PRISM: Synergizing Vision Foundation Models via Self-organized Expert Specialization
Pith reviewed 2026-06-28 10:44 UTC · model grok-4.3
The pith
A dual-stream MoE lets vision foundation model experts specialize in separate subspaces then recombine for task-specific pathways.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
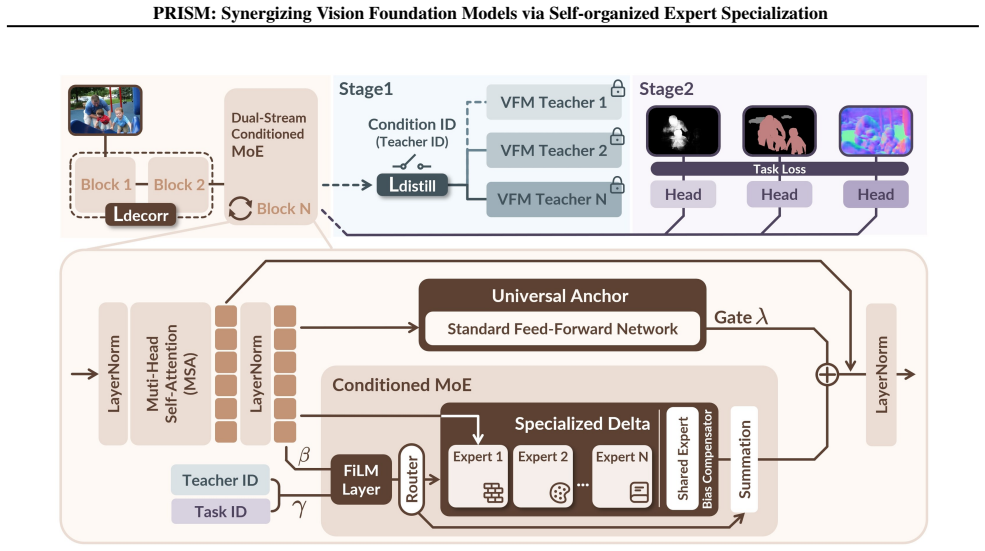
PRISM is a dual-stream Mixture-of-Experts framework that first uses a teacher-conditional router to deconstruct expertise into specialized subspaces and then uses the same router to dynamically recompose those experts into tailored pathways, establishing new state-of-the-art results on PASCAL-Context and NYUD-v2 and thereby showing that sparse emergent specialization can integrate diverse visual knowledge at scale.
What carries the argument
Dual-stream Mixture-of-Experts framework whose teacher-conditional router guides initial subspace specialization and later assembles task-specific expert pathways.
If this is right
- Multiple vision foundation models can be fused without negative transfer by letting experts occupy separate representational areas.
- A single router can handle both the specialization phase and the later task-specific assembly phase.
- Sparse activation during inference becomes feasible once experts have specialized.
- The approach scales with the number of source models because specialization prevents interference.
Where Pith is reading between the lines
- The same router-driven specialization pattern could be tested on video or 3D tasks where temporal or geometric consistency might emerge automatically.
- If the subspaces remain distinct across different downstream datasets, the method could reduce the need for full model retraining when adding new tasks.
- Measuring the degree of subspace separation directly might reveal whether the router is truly discovering natural divisions in visual features or simply enforcing artificial ones.
Load-bearing premise
The router can drive experts into non-interfering subspaces and then learn reliable ways to combine them for downstream tasks.
What would settle it
Running PRISM on PASCAL-Context and NYUD-v2 and finding that its performance does not exceed prior single-model or distillation baselines, or that expert activation patterns show no measurable separation in the subspaces they cover.
Figures
read the original abstract
Unifying the complementary strengths of diverse Vision Foundation Models (VFMs) into a single efficient model is highly desirable but challenged by the negative transfer inherent in monolithic distillation. To address these feature conflicts, we introduce \textbf{PRISM}, a novel dual-stream Mixture-of-Experts (MoE) framework that synergizes VFMs via modular specialization. We propose a two-stage paradigm: (1) expertise deconstruction, where a teacher-conditional router guides experts to specialize in distinct representational subspaces to mitigate interference, followed by (2) dynamic recomposition, where the router learns to assemble these experts into tailored computational pathways for downstream tasks. Experiments on PASCAL-Context and NYUD-v2 show that \textbf{PRISM} establishes a new state of the art, validating that sparse, emergent specialization is a scalable approach for integrating diverse visual knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PRISM, a dual-stream Mixture-of-Experts (MoE) framework for unifying complementary strengths of diverse Vision Foundation Models while mitigating negative transfer. It proposes a two-stage paradigm of expertise deconstruction, in which a teacher-conditional router guides experts toward distinct representational subspaces, followed by dynamic recomposition in which the router assembles experts into task-specific pathways. Experiments are reported to establish new state-of-the-art results on PASCAL-Context and NYUD-v2, thereby validating sparse, emergent specialization as a scalable integration strategy.
Significance. If the reported gains are reproducible and the specialization mechanism is shown to operate without explicit teacher-directed subspace assignment, the work would offer a concrete route to modular, sparse combination of multiple VFMs that avoids the interference typical of monolithic distillation. This would be of interest to the community working on multi-model fusion and efficient deployment of foundation models in vision.
major comments (1)
- [Abstract] Abstract: the claim that the PASCAL-Context and NYUD-v2 results validate 'sparse, emergent specialization' rests on the two-stage paradigm, yet the expertise-deconstruction stage explicitly employs a 'teacher-conditional router' to force experts into distinct subspaces. This conditioning appears to make specialization teacher-directed rather than self-organized or emergent, which directly affects whether the SOTA numbers can be interpreted as evidence for the title's central thesis.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying an important point of potential ambiguity in how the abstract characterizes the specialization mechanism. We address the comment directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the PASCAL-Context and NYUD-v2 results validate 'sparse, emergent specialization' rests on the two-stage paradigm, yet the expertise-deconstruction stage explicitly employs a 'teacher-conditional router' to force experts into distinct subspaces. This conditioning appears to make specialization teacher-directed rather than self-organized or emergent, which directly affects whether the SOTA numbers can be interpreted as evidence for the title's central thesis.
Authors: We agree that the current abstract wording risks overstating the purely emergent character of the deconstruction stage. The teacher-conditional router does supply a signal that encourages distinct representational subspaces, which is a form of guidance rather than fully unsupervised emergence. At the same time, the router does not receive explicit per-expert subspace labels; the particular partitioning that arises is discovered by the model itself. The subsequent recomposition stage is fully dynamic and task-driven with no teacher conditioning. We will therefore revise the abstract to replace the phrase 'sparse, emergent specialization' with 'sparse, guided-then-dynamic specialization' and to clarify the two-stage distinction. This change preserves the empirical claims while aligning the language more precisely with the method. revision: yes
Circularity Check
No circularity; empirical claims rest on benchmark results without self-referential derivations
full rationale
The paper introduces a two-stage MoE method with a teacher-conditional router for specialization and reports SOTA results on PASCAL-Context and NYUD-v2 to support the claim of scalable sparse emergent specialization. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim is an empirical validation rather than a mathematical reduction to inputs by construction. The terminology mismatch between 'self-organized'/'emergent' and the teacher-conditional router is an interpretive or correctness concern, not a circularity in any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Net2Net: Accelerating Learning via Knowledge Transfer
Chen, T., Goodfellow, I., and Shlens, J. Net2net: Accel- erating learning via knowledge transfer.arXiv preprint arXiv:1511.05641,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Just pick a sign: Opti- mizing deep multitask models with gradient sign dropout
Chen, Z., Ngiam, J., Huang, Y ., Luong, T., Kretzschmar, H., Chai, Y ., and Anguelov, D. Just pick a sign: Opti- mizing deep multitask models with gradient sign dropout. Advances in Neural Information Processing Systems, 33: 2039–2050,
2039
-
[3]
org/papers/v23/21-0998.html
URL https://jmlr. org/papers/v23/21-0998.html. Fukuda, T., Suzuki, M., Kurata, G., Thomas, S., Cui, J., and Ramabhadran, B. Efficient knowledge distillation from an ensemble of teachers. InInterspeech 2017, pp. 3697–3701,
2017
-
[4]
Guo, M., Haque, A., Huang, D.-A., Yeung, S., and Fei-Fei, L
doi: 10.21437/Interspeech.2017-614. Guo, M., Haque, A., Huang, D.-A., Yeung, S., and Fei-Fei, L. Dynamic task prioritization for multitask learning. In Proceedings of the European conference on computer vision (ECCV), pp. 270–287,
-
[5]
Crafting papers on machine learning
Langley, P. Crafting papers on machine learning. In Langley, P. (ed.),Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp. 1207–1216, Stan- ford, CA,
2000
-
[6]
LoRA-Mixer: Coordinate Modular LoRA Experts Through Serial Attention Routing
Morgan Kaufmann. 10 PRISM: Synergizing Vision Foundation Models via Self-organized Expert Specialization Li, W., Zhou, H., Yu, J., Song, Z., and Yang, W. Coupled mamba: Enhanced multimodal fusion with coupled state space model.Advances in Neural Information Processing Systems, 37:59808–59832, 2024a. Li, W., Song, Z., Zhou, H., Zhang, Y ., Yu, J., and Yang...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Lu, Y ., Cao, S., and Wang, Y .-X
doi: 10.1016/j.neucom.2020.07.048. Lu, Y ., Cao, S., and Wang, Y .-X. Swiss army knife: Syner- gizing biases in knowledge from vision foundation mod- els for multi-task learning. InThe Thirteenth Interna- tional Conference on Learning Representations,
-
[8]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., V o, H., Szafraniec, M., Khalidov, V ., Fernandez, P., Haziza, D., Massa, F., El- Nouby, A., et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Ranzinger, M., Barker, J., Heinrich, G., Molchanov, P., Catanzaro, B., and Tao, A. Phi-s: Distribution balancing for label-free multi-teacher distillation.arXiv preprint arXiv:2410.01680, 2024a. Ranzinger, M., Heinrich, G., Kautz, J., and Molchanov, P. Am-radio: Agglomerative vision foundation model reduce all domains into one. InProceedings of the IEEE/C...
-
[10]
B., Weinzaepfel, P., Lucas, T., Larlus, D., and Kalantidis, Y
Sariyildiz, M. B., Weinzaepfel, P., Lucas, T., Larlus, D., and Kalantidis, Y . Unic: Universal classification models via multi-teacher distillation.arXiv preprint arXiv:2408.05088,
-
[11]
arXiv preprint arXiv:2407.20179 , year=
Shang, J., Schmeckpeper, K., May, B. B., Minniti, M. V ., Kelestemur, T., Watkins, D., and Herlant, L. Theia: Dis- tilling diverse vision foundation models for robot learning. arXiv preprint arXiv:2407.20179,
-
[12]
URL https://openreview.net/forum? id=B1ckMDqlg. Shi, M., Liu, F., Wang, S., Liao, S., Radhakrishnan, S., Zhao, Y ., Huang, D.-A., Yin, H., Sapra, K., Yacoob, Y ., et al. Ea- gle: Exploring the design space for multimodal llms with mixture of encoders.arXiv preprint arXiv:2408.15998,
-
[13]
P., and Yang, W
Song, Z., Tang, Y ., Luo, R., Ma, L., Yu, J., Chen, Y .-P. P., and Yang, W. Autogenic language embedding for co- herent point tracking. InProceedings of the 32nd ACM International Conference on Multimedia, pp. 2021–2030,
2021
-
[14]
Seeing Further and Wider: Joint Spatio-Temporal Enlargement for Micro-Video Popularity Prediction
Wang, D., Zhang, Y ., Yu, J., Chen, Y .-P. P., Xu, C., and Song, Z. Seeing further and wider: Joint spatio-temporal enlargement for micro-video popularity prediction.arXiv preprint arXiv:2604.20311,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Wang, H., Vasu, P. K. A., Faghri, F., Vemulapalli, R., Fara- jtabar, M., Mehta, S., Rastegari, M., Tuzel, O., and Pouransari, H. Sam-clip: Merging vision foundation models towards semantic and spatial understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3635–3647, 2024a. Wang, S., Li, J., Zhao, Z., Lian,...
-
[16]
P., Yu, J., Yang, W., and Song, Z
Ye, L., Zhang, Y ., Wu, Y ., Chen, Y .-P. P., Yu, J., Yang, W., and Song, Z. Mvp: Winning solution to smp chal- lenge 2025 video track.arXiv preprint arXiv:2507.00950,
-
[17]
doi: 10.1145/3097983.3098135. Yu, J., Dai, Y ., Liu, X., Huang, J., Shen, Y ., Zhang, K., Zhou, R., Adhikarla, E., Ye, W., Liu, Y ., et al. Unleashing the power of multi-task learning: A comprehensive sur- vey spanning traditional, deep, and pretrained foundation model eras.arXiv preprint arXiv:2404.18961,
-
[18]
CurEvo: Curriculum-Guided Self-Evolution for Video Understanding
Zeng, G., Yu, J., Chen, Y .-P. P., Chen, X., Yang, W., and Song, Z. Curevo: Curriculum-guided self-evolution for video understanding.arXiv preprint arXiv:2604.26707,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
doi: 10.1609/aaai.v38i15.29622. Zhang, Y . and Yang, Q. A survey on multi-task learning. IEEE transactions on knowledge and data engineering, 34(12):5586–5609,
-
[20]
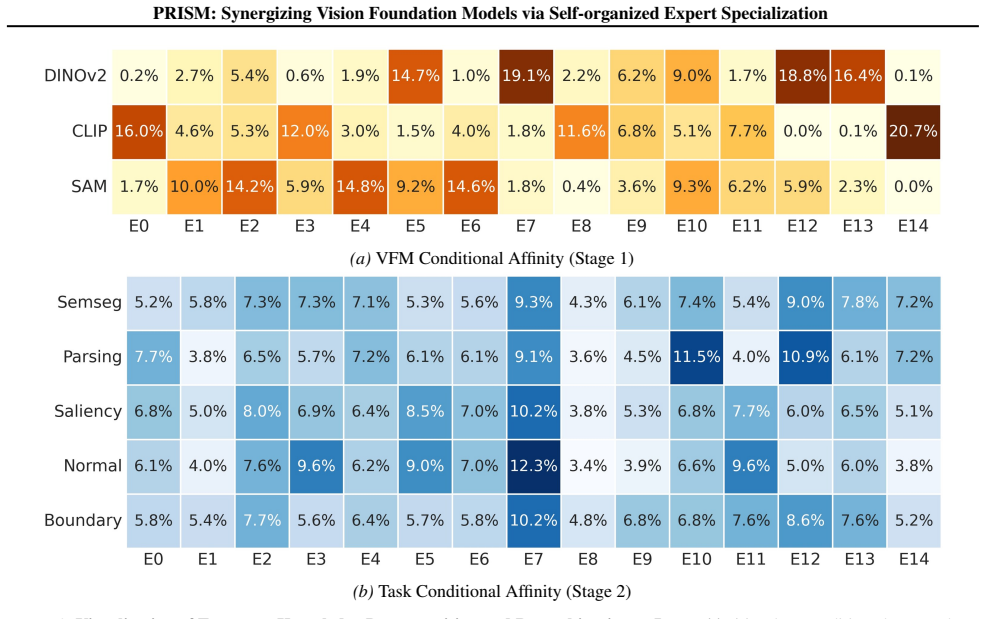
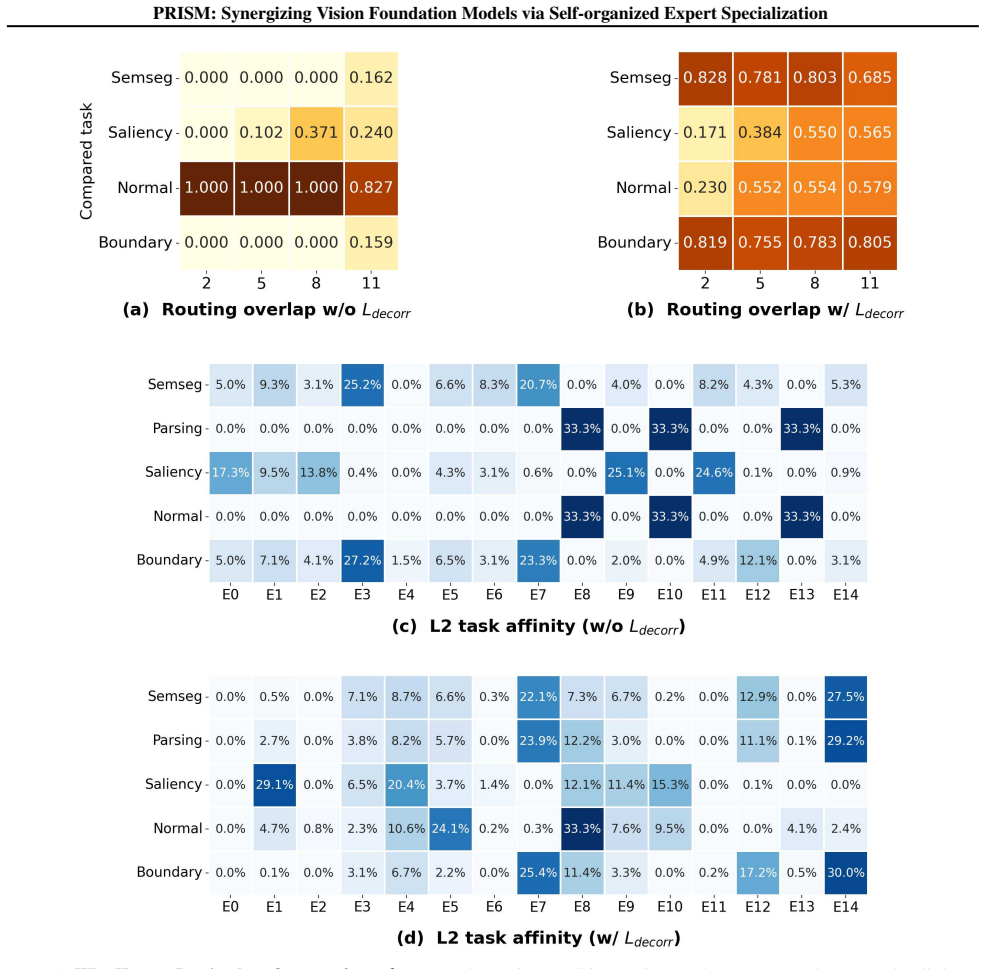
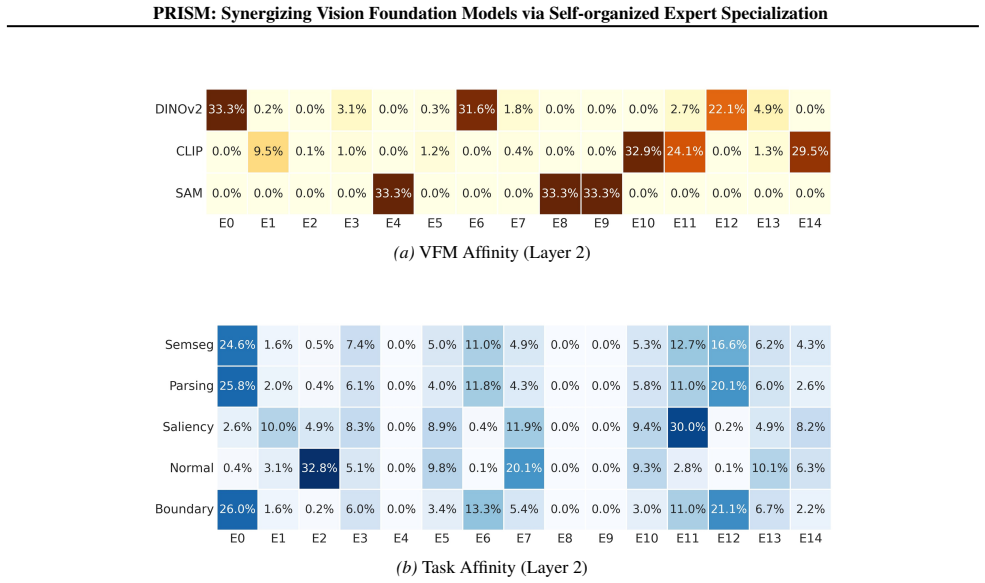
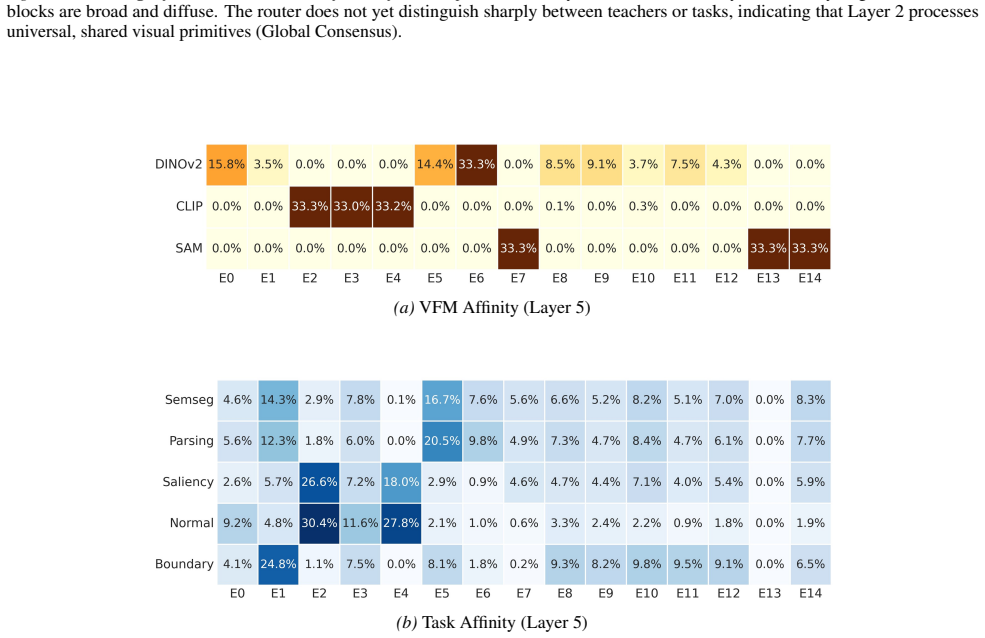
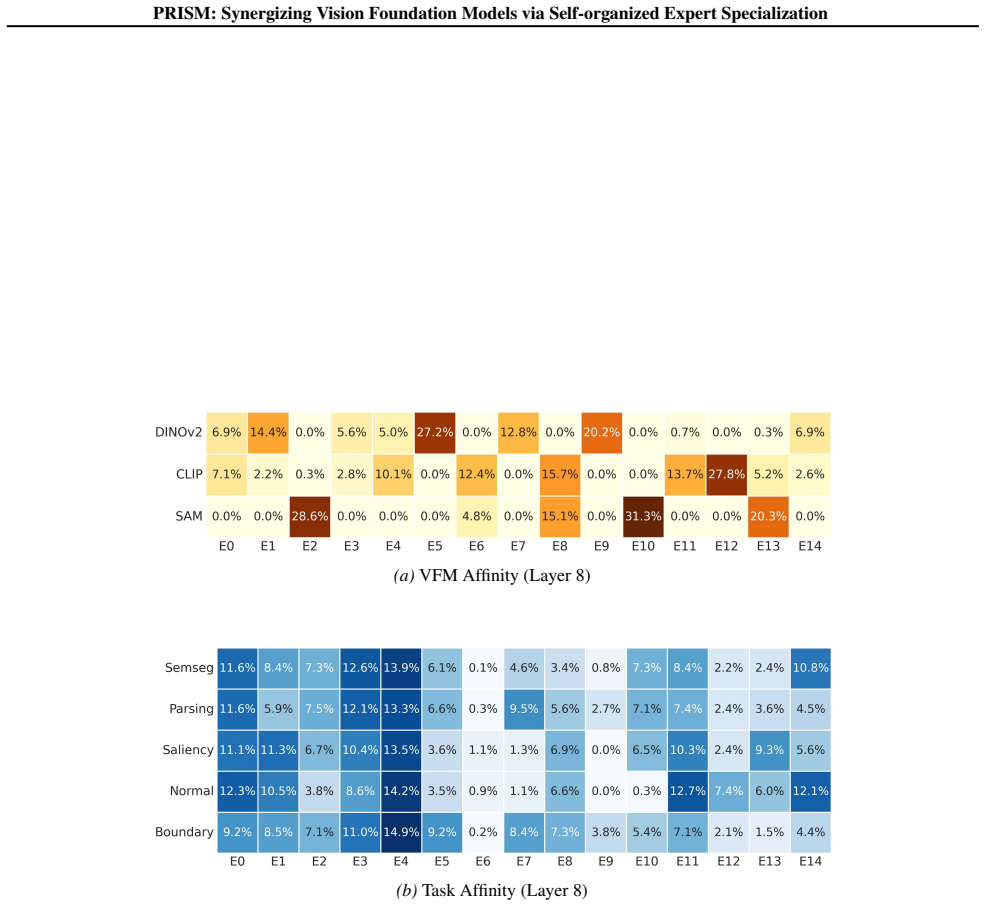
(c,d) Layer-2 task affinity, i.e., expert usage distribution
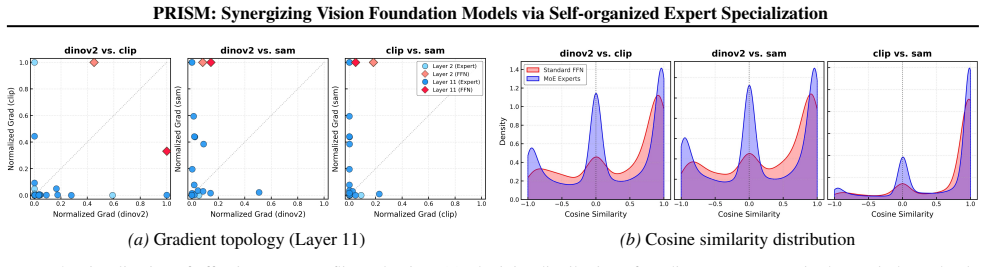
With Ldecorr, this pattern changes substantially: Parsing–Normal overlap decreases, while overlap with SemSeg and Boundary increases markedly. (c,d) Layer-2 task affinity, i.e., expert usage distribution. Without Ldecorr, Parsing and Normal concentrate on nearly the same sparse experts; with Ldecorr, Parsing redistributes toward experts that are also used...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.