi Xie and Yunjie Tian and Jianbin Jiao and Qixiang Ye , title =
-
[79]
arXiv preprint arXiv:2411.11066 , year=
TS-LLaVA: Constructing Visual Tokens through Thumbnail-and-Sampling for Training-Free Video Large Language Models , author=. arXiv preprint arXiv:2411.11066 , year=
-
[80]
arXiv preprint arXiv:2405.07798 , year=
Freeva: Offline mllm as training-free video assistant , author=. arXiv preprint arXiv:2405.07798 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.