Extreme Motion Generation via Hybrid Null-Space Control for Straight-Line Path Following
Pith reviewed 2026-06-28 09:32 UTC · model grok-4.3
The pith
A hybrid controller delegates long-horizon path maximization to reinforcement learning and switches to model-based control only near joint limits, extending average straight-line rollouts by 27 percent on a 7-DoF arm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
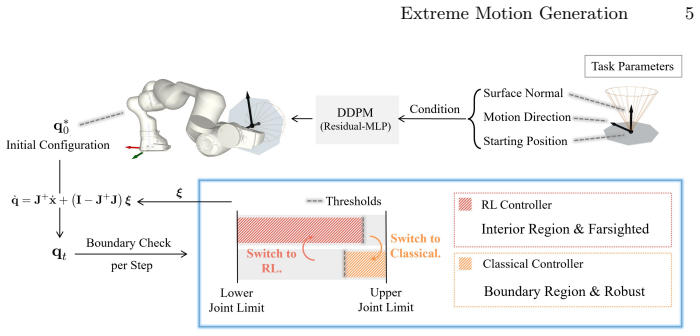
The central claim is that long-horizon decision-making for maximizing path length should be delegated to a learning-based policy to maximize exploitation of the workspace, while a classical model-based controller covers only the near-boundary region where the learning policy degrades due to sparse data coverage; the switch occurs at a normalized joint-limit distance threshold, and conditional diffusion-based sampling for the initial joint configuration further improves the achievable path length, as shown by a 27 percent extension of average rollout length over the model-based baseline across 10,000 straight-line tasks on a 7-DoF Franka FR3.
What carries the argument
step-level hybrid controller that switches between an RL-based and a model-based controller according to the normalized joint-limit distance, paired with conditional diffusion-based sampling for the initial joint configuration
If this is right
- Fixed-base manipulators gain the ability to complete longer trajectories in path-following tasks such as surface coating and welding without hardware changes.
- The hybrid split reduces the effect of data sparsity by limiting the learning policy to regions with adequate coverage.
- Conditional diffusion sampling for initial configurations increases the starting point for reaching motion extremes.
- The approach scales to large numbers of tasks, as shown by consistent gains across 10,000 evaluated straight-line instances.
Where Pith is reading between the lines
- The same switching logic could be tested on curved or surface-following trajectories to check whether the 27 percent gain holds beyond straight lines.
- Replacing the diffusion sampler with other generative models for initial configurations would isolate whether the motion prior or the sampling method drives the improvement.
- Applying the hybrid controller to robots with different degrees of freedom would reveal how dependent the gains are on the 7-DoF Franka FR3 kinematics.
Load-bearing premise
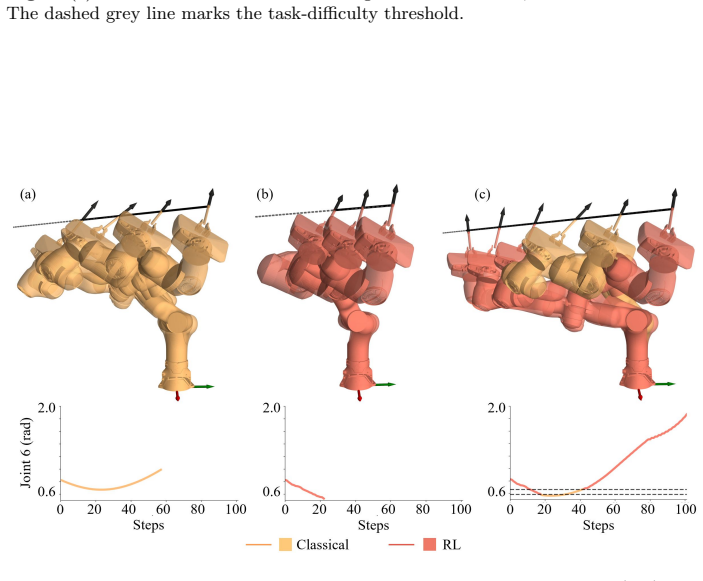
The learning-based policy degrades sharply near the safety boundary due to sparse data coverage, which justifies delegating only the near-boundary region to the model-based controller and switching at a normalized joint-limit distance threshold.
What would settle it
Running the pure RL policy without any model-based switch on the identical set of 10,000 straight-line path-following tasks and measuring whether the average rollout length equals or exceeds the reported hybrid result.
Figures

read the original abstract
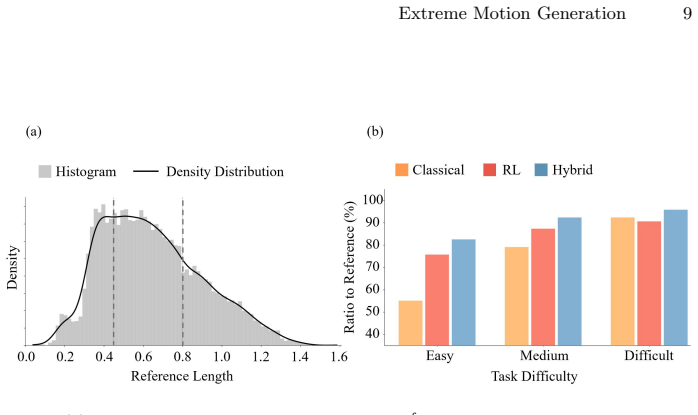
This work studies ``extreme motion generation'', which aims to maximize the Cartesian path length along a pre-defined trajectory within the manipulator's workspace. This objective is important in industry as long as path-following is fundamental to a large variety of tasks such as surface coating and welding. More critically, extreme motion enables a fixed-base manipulator to exploit the kinematic capability under limited reachability. However, such exploitation is challenging in practice, as the manipulator must actively avoid the safety boundary through execution, which is inherently a long-horizon problem. Accordingly, we claim that long-horizon decision-making should be delegated to a learning-based policy to maximize exploitation, while a classical model-based controller covers the near-boundary region, where the learning policy degrades sharply due to sparse data coverage. In detail, our proposed method is a step-level hybrid controller that switches between an RL-based and a model-based controller according to the normalized joint-limit distance. The initial joint configuration is sampled through conditional diffusion-based sampling, which improves the achievable path length based on the learned motion prior. We evaluate the proposed framework on 10,000 straight-line path-following tasks with a 7-DoF Franka FR3, extending the average rollout length by 27\% over the model-based baseline. Notably, certain tasks yield a pronounced extension toward the motion extreme, as reflected in the maximum improvement reported in the statistical results. The project website and related videos of this paper can be found at https://yuan-xinyi.github.io/extreme-motion-generation/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hybrid controller for extreme motion generation in 7-DoF manipulators performing straight-line path following. It delegates long-horizon decisions to an RL policy while switching to a model-based null-space controller near joint limits (based on normalized joint-limit distance), with initial configurations sampled via conditional diffusion. The central empirical claim is a 27% average extension in rollout length over a model-based baseline across 10,000 tasks on a Franka FR3, with some tasks showing larger gains toward motion extremes.
Significance. If the hybrid switching mechanism is shown to be the primary driver of the reported gains (rather than the diffusion initialization alone), the work would provide a practical template for combining learned long-horizon policies with classical safety layers in redundant manipulators, potentially improving exploitation of workspace limits in industrial path-following tasks.
major comments (3)
- [Evaluation] Evaluation section (results on 10,000 tasks): the 27% average improvement is reported only against a model-based baseline; no ablation is presented that applies the conditional diffusion sampling to the model-based controller alone or that compares against a pure RL policy, leaving open the possibility that gains arise from better initial configurations rather than the step-level hybrid switch.
- [Methods] Methods (hybrid controller description): the justification for delegating only the near-boundary region to the model-based controller rests on the untested claim that 'the learning policy degrades sharply due to sparse data coverage'; no rollout statistics, failure-rate curves, or direct comparison of pure RL performance inside versus outside the normalized joint-limit threshold are provided to support this assumption.
- [Evaluation] Evaluation (statistical results): while maximum improvements are noted, the paper does not report per-task variance, confidence intervals, or sensitivity of the 27% figure to the choice of switching threshold, which is required to establish that the hybrid design is robustly responsible for the claimed extension.
minor comments (2)
- [Abstract] The abstract and introduction use 'extreme motion generation' without a precise mathematical definition (e.g., as an optimization objective over path length subject to joint limits); a formal problem statement would clarify the objective.
- [Methods] Figure captions and text refer to 'normalized joint-limit distance' without an explicit equation; adding the formula (e.g., min distance to limits scaled by range) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation and methods. The comments correctly identify areas where additional analysis would strengthen the claims regarding the hybrid controller's contributions. We address each major comment below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (results on 10,000 tasks): the 27% average improvement is reported only against a model-based baseline; no ablation is presented that applies the conditional diffusion sampling to the model-based controller alone or that compares against a pure RL policy, leaving open the possibility that gains arise from better initial configurations rather than the step-level hybrid switch.
Authors: We agree that the current comparison leaves open whether the gains stem primarily from the diffusion-based initialization or the hybrid switching. To isolate the contribution of the step-level hybrid mechanism, we will add ablations that apply conditional diffusion sampling to the model-based controller alone and that evaluate a pure RL policy without the model-based component. These results will be incorporated into the revised evaluation section. revision: yes
-
Referee: [Methods] Methods (hybrid controller description): the justification for delegating only the near-boundary region to the model-based controller rests on the untested claim that 'the learning policy degrades sharply due to sparse data coverage'; no rollout statistics, failure-rate curves, or direct comparison of pure RL performance inside versus outside the normalized joint-limit threshold are provided to support this assumption.
Authors: The design choice is motivated by observed instability of the RL policy near joint limits during development, but we acknowledge that this rests on an untested assumption without supporting statistics. We will add rollout statistics, failure-rate curves, and direct comparisons of pure RL performance inside versus outside the normalized joint-limit threshold to the methods section in the revision. revision: yes
-
Referee: [Evaluation] Evaluation (statistical results): while maximum improvements are noted, the paper does not report per-task variance, confidence intervals, or sensitivity of the 27% figure to the choice of switching threshold, which is required to establish that the hybrid design is robustly responsible for the claimed extension.
Authors: We agree that variance, confidence intervals, and sensitivity to the switching threshold are needed to substantiate robustness of the hybrid design. We will include per-task variance, confidence intervals around the 27% figure, and a sensitivity analysis with respect to the switching threshold in the revised statistical results. revision: yes
Circularity Check
No circularity: empirical performance comparison on held-out tasks
full rationale
The paper presents a hybrid RL/model-based controller for extreme motion generation and reports an empirical 27% extension in average rollout length over a model-based baseline across 10,000 held-out straight-line tasks. No mathematical derivation chain, equations, or fitted parameters are shown that reduce by construction to the paper's own inputs. The central performance claim rests on external evaluation rather than self-definition, self-citation load-bearing, or renaming of known results. The assumption about RL degradation near boundaries is stated but not derived from prior equations within the paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Manipulability and redundancy control of robotic mechanisms
Tsuneo Yoshikawa. Manipulability and redundancy control of robotic mechanisms. InProceedings. 1985 IEEE International Conference on Robotics and Automation, volume 2, pages 1004–1009. IEEE, 1985
1985
-
[2]
Manipulability optimization of redundant manipulators using dynamic neural networks.IEEE Transactions on Industrial Electronics, 64(6):4710–4720, 2017
Long Jin, Shuai Li, Hung Manh La, and Xin Luo. Manipulability optimization of redundant manipulators using dynamic neural networks.IEEE Transactions on Industrial Electronics, 64(6):4710–4720, 2017
2017
-
[3]
Adaptive manipulability-based path planning strategy for industrial robot manipulators
Henghua Shen, Wen-Fang Xie, Jianyu Tang, and Tao Zhou. Adaptive manipulability-based path planning strategy for industrial robot manipulators. IEEE/ASME transactions on mechatronics, 28(3):1742–1753, 2023
2023
-
[4]
Just-in-time in- formed trees: Manipulability-aware asymptotically optimized motion planning
Kuanqi Cai, Liding Zhang, Xinwen Su, Kejia Chen, Chaoqun Wang, Sami Haddadin, Alois Knoll, Arash Ajoudani, and Luis Figueredo. Just-in-time in- formed trees: Manipulability-aware asymptotically optimized motion planning. IEEE/ASME Transactions on Mechatronics, 2025. Extreme Motion Generation 15
2025
-
[5]
On the place- ment of open-loop robotic manipulators for reachability.Mechanism and Machine Theory, 44(4):671–684, 2009
Jingzhou James Yang, Wei Yu, Joo Kim, and Karim Abdel-Malek. On the place- ment of open-loop robotic manipulators for reachability.Mechanism and Machine Theory, 44(4):671–684, 2009
2009
-
[6]
Reuleaux: robot base placement by reachabil- ity analysis
Abhijit Makhal and Alex K Goins. Reuleaux: robot base placement by reachabil- ity analysis. In2018 second IEEE international conference on robotic computing (IRC), pages 137–142. IEEE, 2018
2018
-
[7]
Predictive reachability for embod- iment selection in mobile manipulation behaviors.IEEE Robotics and Automation Letters, 10(3):2966–2973, 2025
Xiaoxu Feng, Takato Horii, and Takayuki Nagai. Predictive reachability for embod- iment selection in mobile manipulation behaviors.IEEE Robotics and Automation Letters, 10(3):2966–2973, 2025
2025
-
[8]
Robot learning of mobile manipulation with reachability behavior priors.IEEE Robotics and Automation Letters, 7(3):8399–8406, 2022
Snehal Jauhri, Jan Peters, and Georgia Chalvatzaki. Robot learning of mobile manipulation with reachability behavior priors.IEEE Robotics and Automation Letters, 7(3):8399–8406, 2022
2022
-
[9]
Safe reinforcement learning using black-box reachability anal- ysis.IEEE Robotics and Automation Letters, 7(4):10665–10672, 2022
Mahmoud Selim, Amr Alanwar, Shreyas Kousik, Grace Gao, Marco Pavone, and Karl H Johansson. Safe reinforcement learning using black-box reachability anal- ysis.IEEE Robotics and Automation Letters, 7(4):10665–10672, 2022
2022
-
[10]
A deep reinforcement-learning approach for inverse kinematics solution of a high degree of freedom robotic manipulator.Robotics, 11(2):44, 2022
Aryslan Malik, Yevgeniy Lischuk, Troy Henderson, and Richard Prazenica. A deep reinforcement-learning approach for inverse kinematics solution of a high degree of freedom robotic manipulator.Robotics, 11(2):44, 2022
2022
-
[11]
Ikflow: Generating diverse inverse kinematics solutions.IEEE Robotics and Automation Letters, 7(3):7177– 7184, 2022
Barrett Ames, Jeremy Morgan, and George Konidaris. Ikflow: Generating diverse inverse kinematics solutions.IEEE Robotics and Automation Letters, 7(3):7177– 7184, 2022
2022
-
[12]
Zeyu Zhang and Ziyuan Jiao. Ikdiffuser: a diffusion-based generative inverse kine- matics solver for kinematic trees.arXiv preprint arXiv:2506.13087, 2025
-
[13]
Diffusionseeder: Seeding motion optimiza- tion with diffusion for rapid motion planning
Huang Huang, Balakumar Sundaralingam, Arsalan Mousavian, Adithyavairavan Murali, Ken Goldberg, and Dieter Fox. Diffusionseeder: Seeding motion optimiza- tion with diffusion for rapid motion planning. In8th Annual Conference on Robot Learning, 2024
2024
-
[14]
Learning- based initialization of trajectory optimization for path-following problems of re- dundant manipulators
Minsung Yoon, Mincheul Kang, Daehyung Park, and Sung-Eui Yoon. Learning- based initialization of trajectory optimization for path-following problems of re- dundant manipulators. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9686–9692. IEEE, 2023
2023
-
[15]
Resid- ual reinforcement learning for robot control
Tobias Johannink, Shikhar Bahl, Ashvin Nair, Jianlan Luo, Avinash Kumar, Matthias Loskyll, Juan Aparicio Ojea, Eugen Solowjow, and Sergey Levine. Resid- ual reinforcement learning for robot control. In2019 international conference on robotics and automation (ICRA), pages 6023–6029. IEEE, 2019
2019
-
[16]
Tom Silver, Kelsey Allen, Josh Tenenbaum, and Leslie Kaelbling. Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
The black-box simplex architecture for runtime assurance of autonomous cps
Usama Mehmood, Sanaz Sheikhi, Stanley Bak, Scott A Smolka, and Scott D Stoller. The black-box simplex architecture for runtime assurance of autonomous cps. InNASA formal methods symposium, pages 231–250. Springer, 2022
2022
-
[18]
Safe reinforcement learning via shielding
Mohammed Alshiekh, Roderick Bloem, R¨ udiger Ehlers, Bettina K¨ onighofer, Scott Niekum, and Ufuk Topcu. Safe reinforcement learning via shielding. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[19]
Control barrier functions for sin- gularity avoidance in passivity-based manipulator control
Vince Kurtz, Patrick M Wensing, and Hai Lin. Control barrier functions for sin- gularity avoidance in passivity-based manipulator control. In2021 60th IEEE Conference on Decision and Control (CDC), pages 6125–6130. IEEE, 2021
2021
-
[20]
Iksel: Selecting good seed joint values for fast numerical inverse kinematics iterations.IEEE Transactions on Automation Science and Engineering, 2026
Xinyi Yuan, Weiwei Wan, and Kensuke Harada. Iksel: Selecting good seed joint values for fast numerical inverse kinematics iterations.IEEE Transactions on Automation Science and Engineering, 2026
2026
-
[21]
Denoising diffusion probabilistic mod- els.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic mod- els.Advances in neural information processing systems, 33:6840–6851, 2020. 16 Yuan et al
2020
-
[22]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.