Synthesize and Reward -- Reinforcement Learning for Multi-Step Tool Use in Live Environments
Pith reviewed 2026-06-28 09:52 UTC · model grok-4.3
The pith
PROVE trains LLMs for multi-step tool calls using live stateful servers, grounded synthesis, and efficiency-penalized rewards to achieve consistent benchmark gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
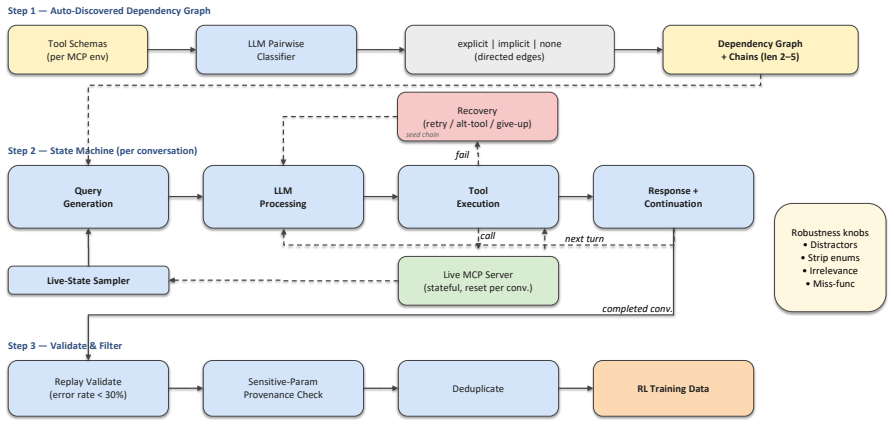
PROVE combines a library of twenty stateful MCP servers, a state-machine pipeline that produces multi-turn trajectories whose queries reference entities present in live server samples, and a multi-component programmatic reward containing an adaptive efficiency penalty; when four models are trained via GRPO on the resulting data, performance rises on BFCL Multi-Turn, tau2-bench, and T-Eval.
What carries the argument
The state-machine data synthesis pipeline that generates multi-turn tool-call trajectories grounded in live-sampled server state, paired with the multi-component programmatic reward that includes an adaptive efficiency penalty.
If this is right
- The trained models produce higher success rates on tasks that require several coordinated tool calls.
- The same training recipe delivers gains on two different model families and across several sizes.
- Session-scoped state isolation in the servers allows reinforcement learning to run without custom environment engineering for each task.
- The adaptive efficiency term reduces the number of extraneous tool calls while preserving task completion.
Where Pith is reading between the lines
- The synthesis approach could be reused for other interactive domains that maintain persistent state, such as database sessions or web applications.
- If the efficiency penalty generalizes, similar reward shaping might address verbosity in other reinforcement-learning settings that use recall-based signals.
- Scaling the server library beyond the current twenty instances would test whether the gains remain stable as tool diversity increases.
Load-bearing premise
The state-machine synthesis pipeline produces queries that reference entities actually present in the sampled server state.
What would settle it
Retraining the same models on trajectories generated without reference to live server state or without the efficiency penalty removes the reported gains on the three benchmarks.
Figures

read the original abstract
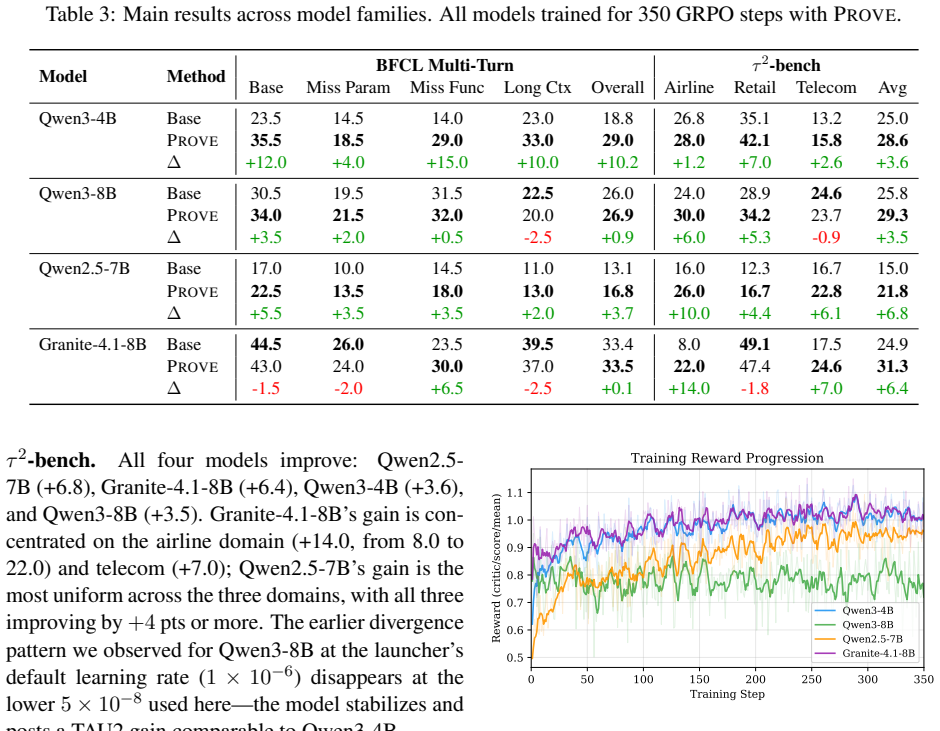
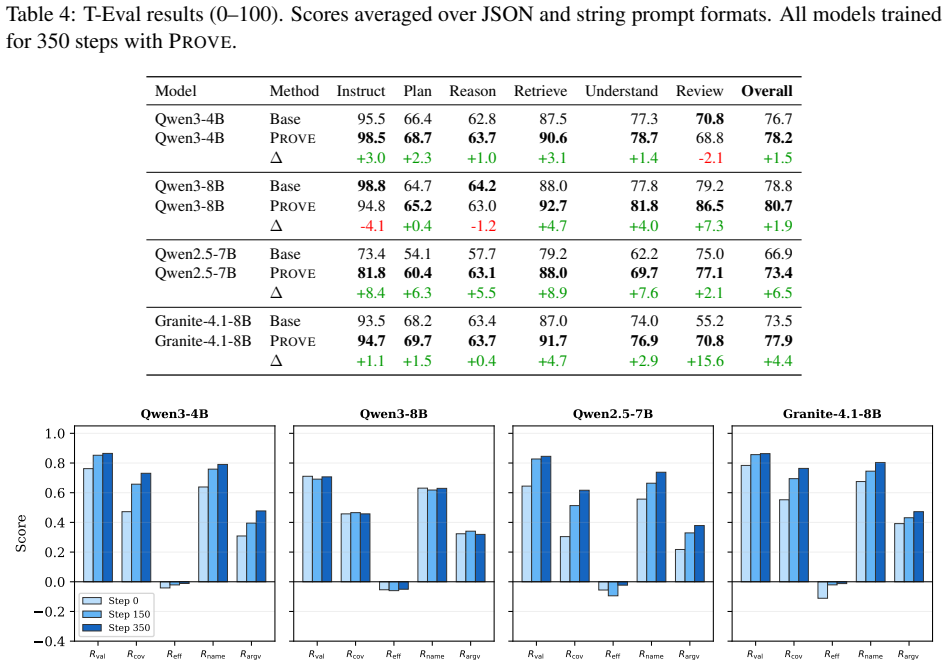
Training LLMs to orchestrate multi-step tool calls is held back by three coupled obstacles: realistic stateful execution environments are costly to build, synthetic training queries are often detached from the server's actual state (so the generated tool calls fail to execute), and recall-based RL rewards incentivize verbose tool-calling patterns. We present PROVE (Programmatic Rewards On Verified Environments), a framework with three contributions: (1) a library of 20 stateful MCP (Model Context Protocol) servers exposing 343 tools, enabling live-execution RL training with session-scoped state isolation; (2) a state-machine data synthesis pipeline that generates multi-turn tool-call trajectories grounded in live-sampled server state, so generated queries reference entities that actually exist; and (3) a multi-component programmatic reward with an adaptive efficiency penalty that counters the verbosity incentive of recall-based rewards. We train four models (Qwen3-4B, Qwen3-8B, Qwen2.5-7B, Granite-4.1-8B) with GRPO on the resulting ~13K training examples. On BFCL Multi-Turn, tau2-bench, and T-Eval, PROVE yields improvements of up to +10.2, +6.8, and +6.5 points respectively, demonstrating that this framework yields consistent gains on multi-step tool orchestration across two model families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PROVE, a framework for RL-based training of LLMs on multi-step tool use. It contributes (1) a library of 20 stateful MCP servers with 343 tools for live execution, (2) a state-machine pipeline that synthesizes ~13K multi-turn trajectories grounded in live-sampled server state, and (3) a multi-component programmatic reward including an adaptive efficiency penalty. Four models (Qwen3-4B, Qwen3-8B, Qwen2.5-7B, Granite-4.1-8B) are trained via GRPO; the abstract reports gains of up to +10.2 on BFCL Multi-Turn, +6.8 on tau2-bench, and +6.5 on T-Eval.
Significance. If the grounding of the synthesized data and the experimental controls are verified, the work offers a concrete path to scalable RL for tool orchestration by combining live environments with programmatic rewards that mitigate verbosity. The release of the server library and the emphasis on verified state constitute reusable infrastructure that could support follow-on research.
major comments (2)
- [Abstract] Abstract, contribution 2: The claim that the state-machine pipeline produces queries referencing entities that 'actually exist' in the live-sampled server state is stated without any quantitative verification (e.g., fraction of trajectories passing an existence probe, state-machine failure rate, or comparison to a non-grounded baseline). This verification is load-bearing for attributing the reported benchmark deltas to the framework rather than to data artifacts.
- [Abstract] Abstract: The reported improvements (+10.2, +6.8, +6.5) are presented without any information on baseline definitions, number of evaluation runs, variance across seeds, or statistical significance tests. These omissions prevent assessment of whether the gains are robust or sensitive to post-hoc choices.
minor comments (1)
- [Abstract] The abstract would benefit from a one-sentence description of how the adaptive efficiency penalty is computed relative to the recall-based component.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for quantitative verification of data grounding and clearer reporting of evaluation details. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract, contribution 2: The claim that the state-machine pipeline produces queries referencing entities that 'actually exist' in the live-sampled server state is stated without any quantitative verification (e.g., fraction of trajectories passing an existence probe, state-machine failure rate, or comparison to a non-grounded baseline). This verification is load-bearing for attributing the reported benchmark deltas to the framework rather than to data artifacts.
Authors: We agree that explicit quantitative verification is necessary to support the grounding claim and to rule out data artifacts as the source of gains. The manuscript describes the state-machine design but does not report success rates, failure rates, or baseline comparisons. We will add a dedicated paragraph in the data synthesis section (Section 3.2) that includes: (1) the fraction of trajectories passing an existence probe on live-sampled state, (2) the observed state-machine failure rate, and (3) a direct comparison against a non-grounded synthesis baseline. These additions will be supported by the same ~13K trajectory set used for training. revision: yes
-
Referee: [Abstract] Abstract: The reported improvements (+10.2, +6.8, +6.5) are presented without any information on baseline definitions, number of evaluation runs, variance across seeds, or statistical significance tests. These omissions prevent assessment of whether the gains are robust or sensitive to post-hoc choices.
Authors: The abstract reports peak improvements but omits evaluation protocol details. The full manuscript defines baselines in Section 4 (untuned base models evaluated under identical conditions) and describes the evaluation setup. However, the current version does not report multiple runs, seed variance, or significance tests. We will revise the abstract to explicitly name the baselines and add a sentence noting that results reflect single-run evaluations with fixed seeds due to compute limits. We will also expand the experimental section to include any available run-level details and acknowledge the absence of multi-seed statistics as a limitation, while committing to future multi-run verification. revision: partial
Circularity Check
No circularity; empirical gains on external benchmarks are independent of inputs
full rationale
The paper reports empirical improvements from training four models with GRPO on ~13K synthesized trajectories using a state-machine pipeline and programmatic rewards, evaluated on public benchmarks (BFCL Multi-Turn, tau2-bench, T-Eval). No equations, fitted parameters, or predictions are presented that reduce to the synthesis pipeline or reward function by construction. The grounding claim for the state-machine is an unverified assumption about data quality rather than a self-definitional or fitted-input reduction. The derivation chain consists of standard RL training plus external evaluation and is therefore self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jiayang Cheng and Xin Liu and Zhihan Zhang and Haoyang Wen and Zixuan Zhang and Qingyu Yin and Shiyang Li and Priyanka Nigam and Bing Yin and Chao Zhang and Yangqiu Song , year=. Training. 2603.24709 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil and Tianjun Zhang and Xin Wang and Joseph E. Gonzalez , year=. Gorilla: Large Language Model Connected with Massive. 2305.15334 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Patil and Huanzhi Mao and Charlie Cheng-Jie Ji and Fanjia Yan and Vishnu Suresh and Ion Stoica and Joseph E
Shishir G. Patil and Huanzhi Mao and Charlie Cheng-Jie Ji and Fanjia Yan and Vishnu Suresh and Ion Stoica and Joseph E. Gonzalez , year=. The Berkeley Function Calling Leaderboard (
-
[4]
Lucen Zhong and Zhengxiao Du and Akari Asai and Jie Tang , year=. 2501.10005 , archivePrefix=
-
[5]
Zehui Chen and Weihua Du and Wenwei Zhang and Kuikun Liu and Jiangning Liu and Miao Zheng and Jingming Zhuo and Songyang Zhang and Dahua Lin and Kai Chen and Feng Zhao , year=. 2312.14033 , archivePrefix=
-
[6]
2025 , eprint=
^2 -bench: Evaluating Conversational Agents in a Dual-Control Environment , author=. 2025 , eprint=
2025
-
[7]
Chen Chen and Xinlong Hao and Weiwen Liu and Xu Huang and Xingshan Zeng and Shuai Yu and Dexun Li and Shuai Wang and Weinan Gan and Yuefeng Huang and Wulong Liu and Xinzhi Wang and Defu Lian and Baoqun Yin and Yasheng Wang and Wu Liu , year=. 2501.12851 , archivePrefix=
-
[8]
Kinjal Poulton and others , year=. 2409.03797 , archivePrefix=
-
[9]
Mengsong Wang and others , year=. 2405.08355 , archivePrefix=
-
[10]
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
Qiaoyu Tang and Ziliang Deng and Hongyu Lin and Xianpei Han and Qiao Liang and Boxi Cao and Le Sun , year=. 2306.05301 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin and others , year=. 2307.16789 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Akshara Prabhakar and Zuxin Liu and Weiran Yao and Jianguo Zhang and Tian Lan and Rithesh Murthy and Zhiwei Liu and Thai Hoang and Shelby Heinecke and Huan Wang and Silvio Savarese and Caiming Xiong , year=. 2504.03601 , archivePrefix=
-
[13]
International Conference on Learning Representations (ICLR) , eprint=
Xingshan Zeng and Weiwen Liu and Lingzhi Wang and Liangyou Li and Fei Mi and Yasheng Wang and Lifeng Shang and Xin Jiang and Qun Liu , year=. International Conference on Learning Representations (ICLR) , eprint=
-
[14]
arXiv preprint arXiv:2510.01179 , year=
Zhangchen Xu and Adriana Meza Soria and Shawn Tan and Anurag Roy and Ashish Sunil Agrawal and Radha Poovendran and Rameswar Panda , year=. 2510.01179 , archivePrefix=
-
[15]
2024 , howpublished=
2024
-
[16]
Proceedings of NAACL , eprint=
Hayley Ross and Ameya Sunil Mahabaleshwarkar and Yoshi Suhara , year=. Proceedings of NAACL , eprint=
-
[17]
2026 , eprint=
Simulating Complex Multi-Turn Tool Calling Interactions in Stateless Execution Environments , author=. 2026 , eprint=
2026
-
[18]
Le and Kai-Wei Chang and Chen-Yu Lee and Hamid Palangi and Tomas Pfister , year=
Fan Yin and Zifeng Wang and I-Hung Hsu and Jun Yan and Ke Jiang and Yanfei Chen and Jindong Gu and Long T. Le and Kai-Wei Chang and Chen-Yu Lee and Hamid Palangi and Tomas Pfister , year=. 2503.07826 , archivePrefix=
-
[19]
Jianguo Zhang and Tian Lan and Ming Zhu and Zuxin Liu and Thai Hoang and Shirley Kokane and Weiran Yao and Juntao Tan and Akshara Prabhakar and Haolin Chen and Zhiwei Liu and Yihao Feng and Tulika Awalgaonkar and Rithesh Murthy and Eric Hu and Zeyuan Chen and Ran Xu and Juan Carlos Niebles and Shelby Heinecke and Huan Wang and Silvio Savarese and Caiming ...
-
[20]
ToolRL: Reward is All Tool Learning Needs
Cheng Chen and others , year=. 2504.13958 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng and Ruochen Li and Junheng Hao and Xin Eric Wang , year=. 2504.11536 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song and Jinhao Jiang and Yingqian Min and Jie Chen and Zhipeng Chen and Wayne Xin Zhao and Lei Fang and Ji-Rong Wen , year=. 2503.05592 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Yongchao Sun and others , year=
-
[24]
Yuanqing Yu and Zhefan Wang and Weizhi Ma and Zhicheng Guo and Jingtao Zhan and Shuai Wang and Chuhan Wu and Zhiqiang Guo and Min Zhang , year=. 2410.07745 , archivePrefix=
-
[25]
Shaokun Zhang and Yi Dong and Jieyu Zhang and Jan Kautz and Bryan Catanzaro and Andrew Tao and Qingyun Wu and Zhiding Yu and Guilin Liu , year=. 2505.00024 , archivePrefix=
-
[26]
Yabo Zhang and Yirong Zeng and Qingfu Li and Zhenyi Hu and Kai Han and Wangmeng Zuo , year=. 2509.12867 , archivePrefix=
-
[27]
Weikang Zhao and Xili Wang and others , year=. 2508.18669 , archivePrefix=
-
[28]
Findings of EMNLP , eprint=
Yirong Zeng and Xiao Ding and Yutai Hou and Yuxian Wang and Li Du and Juyi Dai and others , year=. Findings of EMNLP , eprint=
-
[29]
Proceedings of the 26th International Conference on Machine Learning (ICML) , pages=
Curriculum Learning , author=. Proceedings of the 26th International Conference on Machine Learning (ICML) , pages=. 2009 , publisher=
2009
-
[30]
RLHF Workflow: From Reward Modeling to Online RLHF
Hanze Dong and Wei Xiong and Bo Pang and Haoxiang Wang and Han Zhao and Yingbo Zhou and Nan Jiang and Doyen Sahoo and Caiming Xiong and Tong Zhang , year=. 2405.07863 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Xiao Bi and Haowei Zhang and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , year=. 2402.03300 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[33]
Guangming Sheng and others , year=
-
[34]
2024 , note=
Model Context Protocol , author=. 2024 , note=
2024
-
[35]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[37]
2025 , note=
Granite 4.1 Language Models , author=. 2025 , note=
2025
-
[38]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[39]
2024 , eprint=
Let's Verify Step by Step , author=. 2024 , eprint=
2024
-
[40]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik Narasimhan and Yuan Cao , year=. 2210.03629 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
2023 , eprint=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.