Need to Know: Contextual-Integrity-Grounded Query Rewriting for Privacy-Conscious LLM Delegation
Pith reviewed 2026-06-28 09:39 UTC · model grok-4.3
The pith
Contextual integrity rules let a learned rewriter forward only task-necessary spans to cloud LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
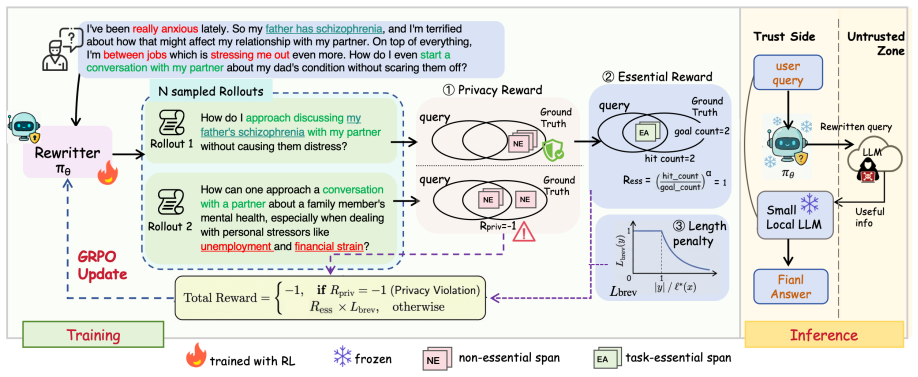
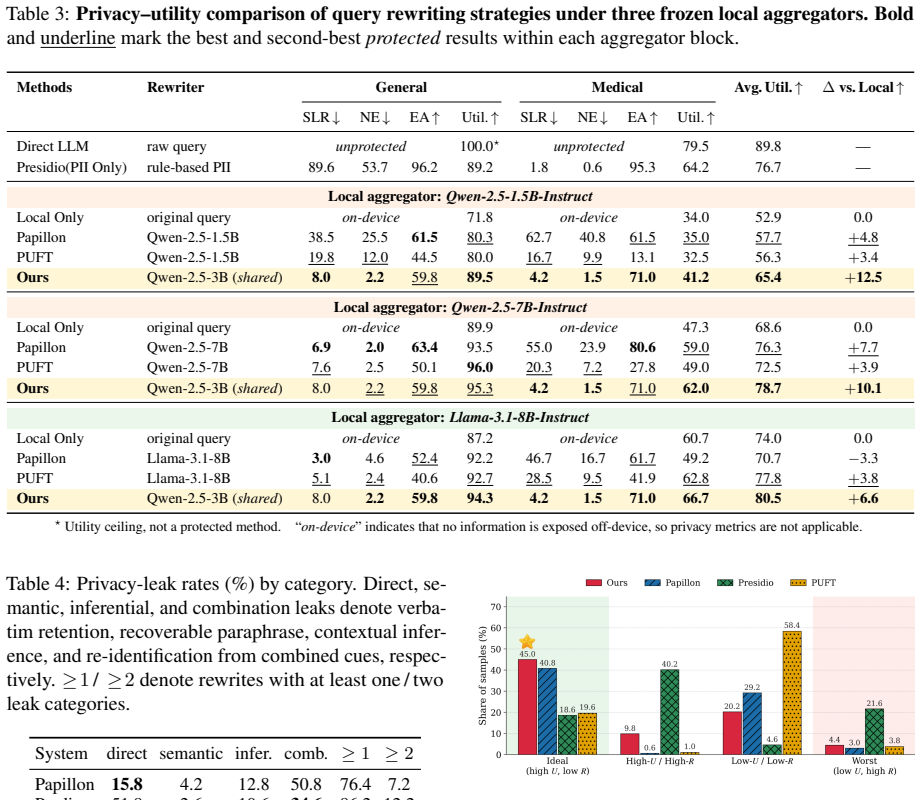
By treating query rewriting as a contextual-integrity decision problem and training a rewriter with reinforcement learning on signals that mark task-essential versus non-essential sensitive spans, the resulting model achieves the best privacy-utility tradeoff on DelegateCI-Bench and records up to 10.1 higher average utility than on-device baselines.
What carries the argument
CI-guided reinforcement learning framework that converts essential and non-essential span annotations into verifiable optimization signals for the query rewriter.
If this is right
- The rewriter preserves task-critical information while suppressing unnecessary sensitive disclosure.
- It records the best privacy-utility tradeoff across synthetic tasks, real user queries, and a medical challenge set.
- Average utility rises by as much as 10.1 points relative to on-device baselines.
- The approach works on both high-quality synthetic data spanning 11 tasks and 20 task types and on WildChat-derived real queries.
Where Pith is reading between the lines
- The same necessity filter could be applied to other forms of AI delegation where context must be shared selectively.
- On-device models might become less necessary if cloud queries can be safely reduced to task-essential content only.
- The method invites direct comparison with rule-based or LLM-prompt rewriting baselines on live user traffic.
Load-bearing premise
The annotations supplied in DelegateCI-Bench correctly label which spans are necessary versus non-essential under contextual integrity principles for each task.
What would settle it
Independent human raters applying contextual integrity criteria to the rewriter's decisions on a fresh set of queries find that many forwarded spans are unnecessary or that utility gains disappear.
Figures

read the original abstract
As LLMs become increasingly woven into everyday workflows, user queries sent to cloud hosted LLMs routinely mix task-essential content with task non-essential sensitive disclosures, yet type based PII redaction is context agnostic and may raise two issues: over disclosing untyped sensitive context and over removing answer bearing spans. We recast privacy preserving query rewriting under Contextual Integrity: a span should be forwarded only if it is necessary for the task. We introduce DelegateCI-Bench, the first task based Contextual Integrity benchmark for privacy-conscious delegation, comprising 3,167 samples that combine high quality synthetic data spanning 11 tasks and 20 task types, WildChat based real user queries, and a medical challenge set with dense sensitive information. Building on this benchmark, we propose a CI-guided reinforcement learning framework that converts essential and non-essential sensitive spans into verifiable optimization signals, and train a query rewriter to preserve task critical information while suppressing unnecessary sensitive disclosure. Experiments show that our learned rewriter achieves the best privacy-utility tradeoff, achieving up to +10.1 average utility over on-device baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DelegateCI-Bench, a 3,167-sample benchmark for task-based Contextual Integrity (CI) in privacy-preserving LLM query delegation that combines synthetic data across 11 tasks, WildChat queries, and a medical set. It proposes a CI-guided reinforcement learning framework that uses essential/non-essential span annotations as reward signals to train a query rewriter, claiming this yields the best privacy-utility tradeoff with up to +10.1 average utility gain over on-device baselines.
Significance. If the benchmark labels faithfully encode CI necessity judgments and the experimental results prove robust, the work would supply the first task-oriented CI benchmark and a verifiable optimization approach that moves beyond type-based PII redaction, offering a concrete path to reduce unnecessary sensitive disclosures while preserving task utility in cloud LLM delegation.
major comments (1)
- [Abstract] Abstract: The headline claim of superior privacy-utility tradeoff (+10.1 utility) depends entirely on DelegateCI-Bench annotations serving as accurate ground truth for both RL rewards and evaluation metrics. No inter-annotator agreement, expert validation against Nissenbaum's CI parameters (e.g., actors, attributes, transmission principles), or ablation on label noise is reported, rendering both the learned rewriter and the reported deltas unreliable if the labels systematically misclassify task-critical spans.
minor comments (1)
- [Abstract] Abstract: Experimental design details (baseline definitions, statistical tests, error analysis, and exact utility metric) are absent, preventing assessment of the +10.1 gain.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for emphasizing the need to substantiate the reliability of DelegateCI-Bench annotations. We address the concern directly below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of superior privacy-utility tradeoff (+10.1 utility) depends entirely on DelegateCI-Bench annotations serving as accurate ground truth for both RL rewards and evaluation metrics. No inter-annotator agreement, expert validation against Nissenbaum's CI parameters (e.g., actors, attributes, transmission principles), or ablation on label noise is reported, rendering both the learned rewriter and the reported deltas unreliable if the labels systematically misclassify task-critical spans.
Authors: We agree that the validity of the annotations is foundational to both the RL training signals and the reported utility gains. DelegateCI-Bench annotations were produced by defining essential spans as those required to fulfill the stated task under Contextual Integrity (explicitly incorporating actors, attributes, and transmission principles during synthetic data generation for the 11 tasks). WildChat and medical samples were annotated by the authors using the same CI criteria. However, the current manuscript does not report inter-annotator agreement, a systematic mapping to Nissenbaum's parameters, or label-noise ablations. In the revised manuscript we will add (1) IAA statistics from at least two additional annotators, (2) an explicit table mapping each annotation decision to the three CI parameters, and (3) an ablation that randomly flips 10-20% of essential/non-essential labels and re-evaluates the rewriter's utility delta. These additions will directly test whether the +10.1 gain remains stable under plausible label noise. revision: yes
Circularity Check
No circularity: empirical benchmark and RL training with external baselines
full rationale
The paper describes an empirical pipeline: creation of DelegateCI-Bench from synthetic, WildChat, and medical data; conversion of span labels into RL signals; training of a rewriter; and comparison of privacy-utility metrics against on-device baselines. No equations, derivations, or first-principles claims appear that reduce any reported utility gain (+10.1) to a fitted parameter or self-defined quantity by construction. The benchmark labels serve as standard ground truth for both reward and evaluation, which is conventional supervised learning rather than a self-referential loop. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contextual Integrity theory provides a context-dependent criterion for whether a span should be forwarded.
invented entities (2)
-
DelegateCI-Bench
no independent evidence
-
CI-guided reinforcement learning framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2010 , publisher =
Helen Nissenbaum , title =. 2010 , publisher =
2010
-
[2]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Niloofar Mireshghallah and Hyunwoo Kim and Xuhui Zhou and Yulia Tsvetkov and Maarten Sap and Reza Shokri and Yejin Choi , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Yijia Shao and Tianshi Li and Weiyan Shi and Yanchen Liu and Diyi Yang , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[5]
Weisz and Amit Dhurandhar and Karthikeyan Natesan Ramamurthy , title =
Ivoline Ngong and Swanand Kadhe and Hao Wang and Keerthiram Murugesan and Justin D. Weisz and Amit Dhurandhar and Karthikeyan Natesan Ramamurthy , title =. Findings of the Association for Computational Linguistics: ACL 2025 , year =
2025
-
[8]
Inan and Andre Manoel and Fatemehsadat Mireshghallah and Zinan Lin and Sivakanth Gopi and Janardhan Kulkarni and Robert Sim , title =
Xinyu Tang and Richard Shin and Huseyin A. Inan and Andre Manoel and Fatemehsadat Mireshghallah and Zinan Lin and Sivakanth Gopi and Janardhan Kulkarni and Robert Sim , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[9]
Wang and Chenhui Zhang and Zhangheng Li and Bo Li and Zhangyang Wang , title =
Junyuan Hong and Jiachen T. Wang and Chenhui Zhang and Zhangheng Li and Bo Li and Zhangyang Wang , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[10]
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL) , year =
Li Siyan and Vethavikashini Chithrra Raghuram and Omar Khattab and Julia Hirschberg and Zhou Yu , title =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL) , year =
2025
-
[11]
2021 , howpublished =
2021
-
[12]
The Text Anonymization Benchmark (
Ildik\'. The Text Anonymization Benchmark (. Computational Linguistics , volume =. 2022 , publisher =
2022
-
[13]
Analyzing Leakage of Personally Identifiable Information in Language Models , booktitle =
Nils Lukas and Ahmed Salem and Robert Sim and Shruti Tople and Lukas Wutschitz and Santiago Zanella-B. Analyzing Leakage of Personally Identifiable Information in Language Models , booktitle =. 2023 , pages =
2023
-
[14]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Wenting Zhao and Xiang Ren and Jack Hessel and Claire Cardie and Yejin Choi and Yuntian Deng , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[15]
2023 , howpublished =
2023
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , year =
John Langford and Tong Zhang , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[20]
Joar Skalse and Nikolaus H. R. Howe and Dmitrii Krasheninnikov and David Krueger , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[21]
Weinberger and Yoav Artzi , title =
Tianyi Zhang and Varsha Kishore and Felix Wu and Kilian Q. Weinberger and Yoav Artzi , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[22]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[23]
Publications Manual , year = "1983", publisher =
1983
-
[24]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[25]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[26]
Dan Gusfield , title =. 1997
1997
-
[27]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[28]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[29]
Proceedings of the Twentieth European Conference on Computer Systems (EuroSys '25) , year =
Guangming Sheng and Chi Zhang and Zilingfeng Ye and Xibin Wu and Wang Zhang and Ru Zhang and Yanghua Peng and Haibin Lin and Chuan Wu , title =. Proceedings of the Twentieth European Conference on Computer Systems (EuroSys '25) , year =
-
[31]
Jordan and Ion Stoica , title =
Philipp Moritz and Robert Nishihara and Stephanie Wang and Alexey Tumanov and Richard Liaw and Eric Liang and Melih Elibol and Zongheng Yang and William Paul and Michael I. Jordan and Ion Stoica , title =. Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI) , year =
-
[32]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Tri Dao , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[36]
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. 2024. https://arxiv.org/abs/2412.18925 HuatuoGPT-o1 : Towards medical complex reasoning with LLM s . arXiv preprint arXiv:2412.18925
Pith/arXiv arXiv 2024
-
[37]
Yu Chen, Tingxin Li, Huiming Liu, and Yang Yu. 2023. https://arxiv.org/abs/2309.03057 Hide and seek ( HaS ): A lightweight framework for prompt privacy protection . In arXiv preprint arXiv:2309.03057
arXiv 2023
-
[38]
Zhao Cheng, Diane Bouchacourt, and Mark Ibrahim. 2024. https://arxiv.org/abs/2409.13903 CI-Bench : Benchmarking contextual integrity of AI assistants on synthetic data . arXiv preprint arXiv:2409.13903
arXiv 2024
-
[39]
Tri Dao. 2024. https://arxiv.org/abs/2307.08691 FlashAttention-2 : Faster attention with better parallelism and work partitioning . In Proceedings of the International Conference on Learning Representations (ICLR)
Pith/arXiv arXiv 2024
-
[40]
Wang, Chenhui Zhang, Zhangheng Li, Bo Li, and Zhangyang Wang
Junyuan Hong, Jiachen T. Wang, Chenhui Zhang, Zhangheng Li, Bo Li, and Zhangyang Wang. 2024. https://openreview.net/forum?id=Ifz3IgsEPX DP-OPT : Make large language model your privacy-preserving prompt engineer . In Proceedings of the International Conference on Learning Representations (ICLR)
2024
-
[41]
Zhigang Kan, Linbo Qiao, Hao Yu, Liwen Peng, Yifu Gao, and Dongsheng Li. 2023. https://arxiv.org/abs/2306.08223 Protecting user privacy in remote conversational systems: A privacy-preserving framework based on text sanitization . In arXiv preprint arXiv:2306.08223
arXiv 2023
-
[42]
Proceedings of the 29th Symposium on Operating Systems Principles , pages =
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. https://doi.org/10.1145/3600006.3613165 Efficient memory management for large language model serving with PagedAttention . In Proceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP)
-
[43]
John Langford and Tong Zhang. 2007. The epoch-greedy algorithm for multi-armed bandits with side information. In Advances in Neural Information Processing Systems (NeurIPS)
2007
-
[44]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. https://arxiv.org/abs/1907.11692 RoBERTa : A robustly optimized BERT pretraining approach . arXiv preprint arXiv:1907.11692
Pith/arXiv arXiv 2019
-
[45]
Nils Lukas, Ahmed Salem, Robert Sim, Shruti Tople, Lukas Wutschitz, and Santiago Zanella-B \'e guelin. 2023. https://doi.org/10.1109/SP46215.2023.10179300 Analyzing leakage of personally identifiable information in language models . In Proceedings of the IEEE Symposium on Security and Privacy (SP), pages 346--363
-
[46]
Microsoft . 2021. Microsoft Presidio : Context-aware, pluggable and customizable PII anonymization service for text and images. https://microsoft.github.io/presidio/
2021
-
[47]
Niloofar Mireshghallah, Hyunwoo Kim, Xuhui Zhou, Yulia Tsvetkov, Maarten Sap, Reza Shokri, and Yejin Choi. 2024. https://openreview.net/forum?id=gmg7t8b4s0 Can LLM s keep a secret? T esting privacy implications of language models via contextual integrity theory . In Proceedings of the International Conference on Learning Representations (ICLR)
2024
-
[48]
Jordan, and Ion Stoica
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I. Jordan, and Ion Stoica. 2018. https://www.usenix.org/conference/osdi18/presentation/moritz Ray : A distributed framework for emerging AI applications . In Proceedings of the 13th USENIX Symposium on Operating Sy...
2018
-
[49]
Seth Neel and Peter Chang. 2023. https://arxiv.org/abs/2312.06717 Privacy issues in large language models: A survey . arXiv preprint arXiv:2312.06717
arXiv 2023
-
[50]
Weisz, Amit Dhurandhar, and Karthikeyan Natesan Ramamurthy
Ivoline Ngong, Swanand Kadhe, Hao Wang, Keerthiram Murugesan, Justin D. Weisz, Amit Dhurandhar, and Karthikeyan Natesan Ramamurthy. 2025. https://aclanthology.org/2025.findings-acl.1343/ Protecting user privacy in online settings via supervised learning guided by contextual integrity . In Findings of the Association for Computational Linguistics: ACL 2025...
2025
-
[51]
Helen Nissenbaum. 2010. Privacy in Context: Technology, Policy, and the Integrity of Social Life. Stanford University Press, Stanford, CA
2010
-
[52]
Ildik\' o Pil\' a n, Pierre Lison, Lilja vrelid, Anthi Papadopoulou, David S\' a nchez, and Montserrat Batet. 2022. https://doi.org/10.1162/coli_a_00458 The text anonymization benchmark ( TAB ): A dedicated corpus and evaluation framework for text anonymization . Computational Linguistics, 48(4):1053--1101
-
[53]
Qwen Team , An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, and 24 others. 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . arXiv preprint arXiv:2412.15115
Pith/arXiv arXiv 2025
-
[54]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. https://arxiv.org/abs/1707.06347 Proximal policy optimization algorithms . arXiv preprint arXiv:1707.06347
Pith/arXiv arXiv 2017
-
[55]
Yijia Shao, Tianshi Li, Weiyan Shi, Yanchen Liu, and Diyi Yang. 2024 a . PrivacyLens : Evaluating privacy norm awareness of language models in action. In Advances in Neural Information Processing Systems (NeurIPS)
2024
-
[56]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024 b . https://arxiv.org/abs/2402.03300 DeepSeekMath : Pushing the limits of mathematical reasoning in open language models . arXiv preprint arXiv:2402.03300
Pith/arXiv arXiv 2024
-
[57]
ShareGPT . 2023. ShareGPT : Share your wildest ChatGPT conversations with one click. https://sharegpt.com/. Accessed: 2025-05-24
2023
-
[58]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. https://arxiv.org/abs/2409.19256 HybridFlow : A flexible and efficient RLHF framework . In Proceedings of the Twentieth European Conference on Computer Systems (EuroSys '25)
Pith/arXiv arXiv 2025
-
[59]
Li Siyan, Vethavikashini Chithrra Raghuram, Omar Khattab, Julia Hirschberg, and Zhou Yu. 2025. https://arxiv.org/abs/2410.17127 PAPILLON : Privacy preservation from I nternet-based and L ocal L anguage M odel O rchestratio N . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL)
arXiv 2025
-
[60]
Joar Skalse, Nikolaus H. R. Howe, Dmitrii Krasheninnikov, and David Krueger. 2022. https://arxiv.org/abs/2209.13085 Defining and characterizing reward hacking . In Advances in Neural Information Processing Systems (NeurIPS)
arXiv 2022
-
[61]
Inan, Andre Manoel, Fatemehsadat Mireshghallah, Zinan Lin, Sivakanth Gopi, Janardhan Kulkarni, and Robert Sim
Xinyu Tang, Richard Shin, Huseyin A. Inan, Andre Manoel, Fatemehsadat Mireshghallah, Zinan Lin, Sivakanth Gopi, Janardhan Kulkarni, and Robert Sim. 2024. https://openreview.net/forum?id=oZtt0pRnOl Privacy-preserving in-context learning with differentially private few-shot generation . In Proceedings of the International Conference on Learning Representati...
2024
-
[62]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. https://openreview.net/forum?id=SkeHuCVFDr BERTScore : Evaluating text generation with BERT . In Proceedings of the International Conference on Learning Representations (ICLR)
2020
-
[63]
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. 2024. https://openreview.net/forum?id=Bl8u7ZRlbM WildChat : 1 M ChatGPT interaction logs in the wild . In Proceedings of the International Conference on Learning Representations (ICLR)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.