Can LLM Rerankers Predict Their Own Ranking Performance?
Pith reviewed 2026-06-28 08:17 UTC · model grok-4.3
The pith
LLM rerankers can estimate the quality of rankings they produce by checking consistency across multiple sampled outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
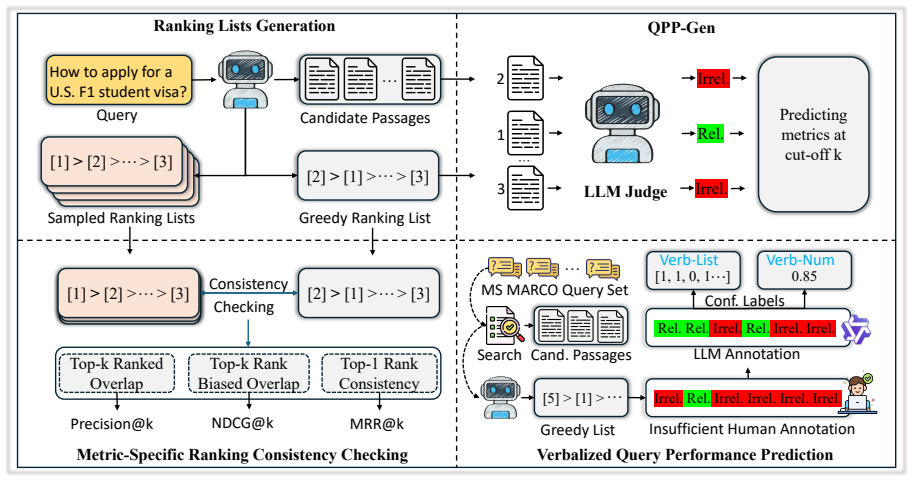
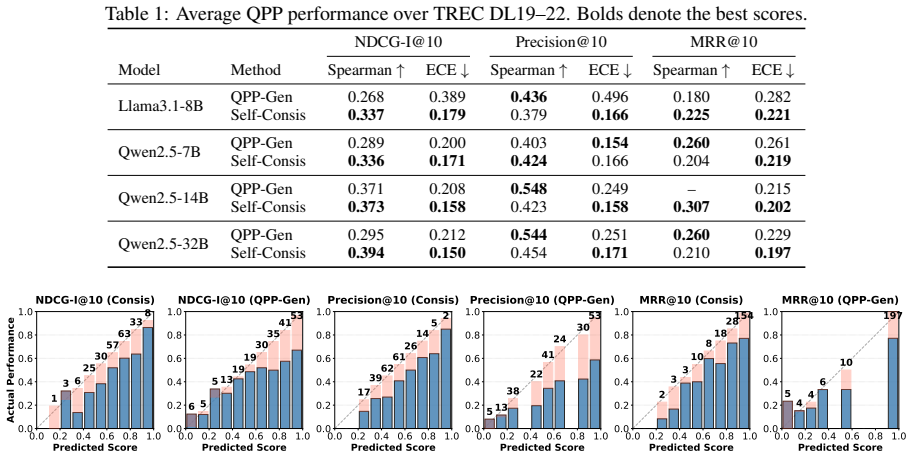
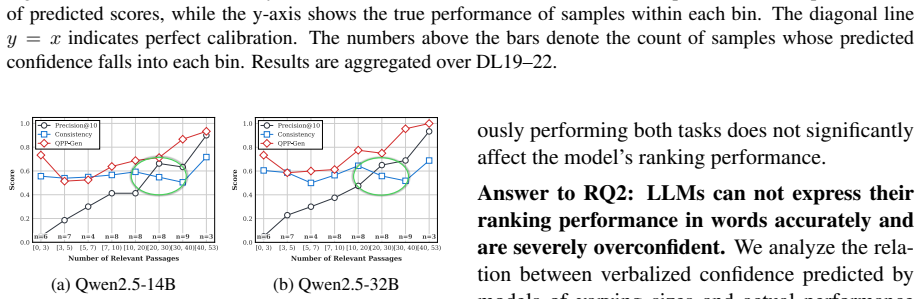
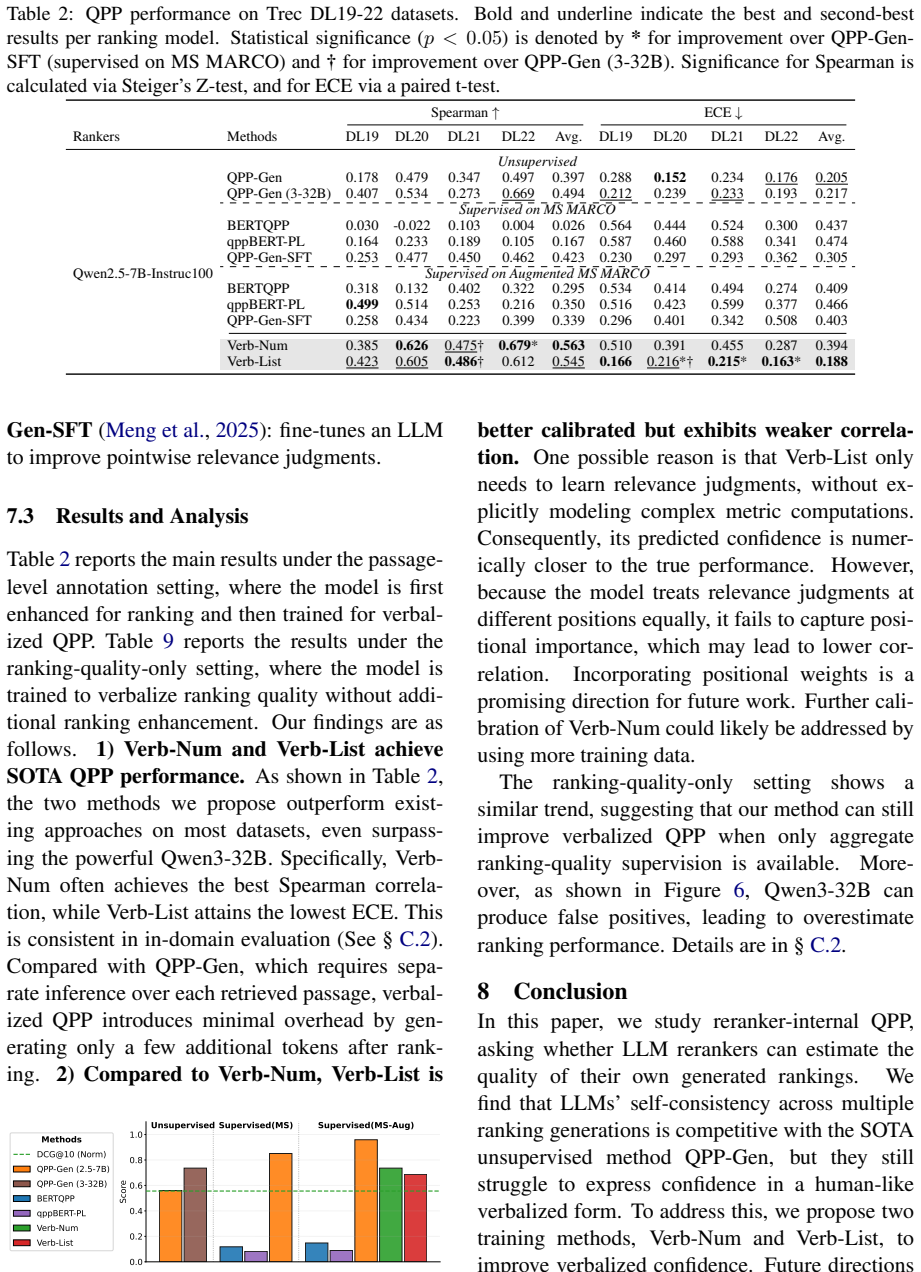
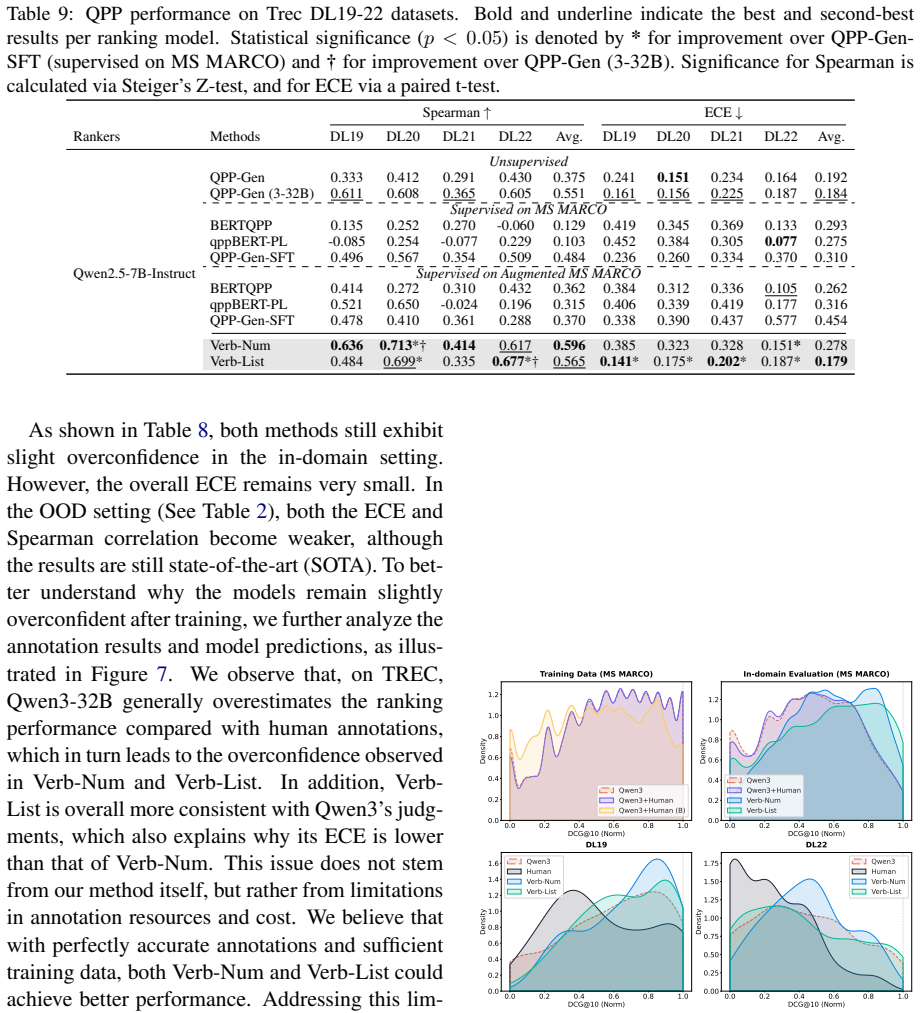
Reranker-internal query performance prediction works: metric-specific self-consistency across rankings sampled from an LLM reranker is competitive with the state-of-the-art external QPP approach and better calibrated in almost all settings on TREC DL 2019-2022, whereas direct verbalized confidence is severely overconfident but can be improved by supervised methods that require only a few additional output tokens.
What carries the argument
metric-specific self-consistency across independently sampled rankings produced by the same LLM reranker
If this is right
- Self-consistency matches or exceeds external SOTA QPP on TREC DL 2019-2022.
- Self-consistency is better calibrated than external predictors in nearly every tested setting.
- Direct verbalized confidence from the reranker is severely overconfident.
- Verb-Num and Verb-List supervised methods produce calibrated quality estimates with minimal added tokens.
Where Pith is reading between the lines
- Internal consistency checks could let retrieval systems skip maintaining a separate QPP model.
- The same sampling-consistency idea may apply to other LLM tasks whose output quality varies with the prompt.
- Hybrid systems could combine internal self-consistency with external signals for still stronger predictions.
Load-bearing premise
Agreement among multiple rankings sampled from the LLM indicates genuine ranking quality rather than shared model biases or prompt artifacts.
What would settle it
Self-consistency scores show no correlation with actual NDCG or other ranking metrics when evaluated against ground-truth relevance judgments on held-out queries.
Figures







read the original abstract
Retrieval effectiveness varies substantially across queries, making it important to estimate ranking quality before relevance judgments are available. Query performance prediction (QPP) addresses this need, but most existing methods rely on external predictors after retrieval or reranking. In this paper, we study \textit{reranker-internal QPP}: can an LLM reranker estimate the quality of the ranking it has just produced? We investigate both training-free and training-based approaches. For training-free estimation, we examine metric-specific self-consistency across sampled rankings and verbalized confidence produced directly by the reranker. Experiments on TREC Deep Learning 2019--2022 with four LLMs show that self-consistency is competitive with the state-of-the-art (SOTA) approach and better calibrated in almost all settings, while direct verbalized confidence is severely overconfident. To improve verbalized confidence, we propose two supervised methods, Verb-Num and Verb-List, which enable LLM rerankers to produce calibrated ranking-quality estimates with only a few additional output tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM rerankers can internally predict ranking quality via training-free metric-specific self-consistency across sampled rankings (competitive with external SOTA QPP and better calibrated on TREC DL 2019-2022) and verbalized confidence (overconfident), plus two supervised methods (Verb-Num, Verb-List) that achieve calibration with few extra tokens. Experiments use four LLMs on public TREC collections.
Significance. If the empirical claims hold after verification, the work would enable efficient reranker-internal QPP without external predictors, advancing retrieval systems that use LLMs. The public-dataset evaluation across multiple models is a strength for reproducibility.
major comments (3)
- [Experimental setup] The sampling procedure, number of samples per query, and exact computation of metric-specific self-consistency are not detailed enough to verify robustness against prompt artifacts or model biases (central to the training-free claim and competitiveness with SOTA).
- [Results] No statistical significance tests, confidence intervals, or variance reporting accompany the competitiveness and calibration comparisons with external QPP baselines on TREC DL 2019-2022, preventing assessment of whether observed gains are reliable.
- [Discussion] The manuscript does not include controls or ablations to rule out that high self-consistency arises from shared LLM biases or prompt artifacts rather than true relevance alignment, leaving the interpretation of the proxy open to alternative explanations.
minor comments (1)
- [Abstract] Abstract should explicitly name the four LLMs and list the precise TREC DL years/metrics for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental details, statistical reporting, and potential alternative explanations. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experimental setup] The sampling procedure, number of samples per query, and exact computation of metric-specific self-consistency are not detailed enough to verify robustness against prompt artifacts or model biases (central to the training-free claim and competitiveness with SOTA).
Authors: We agree that greater precision is warranted for reproducibility of the training-free approach. Section 3.2 of the manuscript specifies sampling 5 rankings per query at temperature 0.7 and computing self-consistency as the average pairwise nDCG@10 agreement across samples, but we will expand this with pseudocode, exact formulas, and a sensitivity table for sample count and temperature in the revision. revision: yes
-
Referee: [Results] No statistical significance tests, confidence intervals, or variance reporting accompany the competitiveness and calibration comparisons with external QPP baselines on TREC DL 2019-2022, preventing assessment of whether observed gains are reliable.
Authors: This observation is correct and limits interpretability of the reported competitiveness. In the revised manuscript we will add bootstrap 95% confidence intervals and paired significance tests (Wilcoxon signed-rank) for all main comparisons against external QPP baselines, along with per-model variance across the four LLMs. revision: yes
-
Referee: [Discussion] The manuscript does not include controls or ablations to rule out that high self-consistency arises from shared LLM biases or prompt artifacts rather than true relevance alignment, leaving the interpretation of the proxy open to alternative explanations.
Authors: We acknowledge the value of explicit controls. While the competitiveness with external SOTA QPP methods (which are explicitly relevance-oriented) provides indirect support, we will add a new ablation using randomized document orderings to demonstrate that self-consistency collapses under loss of relevance signal, plus a brief discussion of prompt-artifact risks in the limitations section. revision: yes
Circularity Check
No significant circularity; empirical results on held-out data
full rationale
The paper reports experimental comparisons of training-free self-consistency (across multiple LLM reranker samples) and supervised verbalized confidence methods against external SOTA QPP baselines on TREC DL 2019-2022, using ground-truth relevance judgments for evaluation. No equations, derivations, or first-principles claims are present that reduce any reported performance metric to a quantity fitted or defined inside the same experiment. Self-consistency is computed from independent samples but scored externally, satisfying the criteria for non-circular empirical evidence. Any self-citations are incidental and not load-bearing for the central competitiveness claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Information processing & management , volume=
A probabilistic model of information retrieval: development and comparative experiments: Part 2 , author=. Information processing & management , volume=. 2000 , publisher=
2000
-
[2]
Proceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval , pages=
Document language models, query models, and risk minimization for information retrieval , author=. Proceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval , pages=
-
[3]
Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
Colbert: Efficient and effective passage search via contextualized late interaction over bert , author=. Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
-
[4]
arXiv preprint arXiv:2007.00808 , year=
Approximate nearest neighbor negative contrastive learning for dense text retrieval , author=. arXiv preprint arXiv:2007.00808 , year=
arXiv 2007
-
[5]
2010 , publisher=
Estimating the query difficulty for information retrieval , author=. 2010 , publisher=
2010
-
[6]
Journal of the Association for Information Science and Technology , volume=
Query-performance prediction for effective query routing in domain-specific repositories , author=. Journal of the Association for Information Science and Technology , volume=. 2014 , publisher=
2014
-
[7]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Sliding windows are not the end: Exploring full ranking with long-context large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[8]
1995 , publisher=
Okapi at TREC-3 , author=. 1995 , publisher=
1995
-
[9]
ACM Transactions on Information Systems (TOIS) , volume=
A similarity measure for indefinite rankings , author=. ACM Transactions on Information Systems (TOIS) , volume=. 2010 , publisher=
2010
-
[10]
ACM Transactions on Information Systems , volume=
Query performance prediction using relevance judgments generated by large language models , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[11]
arXiv preprint arXiv:2507.10865 , year=
Overview of the TREC 2022 deep learning track , author=. arXiv preprint arXiv:2507.10865 , year=
arXiv 2022
-
[12]
The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
Neural query performance prediction using weak supervision from multiple signals , author=. The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
-
[13]
Proceedings of the 2019 ACM SIGIR International Conference on Theory of Information Retrieval , pages=
Performance prediction for non-factoid question answering , author=. Proceedings of the 2019 ACM SIGIR International Conference on Theory of Information Retrieval , pages=
2019
-
[14]
Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
BERT-QPP: contextualized pre-trained transformers for query performance prediction , author=. Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
-
[15]
Proceedings of the fifteenth ACM international conference on web search and data mining , pages=
Deep-qpp: A pairwise interaction-based deep learning model for supervised query performance prediction , author=. Proceedings of the fifteenth ACM international conference on web search and data mining , pages=
-
[16]
European Conference on Information Retrieval , pages=
Groupwise query performance prediction with BERT , author=. European Conference on Information Retrieval , pages=. 2022 , organization=
2022
-
[17]
Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
A'Pointwise-Query, Listwise-Document'based Query Performance Prediction Approach , author=. Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[18]
Information Sciences , volume=
Learning to rank and predict: Multi-task learning for ad hoc retrieval and query performance prediction , author=. Information Sciences , volume=. 2023 , publisher=
2023
-
[19]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[20]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[21]
5: A party of foundation models , author=
Qwen2. 5: A party of foundation models , author=. 2024 , publisher=
2024
-
[22]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[23]
Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval , pages=
Predicting query performance , author=. Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval , pages=
-
[24]
European conference on information retrieval , pages=
Query hardness estimation using Jensen-Shannon divergence among multiple scoring functions , author=. European conference on information retrieval , pages=. 2007 , organization=
2007
-
[25]
Proceedings of the 15th ACM international conference on Information and knowledge management , pages=
Ranking robustness: a novel framework to predict query performance , author=. Proceedings of the 15th ACM international conference on Information and knowledge management , pages=
-
[26]
Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval , pages=
Query performance prediction in web search environments , author=. Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval , pages=
-
[27]
Proceedings of the 32nd ACM International Conference on Information and Knowledge Management , pages=
Noisy perturbations for estimating query difficulty in dense retrievers , author=. Proceedings of the 32nd ACM International Conference on Information and Knowledge Management , pages=
-
[28]
ACM Transactions on Information Systems , volume=
A relative information gain-based query performance prediction framework with generated query variants , author=. ACM Transactions on Information Systems , volume=. 2022 , publisher=
2022
-
[29]
ACM Transactions on Information Systems (TOIS) , volume=
Predicting query performance by query-drift estimation , author=. ACM Transactions on Information Systems (TOIS) , volume=. 2012 , publisher=
2012
-
[30]
International Symposium on String Processing and Information Retrieval , pages=
Standard deviation as a query hardness estimator , author=. International Symposium on String Processing and Information Retrieval , pages=. 2010 , organization=
2010
-
[31]
Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval , pages=
Improved query performance prediction using standard deviation , author=. Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval , pages=
-
[32]
Proceedings of the 23rd ACM international conference on conference on information and knowledge management , pages=
Query performance prediction by considering score magnitude and variance together , author=. Proceedings of the 23rd ACM international conference on conference on information and knowledge management , pages=
-
[33]
2023 , publisher=
Entropy-based query performance prediction for neural information retrieval systems , author=. 2023 , publisher=
2023
-
[34]
Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval , pages=
Towards query performance prediction for neural information retrieval: challenges and opportunities , author=. Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval , pages=
2023
-
[35]
European Conference on Information Retrieval , pages=
Query performance prediction through retrieval coherency , author=. European Conference on Information Retrieval , pages=. 2021 , organization=
2021
-
[36]
arXiv preprint arXiv:2310.11405 , year=
On coherence-based predictors for dense query performance prediction , author=. arXiv preprint arXiv:2310.11405 , year=
-
[37]
Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Unsupervised query performance prediction for neural models with pairwise rank preferences , author=. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[38]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[39]
arXiv preprint arXiv:2003.07892 , year=
Calibration of pre-trained transformers , author=. arXiv preprint arXiv:2003.07892 , year=
arXiv 2003
-
[40]
Transactions of the Association for Computational Linguistics , volume=
How can we know when language models know? on the calibration of language models for question answering , author=. Transactions of the Association for Computational Linguistics , volume=. 2021 , publisher=
2021
-
[41]
arXiv preprint arXiv:2207.05221 , year=
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
-
[42]
arXiv preprint arXiv:2210.09150 , year=
Prompting gpt-3 to be reliable , author=. arXiv preprint arXiv:2210.09150 , year=
-
[43]
Transactions of the Association for Computational Linguistics , volume=
Unsupervised quality estimation for neural machine translation , author=. Transactions of the Association for Computational Linguistics , volume=. 2020 , publisher=
2020
-
[44]
arXiv preprint arXiv:2602.07842 , year=
Evaluating and Calibrating LLM Confidence on Questions with Multiple Correct Answers , author=. arXiv preprint arXiv:2602.07842 , year=
-
[45]
Proceedings of EMNLP 2023 , pages =
Potsawee Manakul and Adian Liusie and Mark Gales , title =. Proceedings of EMNLP 2023 , pages =. 2023 , doi =
2023
-
[46]
International Conference on Learning Representations (ICLR) , year =
Kuhn, Lorenz and Gal, Yarin and Farquhar, Sebastian , title =. International Conference on Learning Representations (ICLR) , year =
-
[47]
arXiv preprint arXiv:2311.01740 , year=
SAC3: Reliable hallucination detection in black-box language models via semantic-aware cross-check consistency , author=. arXiv preprint arXiv:2311.01740 , year=
-
[48]
arXiv preprint arXiv:2402.10612 , year=
Retrieve only when it needs: Adaptive retrieval augmentation for hallucination mitigation in large language models , author=. arXiv preprint arXiv:2402.10612 , year=
-
[49]
arXiv preprint arXiv:2505.17656 , year=
Too Consistent to Detect: A Study of Self-Consistent Errors in LLMs , author=. arXiv preprint arXiv:2505.17656 , year=
-
[50]
arXiv preprint arXiv:2305.18153 , year=
Do Large Language Models Know What They Don't Know? , author=. arXiv preprint arXiv:2305.18153 , year=
-
[51]
arXiv preprint arXiv:2305.14975 , year=
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback , author=. arXiv preprint arXiv:2305.14975 , year=
-
[52]
arXiv preprint arXiv:2306.13063 , year=
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms , author=. arXiv preprint arXiv:2306.13063 , year=
-
[53]
arXiv preprint arXiv:2402.11457 , year=
When Do LLMs Need Retrieval Augmentation? Mitigating LLMs' Overconfidence Helps Retrieval Augmentation , author=. arXiv preprint arXiv:2402.11457 , year=
-
[54]
arXiv preprint arXiv:2205.14334 , year=
Teaching models to express their uncertainty in words , author=. arXiv preprint arXiv:2205.14334 , year=
-
[55]
arXiv preprint arXiv:2312.07000 , year=
Alignment for honesty , author=. arXiv preprint arXiv:2312.07000 , year=
-
[56]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
R-tuning: Instructing large language models to say ‘I don’t know’ , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[57]
arXiv preprint arXiv:2304.13734 , year=
The internal state of an LLM knows when it's lying , author=. arXiv preprint arXiv:2304.13734 , year=
-
[58]
arXiv preprint arXiv:2403.06448 , year=
Unsupervised real-time hallucination detection based on the internal states of large language models , author=. arXiv preprint arXiv:2403.06448 , year=
-
[59]
arXiv preprint arXiv:2402.03744 , year=
INSIDE: LLMs' Internal States Retain the Power of Hallucination Detection , author=. arXiv preprint arXiv:2402.03744 , year=
-
[60]
arXiv preprint arXiv:2502.11677 , year=
Towards fully exploiting llm internal states to enhance knowledge boundary perception , author=. arXiv preprint arXiv:2502.11677 , year=
-
[61]
arXiv preprint arXiv:2510.17509 , year=
Annotation-efficient universal honesty alignment , author=. arXiv preprint arXiv:2510.17509 , year=
-
[62]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[63]
, author=
The proof and measurement of association between two things. , author=. 1961 , publisher=
1961
-
[64]
arXiv preprint arXiv:1611.09268 , year=
Ms marco: A human generated machine reading comprehension dataset , author=. arXiv preprint arXiv:1611.09268 , year=
-
[65]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[66]
Publications Manual , year = "1983", publisher =
1983
-
[67]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[68]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[69]
Dan Gusfield , title =. 1997
1997
-
[70]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[71]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.