AgenticDiffusion: Agentic Diffusion-based Path Planning for Vision-Based UAV Navigation
Pith reviewed 2026-06-28 09:56 UTC · model grok-4.3
The pith
AgenticDiffusion uses synchronized FPV and top-view images with language instructions to select viewpoints and generate diffusion-based UAV trajectories, achieving 80% mission success in 40 real-world trials.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given a natural language instruction and synchronized first-person-view and top-view observations, the AgenticDiffusion framework determines the most informative viewpoint for navigation and generates a mission plan prior to trajectory execution. Targets are localized using an open-vocabulary grounding model, after which viewpoint-specific diffusion planners generate navigation trajectories for UAV execution by NMPC, yielding an overall mission success rate of 80% in 40 real-world trials and 100% trajectory generation success.
What carries the argument
The AgenticDiffusion pipeline that coordinates language-guided reasoning, open-vocabulary target grounding, vision-based diffusion planning, and NMPC using complementary FPV and top-view observations.
If this is right
- Complementary viewpoints reduce repeated target exploration compared with single-view baselines.
- Navigation efficiency improves in cluttered indoor environments through prior mission planning.
- The system supports adaptive viewpoint selection, multi-stage mission execution, long-horizon navigation, and safe landing-site selection.
- Diffusion planners achieve 100% success at generating trajectories that NMPC can execute.
Where Pith is reading between the lines
- The same dual-view structure could be tested outdoors by replacing the top-view camera with a satellite or drone-overhead feed.
- Replacing the open-vocabulary model with a different grounding network would reveal how much the reported success depends on that particular component.
- Adding online replanning when new obstacles appear after takeoff would extend the current offline planning step.
Load-bearing premise
Synchronized FPV and top-view observations remain reliably available and the open-vocabulary grounding model correctly localizes targets in the tested indoor conditions.
What would settle it
A drop in mission success rate below 80% when the same four scenarios are rerun with identical hardware but slightly altered lighting or object placements would falsify the claim that the framework reliably selects informative viewpoints and produces executable plans.
Figures


read the original abstract
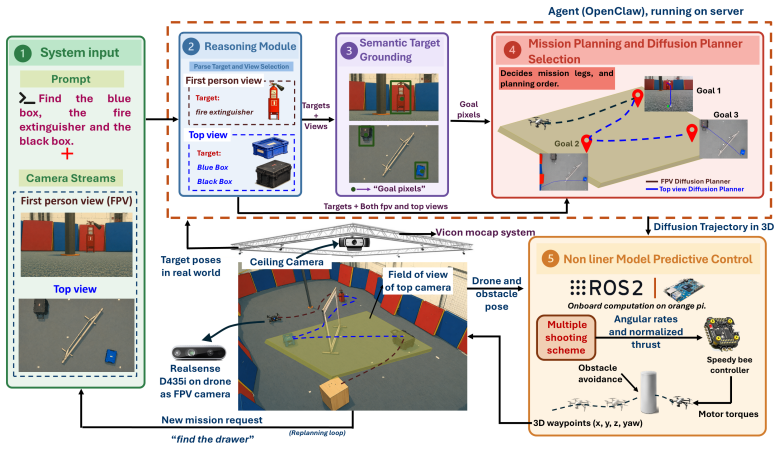
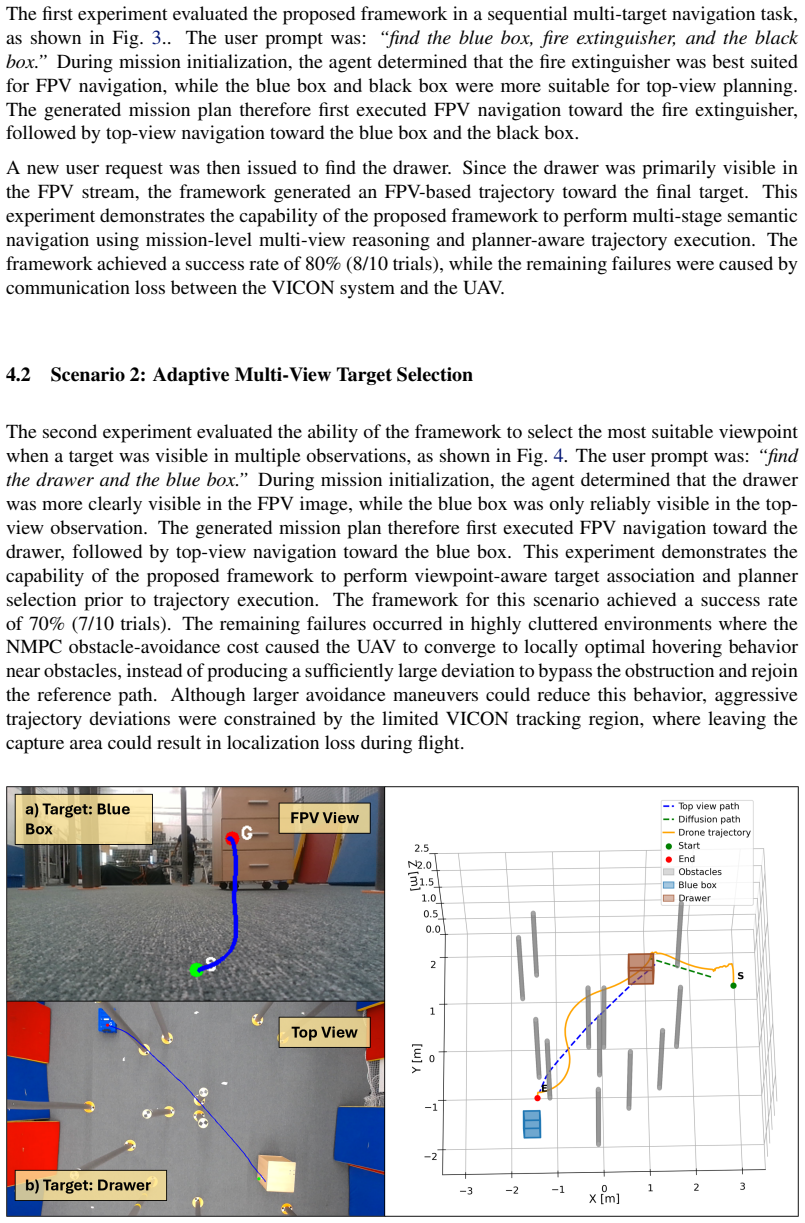
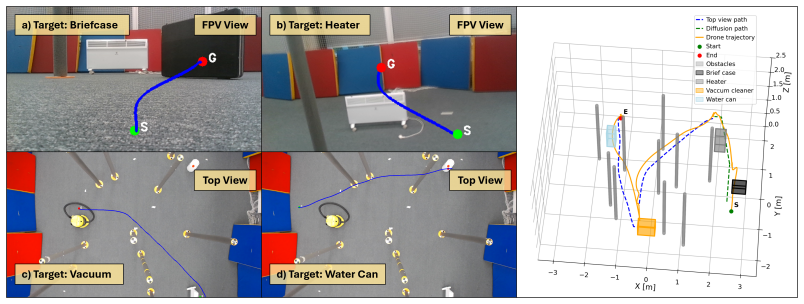
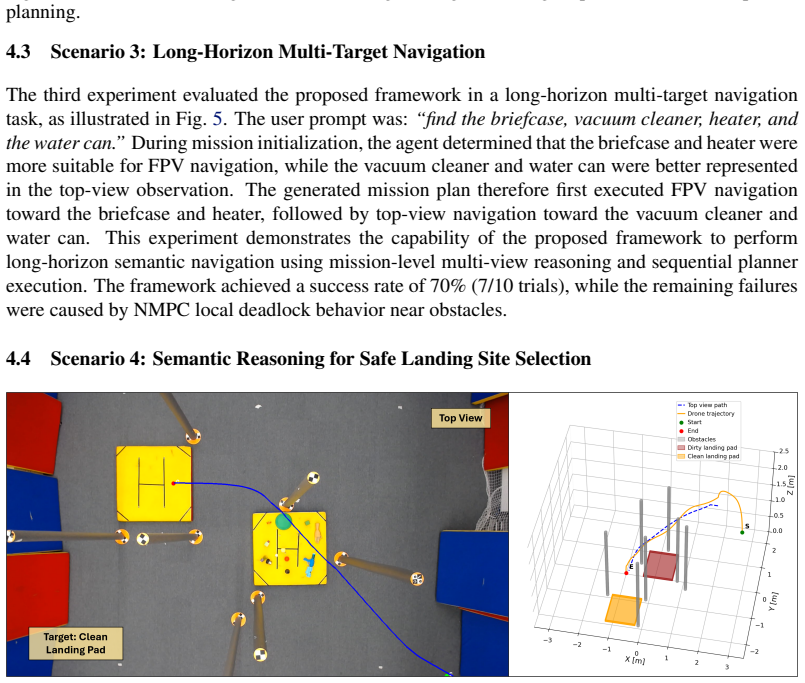
Indoor UAV navigation requires efficient exploration, scene understanding, and reliable trajectory execution under limited field-of-view observations. Existing vision-based navigation frameworks typically rely on single-view observations, limiting their ability to reason about occlusions, target visibility, and global scene structure. In this work, we propose AgenticDiffusion, a multi-view UAV navigation framework that coordinates language-guided reasoning, open-vocabulary target grounding, vision-based diffusion planning, and NMPC within a unified aerial navigation pipeline. Given a natural language instruction and synchronized first-person-view (FPV) and top-view observations, the framework determines the most informative viewpoint for navigation and generates a mission plan prior to trajectory execution. The targets are localized using an open-vocabulary grounding model, after which viewpoint-specific diffusion planners generate navigation trajectories for UAV execution. Using complementary viewpoints, the proposed framework reduces repeated target exploration and improves navigation efficiency in cluttered indoor environments. The framework was validated in four real-world UAV navigation scenarios involving adaptive viewpoint selection, multi-stage mission execution, long-horizon navigation, and safe landing-site selection. The experimental results demonstrated an overall mission success rate of 80% in 40 real-world trials, while the diffusion planners achieved a trajectory generation success rate of 100%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AgenticDiffusion, a multi-view UAV navigation framework coordinating language-guided reasoning, open-vocabulary grounding, vision-based diffusion planning, and NMPC. Given natural language instructions plus synchronized FPV and top-view observations, it selects informative viewpoints, localizes targets, generates trajectories via diffusion planners, and executes them. Validation in four real-world scenarios yields an 80% mission success rate over 40 trials and 100% diffusion trajectory success, with claims of reduced repeated exploration and improved efficiency in cluttered indoor settings.
Significance. If the evaluation were strengthened with baselines and protocol details, the integration of complementary viewpoints with diffusion-based planning could advance vision-based UAV navigation by addressing occlusion and global structure issues that single-view methods face.
major comments (2)
- [Abstract / Experimental Results] Abstract and Experimental Results: the claim of improved navigation efficiency over single-view methods is unsupported, as no baseline comparisons, quantitative efficiency metrics (e.g., time or path length), or statistical analysis are reported; the 80% success rate over 40 trials supplies no description of success/collision measurement, failure cases, or environment specifications.
- [Methods] Methods: the diffusion planner training procedure, viewpoint selection mechanism, open-vocabulary grounding integration, and NMPC execution details are described at a high level only, preventing assessment of whether the 100% trajectory success rate is reproducible or load-bearing for the central multi-view claim.
minor comments (1)
- [Abstract] The abstract states that complementary viewpoints 'reduce repeated target exploration' but provides no supporting quantitative evidence or ablation in the reported results.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We agree that the current manuscript requires additional experimental comparisons, quantitative metrics, and methodological details to fully support its claims. We will revise the paper to address these points.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results: the claim of improved navigation efficiency over single-view methods is unsupported, as no baseline comparisons, quantitative efficiency metrics (e.g., time or path length), or statistical analysis are reported; the 80% success rate over 40 trials supplies no description of success/collision measurement, failure cases, or environment specifications.
Authors: We acknowledge that the abstract and experimental results section do not include direct baseline comparisons or the requested quantitative metrics and statistical details. In the revised manuscript we will add comparisons against single-view baselines, report metrics such as average navigation time and path length with statistical analysis, and provide explicit definitions of success/collision criteria, descriptions of all failure cases, and full environment specifications. revision: yes
-
Referee: [Methods] Methods: the diffusion planner training procedure, viewpoint selection mechanism, open-vocabulary grounding integration, and NMPC execution details are described at a high level only, preventing assessment of whether the 100% trajectory success rate is reproducible or load-bearing for the central multi-view claim.
Authors: We agree that the methods are currently described at a high level. The revised version will expand each component with concrete implementation details: the diffusion planner training procedure and hyperparameters, the exact viewpoint selection algorithm, the integration steps with the open-vocabulary grounding model, and the NMPC formulation and parameters. These additions will enable reproducibility assessment and clarify the contribution of the multi-view design to the reported trajectory success rate. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a high-level system description of a UAV navigation pipeline combining language reasoning, open-vocabulary grounding, diffusion-based trajectory generation, and NMPC. No equations, derivations, fitted parameters, or self-citation chains are present in the supplied text. Claims rest on experimental success rates from 40 real-world trials rather than any internal reduction of outputs to inputs by construction. No load-bearing mathematical steps exist to analyze for circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Z. Xu, X. Han, H. Shen, H. Jin, and K. Shimada. NavRL: Learning Safe Flight in Dynamic Environments.IEEE Robotics and Automation Letters, 10(4):3668–3675, Feb, 26, 2025
2025
- [2]
-
[3]
Sridhar, D
A. Sridhar, D. Shah, C. Glossop, and S. Levine. NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration. InProc. IEEE Int. Conf. on Robotics and Automation (ICRA), pages 63–70, May 13-17, 2024
2024
-
[4]
Zhang, K
J. Zhang, K. Wang, R. Xu, G. Zhou, Y . Hong, X. Fang, et al. NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation.Robotics: Science and Systems, 2024
2024
-
[5]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, et al. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. InProc. European Conference on Computer Vision, page 38–55, 2024
2024
-
[6]
Castellani, E
C. Castellani, E. Turco, and D. Prattichizzo. 3D RL-DW A: A Hybrid Reinforcement Learning and Dynamic Window Approach for Goal-Directed Local Navigation in Multi-DoF Robots,
-
[7]
S. Hakenes and T. Glasmachers. Deep Reinforcement Learning Based Navigation with Macro Actions and Topological Maps, 2025. arxiv:2504.18300
-
[8]
J. Liu, M. Stamatopoulou, and D. Kanoulas. DiPPeR: Diffusion-based 2D Path Planner applied on Legged Robots. InProc. IEEE Int. Conf. on Robotics and Automation (ICRA), pages 9264– 9270, May 13-17, 2024
2024
-
[9]
Stamatopoulou, J
M. Stamatopoulou, J. Liu, and D. Kanoulas. DiPPeST: Diffusion-based Path Planner for Syn- thesizing Trajectories Applied on Quadruped Robots. InProc. IEEE Int. Conf. on Intelligent Robots and Systems (IROS), pages 7787–7793, Oct. 14-18, 2024
2024
-
[10]
Liang, A
J. Liang, A. Payandeh, D. Song, X. Xiao, and D. Manocha. DTG: Diffusion-based Trajectory Generation for Mapless Global Navigation. InProc. IEEE Int. Conf. on Intelligent Robots and Systems (IROS), pages 5340–5347, Oct. 14-18, 2024
2024
-
[11]
Y . Zeng, H. Ren, S. Wang, J. Huang, and H. Cheng. NaviDiffusor: Cost-Guided Diffusion Model for Visual Navigation. InProc. IEEE Int. Conf. on on Robotics and Automation (ICRA), pages 11994–12001, May 20-23, 2025
2025
-
[12]
X. Liu, V . Armstrong, S. Nabil, and C. Muise. Exploring multi-view perspectives on deep reinforcement learning agents for embodied object navigation in virtual home environments. In Proc. of Int. Conf. on Computer Science and Software Engineering (CASCON), page 190–195, Nov. 22-25, 2021
2021
-
[13]
S. Yang, S. A. Scherer, X. Yi, and A. Zell. Multi-camera visual SLAM for autonomous navi- gation of micro aerial vehicles.Robotics and Autonomous Systems, 93:116–134, July 2017
2017
-
[14]
K. Zhu, W. Chen, W. Zhang, R. Song, and Y . Li. utonomous Robot Navigation Based on Multi- Camera Perception. InProc. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pages 5879–5885, 2020
2020
-
[15]
H. Lu, M. Chiquier, and C. V ondrick. Private multiparty perception for navigation. InProc. of the Int. Conf. on Neural Information Processing Systems (NeurIPS), pages 3318–3328, Nov.- Dec. 28-09, 2022. 9
2022
-
[16]
T. Xu, J. Chen, J. Zhang, W. Zhang, Z. Qi, M. Li, Z. Zhang, and H. Wang. MM-Nav: Multi-View VLA Model for Robust Visual Navigation via Multi-Expert Learning, 2025. arxiv:2510.03142
work page internal anchor Pith review arXiv 2025
-
[17]
Huang, O
C. Huang, O. Mees, A. Zeng, and W. Burgard. Visual Language Maps for Robot Navigation. InProc. IEEE Int. Conf. on Robotics and Automation (ICRA), pages 10608–10615, May-June, 29-2, 2023
2023
-
[18]
B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Sadigh, L. Guibas, and F. Xia. SpatialVLM: Endow- ing Vision-Language Models with Spatial Reasoning Capabilities. InProc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages 14455–14465, June 16-22, 2024
2024
-
[19]
MapNav: A Novel Memory Representation via Annotated Semantic Maps for Vision-and-Language Navigation
L. Zhang, X. Hao, Q. Xu, Q. Zhang, X. Zhang, P. Wang, J. Zhang, Z. Wang, S. Zhang, and R. Xu. MapNav: A Novel Memory Representation via Annotated Semantic Maps for Vision- and-Language Navigation, 2026. arxiv:2502.13451
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
S. Lee, D. Ekpo, H. Liu, F. Huang, A. Shrivastava, and J.-B. Huang. Imagine, Verify, Execute: Memory-guided Agentic Exploration with Vision-Language Models. InConference on Robot Learning (CoRL), pages 4837–4858, Sept. 27-30, 2025
2025
-
[21]
Wang and X
Z. Wang and X. Yang. Enhancing Vision-and-Language Navigation in Continuous Environ- ment via Data Synthesis. InProc. IEEE Int. Conf. on Neural Networks, Information and Communication Engineering (NNICE), pages 713–716, Jan. 10-12, 2025
2025
- [22]
-
[23]
S. Zeng, D. Qi, X. Chang, F. Xiong, X. Shichao, X. Wu, et al. JanusVLN: Decoupling Seman- tics and Spatiality with Dual Implicit Memory for Vision-Language Navigation. InInt. Conf. on Learning Representations, April 23-25, 2026
2026
- [24]
-
[25]
X. Wang, D. Yang, Z. Wang, H. Kwan, J. Chen, W. Wu, et al. Towards Realistic UA V Vision- Language Navigation: Platform, Benchmark, and Methodology. InInt. Conf. on Learning Representations, April 24-28, 2025
2025
-
[26]
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar. V oyager: An Open-Ended Embodied Agent with Large Language Models.Transactions on Machine Learning Research, March 2024
2024
-
[27]
S. S. Kannan, V . L. N. Venkatesh, and B.-C. Min. SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models. InProc. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pages 12140–12147, Oct. 14-18, 2024
2024
-
[28]
A Hierarchical Agentic Framework for Autonomous Drone-Based Visual Inspection, au- thor=Ethan Herron and Xian Yeow Lee and Gregory Sin and Teresa Gonzalez Diaz and Ahmed Farahat and Chetan Gupta, 2025. arxiv:2510.00259
-
[29]
J. Sam, N. Khang, Y . Mahmoud, M. A. Cabrera, and D. Tsetserukou. Action Agent: Agentic Video Generation Meets Flow-Constrained Diffusion, 2026. arxiv:2605.01477
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Openclaw: Open-source agentic ai framework.https://github
OpenClaw Contributors. Openclaw: Open-source agentic ai framework.https://github. com/openclaw/openclaw, 2026. GitHub repository, Accessed: 2026-05-27
2026
-
[31]
Claude sonnet.https://www.anthropic.com/claude/sonnet, 2026
Anthropic. Claude sonnet.https://www.anthropic.com/claude/sonnet, 2026. Ac- cessed: 2026-05-27. 10
2026
-
[32]
J. A. E. Andersson, J. Gillis, G. Horn, J. B. Rawlings, and M. Diehl. CasADi – A software framework for nonlinear optimization and optimal control.Mathematical Programming Com- putation, 11(1):1–36, 2019
2019
-
[33]
Verschueren, G
R. Verschueren, G. Frison, D. Kouzoupis, J. Frey, N. van Duijkeren, A. Zanelli, B. Novoselnik, T. Albin, R. Quirynen, and M. Diehl. acados – a modular open-source framework for fast embedded optimal control.Mathematical Programming Computation, 2021
2021
-
[34]
ProcTHOR: Procedural Generation for Embodied AI.https://procthor.allenai.org/,
-
[35]
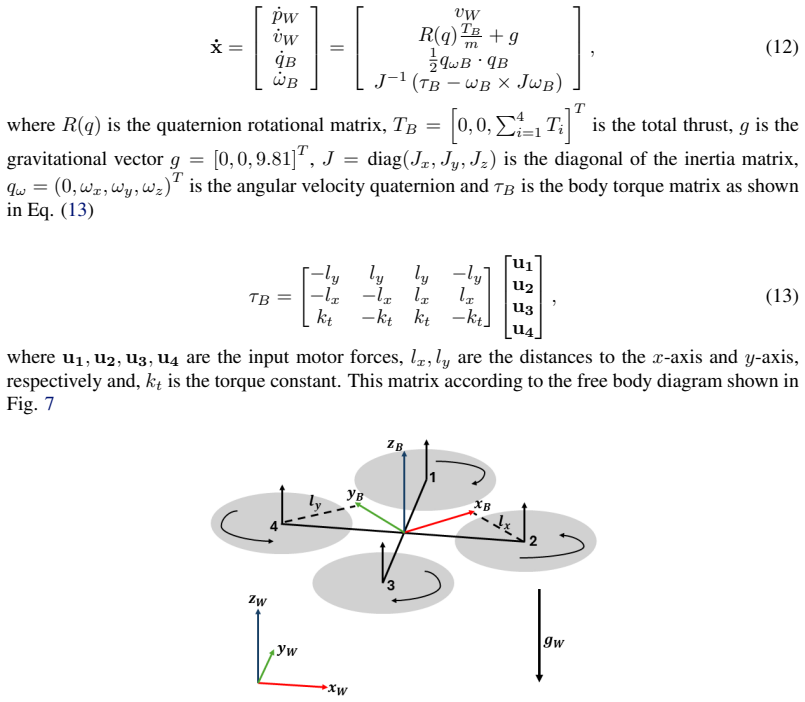
Accessed: 2026-02-20. 11 Appendix A Diffusion-Based Trajectory Planning The proposed top-view diffusion planner is formulated as a conditional UNet-based diffusion model for long-horizon trajectory generation in cluttered indoor environments. The planner predicts a pixel-space trajectory mask conditioned on the start point, goal point, and top-view scene ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.