Recognition: unknown
Seeing Further and Wider: Joint Spatio-Temporal Enlargement for Micro-Video Popularity Prediction
Pith reviewed 2026-05-09 23:09 UTC · model grok-4.3
The pith
A unified framework for joint spatio-temporal enlargement lets micro-video popularity models perceive longer sequences and draw from more historical videos without growing storage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that temporal enlargement via a frame scoring module (which extracts highlight cues through sparse sampling and dense perception pathways and fuses them adaptively) combined with spatial enlargement via a topology-aware memory bank (which hierarchically clusters historical content and updates encoder features rather than expanding storage) produces precise long-sequence understanding and scalable knowledge utilization, directly improving popularity prediction.
What carries the argument
The joint spatio-temporal enlargement formed by the frame scoring module for adaptive long-sequence fusion and the topology-aware memory bank for hierarchical clustering and feature updates.
If this is right
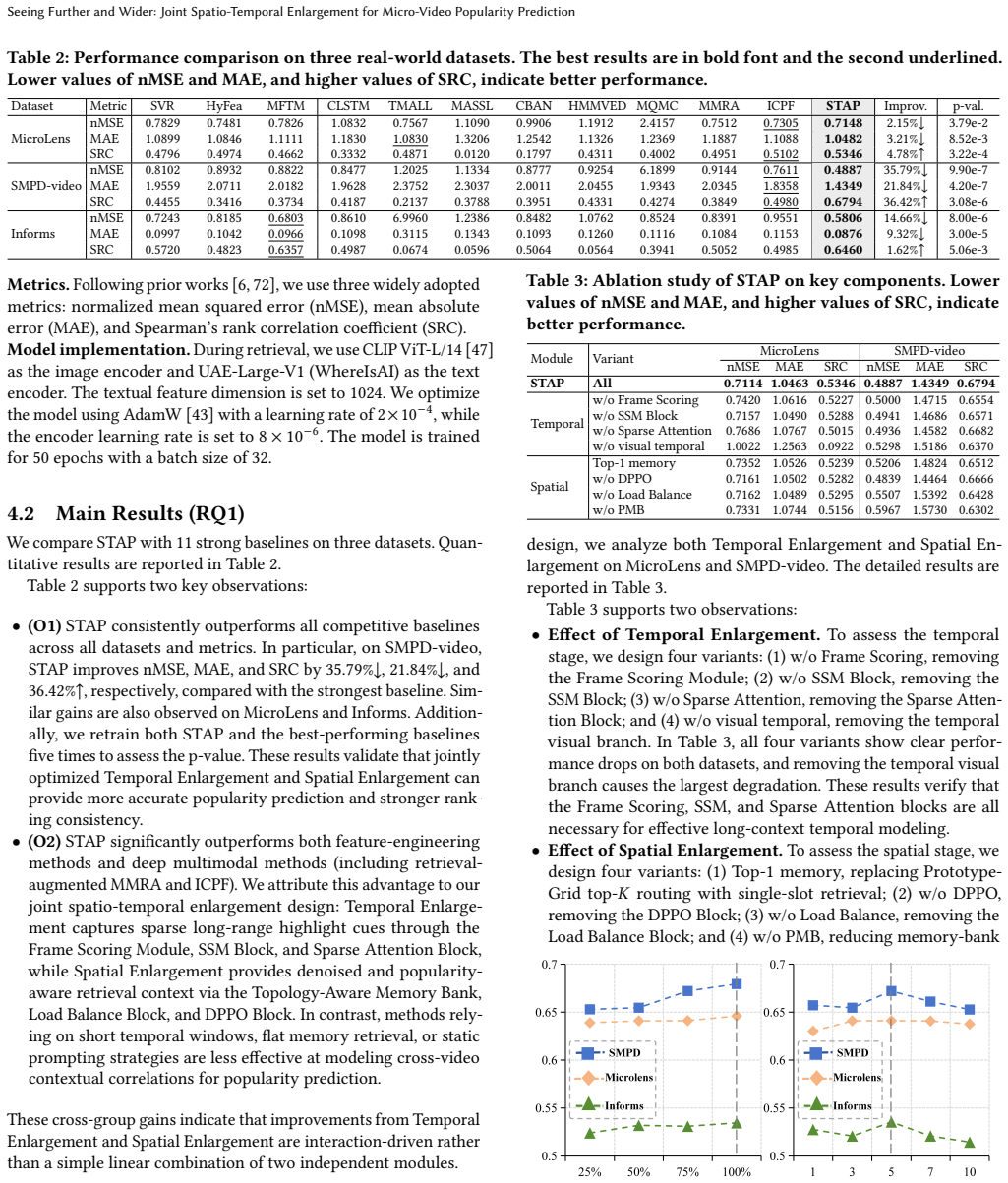
- The method produces consistent gains over eleven baselines on three standard MVPP benchmarks.
- It improves both prediction accuracy and ranking consistency.
- It supports more reliable content recommendation and traffic allocation by using fuller video context.
- It incorporates all relevant historical videos while keeping storage growth bounded.
Where Pith is reading between the lines
- The same enlargement pattern could be tested on other sequential prediction tasks such as view-count forecasting for longer videos.
- Applying the memory bank to datasets with millions of clips would check whether clustering remains efficient at web scale.
- The dual sampling paths suggest a general way to combine coarse and fine video signals in any task that needs both speed and detail.
Load-bearing premise
The adaptive fusion of sparse and dense frame views together with the hierarchical clustering and feature updates will deliver the claimed long-sequence perception and scalable storage without introducing biases or new efficiency costs.
What would settle it
A side-by-side test on videos whose length exceeds the original sparse sampling window or on a growing set of historical references where the new method shows no gain in accuracy or ranking over the flat-memory baselines.
Figures


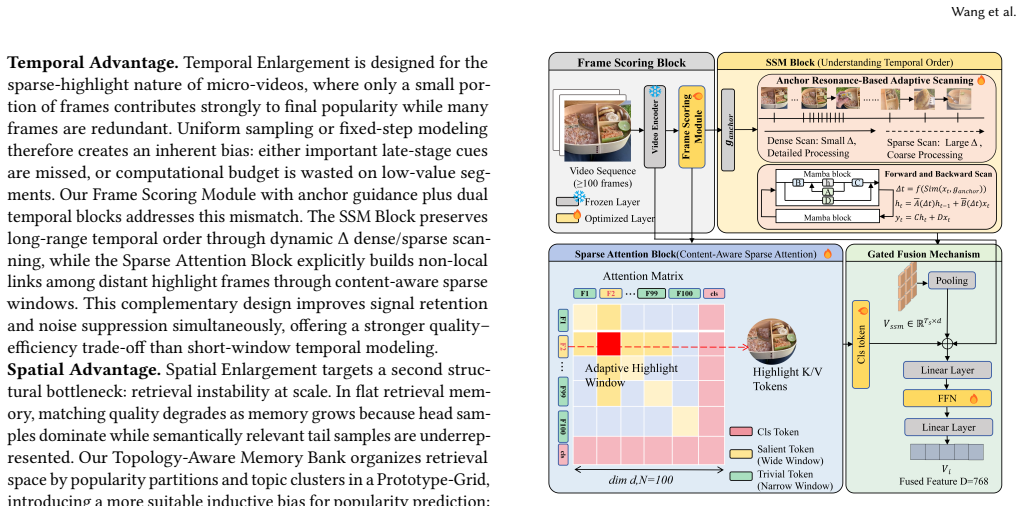



read the original abstract
Micro-video popularity prediction (MVPP) aims to forecast the future popularity of videos on online media, which is essential for applications such as content recommendation and traffic allocation. In real-world scenarios, it is critical for MVPP approaches to understand both the temporal dynamics of a given video (temporal) and its historical relevance to other videos (spatial). However, existing approaches sufer from limitations in both dimensions: temporally, they rely on sparse short-range sampling that restricts content perception; spatially, they depend on flat retrieval memory with limited capacity and low efficiency, hindering scalable knowledge utilization. To overcome these limitations, we propose a unified framework that achieves joint spatio-temporal enlargement, enabling precise perception of extremely long video sequences while supporting a scalable memory bank that can infinitely expand to incorporate all relevant historical videos. Technically, we employ a Temporal Enlargement driven by a frame scoring module that extracts highlight cues from video frames through two complementary pathways: sparse sampling and dense perception. Their outputs are adaptively fused to enable robust long-sequence content understanding. For Spatial Enlargement, we construct a Topology-Aware Memory Bank that hierarchically clusters historically relevant content based on topological relationships. Instead of directly expanding memory capacity, we update the encoder features of the corresponding clusters when incorporating new videos, enabling unbounded historical association without unbounded storage growth. Extensive experiments on three widely used MVPP benchmarks demonstrate that our method consistently outperforms 11 strong baselines across mainstream metrics, achieving robust improvements in both prediction accuracy and ranking consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a unified framework for micro-video popularity prediction (MVPP) that performs joint spatio-temporal enlargement. Temporally, a frame scoring module extracts highlight cues via complementary sparse sampling and dense perception pathways whose outputs are adaptively fused. Spatially, a Topology-Aware Memory Bank hierarchically clusters historical videos by topological relationships and updates the encoder features of the corresponding clusters (rather than adding new entries) to support unbounded historical association without unbounded storage growth. The authors report that the resulting model consistently outperforms 11 strong baselines across mainstream metrics on three widely used MVPP benchmarks, with gains in both prediction accuracy and ranking consistency.
Significance. If the central claims hold, the work would advance MVPP by addressing two practical bottlenecks—restricted temporal range from short-range sampling and limited scalability of flat retrieval memory—thereby improving content recommendation and traffic allocation systems. The constructive design of the memory bank (hierarchical clustering plus feature updates) is a notable technical contribution that could generalize beyond MVPP if information preservation is demonstrated.
major comments (1)
- [§3.3] §3.3 (Topology-Aware Memory Bank): The claim that updating cluster encoder features enables 'unbounded historical association' without loss of video-specific information is load-bearing for the spatial-enlargement contribution and the reported benchmark gains. The manuscript does not specify the exact update rule (e.g., averaging, weighted fusion) nor provide an analysis or ablation showing that distinctive per-video cues are retained after repeated updates. If clustering is imperfect or updates overwrite details, the memory bank would not truly support scalable knowledge utilization, making the outperformance potentially attributable to the temporal module alone.
minor comments (2)
- [Abstract] Abstract: 'sufer' is a typographical error and should read 'suffer'.
- [Abstract] Abstract: The abstract asserts consistent outperformance and 'robust improvements' but supplies no numerical deltas, ablation results, or error bars. Adding at least one representative table excerpt or key metric values would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential impact. We address the single major comment point-by-point below, agreeing that clarification and additional validation are warranted for the Topology-Aware Memory Bank.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Topology-Aware Memory Bank): The claim that updating cluster encoder features enables 'unbounded historical association' without loss of video-specific information is load-bearing for the spatial-enlargement contribution and the reported benchmark gains. The manuscript does not specify the exact update rule (e.g., averaging, weighted fusion) nor provide an analysis or ablation showing that distinctive per-video cues are retained after repeated updates. If clustering is imperfect or updates overwrite details, the memory bank would not truly support scalable knowledge utilization, making the outperformance potentially attributable to the temporal module alone.
Authors: We agree that the update rule and its effect on information retention must be made explicit to substantiate the spatial-enlargement claims. In the revised manuscript we will add the precise update formula in §3.3: when a new video is assigned to cluster c with centroid similarity s, the cluster encoder feature is updated via a weighted moving average f_c ← (1 − β·s)·f_c + (β·s)·f_new, where β is a fixed decay hyper-parameter (set to 0.3 in all experiments). This rule blends new information proportionally to relevance while damping overwriting of prior cluster content. We will also insert a new ablation subsection (§4.4) that (i) tracks average cosine similarity between original per-video features and their post-update cluster representations over 10 successive updates, (ii) compares prediction performance when the memory bank is replaced by a flat retrieval baseline of equal capacity, and (iii) reports that the joint spatio-temporal model still yields statistically significant gains over the temporal-only variant. These additions directly address the concern that gains might stem solely from the temporal module. revision: yes
Circularity Check
No circularity: constructive framework with independent empirical validation
full rationale
The paper presents a constructive proposal for joint spatio-temporal enlargement in MVPP, describing a frame scoring module with adaptive fusion for temporal enlargement and a topology-aware memory bank using hierarchical clustering and cluster feature updates for spatial enlargement. No equations, derivations, or self-referential definitions appear that reduce the claimed outperformance to fitted inputs or prior self-citations by construction. The central claims rest on the architectural design and benchmark experiments against 11 baselines, which are externally falsifiable and do not collapse into the method's own parameters or definitions.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Frame scoring module with sparse and dense pathways
no independent evidence
-
Topology-Aware Memory Bank
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lucic, Cordelia Schmid, Ali Zolna, Jonathan Romero, Alexey Dosovitskiy, Jakob Uszkor- eit, et al. 2021. ViViT: A Video Vision Transformer.arXiv preprint arXiv:2103.15691 (2021). doi:10.48550/arXiv.2103.15691
-
[2]
Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long- document transformer.arXiv preprint arXiv:2004.05150(2020)
work page internal anchor Pith review arXiv 2020
-
[3]
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. 2021. Is Space-Time At- tention All You Need for Video Understanding?arXiv preprint arXiv:2102.05095 (2021). doi:10.48550/arXiv.2102.05095
-
[4]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
2020
-
[5]
João Carreira and Andrew Zisserman. 2017. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 4724–4733. doi:10.1109/CVPR.2017.502
-
[6]
Jingyuan Chen, Xuemeng Song, Liqiang Nie, Xiang Wang, Hanwang Zhang, and Tat-Seng Chua. 2016. Micro Tells Macro: Predicting the Popularity of Micro- Videos via a Transductive Model. InProceedings of the 24th ACM International Conference on Multimedia(Amsterdam, The Netherlands)(MM ’16). Association for Computing Machinery, New York, NY, USA, 898–907. doi:...
-
[7]
Zhiwei Chen, Yupeng Hu, Zhiheng Fu, Zixu Li, Jiale Huang, Qinlei Huang, and Yinwei Wei. 2026. Intent: Invariance and discrimination-aware noise mitigation for robust composed image retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 20463–20471
2026
-
[8]
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Xuemeng Song, and Liqiang Nie. 2025. Offset: Segmentation-based focus shift revision for composed image retrieval. InProceedings of the 33rd ACM International Conference on Multimedia. 6113–6122
2025
-
[9]
Zhangtao Cheng, Jian Lang, Ting Zhong, and Fan Zhou. 2025. Seeing the Unseen in Micro-Video Popularity Prediction: Self-Correlation Retrieval for Missing Modality Generation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1(Toronto ON, Canada)(KDD ’25). Association for Computing Machinery, New York, NY, USA, 142–1...
-
[10]
Zhangtao Cheng, Jiao Li, Jian Lang, Ting Zhong, and Fan Zhou. 2025. In- context prompt-augmented micro-video popularity prediction. InProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Sympo- sium on Educational Advances in Artificial ...
-
[11]
Zhangtao Cheng, Jienan Zhang, Xovee Xu, Goce Trajcevski, Ting Zhong, and Fan Zhou. 2024. Retrieval-Augmented Hypergraph for Multimodal Social Media Popularity Prediction. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Barcelona, Spain)(KDD ’24). Association for Computing Machinery, New York, NY, USA, 445–455. doi:10...
-
[12]
Zhangtao Cheng, Fan Zhou, Xovee Xu, Kunpeng Zhang, Goce Trajcevski, Ting Zhong, and Philip S. Yu. 2024. Information Cascade Popularity Prediction via Probabilistic Diffusion.IEEE Trans. on Knowl. and Data Eng.36, 12 (Dec. 2024), 8541–8555. doi:10.1109/TKDE.2024.3465241
-
[13]
Tsun-hin Cheung and Kin-man Lam. 2022. Crossmodal bipolar attention for multimodal classification on social media.Neurocomput.514, C (Dec. 2022), 1–12. doi:10.1016/j.neucom.2022.09.140
-
[14]
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, An- dreea Gane, Tamas Sarlos, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. 2021. Rethinking Attention with Performers.arXiv preprint arXiv:2009.14794(2021). doi:10.48550/arXiv.2009.14794
work page internal anchor Pith review doi:10.48550/arxiv.2009.14794 2021
-
[15]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[16]
Yali Du, Yinwei Wei, Wei Ji, Fan Liu, Xin Luo, and Liqiang Nie. 2023. Multi- queue Momentum Contrast for Microvideo-Product Retrieval. InProceedings of the Sixteenth ACM International Conference on Web Search and Data Mining (Singapore, Singapore)(WSDM ’23). Association for Computing Machinery, New York, NY, USA, 1003–1011. doi:10.1145/3539597.3570405
-
[17]
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. 2019. Slow- Fast Networks for Video Recognition.arXiv preprint arXiv:1812.03982(2019). doi:10.48550/arXiv.1812.03982
-
[18]
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 5484–5495
2021
-
[19]
Shalini Ghosh, Oriol Vinyals, Brian Strope, Scott Roy, Tom Dean, and Larry Heck
- [20]
-
[21]
Albert Gu and Tri Dao. 2024. Mamba: Linear-time sequence modeling with selective state spaces. InFirst conference on language modeling
2024
-
[22]
Albert Gu, Karan Goel, and Christopher Ré. 2021. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396(2021)
work page internal anchor Pith review arXiv 2021
-
[23]
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating large-scale inference with anisotropic vector quantization. InProceedings of the 37th International Conference on Machine Learning (ICML’20). JMLR.org, Article 364, 10 pages
2020
-
[24]
Chih-Chung Hsu, Chia-Ming Lee, Xiu-Yu Hou, and Chi-Han Tsai. 2023. Gra- dient Boost Tree Network based on Extensive Feature Analysis for Popularity Prediction of Social Posts. InProceedings of the 31st ACM International Confer- ence on Multimedia(Ottawa ON, Canada)(MM ’23). Association for Computing Machinery, New York, NY, USA, 9451–9455. doi:10.1145/358...
-
[25]
Yupeng Hu, Zixu Li, Zhiwei Chen, Qinlei Huang, Zhiheng Fu, Mingzhu Xu, and Liqiang Nie. 2026. Refine: Composed video retrieval via shared and differ- ential semantics enhancement.ACM Transactions on Multimedia Computing, Communications and Applications(2026)
2026
- [26]
-
[27]
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. 2022. Visual prompt tuning. InEuro- pean conference on computer vision. Springer, 709–727
2022
-
[28]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 6769–6781. doi:10.18653/v1/2020.emnlp-main.550
-
[29]
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 39–48. doi:10.1145/3397271.3401075
-
[30]
Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. 2023. Maple: Multi-modal prompt learning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19113–19122
2023
-
[31]
Aditya Khosla, Atish Das Sarma, and Raffay Hamid. 2014. What makes an image popular?. InProceedings of the 23rd International Conference on World Wide Web (Seoul, Korea)(WWW ’14). Association for Computing Machinery, New York, NY, USA, 867–876. doi:10.1145/2566486.2567996
-
[32]
Xin Lai, Yihong Zhang, and Wei Zhang. 2020. HyFea: Winning Solution to Social Media Popularity Prediction for Multimedia Grand Challenge 2020. InProceedings of the 28th ACM International Conference on Multimedia(Seattle, WA, USA)(MM ’20). Association for Computing Machinery, New York, NY, USA, 4565–4569. doi:10.1145/3394171.3416273
-
[33]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, et al
-
[34]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv preprint arXiv:2005.11401(2020). doi:10.48550/arXiv.2005.11401
work page internal anchor Pith review doi:10.48550/arxiv.2005.11401 2005
-
[35]
Kunchang Li, Xinhao Li, Yi Wang, Yinan He, Yali Wang, Limin Wang, and Yu Qiao
-
[36]
VideoMamba: State Space Model for Efficient Video Understanding. In Computer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XXVI(Milan, Italy). Springer-Verlag, Berlin, Heidelberg, 237–255. doi:10.1007/978-3-031-73347-5_14
-
[37]
Wenbing Li, Zikai Song, Jielei Zhang, Tianhao Zhao, Junkai Lin, Yiran Wang, and Wei Yang. 2026. Large Language Model as Token Compressor and Decompressor. arXiv:2603.25340 [cs.CL]
work page internal anchor Pith review arXiv 2026
-
[38]
Wenbing Li, Zikai Song, Hang Zhou, Yunyao Zhang, Junqing Yu, and Wei Yang
-
[39]
arXiv preprint arXiv:2507.00029 (2025)
LoRA-Mixer: Coordinate Modular LoRA Experts Through Serial Attention Routing.arXiv preprint arXiv:2507.00029(2025). 9 Wang et al
work page internal anchor Pith review arXiv 2025
- [40]
-
[41]
Yanshu Li, Yi Cao, Hongyang He, Qisen Cheng, Xiang Fu, Xi Xiao, Tianyang Wang, and Ruixiang Tang. 2025. M2IV: Towards Efficient and Fine-grained Multimodal In-Context Learning via Representation Engineering. InSecond Conference on Language Modeling. https://openreview.net/forum?id=9ffYcEiNw9
2025
-
[42]
Yanshu Li, Jianjiang Yang, Tian Yun, Pinyuan Feng, Jinfa Huang, and Ruixiang Tang. 2025. Taco: Enhancing multimodal in-context learning via task mapping- guided sequence configuration. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 736–763
2025
-
[43]
Zixu Li, Yupeng Hu, Zhiwei Chen, Qinlei Huang, Guozhi Qiu, Zhiheng Fu, and Meng Liu. 2026. Retrack: Evidence-driven dual-stream directional anchor calibra- tion network for composed video retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 23373–23381
2026
-
[44]
Zixu Li, Yupeng Hu, Zhiwei Chen, Shiqi Zhang, Qinlei Huang, Zhiheng Fu, and Yinwei Wei. 2026. Habit: Chrono-synergia robust progressive learning framework for composed image retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 6762–6770
2026
- [45]
-
[46]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing.ACM Comput. Surv.55, 9, Article 195 (Jan. 2023), 35 pages. doi:10.1145/3560815
-
[47]
Ilya Loshchilov, Frank Hutter, et al. 2017. Fixing weight decay regularization in adam.arXiv preprint arXiv:1711.051015, 5 (2017), 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
Shijian Mao, Wudong Xi, Lei Yu, Gaotian Lü, Xingxing Xing, Xingchen Zhou, and Wei Wan. 2023. Enhanced CatBoost with Stacking Features for Social Media Prediction. InProceedings of the 31st ACM International Conference on Multimedia (Ottawa ON, Canada)(MM ’23). Association for Computing Machinery, New York, NY, USA, 9430–9435. doi:10.1145/3581783.3612839
-
[49]
Yongxin Ni, Yu Cheng, Xiangyan Liu, Junchen Fu, Youhua Li, Xiangnan He, Yongfeng Zhang, and Fajie Yuan. 2025. A Content-Driven Micro-Video Rec- ommendation Dataset at Scale. InProceedings of the 34th ACM International Conference on Information and Knowledge Management(Seoul, Republic of Ko- rea)(CIKM ’25). Association for Computing Machinery, New York, NY...
- [50]
-
[51]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[52]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[53]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme
-
[54]
BPR: Bayesian personalized ranking from implicit feedback.arXiv preprint arXiv:1205.2618(2012)
work page internal anchor Pith review arXiv 2012
-
[55]
Zikai Song, Run Luo, Lintao Ma, Ying Tang, Yi-Ping Phoebe Chen, Junqing Yu, and Wei Yang. 2025. Temporal Coherent Object Flow for Multi-Object Tracking. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 6978–6986
2025
-
[56]
Zikai Song, Run Luo, Junqing Yu, Yi-Ping Phoebe Chen, and Wei Yang. 2023. Compact transformer tracker with correlative masked modeling. InProceedings of the AAAI conference on artificial intelligence, Vol. 37. 2321–2329
2023
-
[57]
Zikai Song, Ying Tang, Run Luo, Lintao Ma, Junqing Yu, Yi-Ping Phoebe Chen, and Wei Yang. 2024. Autogenic language embedding for coherent point tracking. In Proceedings of the 32nd ACM International Conference on Multimedia. 2021–2030
2024
-
[58]
Zikai Song, Junqing Yu, Yi-Ping Phoebe Chen, and Wei Yang. 2022. Transformer tracking with cyclic shifting window attention. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8791–8800
2022
-
[59]
Zikai Song, Junqing Yu, Yi-Ping Phoebe Chen, Wei Yang, and Xinchao Wang
-
[60]
Hypergraph-State Collaborative Reasoning for Multi-Object Tracking
Hypergraph-State Collaborative Reasoning for Multi-Object Tracking. arXiv:2604.12665 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[62]
Linformer: Self-Attention with Linear Complexity
Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, and Hao Ma. 2020. Linformer: Self-Attention with Linear Complexity.arXiv preprint arXiv:2006.04768 (2020). doi:10.48550/arXiv.2006.04768
work page internal anchor Pith review doi:10.48550/arxiv.2006.04768 2020
-
[63]
Bo Wu, Peiye Liu, Qiushi Huang, Zhaoyang Zeng, Jia Wang, Bei Liu, Jiebo Luo, and Wen-Huang Cheng. 2025. SMPV: Social Media Prediction for Videos. In Proceedings of the 33rd ACM International Conference on Multimedia(Dublin, Ireland)(MM ’25). Association for Computing Machinery, New York, NY, USA, 14055–14057. doi:10.1145/3746027.3763757
-
[64]
Bo Wu, Tao Mei, Wen-Huang Cheng, and Yongdong Zhang. 2016. Unfolding temporal dynamics: Predicting social media popularity using multi-scale temporal decomposition. InProceedings of the AAAI conference on artificial intelligence, Vol. 30
2016
-
[65]
Jiayi Xie, Yaochen Zhu, and Zhenzhong Chen. 2021. Micro-video popularity prediction via multimodal variational information bottleneck.IEEE Transactions on Multimedia25 (2021), 24–37
2021
- [66]
-
[67]
Kele Xu, Zhimin Lin, Jianqiao Zhao, Peicang Shi, Wei Deng, and Huaimin Wang
-
[68]
InProceedings of the 28th ACM International Conference on Multimedia(Seattle, WA, USA)(MM ’20)
Multimodal Deep Learning for Social Media Popularity Prediction With Attention Mechanism. InProceedings of the 28th ACM International Conference on Multimedia(Seattle, WA, USA)(MM ’20). Association for Computing Machinery, New York, NY, USA, 4580–4584. doi:10.1145/3394171.3416274
-
[69]
Qianyun Yang, Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, and Liqiang Nie
- [70]
-
[71]
Liliang Ye, Yunyao Zhang, Yafeng Wu, Yi-Ping Phoebe Chen, Junqing Yu, Wei Yang, and Zikai Song. 2025. MVP: Winning Solution to SMP Challenge 2025 Video Track. InProceedings of the 33rd ACM International Conference on Multimedia (Dublin, Ireland)(MM ’25). Association for Computing Machinery, New York, NY, USA, 14079–14085. doi:10.1145/3746027.3763761
-
[72]
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. 2020. Big Bird: Transformers for Longer Sequences.arXiv preprint arXiv:2007.14062(2020). doi:10.48550/arXiv.2007.14062
- [73]
-
[74]
Xinglang Zhang, Yunyao Zhang, ZeLiang Chen, Junqing Yu, Wei Yang, and Zikai Song. 2026. Logical Phase Transitions: Understanding Collapse in LLM Logical Reasoning. arXiv:2601.02902 [cs.AI] https://arxiv.org/abs/2601.02902
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[75]
Yunyao Zhang, Yihao Ai, Zuocheng Ying, Qirui Mi, Junqing Yu, Wei Yang, and Zikai Song. 2026. Coupling Macro Dynamics and Micro States for Long-Horizon Social Simulation. arXiv:2604.05516 [cs.SI] https://arxiv.org/abs/2604.05516
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[76]
Yunyao Zhang, Zikai Song, Hang Zhou, Wenfeng Ren, Yi-Ping Phoebe Chen, Junqing Yu, and Wei Yang. 2025. 𝐺𝐴−𝑆 3: Comprehensive Social Network Simulation with Group Agents. InFindings of the Association for Computational Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational Li...
-
[77]
Yunyao Zhang, Zuocheng Ying, Xinglang Zhang, Junqing Yu, Peng Fang, Xu Chen, Wei Yang, and Zikai Song. 2026. IntervenSim: Intervention-Aware Social Network Simulation for Opinion Dynamics. arXiv:2604.06600 [cs.SI] https: //arxiv.org/abs/2604.06600
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[78]
Yunyao Zhang, Xinglang Zhang, Junxi Sheng, Wenbing Li, Junqing Yu, Yi- Ping Phoebe Chen, Wei Yang, and Zikai Song. 2026. Semantic-Aware Log- ical Reasoning via a Semiotic Framework. arXiv:2509.24765 [cs.AI] https: //arxiv.org/abs/2509.24765
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[79]
Zhuoran Zhang, Shibiao Xu, Li Guo, and Wenke Lian. 2023. Multi-modal Varia- tional Auto-Encoder Model for Micro-video Popularity Prediction. InProceedings of the 8th International Conference on Communication and Information Processing (Beijing, China)(ICCIP ’22). Association for Computing Machinery, New York, NY, USA, 9–16. doi:10.1145/3571662.3571664
-
[80]
Ting Zhong, Jian Lang, Yifan Zhang, Zhangtao Cheng, Kunpeng Zhang, and Fan Zhou. 2024. Predicting Micro-video Popularity via Multi-modal Retrieval Augmentation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval(Washington DC, USA)(SIGIR ’24). Association for Computing Machinery, New York, NY,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.