Formalizing the Binding Problem
Pith reviewed 2026-06-28 10:19 UTC · model grok-4.3
The pith
Vision transformers encode binding information that associates features with specific objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formalize the binding problem with an information-theoretic approach, and introduce a probing method to measure binding information in model representations. We perform experiments on ViTs, measuring binding from different components of the architecture, such as the image summary token [CLS] or the spatial tokens. We use datasets with different binding challenges, such as feature sharing, occlusion, and natural features, while comparing the performance of several pre-trained ViTs. Overall, our research demonstrates binding as a key ingredient to strong visual recognition and reasoning.
What carries the argument
Information-theoretic probing method to measure how features are bound to objects in model representations.
If this is right
- Binding information varies across different components like the CLS token and spatial tokens in ViTs.
- Datasets with feature sharing, occlusion, and natural features reveal differences in binding across pre-trained models.
- Higher binding information supports stronger performance in visual recognition and reasoning tasks.
- The probe allows separate measurement of binding from other representation properties.
Where Pith is reading between the lines
- The same probe could be applied to CNNs or other architectures to compare their binding capacity directly.
- Training losses that reward higher probe scores might reduce errors on scenes where objects share features.
- Binding measurements could diagnose specific failure modes in current multi-object scene parsers.
Load-bearing premise
The introduced probing method isolates and accurately measures binding information in representations without being dominated by other correlated factors in the model or dataset construction.
What would settle it
If the probe assigns high binding scores to models that continue to misattribute features to the wrong objects at rates predicted by random guessing on controlled multi-object datasets, the claim that binding is a measurable key ingredient would be falsified.
Figures

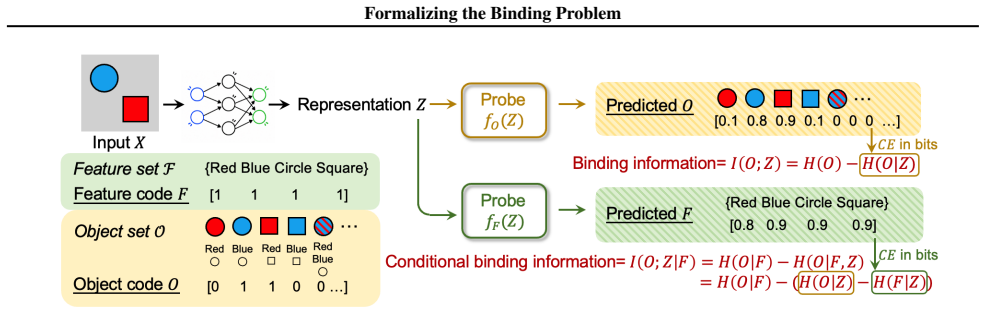
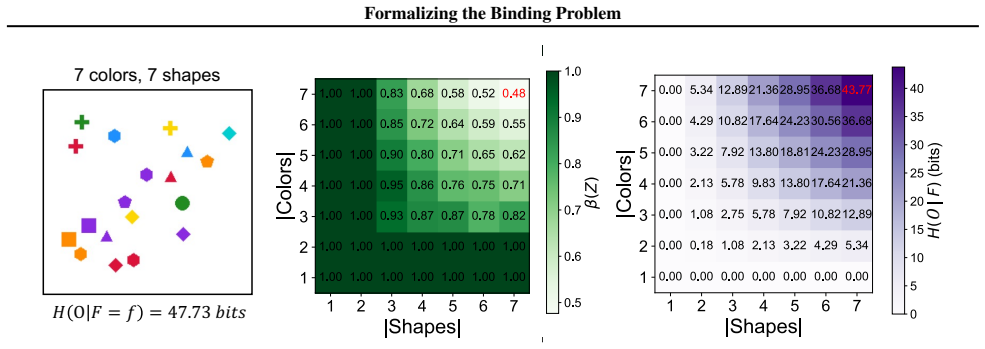



read the original abstract
Representations of the world, arguably, contain information about features (e.g. something is blue, something is a circle) but also information about which features are part of the same object (e.g. the circle is blue), which we call binding information. Any system with the ability to understand scenes with multiple objects must be able to solve the binding problem: it needs to know which features belong together. However, despite work showing that Vision Transformers (ViTs) know which patches belong together, it is not known whether current deep learning models learn to exhibit binding information, i.e., for features. We may believe that there is not much binding information, after all misattributing features to wrong objects is a common failure of ViT-based architectures, especially in scenes with objects sharing features. Here we formalize the binding problem with an information-theoretic approach, and introduce a probing method to measure binding information in model representations. We perform experiments on ViTs, measuring binding from different components of the architecture, such as the image summary token [CLS] or the spatial tokens. We use datasets with different binding challenges, such as feature sharing, occlusion, and natural features, while comparing the performance of several pre-trained ViTs. Overall, our research demonstrates binding as a key ingredient to strong visual recognition and reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the binding problem in visual representations as the information about which features belong to the same object (distinct from marginal feature presence), using an information-theoretic definition based on mutual information between feature and object variables. It introduces a probing method to measure this binding information in components of Vision Transformers (e.g., [CLS] token vs. spatial tokens) and evaluates it across datasets with varying binding challenges (feature sharing, occlusion, natural features), comparing multiple pre-trained ViTs. The central claim is that binding information is a key ingredient for strong visual recognition and reasoning.
Significance. If the probing method validly isolates binding structure, the work would provide a useful formalization and measurement tool for a longstanding issue in scene understanding, with potential to guide improvements in architectures like ViTs that currently struggle with feature misattribution. The experiments across multiple models and datasets offer a starting point for quantitative assessment, though the lack of controls for marginal statistics limits the strength of the conclusions.
major comments (1)
- [§3, §4] §3 and §4: The information-theoretic definition of binding via mutual information between feature and object variables is reasonable in principle, but the probe construction (using classifiers or estimators on full representation vectors) does not include the necessary control of holding marginal feature distributions fixed while randomizing object-feature assignments. Without this ablation, the measured quantity can increase due to improved marginal feature detection alone, undermining the claim that the probe quantifies binding separately from feature presence. This is load-bearing for the empirical conclusion that binding is demonstrated as a key ingredient.
minor comments (1)
- [Abstract] Abstract: The phrasing 'we may believe that there is not much binding information' is informal and could be clarified with reference to specific prior failure modes in ViTs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern about controlling for marginal feature distributions is well-taken and directly impacts the interpretation of our probing results. We address it below and outline the planned revision.
read point-by-point responses
-
Referee: [§3, §4] §3 and §4: The information-theoretic definition of binding via mutual information between feature and object variables is reasonable in principle, but the probe construction (using classifiers or estimators on full representation vectors) does not include the necessary control of holding marginal feature distributions fixed while randomizing object-feature assignments. Without this ablation, the measured quantity can increase due to improved marginal feature detection alone, undermining the claim that the probe quantifies binding separately from feature presence. This is load-bearing for the empirical conclusion that binding is demonstrated as a key ingredient.
Authors: We agree that the current probe lacks an explicit control that holds marginal feature statistics fixed while disrupting object-feature bindings. Such a control is necessary to isolate binding information from improvements in marginal feature detection. In the revised version we will add this ablation: for each dataset we will generate a matched control set in which object-feature assignments are randomized (via permutation of object labels within feature-sharing groups) while exactly preserving the marginal distributions of individual features. We will then re-run the probe on both the original and control representations and report the difference, which should reflect binding-specific information. This addition will be included in §4 and the associated figures. revision: yes
Circularity Check
No significant circularity; formalization and probe are definitional and methodological
full rationale
The paper's core contribution is an information-theoretic definition of binding (mutual information between feature and object variables) followed by a probing method to measure it in ViT representations. This constitutes a self-contained formalization and measurement proposal rather than any derivation that reduces to its inputs by construction. No self-citations are load-bearing, no fitted parameters are relabeled as predictions, no uniqueness theorems or ansatzes are imported from prior author work, and no renaming of known results occurs. The approach stands as an independent proposal that can be evaluated against external data and controls without internal circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning , author=. 2025 , eprint=
2025
-
[2]
Illusory conjunctions in the perception of objects , journal =. 1982 , issn =. doi:https://doi.org/10.1016/0010-0285(82)90006-8 , url =
-
[3]
The reviewing of object files: Object-specific integration of information , journal =. 1992 , issn =. doi:https://doi.org/10.1016/0010-0285(92)90007-O , url =
-
[4]
Saxe , title =
Devon Jarvis and Richard Klein and Benjamin Rosman and Andrew M. Saxe , title =. Proceedings of the National Academy of Sciences , volume =. 2026 , doi =
2026
-
[5]
5, 359–366,https: //doi.org/10.1016/0893-6080(89)90020-8
Kurt Hornik and Maxwell Stinchcombe and Halbert White , keywords =. Multilayer feedforward networks are universal approximators , journal =. 1989 , issn =. doi:https://doi.org/10.1016/0893-6080(89)90020-8 , url =
-
[6]
Matrix Factorization Revisited , author=
Neural Collaborative Filtering vs. Matrix Factorization Revisited , author=. 2020 , eprint=
2020
-
[7]
Can we fix it? Yes! , author=
Is CLIP ideal? No. Can we fix it? Yes! , author=. 2026 , eprint=
2026
-
[8]
2026 , eprint=
Beyond the final layer: Attentive multilayer fusion for vision transformers , author=. 2026 , eprint=
2026
-
[9]
Transactions on Machine Learning Research , issn=
Characterizing Vision Backbones for Dense Prediction with Dense Attentive Probing , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[10]
2026 , eprint=
V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning , author=. 2026 , eprint=
2026
-
[11]
2023 , eprint=
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. 2023 , eprint=
2023
-
[12]
2023 , eprint=
Visual Instruction Tuning , author=. 2023 , eprint=
2023
-
[13]
2021 , eprint=
Barlow Twins: Self-Supervised Learning via Redundancy Reduction , author=. 2021 , eprint=
2021
-
[14]
2020 , eprint=
A Simple Framework for Contrastive Learning of Visual Representations , author=. 2020 , eprint=
2020
-
[15]
2017 , eprint=
Neural Module Networks , author=. 2017 , eprint=
2017
-
[16]
Smolensky, P. , title =. 1990 , issue_date =. doi:10.1016/0004-3702(90)90007-M , journal =
-
[17]
2017 , eprint=
Dynamic Routing Between Capsules , author=. 2017 , eprint=
2017
-
[18]
2023 , eprint=
Bridging the Gap to Real-World Object-Centric Learning , author=. 2023 , eprint=
2023
-
[19]
2021 , eprint=
Probing Classifiers: Promises, Shortcomings, and Advances , author=. 2021 , eprint=
2021
-
[20]
2018 , eprint=
Understanding intermediate layers using linear classifier probes , author=. 2018 , eprint=
2018
-
[21]
2024 , eprint=
SAM 2: Segment Anything in Images and Videos , author=. 2024 , eprint=
2024
-
[22]
2023 , eprint=
Segment Anything , author=. 2023 , eprint=
2023
-
[23]
2025 , eprint=
Segment Anything, Even Occluded , author=. 2025 , eprint=
2025
-
[24]
2020 , eprint=
On the Binding Problem in Artificial Neural Networks , author=. 2020 , eprint=
2020
-
[25]
2023 , eprint=
Compositional Generalization from First Principles , author=. 2023 , eprint=
2023
-
[26]
2018 , eprint=
Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks , author=. 2018 , eprint=
2018
-
[27]
2020 , eprint=
Compositionality decomposed: how do neural networks generalise? , author=. 2020 , eprint=
2020
-
[28]
2025 , eprint=
Does Data Scaling Lead to Visual Compositional Generalization? , author=. 2025 , eprint=
2025
-
[29]
Cognitive Science , volume =
Xinchi Yu and Ellen Lau , title =. Cognitive Science , volume =. 2023 , doi =
2023
-
[30]
Neural mechanisms of feature binding , author=. Sci. China Life Sci , volume=
-
[31]
2025 , eprint=
Quantifying the Limits of Segmentation Foundation Models: Modeling Challenges in Segmenting Tree-Like and Low-Contrast Objects , author=. 2025 , eprint=
2025
-
[32]
2015 , eprint=
Microsoft COCO: Common Objects in Context , author=. 2015 , eprint=
2015
-
[33]
2023 , eprint=
PUG: Photorealistic and Semantically Controllable Synthetic Data for Representation Learning , author=. 2023 , eprint=
2023
-
[34]
2016 , eprint=
CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning , author=. 2016 , eprint=
2016
-
[35]
2025 , eprint=
SuperCLIP: CLIP with Simple Classification Supervision , author=. 2025 , eprint=
2025
-
[36]
2021 , eprint=
Emerging Properties in Self-Supervised Vision Transformers , author=. 2021 , eprint=
2021
-
[37]
2024 , eprint=
DINOv2: Learning Robust Visual Features without Supervision , author=. 2024 , eprint=
2024
-
[38]
2021 , eprint=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. 2021 , eprint=
2021
-
[39]
2021 , eprint=
Learning Transferable Visual Models From Natural Language Supervision , author=. 2021 , eprint=
2021
-
[40]
2025 , eprint=
CLIP Behaves like a Bag-of-Words Model Cross-modally but not Uni-modally , author=. 2025 , eprint=
2025
-
[41]
Poster Sessions at the 7th Annual Conference on Cognitive Computational Neuroscience (CCN 2024) , year =
Fangrui Huang and Klemen Kotar and Wanhee Lee and Rosa Cao and Daniel Yamins , title =. Poster Sessions at the 7th Annual Conference on Cognitive Computational Neuroscience (CCN 2024) , year =
2024
-
[42]
2025 , eprint=
Evaluating Compositional Generalisation in VLMs and Diffusion Models , author=. 2025 , eprint=
2025
-
[43]
2024 , eprint=
Does CLIP Bind Concepts? Probing Compositionality in Large Image Models , author=. 2024 , eprint=
2024
-
[44]
2022 , journal=
Toy Models of Superposition , author=. 2022 , journal=
2022
-
[45]
2025 , eprint=
On the Complexity of Neural Computation in Superposition , author=. 2025 , eprint=
2025
-
[46]
2025 , eprint=
Does Object Binding Naturally Emerge in Large Pretrained Vision Transformers? , author=. 2025 , eprint=
2025
-
[47]
The Correlation Theory of Brain Function , institution =
von der Malsburg, Christoph , year =. The Correlation Theory of Brain Function , institution =
-
[48]
Humphreys, G. W. and Duncan, J. and Treisman, A. and Treisman, Anne , title =. Philosophical Transactions of the Royal Society B: Biological Sciences , volume =. 1998 , month =. doi:10.1098/rstb.1998.0284 , url =
-
[49]
2023 , eprint=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. 2023 , eprint=
2023
-
[50]
2025 , eprint=
Understanding the Limits of Vision Language Models Through the Lens of the Binding Problem , author=. 2025 , eprint=
2025
-
[51]
2024 , eprint=
How Far Are We from Intelligent Visual Deductive Reasoning? , author=. 2024 , eprint=
2024
-
[52]
2023 , eprint=
When and why vision-language models behave like bags-of-words, and what to do about it? , author=. 2023 , eprint=
2023
-
[53]
2025 , eprint=
Visual symbolic mechanisms: Emergent symbol processing in vision language models , author=. 2025 , eprint=
2025
-
[54]
2019 , eprint=
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations , author=. 2019 , eprint=
2019
-
[55]
2025 , eprint=
On the Theoretical Understanding of Identifiable Sparse Autoencoders and Beyond , author=. 2025 , eprint=
2025
-
[56]
A feature-integration theory of attention , journal =. 1980 , issn =. doi:https://doi.org/10.1016/0010-0285(80)90005-5 , url =
-
[57]
The Thirteenth International Conference on Learning Representations , year=
Sparse Autoencoders Do Not Find Canonical Units of Analysis , author=. The Thirteenth International Conference on Learning Representations , year=
-
[58]
2017 , eprint=
The Mythos of Model Interpretability , author=. 2017 , eprint=
2017
-
[59]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[60]
M. J. Kearns , title =
-
[61]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[62]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[63]
Suppressed for Anonymity , author=
-
[64]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[65]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[66]
1962 , publisher=
Principles of neurodynamics: Perceptrons and the theory of brain mechanisms , author=. 1962 , publisher=
1962
-
[67]
Neuron , volume=
The what and why of binding: the modeler’s perspective , author=. Neuron , volume=. 1999 , publisher=
1999
-
[68]
Cognitive neurodynamics , volume=
The neural binding problem (s) , author=. Cognitive neurodynamics , volume=. 2013 , publisher=
2013
-
[69]
Neuron , volume=
The binding problem , author=. Neuron , volume=. 1999 , publisher=
1999
-
[70]
Current opinion in neurobiology , volume=
The binding problem , author=. Current opinion in neurobiology , volume=. 1996 , publisher=
1996
-
[71]
Neuron , volume=
Solutions to the binding problem: progress through controversy and convergence , author=. Neuron , volume=. 1999 , publisher=
1999
-
[72]
Neuron , volume=
The role of neural mechanisms of attention in solving the binding problem , author=. Neuron , volume=. 1999 , publisher=
1999
-
[73]
Neuron , volume=
Solving the binding problem: Assemblies form when neurons enhance their firing rate—they don’t need to oscillate or synchronize , author=. Neuron , volume=. 2023 , publisher=
2023
-
[74]
Trends in Cognitive Sciences , year=
Beyond binding: from modular to natural vision , author=. Trends in Cognitive Sciences , year=
-
[75]
Nature Reviews Neuroscience , volume=
Binding, spatial attention and perceptual awareness , author=. Nature Reviews Neuroscience , volume=. 2003 , publisher=
2003
-
[76]
Trends in cognitive sciences , volume=
The binding problem lives on: Comment on Di Lollo , author=. Trends in cognitive sciences , volume=
-
[77]
Trends in cognitive sciences , volume=
The feature-binding problem is an ill-posed problem , author=. Trends in cognitive sciences , volume=. 2012 , publisher=
2012
-
[78]
Trends in Cognitive Sciences , year=
Feature binding in biological and artificial vision , author=. Trends in Cognitive Sciences , year=
-
[79]
Annual review of neuroscience , volume=
Visual feature integration and the temporal correlation hypothesis , author=. Annual review of neuroscience , volume=. 1995 , publisher=
1995
-
[80]
arXiv preprint arXiv:2410.13821 , year=
Artificial kuramoto oscillatory neurons , author=. arXiv preprint arXiv:2410.13821 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.