Decoupled Smart Contract Audits: Lightweight LLM Framework via Distillation and Aggregation
Pith reviewed 2026-06-28 09:56 UTC · model grok-4.3
The pith
A four-component pipeline lets small LLMs audit smart contracts more accurately than much larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
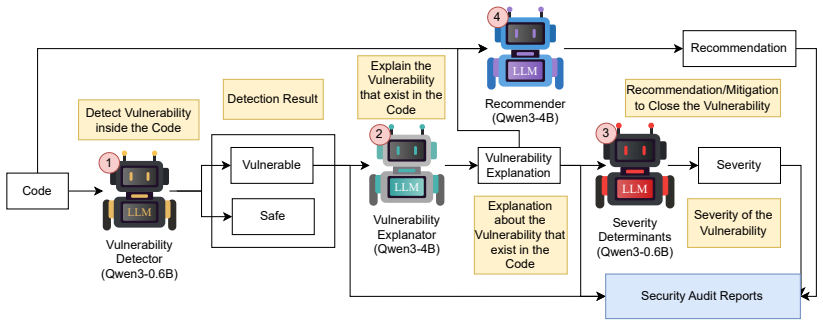
Decoupling the audit into vulnerability detection, explanation, severity classification, and remediation recommendation, supported by rsLoRA adapters, knowledge distillation, and Chain-of-Verification aggregation, enables 0.6B-4B parameter models to outperform 7B-34B parameter dense models, reaching 98.25 percent accuracy on vulnerability detection and 0.4375 alignment on generative explanations while also identifying a severity centrality bias.
What carries the argument
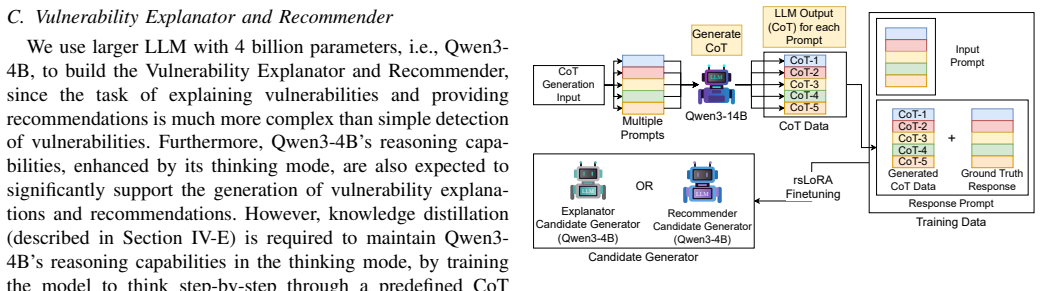
The decoupled four-component audit pipeline that uses Rank-Stabilized Low-Rank Adapters, knowledge distillation, and Chain-of-Verification aggregation to screen and combine outputs from lightweight LLMs.
If this is right
- Splitting the audit into four separate stages produces higher accuracy than asking a single model to handle the entire task in one prompt.
- The observed severity centrality bias appears only when the classification stage runs independently, suggesting unified prompts hide this pattern.
- Actionable remediation recommendations become feasible with models small enough to run on modest hardware.
- Each added component in the pipeline contributes measurably to the final report quality according to the ablation results.
Where Pith is reading between the lines
- The same decoupling pattern could be tested on other codebases such as web applications or firmware if the four-task structure transfers.
- The centrality bias in severity scoring points to a possible need for explicit diversity prompts in any multi-issue analysis task.
- Live deployment testing on active blockchains would show whether the generated remediation steps actually reduce exploit risk in practice.
Load-bearing premise
The datasets and test protocols used in the experiments represent typical real-world smart contract auditing conditions and that the larger comparison models received equivalent evaluation conditions.
What would settle it
A direct head-to-head test of the lightweight pipeline against the same 7B-34B models on a fresh collection of production smart contracts whose vulnerabilities were discovered after the training data cutoff.
Figures


read the original abstract
Smart contracts face critical security challenges that require thorough auditing in decentralized web services. While Large Language Models (LLMs) have shown promise in automated vulnerability detection, existing approaches lack severity evaluations with actionable remediation and demand unnecessarily massive computational overhead. In this study, we introduce an efficient end-to-end smart contract security audit framework utilizing lightweight, highly optimized open-source LLMs (0.6B-4B parameters). Our framework decouples comprehensive audit tasks into four interconnected components: vulnerability detection, explanation, severity classification, and remediation recommendation. To maintain high accuracy without massive parameters, we implement Rank-Stabilized Low-Rank Adapters (rsLoRA), knowledge distillation, and a custom Chain-of-Verification (CoVe) aggregation strategy to systematically screen and consolidate multiple draft responses from the model into a highly accurate audit report. Experimental results demonstrate that our lightweight pipeline consistently outperforms state-of-the-art open-source coder dense LLMs (7B to 34B parameters), achieving 98.25% accuracy in vulnerability detection and an alignment score of 0.4375 in generative explanation tasks. Furthermore, our extensive ablation studies empirically validate the superiority of our decoupled audit processes over unified prompting and uncover a novel severity centrality bias, establishing a critical benchmark for future research in LLM-assisted auditing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a decoupled four-component LLM framework (vulnerability detection, explanation, severity classification, remediation) for smart contract auditing. It employs lightweight models (0.6B–4B parameters) with rsLoRA adapters, knowledge distillation, and a custom Chain-of-Verification (CoVe) aggregation strategy, claiming 98.25% detection accuracy and 0.4375 alignment score while outperforming dense 7B–34B models; ablations are said to validate decoupling over unified prompting and reveal a severity centrality bias.
Significance. If the baseline comparisons prove equivalent and the datasets representative, the work would provide a practical, low-resource alternative for automated smart-contract auditing, with the decoupling-plus-CoVe design offering a reusable template for specialized LLM tasks. The reported ablation validation of the four-component process is a positive methodological feature.
major comments (2)
- [Experimental Results / Baselines] Experimental section (results and ablation studies): the headline claim that the 0.6B–4B pipeline “consistently outperforms” 7B–34B dense models requires explicit confirmation that the larger baselines received the identical four-task decomposition, rsLoRA, distillation, and CoVe screening. The abstract and ablation text compare only against unified prompting; if the 7B–34B models were evaluated under standard single-prompt conditions, the performance delta cannot be attributed to the lightweight optimizations alone.
- [Experimental Setup] §4 (or equivalent experimental setup): no dataset descriptions, train/test splits, vulnerability taxonomy, or statistical tests (e.g., confidence intervals, McNemar tests) are referenced, making it impossible to evaluate whether the 98.25% accuracy and 0.4375 alignment figures are load-bearing or reproducible under real-world smart-contract distributions.
minor comments (2)
- [Abstract] Abstract: the phrase “state-of-the-art open-source coder dense LLMs” should be accompanied by the exact model names and versions used for comparison.
- [Introduction / Method] Notation: “rsLoRA” and “CoVe” are introduced without an initial expansion or reference to the original papers on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our experimental comparisons and setup. These comments highlight areas where additional clarity and detail will strengthen the manuscript. We address each point below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Experimental Results / Baselines] Experimental section (results and ablation studies): the headline claim that the 0.6B–4B pipeline “consistently outperforms” 7B–34B dense models requires explicit confirmation that the larger baselines received the identical four-task decomposition, rsLoRA, distillation, and CoVe screening. The abstract and ablation text compare only against unified prompting; if the 7B–34B models were evaluated under standard single-prompt conditions, the performance delta cannot be attributed to the lightweight optimizations alone.
Authors: The referee is correct that the reported comparisons to 7B–34B models used standard unified prompting, consistent with the ablation studies that isolate the benefit of decoupling versus unified prompting. The headline claim positions our optimized lightweight pipeline against typical usage of larger dense models. To strengthen attribution of gains specifically to rsLoRA, distillation, and CoVe, we will add a new ablation applying the full four-component pipeline (with equivalent adaptations where feasible) to the larger models and report those results in the revised experimental section. revision: yes
-
Referee: [Experimental Setup] §4 (or equivalent experimental setup): no dataset descriptions, train/test splits, vulnerability taxonomy, or statistical tests (e.g., confidence intervals, McNemar tests) are referenced, making it impossible to evaluate whether the 98.25% accuracy and 0.4375 alignment figures are load-bearing or reproducible under real-world smart-contract distributions.
Authors: We agree that these details are essential for reproducibility and were inadvertently omitted from the main experimental section. The revised manuscript will incorporate explicit descriptions of the datasets and their sources, train/test split methodology, the vulnerability taxonomy (aligned with standard classifications such as SWC), and statistical validation including confidence intervals and McNemar tests to assess the reported metrics. revision: yes
Circularity Check
No significant circularity in empirical framework
full rationale
The paper presents an empirical LLM auditing pipeline with rsLoRA, distillation, and CoVe aggregation; claims rest on experimental accuracy (98.25%) and ablation comparisons to unified prompting. No equations, fitted-parameter predictions, self-definitional steps, or load-bearing self-citations appear. Central results are externally falsifiable via the reported datasets and baselines rather than reducing to inputs by construction. The skeptic concern about baseline equivalence is an experimental-validity issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey of applica- tion research based on blockchain smart contract,
S.-Y . Lin, L. Zhang, J. Li, L.-l. Ji, and Y . Sun, “A survey of applica- tion research based on blockchain smart contract,”Wireless Networks, vol. 28, no. 2, pp. 635–690, 2022
2022
-
[2]
Smart contract: Attacks and protections,
S. Sayeed, H. Marco-Gisbert, and T. Caira, “Smart contract: Attacks and protections,”Ieee Access, vol. 8, pp. 24 416–24 427, 2020
2020
-
[3]
Smart contract vulnerability analysis and security audit,
D. He, Z. Deng, Y . Zhang, S. Chan, Y . Cheng, and N. Guizani, “Smart contract vulnerability analysis and security audit,”IEEE Net- work, vol. 34, no. 5, pp. 276–282, 2020
2020
-
[4]
Do you still need a manual smart contract audit?
I. David, L. Zhou, K. Qin, D. Song, L. Cavallaro, and A. Gervais, “Do you still need a manual smart contract audit?”arXiv preprint arXiv:2306.12338, 2023
-
[5]
Gptscan: Detecting logic vulnerabilities in smart contracts by combining gpt with program analysis,
Y . Sun, D. Wu, Y . Xue, H. Liu, H. Wang, Z. Xu, X. Xie, and Y . Liu, “Gptscan: Detecting logic vulnerabilities in smart contracts by combining gpt with program analysis,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–13
2024
-
[6]
Auditgpt: Au- diting smart contracts with chatgpt,
S. Xia, S. Shao, M. He, T. Yu, L. Song, and Y . Zhang, “Auditgpt: Au- diting smart contracts with chatgpt,”arXiv preprint arXiv:2404.04306, 2024
-
[7]
Smartllmsentry: A comprehensive llm based smart contract vulnerability detection framework,
O. Zaazaa and H. El Bakkali, “Smartllmsentry: A comprehensive llm based smart contract vulnerability detection framework,”Journal of Metaverse, vol. 4, no. 2, pp. 126–137, 2024
2024
-
[8]
Llm- smartaudit: Advanced smart contract vulnerability detection,
Z. Wei, J. Sun, Z. Zhang, X. Zhang, M. Li, and Z. Hou, “Llm- smartaudit: Advanced smart contract vulnerability detection,”arXiv preprint arXiv:2410.09381, 2024
-
[9]
Smartguard: An llm- enhanced framework for smart contract vulnerability detection,
H. Ding, Y . Liu, X. Piao, H. Song, and Z. Ji, “Smartguard: An llm- enhanced framework for smart contract vulnerability detection,”Expert Systems with Applications, vol. 269, p. 126479, 2025
2025
-
[10]
Vulnhunt-gpt: a smart contract vulnerabilities detector based on openai chatgpt,
B. Boi, C. Esposito, and S. Lee, “Vulnhunt-gpt: a smart contract vulnerabilities detector based on openai chatgpt,” inProceedings of the 39th ACM/SIGAPP Symposium on Applied Computing, 2024, pp. 1517– 1524
2024
-
[11]
Large language model based smart contract auditing with llmbugscanner,
Y . Yuan, Y . Wang, Y . Xu, Z. Yahn, S. Hu, and L. Liu, “Large language model based smart contract auditing with llmbugscanner,”arXiv preprint arXiv:2512.02069, 2025
-
[12]
P. Jhandi, O. Kazi, S. Subramanian, and N. Sendas, “Small language models for efficient agentic tool calling: Outperforming large models with targeted fine-tuning,”arXiv preprint arXiv:2512.15943, 2025
-
[13]
How small language models are key to scalable agen- tic ai,
P. Belcak, “How small language models are key to scalable agen- tic ai,” https://developer.nvidia.com/blog/how-small-language-models- are-key-to-scalable-agentic-ai/, 2025, nVIDIA Technical Blog
2025
-
[14]
A large-scale collection of (non-) actionable static code analysis reports,
D. K ´osz´o, T. Aladics, R. Ferenc, and P. Heged ˝us, “A large-scale collection of (non-) actionable static code analysis reports,”Scientific Data, vol. 12, no. 1, p. 1884, 2025
2025
-
[15]
An empirical study of sup- pressed static analysis warnings,
H. Hu, Y . Wang, J. Rubin, and M. Pradel, “An empirical study of sup- pressed static analysis warnings,”Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 290–311, 2025
2025
-
[16]
L. Yu, S. Chen, H. Yuan, P. Wang, Z. Huang, J. Zhang, C. Shen, F. Zhang, L. Yang, and J. Ma, “Smart-llama: Two-stage post-training of large language models for smart contract vulnerability detection and explanation,”arXiv preprint arXiv:2411.06221, 2024
-
[17]
Leveraging fine-tuned language models for efficient and accurate smart contract auditing,
Z. Wei, J. Sun, Z. Zhang, X. Zhang, and M. Li, “Leveraging fine-tuned language models for efficient and accurate smart contract auditing,” arXiv preprint arXiv:2410.13918, 2024
-
[18]
W. Ma, D. Wu, Y . Sun, T. Wang, S. Liu, J. Zhang, Y . Xue, and Y . Liu, “Combining fine-tuning and llm-based agents for intuitive smart contract auditing with justifications,”arXiv preprint arXiv:2403.16073, 2024
-
[19]
Compare geforce graphics cards,
NVIDIA Corporation, “Compare geforce graphics cards,” https://www.nvidia.com/en-gb/geforce/graphics-cards/compare, 2025, accessed: 2025-10-04. Provides memory specs (e.g., RTX 3050 with 6 GB / 8 GB) among model comparisons
2025
-
[20]
Securing container images through automated vulnerability detection in shift-left ci/cd pipelines,
A. K. Bhardwaj, P. Dutta, and P. Chintale, “Securing container images through automated vulnerability detection in shift-left ci/cd pipelines,” Babylonian Journal of Networking, vol. 2024, pp. 162–170, 2024
2024
-
[21]
A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA
D. Kalajdzievski, “A rank stabilization scaling factor for fine-tuning with lora,”arXiv preprint arXiv:2312.03732, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Beyond answers: Transferring reasoning capabilities to smaller llms using multi- teacher knowledge distillation,
Y . Tian, Y . Han, X. Chen, W. Wang, and N. V . Chawla, “Beyond answers: Transferring reasoning capabilities to smaller llms using multi- teacher knowledge distillation,” inProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining, 2025, pp. 251–260
2025
-
[23]
C.-Y . Hsieh, C.-L. Li, C.-K. Yeh, H. Nakhost, Y . Fujii, A. Ratner, R. Kr- ishna, C.-Y . Lee, and T. Pfister, “Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes,” arXiv preprint arXiv:2305.02301, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[25]
Large lan- guage models are zero-shot reasoners,
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large lan- guage models are zero-shot reasoners,”Advances in neural information processing systems, vol. 35, pp. 22 199–22 213, 2022
2022
-
[26]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Chain-of-verification reduces hallucination in large language models,
S. Dhuliawala, M. Komeili, J. Xu, R. Raileanu, X. Li, A. Celikyilmaz, and J. Weston, “Chain-of-verification reduces hallucination in large language models,” inFindings of the association for computational linguistics: ACL 2024, 2024, pp. 3563–3578
2024
-
[28]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[29]
Code Llama: Open Foundation Models for Code
B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, R. Sauvestre, T. Remezet al., “Code llama: Open foundation models for code,”arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y . Wu, Y . Liet al., “Deepseek-coder: When the large language model meets programming–the rise of code intelligence,”arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Codestral: Hello, world!
M. A. Team, “Codestral: Hello, world!” https://mistral.ai/news/codestral/, 2024, mistral AI Technical Blog
2024
-
[32]
Codegemma: Open code models based on gemma,
C. Team and G. DeepMind, “Codegemma: Open code models based on gemma,”arXiv preprint arXiv:2406.11409, 2024
-
[33]
Qwen2.5-Coder Technical Report
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Danget al., “Qwen2.5-coder technical report,”arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Y . Sun, D. Wu, Y . Xue, H. Liu, W. Ma, L. Zhang, Y . Liu, and Y . Li, “Llm4vuln: A unified evaluation framework for decoupling and enhanc- ing llms’ vulnerability reasoning,”arXiv preprint arXiv:2401.16185, 2024
-
[35]
Decoupling task-solving and output formatting in llm generation,
H. Deng, P.-N. Kung, and N. Peng, “Decoupling task-solving and output formatting in llm generation,”arXiv preprint arXiv:2510.03595, 2025
-
[36]
Assessing small language models for code generation: An empirical study with benchmarks,
M. M. Hasan, M. Waseem, K.-K. Kemell, J. Rasku, J. Ala-Rantala, and P. Abrahamsson, “Assessing small language models for code generation: An empirical study with benchmarks,”arXiv preprint arXiv:2507.03160, 2025
-
[37]
Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl,
M. Luoet al., “Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl,” https://pretty-radio-b75.notion.site/DeepScaleR- Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL- 19681902c1468005bed8ca303013a4e2, 2025, notion Blog
2025
-
[38]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[39]
Livebench: A challenging, contamination-free LLM benchmark,
C. Whiteet al., “Livebench: A challenging, contamination-free LLM benchmark,” inThe 13th ICLR, 2025
2025
-
[40]
Holistic Evaluation of Language Models
P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y . Zhang, D. Narayanan, Y . Wu, A. Kumaret al., “Holistic evaluation of language models,”arXiv preprint arXiv:2211.09110, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging llm-as-a-judge with mt-bench and chatbot arena,”Advances in neural information processing systems, vol. 36, pp. 46 595–46 623, 2023
2023
-
[42]
RewardBench 2: Advancing Reward Model Evaluation
S. Malik, V . Pyatkin, S. Land, J. Morrison, N. A. Smith, H. Hajishirzi, and N. Lambert, “Rewardbench 2: Advancing reward model evaluation,” arXiv preprint arXiv:2506.01937, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Lmunit: Fine-grained evaluation with natural language unit tests,
J. Saad-Falcon, R. Vivek, W. Berrios, N. S. Naik, M. Franklin, B. Vid- gen, A. Singh, D. Kiela, and S. Mehri, “Lmunit: Fine-grained evaluation with natural language unit tests,”arXiv preprint arXiv:2412.13091, 2024
-
[44]
Atla selene mini: A general purpose evaluation model,
A. Alexandru, A. Calvi, H. Broomfield, J. Golden, K. Dai, M. Leys, M. Burger, M. Bartolo, R. Engeler, S. Pisupatiet al., “Atla selene mini: A general purpose evaluation model,”arXiv preprint arXiv:2501.17195, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.