ACRONYM: Accelerated Approximate Nearest Neighbor Search in Memory for Dynamic Vector Databases
Pith reviewed 2026-06-28 08:19 UTC · model grok-4.3
The pith
ACRONYM uses CAM hardware with two-stage refinement to reach over 90 percent recall at 8 million queries per second on dynamic vector databases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
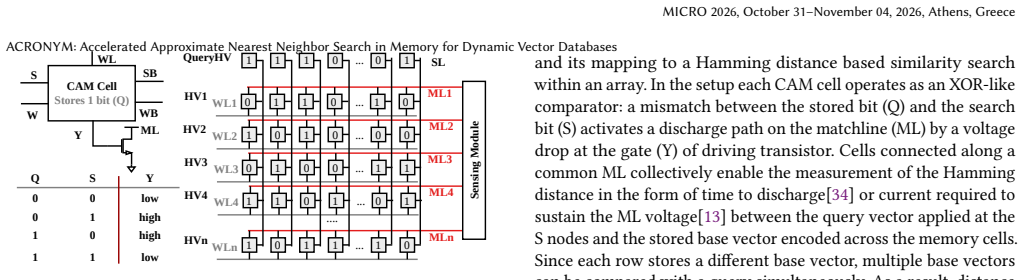
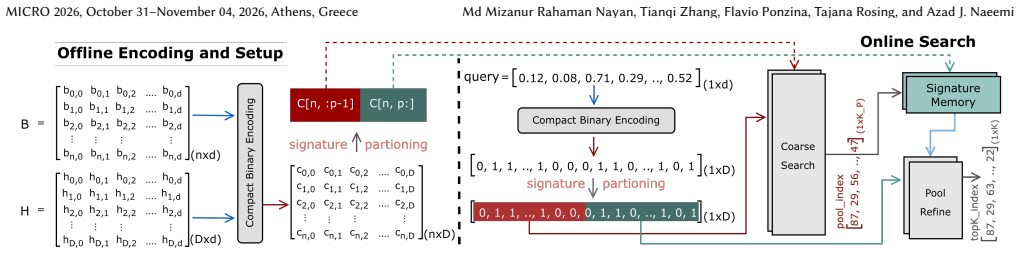
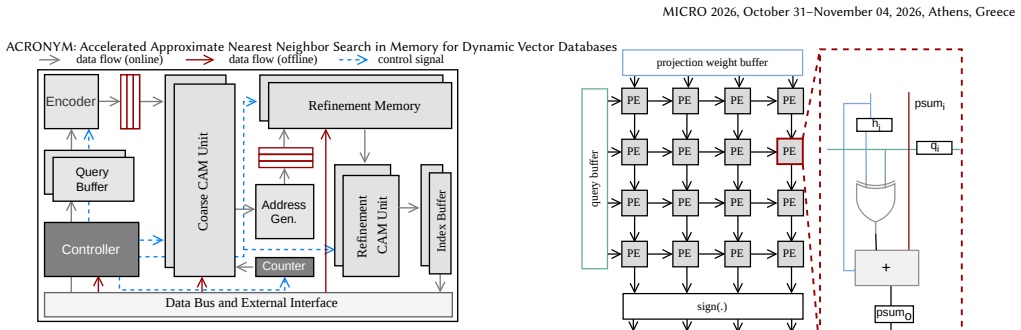
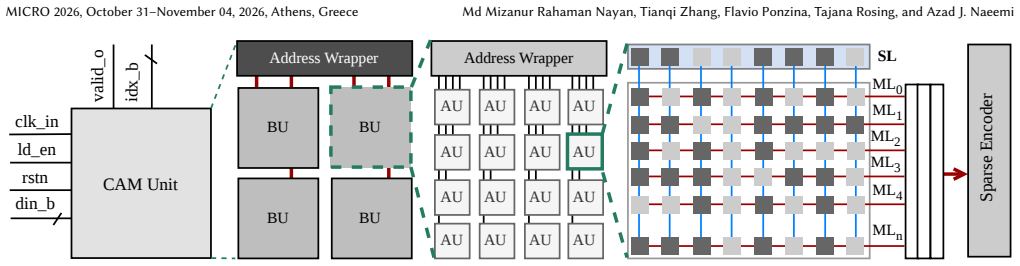
ACRONYM performs exhaustive search via CAM-based parallel distance computation and time-multiplexed top-k selection, with a two-stage coarse search plus binary refinement that overcomes CAM capacity and wordline parasitic limits on vector dimension. It integrates a systolic-array encoder for on-chip encoding during search and maintains search operation while supporting continuous database updates, achieving the stated throughput, recall, memory, energy, and speedup figures on million-scale datasets.
What carries the argument
Two-stage coarse search followed by binary refinement on CAM hardware, supported by XOR-and-Accumulate systolic-array encoder for distribution-independent encoding.
If this is right
- Dynamic vector databases can maintain continuous updates without stalling search operations or rebuilding indices.
- Memory footprint stays at 32 MB while serving million-scale datasets at the reported throughput.
- Average energy per query remains at 2.56 microjoules while delivering roughly 400x speedup over CPU graph-based methods.
- The same platform applies to retrieval-augmented generation and recommendation systems that require frequent embedding updates.
Where Pith is reading between the lines
- If the two-stage refinement works across distance metrics, similar CAM designs could extend beyond Hamming distance to other embedding spaces.
- The low memory and energy numbers suggest possible deployment on edge hardware for local vector retrieval tasks.
- Continuous-update support without rebuild latency could reduce end-to-end delay in online systems that ingest new data in real time.
Load-bearing premise
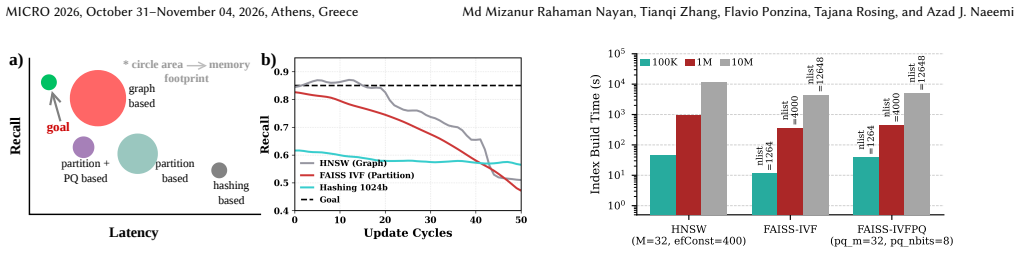
The two-stage search can deliver high recall despite the capacity and wordline parasitic limits that restrict CAM-based search to small vector dimensions.
What would settle it
Measuring recall below 90 percent or throughput below 8 million queries per second on a million-scale dynamic dataset with frequent updates, while keeping the 32 MB memory and 2.56 uJ energy figures, would falsify the central performance claims.
Figures





read the original abstract
Vector database search with frequent updates is increasingly critical in applications such as retrieval augmented generation, recommendation systems, and large-scale embedding retrieval. Existing solutions, such as graph-based and partition-based approximate nearest neighbor search (ANNS), suffer from frequent index rebuilding due to data distribution-dependent indexing that impacts continuous deployment and causes long rebuilding latency. This paper proposes an algorithm-hardware co-designed platform, ACRONYM, that addresses key problems with state of the art database search. Algorithmically, it leverages efficient encoding independent of data distribution and Hamming-distance based search for efficient hardware acceleration. Architecturally, we propose CAM-based in-memory parallel distance computation followed by time multiplexed approximated top-k selection to enable the exhaustive search. We propose two-stage search that includes coarse search followed by binary refinement to achieve high recall in CAM based search which is heavily limited to small vector dimension due to capacity and wordline parasitic. ACRONYM supports continuous update without stalling and integrates novel XOR-and-Accumulate (XAC) based systolic-array encoder for efficient on chip encoding during search. Across million-scale datasets, while serving dynamic database ACRONYM achieves >90% recall at a throughput of 8e6 queries per second, with a memory footprint of only 32MB and an average energy consumption of 2.56uJ per query, speedup over HNSW (CPU) of about 400x and FAISS-IVF (GPU) of about 80x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ACRONYM, an algorithm-hardware co-design for approximate nearest neighbor search (ANNS) in dynamic vector databases. It uses data-distribution-independent encoding and Hamming-distance search, implemented via CAM-based in-memory parallel distance computation with time-multiplexed top-k selection and a novel XOR-and-Accumulate systolic-array encoder. A two-stage search (coarse CAM search followed by binary refinement) is introduced to achieve high recall despite CAM capacity and wordline parasitic limits on vector dimension. The central claims are >90% recall at 8e6 QPS, 32 MB memory footprint, 2.56 uJ/query energy, and speedups of ~400x over HNSW (CPU) and ~80x over FAISS-IVF (GPU) on million-scale dynamic datasets, with support for continuous updates without stalling.
Significance. If the performance numbers and the effectiveness of the two-stage refinement hold under the stated CAM constraints, the work would represent a notable advance in hardware-accelerated ANNS for dynamic vector databases, addressing index-rebuild latency in graph- and partition-based methods while delivering high throughput and low energy. The integration of on-chip encoding during search and exhaustive-search acceleration via CAM are strengths that could influence future in-memory computing designs for retrieval-augmented generation and embedding search.
major comments (1)
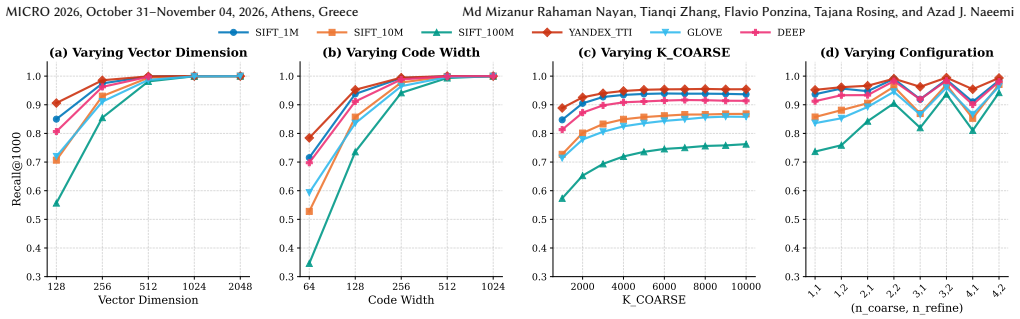
- [Abstract] Abstract: The headline claims (>90% recall, 8e6 QPS, 32 MB, 2.56 uJ/query, and the cited speedups) rest on the two-stage coarse-plus-binary-refinement search compensating for the explicitly stated CAM limitations (capacity and wordline parasitic effects restricting usable vector dimension). No code lengths, cluster counts, encoding parameters, or recall-vs-dimension curves are supplied to demonstrate that the refinement stage recovers the claimed accuracy when effective dimension remains small.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the single major comment below and will incorporate clarifications to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims (>90% recall, 8e6 QPS, 32 MB, 2.56 uJ/query, and the cited speedups) rest on the two-stage coarse-plus-binary-refinement search compensating for the explicitly stated CAM limitations (capacity and wordline parasitic effects restricting usable vector dimension). No code lengths, cluster counts, encoding parameters, or recall-vs-dimension curves are supplied to demonstrate that the refinement stage recovers the claimed accuracy when effective dimension remains small.
Authors: We acknowledge that the abstract would be strengthened by explicitly stating the key parameters supporting the two-stage search. The manuscript (Section 3.3 and 4.2) describes a 64-bit coarse code with 2048 clusters for the initial CAM search and a 256-bit binary refinement stage, with the effective dimension after encoding limited to 128 bits due to CAM wordline constraints. We will revise the abstract to include these parameters (code lengths, cluster count) and add a new figure showing recall versus effective dimension (with and without refinement) to demonstrate recovery of >90% recall. These additions will be included in the revised version. revision: yes
Circularity Check
No circularity; empirical system claims with no derivations or self-referential reductions
full rationale
The manuscript presents an algorithm-hardware co-design for dynamic vector search using CAM-based exhaustive search plus a two-stage coarse-plus-binary-refinement mechanism. No equations, parameter fits, uniqueness theorems, or derivation chains appear in the abstract or described text. Performance numbers are stated as measured outcomes on million-scale datasets rather than outputs of any mathematical reduction that could collapse to the inputs by construction. The two-stage search is introduced to mitigate explicitly stated CAM dimension limits, but this is an architectural proposal, not a self-definitional or fitted-input prediction. No self-citations are invoked as load-bearing premises. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dimitris Achlioptas. 2003. Database-friendly random projections: Johnson- Lindenstrauss with binary coins.Journal of computer and System Sciences66, 4 (2003), 671–687
2003
-
[2]
Ishaq Aden-Ali, Hakan Ferhatosmanoglu, Alexander Greaves-Tunnell, Nina Mishra, and Tal Wagner. 2025. Quantization for Vector Search under Streaming Updates.arXiv preprint arXiv:2512.18335(2025)
arXiv 2025
-
[3]
Martin Aumüller, Erik Bernhardsson, and Alexander Faithfull. 2020. ANN- Benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. Information Systems87 (2020), 101374
2020
-
[4]
Artem Babenko and Victor Lempitsky. 2016. Efficient Indexing of Billion-Scale Datasets of Deep Descriptors. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2055–2063
2016
-
[5]
Dmitry Baranchuk, Matthijs Douze, Yash Upadhyay, and I Zeki Yalniz. 2023. Dedrift: Robust similarity search under content drift. InProceedings of the IEEE/CVF International Conference on Computer Vision. 11026–11035
2023
-
[6]
Barkam, Mohsen Imani, Kai Ni, Grace Li Zhang, Bing Li, Ulf Schlichtmann, Cheng Zhuo, and Xunzhao Yin
Jiahao Cai, Hamza E. Barkam, Mohsen Imani, Kai Ni, Grace Li Zhang, Bing Li, Ulf Schlichtmann, Cheng Zhuo, and Xunzhao Yin. 2025. A Scalable 2T-1FeFET-Based Content Addressable Memory Design for Energy Efficient Data Search.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems44, 5 (2025), 1760–1773. https://doi.org/10.1109/TCAD.202...
-
[7]
Rihan Chen, Bin Liu, Han Zhu, Yaoyu Wang, Qi Li, Butui Ma, Bo Zheng, et al
-
[8]
InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD)
Approximate Nearest Neighbor Search under Neural Similarity Metric for Large-Scale Recommendation. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 3013–3022
-
[9]
Tianshi Chen, Zidong Du, Ninghui Sun, Jia Wang, Chengyong Wu, Yunji Chen, and Olivier Temam. 2014. Diannao: A small-footprint high-throughput accel- erator for ubiquitous machine-learning.ACM SIGARCH Computer Architecture News42, 1 (2014), 269–284
2014
-
[10]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2025. The faiss library.IEEE Transactions on Big Data(2025)
2025
-
[11]
Aristides Gionis, Piotr Indyk, and Rajeev Motwani. 1999. Similarity search in high dimensions via hashing. InVldb, Vol. 99. 518–529
1999
-
[12]
Wilfried Haensch, Anand Raghunathan, Kaushik Roy, Bhaswar Chakrabarti, Charudatta M Phatak, Cheng Wang, and Supratik Guha. 2023. Compute in- memory with non-volatile elements for neural networks: a review from a co- design perspective.Advanced Materials35, 37 (2023), 2204944
2023
-
[13]
Mohamed Ibrahim, Youbin Kim, and Jan M Rabaey. 2024. Efficient design of a hyperdimensional processing unit for multi-layer cognition. In2024 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 1–6
2024
-
[14]
Mohsen Imani, Abbas Rahimi, Deqian Kong, Tajana Rosing, and Jan M Rabaey
-
[15]
In2017 IEEE international symposium on high performance computer architecture (HPCA)
Exploring hyperdimensional associative memory. In2017 IEEE international symposium on high performance computer architecture (HPCA). IEEE, 445–456
-
[16]
Je-Woo Jang, Junyong Oh, Youngbae Kong, Jae-Youn Hong, Sung-Hyuk Cho, Jeongyeol Lee, Hoeseok Yang, and Joon-Sung Yang. 2025. Accelerating Retrieval Augmented Language Model via PIM and PNM Integration. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture. 246–262
2025
-
[17]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. Diskann: Fast accurate billion-point nearest neighbor search on a single node.Advances in neural information pro- cessing Systems32 (2019)
2019
-
[18]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search.IEEE transactions on pattern analysis and machine intelligence33, 1 (2010), 117–128
2010
-
[19]
Hervé Jégou, Romain Tavenard, Matthijs Douze, and Laurent Amsaleg. 2011. Searching in One Billion Vectors: Re-Rank with Source Coding. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 861–864. https://doi.org/10.1109/ICASSP.2011.5946540
-
[20]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data7, 3 (2019), 535–547
2019
-
[21]
Anirban Kar, Albi Mema, Thorgund Nemec, Stefan Dünkel, Halid Mulaosmanovic, Sven Beyer, Yogesh Singh Chauhan, and Hussam Amrouch. 2025. Ferroelectric Digital In-Memory Computing for Scalable, Reliable, and Efficient Similarity Computation.IEEE Transactions on Circuits and Systems I: Regular Papers(2025)
2025
-
[22]
Jinhyung Lee, Kyungjun Cho, Chang Kwon Lee, Yeonho Lee, Jae-Hyung Park, Su-Hyun Oh, Yucheon Ju, Chunseok Jeong, Ho Sung Cho, Jaeseung Lee, Tae- Sik Yun, Jin Hee Cho, Sangmuk Oh, Junil Moon, Young-Jun Park, Hong-Seok Choi, In-Keun Kim, Seung Min Yang, Sun-Yeol Kim, Jaemin Jang, Jinwook Kim, Seong-Hee Lee, Younghyun Jeon, Juhyung Park, Tae-Kyun Kim, Dongyoo...
-
[23]
Yejin Lee, Hyunji Choi, Sunhong Min, Hyunseung Lee, Sangwon Beak, Dawoon Jeong, Jae W Lee, and Tae Jun Ham. 2022. Anna: Specialized architecture for approximate nearest neighbor search. In2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 169–183
2022
-
[24]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[25]
Chao Li, Franz Müller, Tarek Ali, Ricardo Olivo, Mohsen Imani, Shan Deng, Cheng Zhuo, Thomas Kämpfe, Xunzhao Yin, and Kai Ni. 2020. A Scalable Design of Multi- Bit Ferroelectric Content Addressable Memory for Data-Centric Computing. In 2020 IEEE International Electron Devices Meeting (IEDM). 29.3.1–29.3.4. https: //doi.org/10.1109/IEDM13553.2020.9372119
-
[26]
Jing Li, Robert K Montoye, Masatoshi Ishii, and Leland Chang. 2013. 1 mb 0.41 𝜇m2 2t-2r cell nonvolatile tcam with two-bit encoding and clocked self-referenced sensing.IEEE Journal of Solid-State Circuits49, 4 (2013), 896–907
2013
-
[27]
Zhonggen Li, Xiangyu Ke, Yifan Zhu, Bocheng Yu, Baihua Zheng, and Yunjun Gao
-
[28]
Scalable Graph Indexing using GPUs for Approximate Nearest Neighbor Search.Proceedings of the ACM on Management of Data3, 6 (2025), 1–27
2025
-
[29]
Zhiting Lin, Zhiyong Zhu, Honglan Zhan, Chunyu Peng, Xiulong Wu, Yuan Yao, Jianchao Niu, and Junning Chen. 2021. Two-Direction In-Memory Computing Based on 10T SRAM With Horizontal and Vertical Decoupled Read Ports.IEEE Journal of Solid-State Circuits56, 9 (2021), 2832–2844. https://doi.org/10.1109/ JSSC.2021.3061260
arXiv 2021
-
[30]
Chaoqiang Liu, Dan Chen, Yu Huang, Wenjing Xiao, Haifeng Liu, Yi Zhang, Huize Li, Xiaofei Liao, and Hai Jin. 2025. SeIM: In-Memory Acceleration for Approximate Nearest Neighbor Search. In2025 62nd ACM/IEEE Design Automation Conference (DAC). IEEE, 1–7
2025
-
[31]
Che-Kai Liu, Haobang Chen, Mohsen Imani, Kai Ni, Arman Kazemi, Ann Franch- esca Laguna, Michael Niemier, Xiaobo Sharon Hu, Liang Zhao, Cheng Zhuo, et al. 2022. Cosime: Fefet based associative memory for in-memory cosine sim- ilarity search. InProceedings of the 41st IEEE/ACM International Conference on Computer-Aided Design. 1–9
2022
-
[32]
Dawei Liu, Bolong Zheng, Ziyang Yue, Fuhao Ruan, Xiaofang Zhou, and Chris- tian S Jensen. 2025. Wolverine: Highly Efficient Monotonic Search Path Repair for Graph-Based ANN Index Updates.Proceedings of the VLDB Endowment18, 7 (2025), 2268–2280
2025
-
[33]
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE transactions on pattern analysis and machine intelligence42, 4 (2018), 824–836
2018
-
[34]
Jason Mohoney, Anil Pacaci, Shihabur Rahman Chowdhury, Umar Farooq Minhas, Jeffery Pound, Cedric Renggli, Nima Reyhani, Ihab F Ilyas, Theodoros Rekatsi- nas, and Shivaram Venkataraman. 2024. Incremental ivf index maintenance for streaming vector search.arXiv preprint arXiv:2411.00970(2024)
arXiv 2024
-
[35]
Siri Narla, Ruixue Li, Piyush Kumar, Jeff J. P. M. Schulpen, Rebecca A. Dawley, Ageeth A. Bol, Steven J. Koester, and Azad Naeemi. 2026. Transition Metal Dichalcogenide Thin-Film Resistors for Content Addressable Memories With 12 ACRONYM: Accelerated Approximate Nearest Neighbor Search in Memory for Dynamic Vector Databases MICRO 2026, October 31–November...
-
[36]
Md Mizanur Rahaman Nayan, Che-Kai Liu, Zishen Wan, Arijit Raychowdhury, and Azad J Naeemi. 2025. Hydra: Sot-cam based vector symbolic macro for hyperdimensional computing. In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). IEEE, 1–9
2025
-
[37]
Chenyu Ni, Sijie Chen, Che-Kai Liu, Liu Liu, Mohsen Imani, Thomas Kämpfe, Kai Ni, Michael Niemier, Xiaobo Sharon Hu, Cheng Zhuo, et al . 2024. Tap- cam: A tunable approximate matching engine based on ferroelectric content addressable memory. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design. 1–9
2024
-
[38]
Kai Ni, Xunzhao Yin, Ann Franchesca Laguna, Siddharth Joshi, Stefan Dünkel, Martin Trentzsch, Johannes Müller, Sven Beyer, Michael Niemier, Xiaobo Sharon Hu, et al. 2019. Ferroelectric ternary content-addressable memory for one-shot learning.Nature Electronics2, 11 (2019), 521–529
2019
-
[39]
Mohammad Norouzi, Ali Punjani, and David J Fleet. 2013. Fast exact search in hamming space with multi-index hashing.IEEE transactions on pattern analysis and machine intelligence36, 6 (2013), 1107–1119
2013
-
[40]
Eng-Jon Ong and Miroslaw Bober. 2016. Improved hamming distance search using variable length substrings. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2000–2008
2016
-
[41]
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). 1532–1543
2014
-
[42]
Derrick Quinn, Mohammad Nouri, Neel Patel, John Salihu, Alireza Salemi, Sukhan Lee, Hamed Zamani, and Mohammad Alian. 2025. Accelerating retrieval- augmented generation. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume
2025
-
[43]
Kaushik Roy, Adarsh Kosta, Tanvi Sharma, Shubham Negi, Deepika Sharma, Utkarsh Saxena, Sourjya Roy, Anand Raghunathan, Zishen Wan, Samuel Spetal- nick, et al. 2025. Breaking the memory wall: next-generation artificial intelligence hardware.Frontiers in Science3 (2025), 1611658
2025
-
[44]
Aditi Singh, Suhas Jayaram Subramanya, Ravishankar Krishnaswamy, and Har- sha Vardhan Simhadri. 2021. Freshdiskann: A fast and accurate graph-based ann index for streaming similarity search.arXiv preprint arXiv:2105.09613(2021)
arXiv 2021
-
[45]
Zhong Sun, Shahar Kvatinsky, Xin Si, Adnan Mehonic, Yimao Cai, and Ru Huang
-
[46]
A full spectrum of computing-in-memory technologies.Nature Electronics 6, 11 (2023), 823–835
2023
-
[47]
Anthony Thomas, Sanjoy Dasgupta, and Tajana Rosing. 2021. A theoretical perspective on hyperdimensional computing.Journal of Artificial Intelligence Research72 (2021), 215–249
2021
-
[48]
Jingdong Wang, Ting Zhang, Nicu Sebe, Heng Tao Shen, et al. 2017. A survey on learning to hash.IEEE transactions on pattern analysis and machine intelligence 40, 4 (2017), 769–790
2017
-
[49]
Yitu Wang, Shiyu Li, Qilin Zheng, Linghao Song, Zongwang Li, Andrew Chang, Yiran Chen, et al. 2024. NDSEARCH: Accelerating graph-traversal-based approx- imate nearest neighbor search through near data processing. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 368–381
2024
-
[50]
Donna Xu, Ivor W Tsang, and Ying Zhang. 2018. Online product quantization. IEEE Transactions on Knowledge and Data Engineering30, 11 (2018), 2185–2198
2018
-
[51]
Weihong Xu, Junwei Chen, Po-kai Hsu, Jaeyoung Kang, Minxuan Zhou, Sumukh Pinge, Shimeng Yu, and Tajana Rosing. 2026. Proxima: Near-storage Acceleration for Graph-based Approximate Nearest Neighbor Search in 3D NAND.IEEE Trans. Comput.(2026), 1–13. https://doi.org/10.1109/TC.2026.3671718
-
[52]
Tomohiro Yamashita, Daichi Amagata, and Yusuke Matsui. 2025. How Should We Evaluate Data Deletion in Graph-Based ANN Indexes?arXiv preprint arXiv:2512.06200(2025)
arXiv 2025
-
[53]
Yandex Research. [n. d.]. Benchmarks for Billion-Scale Similarity Search. https: //research.yandex.com/datasets/biganns. Accessed: 2026
2026
-
[54]
2022.Semiconductor memory devices and circuits
Shimeng Yu. 2022.Semiconductor memory devices and circuits. CRC Press
2022
-
[55]
Tianyang Yu, Bi Wu, Ke Chen, Chenggang Yan, Gong Zhang, and Weiqiang Liu
-
[56]
HDANNS: In-Memory Hyperdimensional Computing for Billion-Scale Approximate Nearest Neighbour Search Acceleration.IEEE Transactions on Circuits and Systems for Artificial Intelligence(2025)
2025
-
[57]
Wei Yuan and Xi Jin. 2025. FANNS: An FPGA-Based Approximate Nearest- Neighbor Search Accelerator.IEEE Transactions on Very Large Scale Integration (VLSI) Systems(2025)
2025
-
[58]
Ziyu Zhang, Yuanhao Wei, Joshua Engels, and Julian Shun. 2025. CleANN: Efficient Full Dynamism in Graph-based Approximate Nearest Neighbor Search. arXiv preprint arXiv:2507.19802(2025)
arXiv 2025
-
[59]
Quanling Zhao, Yanru Chen, Runyang Tian, Sumukh Pinge, Weihong Xu, Au- gusto Vega, Steven Holmes, Saransh Gupta, and Tajana Rosing. 2025. HDDB: Efficient In-Storage SQL Database Search Using Hyperdimensional Computing on Ferroelectric NAND Flash.arXiv preprint arXiv:2511.18234(2025)
arXiv 2025
-
[60]
Shurui Zhong, Dingheng Mo, and Siqiang Luo. 2025. Lsm-vec: A large-scale disk-based system for dynamic vector search.arXiv preprint arXiv:2505.17152 (2025). 13
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.