What Are We Actually Benchmarking in Robot Manipulation?
Pith reviewed 2026-06-28 09:29 UTC · model grok-4.3
The pith
Many robot manipulation benchmarks fail diagnostics for shortcut use, insignificant gains, and data dependence, so their scores do not prove general capability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
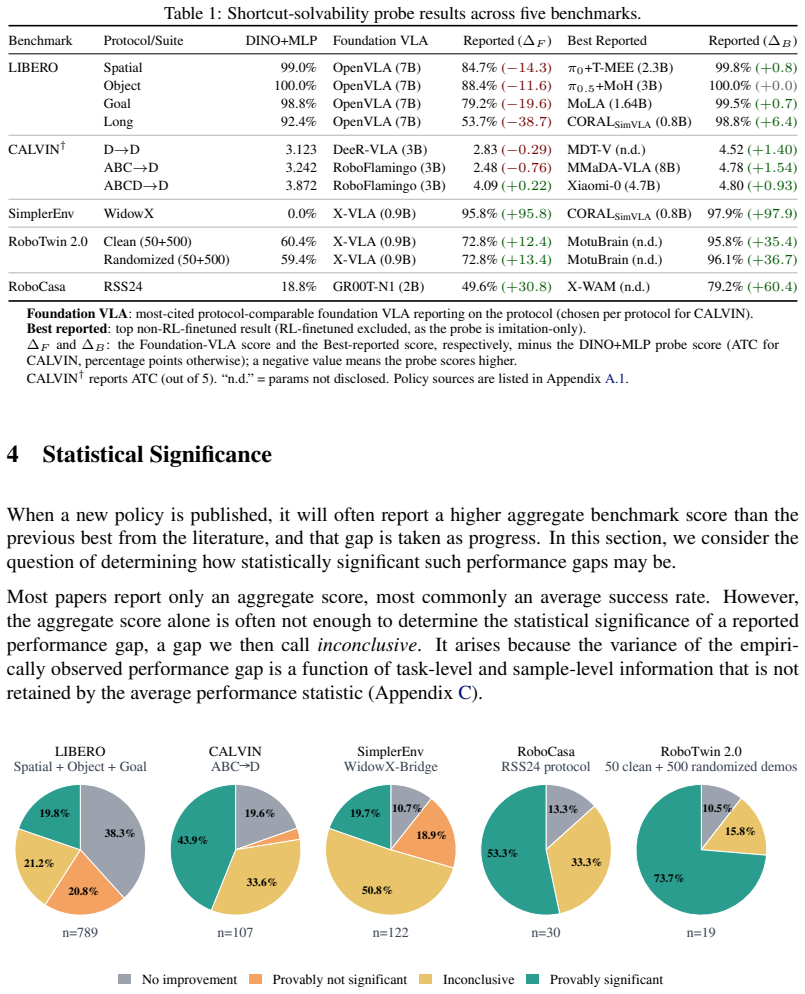
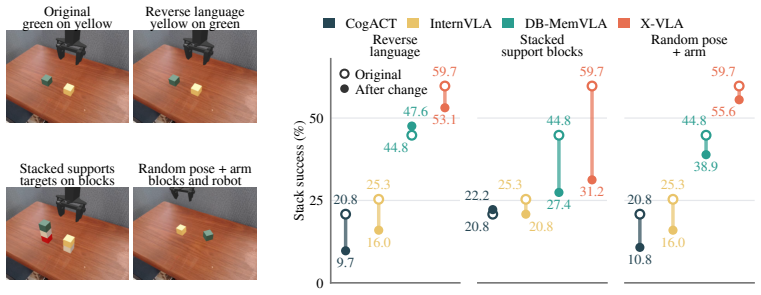
A robotics benchmark score measures success under one fixed evaluation setup, yet is routinely treated as evidence of general manipulation capability. Four failure modes weaken or invalidate this role: shortcut solvability, lack of statistical significance, creeping overfitting, and data-source dependence. One diagnostic is proposed for each mode. LIBERO and CALVIN fail multiple diagnostics; RoboCasa and RoboTwin 2.0 fail fewer. On LIBERO a 0.09B probe without a language encoder scores at or near reported SOTA and most reported gains are not provably statistically significant. On CALVIN, randomizing block poses within the training range drops performance for every tested policy.
What carries the argument
Four failure modes (shortcut solvability, lack of statistical significance, creeping overfitting, data-source dependence) each paired with one diagnostic that checks whether a benchmark score can serve as a valid proxy for general manipulation capability.
If this is right
- LIBERO and CALVIN scores can no longer be cited as evidence of progress without first passing the four diagnostics.
- RoboCasa and RoboTwin 2.0 become preferable evaluation suites for claims that aim to demonstrate general capability.
- Reported SOTA numbers on LIBERO require statistical testing before they can be treated as real improvements.
- Policies that appear strong on failing benchmarks may be exploiting fixed data sources or pose distributions rather than learning transferable skills.
- Authors and reviewers can run the released diagnostics before publishing or accepting a new result.
Where Pith is reading between the lines
- Benchmark designers could add the four diagnostics as mandatory checks in future suite releases.
- If the diagnostics become standard, papers may shift from reporting single-suite numbers to reporting which suites pass which checks.
- The same failure modes could be tested on other embodied benchmarks outside manipulation, such as navigation or assembly tasks.
- A benchmark that passes all four diagnostics would still need separate evidence that its tasks cover the full range of manipulation behaviors a general agent should handle.
Load-bearing premise
The four listed failure modes and their diagnostics are enough to decide whether any given benchmark score really stands for general manipulation skill.
What would settle it
Apply the four diagnostics to a new benchmark in which a language-free 0.09B probe scores far below every reported policy, every claimed gain passes a statistical-significance test, and randomizing object poses inside the training distribution leaves policy performance unchanged.
Figures

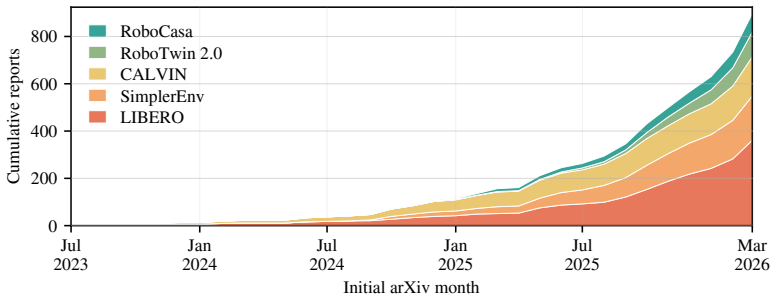

read the original abstract
A robotics benchmark score measures success under one fixed evaluation setup, yet is routinely treated as evidence of general manipulation capability. We identify four failure modes, each of which weakens or invalidates a benchmark's role as a valid proxy for that capability: shortcut solvability, lack of statistical significance, creeping overfitting, and data-source dependence. We propose one diagnostic per failure mode. We audit LIBERO, CALVIN, SimplerEnv, RoboCasa, and RoboTwin 2.0 under these diagnostics. LIBERO and CALVIN fail multiple diagnostics. RoboCasa and RoboTwin 2.0 fail fewer, despite appearing far less often in recent progress claims. On LIBERO, a 0.09B probe with no language encoder scores at or near reported SOTA, and most reported gains are not provably statistically significant. On CALVIN, randomizing block poses within the training range drops performance for every tested policy. We release the four diagnostics with reference implementations for authors and reviewers to apply before treating a benchmark score as evidence of progress. Code and artifacts are available at https://ripl.github.io/manipulation_benchmark_audit/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that robot manipulation benchmark scores are routinely treated as evidence of general manipulation capability but are undermined by four failure modes (shortcut solvability, lack of statistical significance, creeping overfitting, and data-source dependence). It proposes one diagnostic per mode, audits LIBERO, CALVIN, SimplerEnv, RoboCasa, and RoboTwin 2.0, reports that LIBERO and CALVIN fail multiple diagnostics while the others fail fewer, shows that a 0.09B probe without a language encoder reaches near-SOTA on LIBERO with most gains lacking statistical significance, and finds that pose randomization within the training range drops performance on CALVIN for all tested policies. Code and reference implementations are released.
Significance. If the diagnostics are shown to be sufficient, the work could improve evaluation practices in robot learning by discouraging over-interpretation of benchmark scores. The explicit release of code, artifacts, and reference implementations is a clear strength that supports reproducibility and community adoption of the proposed checks.
major comments (3)
- [Abstract] Abstract, first paragraph: the statement that each failure mode 'weakens or invalidates' a benchmark's role as a proxy for general manipulation capability treats the four modes as decisive without an argument or evidence that they are exhaustive, that passing all four guarantees proxy validity, or that failure necessarily severs any link to general capability rather than indicating only a narrower limitation.
- [Results (LIBERO audit)] Results on LIBERO (probe experiment): the claim that a 0.09B probe with no language encoder scores at or near reported SOTA requires the exact evaluation protocol, number of trials, variance estimates, and comparison baselines to be load-bearing; without these, the result cannot be verified as contradicting prior SOTA claims.
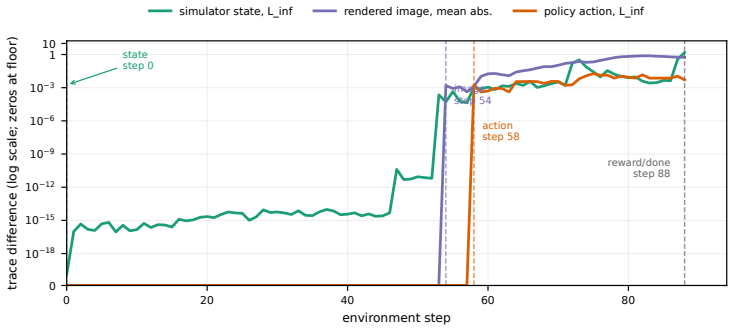
- [Results (CALVIN audit)] CALVIN pose-randomization experiment: the finding that randomizing block poses within the training range drops performance for every tested policy is presented as evidence of a failure mode, but the manuscript must specify the exact randomization procedure, number of seeds, and whether the drop exceeds the variance of the original evaluation to establish it as a diagnostic failure.
minor comments (2)
- [Introduction] The term 'creeping overfitting' is introduced without a formal definition or citation to prior usage; a brief clarification of how it differs from standard overfitting would improve readability.
- [Audit results] Table or figure reporting the per-benchmark diagnostic outcomes should include the exact numerical thresholds used for each diagnostic (e.g., significance level, probe size) to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and presentation of our diagnostics. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract, first paragraph: the statement that each failure mode 'weakens or invalidates' a benchmark's role as a proxy for general manipulation capability treats the four modes as decisive without an argument or evidence that they are exhaustive, that passing all four guarantees proxy validity, or that failure necessarily severs any link to general capability rather than indicating only a narrower limitation.
Authors: We agree the abstract phrasing could be read as implying decisiveness. The manuscript does not claim the four modes are exhaustive, nor that passing them guarantees proxy validity; it presents them as identifiable failure modes that can undermine the interpretation of a score as evidence of general capability. We will revise the abstract to state that each mode 'can weaken or invalidate' the proxy role and add a clarifying sentence that other unlisted failure modes may exist. revision: yes
-
Referee: [Results (LIBERO audit)] Results on LIBERO (probe experiment): the claim that a 0.09B probe with no language encoder scores at or near reported SOTA requires the exact evaluation protocol, number of trials, variance estimates, and comparison baselines to be load-bearing; without these, the result cannot be verified as contradicting prior SOTA claims.
Authors: The full evaluation protocol, trial counts (100 episodes per task), variance estimates, and direct numerical comparisons to published SOTA results are provided in Section 4.2 and the supplementary material, with the released code reproducing the exact numbers. To make this self-contained in the main text, we will add an explicit table listing the probe score against the cited SOTA baselines with their reported standard deviations. revision: yes
-
Referee: [Results (CALVIN audit)] CALVIN pose-randomization experiment: the finding that randomizing block poses within the training range drops performance for every tested policy is presented as evidence of a failure mode, but the manuscript must specify the exact randomization procedure, number of seeds, and whether the drop exceeds the variance of the original evaluation to establish it as a diagnostic failure.
Authors: The exact randomization procedure (uniform sampling of block poses within the original training distribution bounds), number of evaluation seeds (5), and statistical comparison (drop exceeds 2 standard deviations of the original evaluation for all policies) are detailed in Section 4.3 and the released reference implementation. We will insert a short paragraph in the main text summarizing these parameters and the variance comparison to ensure the diagnostic is fully load-bearing without requiring the supplement. revision: yes
Circularity Check
No significant circularity; diagnostics proposed independently
full rationale
The paper identifies four failure modes and proposes one diagnostic per mode, then applies them empirically to existing benchmarks. No equations, fitted parameters, or predictions reduce by construction to inputs defined inside the paper. The central claims rest on direct audits (e.g., 0.09B probe scores, pose randomization drops) rather than self-definition, self-citation chains, or renamed known results. The provided text contains no load-bearing self-citations or ansatzes that justify the failure-mode framework itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A robotics benchmark score measures success under one fixed evaluation setup, yet is routinely treated as evidence of general manipulation capability
Reference graph
Works this paper leans on
-
[1]
Torralba and A
A. Torralba and A. A. Efros. Unbiased look at dataset bias. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1521–1528, 2011
2011
-
[2]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[3]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. CALVIN: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[4]
X. Li, K. Hsu, J. Gu, O. Mees, K. Pertsch, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kirmani, S. Levine, J. Wu, C. Finn, H. Su, Q. Vuong, and T. Xiao. Evaluating real-world robot manip- ulation policies in simulation. InProceedings of the Conference on Robot Learning (CoRL), pages 3705–3728, 2025
2025
-
[5]
Nasiriany, A
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[6]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, W. Deng, Y . Guo, T. Nian, X. Xie, Q. Chen, K. Su, T. Xu, G. Liu, M. Hu, H.-a. Gao, K. Wang, Z. Liang, Y . Qin, X. Yang, P. Luo, and Y . Mu. RoboTwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Goyal, T
Y . Goyal, T. Khot, A. Agrawal, D. Summers-Stay, D. Batra, and D. Parikh. Making the V in VQA matter: Elevating the role of image understanding in visual question answering.Inter- national Journal of Computer Vision, 127(4):398–414, 2019
2019
-
[8]
Lapuschkin, S
S. Lapuschkin, S. W ¨aldchen, A. Binder, G. Montavon, W. Samek, and K.-R. M¨uller. Unmask- ing Clever Hans predictors and assessing what machines really learn.Nature Communications, 10(1):1096, 2019
2019
-
[9]
Everingham, L
M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (VOC) challenge.International Journal of Computer Vision, 88(2):303–338, 2010. 9
2010
-
[10]
K. Musgrave, S. Belongie, and S.-N. Lim. A metric learning reality check. InProceedings of the European Conference on Computer Vision (ECCV), volume 12370 ofLecture Notes in Computer Science, pages 681–699. Springer, 2020. doi:10.1007/978-3-030-58595-2 41
-
[11]
Ponce, T
J. Ponce, T. L. Berg, M. Everingham, D. A. Forsyth, M. Hebert, S. Lazebnik, M. Marszałek, C. Schmid, B. C. Russell, A. Torralba, C. K. I. Williams, J. Zhang, and A. Zisserman. Dataset issues in object recognition. InToward Category-Level Object Recognition, Lecture Notes in Computer Science, pages 29–48. Springer, 2006
2006
-
[12]
Recht, R
B. Recht, R. Roelofs, L. Schmidt, and V . Shankar. Do ImageNet classifiers generalize to ImageNet? InProceedings of the International Conference on Machine Learning (ICML), volume 97, pages 5389–5400, 2019
2019
-
[13]
Hendrycks and T
D. Hendrycks and T. Dietterich. Benchmarking neural network robustness to common corrup- tions and perturbations. InProceedings of the International Conference on Learning Repre- sentations (ICLR), 2019
2019
-
[14]
Barz and J
B. Barz and J. Denzler. Do we train on test data? Purging CIFAR of near-duplicates.Journal of Imaging, 6(6):41, 2020
2020
-
[15]
Elangovan, J
A. Elangovan, J. He, and K. Verspoor. Memorization vs. generalization: Quantifying data leak- age in NLP performance evaluation. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 1325–1335, 2021
2021
-
[16]
Lewis, P
P. Lewis, P. Stenetorp, and S. Riedel. Question and answer test-train overlap in open-domain question answering datasets. InProceedings of the Conference of the European Chapter of the Association for Computational Linguistics (EACL), pages 1000–1008, 2021
2021
-
[17]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. LIBERO-PRO: Towards robust and fair evaluation of vision-language-action models beyond memorization. arXiv preprint arXiv:2510.03827, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, J. Li, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. LIBERO-Plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Y . Zhu, J. Wong, A. Mandlekar, R. Mart´ın-Mart´ın, A. Joshi, K. Lin, A. Maddukuri, S. Nasiri- any, and Y . Zhu. robosuite: A modular simulation framework and benchmark for robot learn- ing.arXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[20]
T. Mu, Z. Ling, F. Xiang, D. Yang, X. Li, S. Tao, Z. Huang, Z. Jia, and H. Su. ManiSkill: Generalizable manipulation skill benchmark with large-scale demonstrations. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. Datasets and Benchmarks Track
2021
-
[21]
B. Shen, F. Xia, C. Li, R. Mart ´ın-Mart´ın, L. Fan, G. Wang, C. P ´erez-D’Arpino, S. Buch, S. Srivastava, L. P. Tchapmi, M. E. Tchapmi, K. Vainio, J. Wong, L. Fei-Fei, and S. Savarese. iGibson 1.0: A simulation environment for interactive tasks in large realistic scenes. InPro- ceedings of the IEEE/RSJ International Conference on Intelligent Robots and S...
2021
-
[22]
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-World: A benchmark and evaluation for multi-task and meta reinforcement learning. InProceedings of the Conference on Robot Learning (CoRL), pages 1094–1100, 2020
2020
-
[23]
A. Zeng, P. Florence, J. Tompson, S. Welker, J. Chien, M. Attarian, T. Armstrong, I. Krasin, D. Duong, V . Sindhwani, and J. Lee. Transporter networks: Rearranging the visual world for robotic manipulation. InProceedings of the Conference on Robot Learning (CoRL), volume 155 ofProceedings of Machine Learning Research, pages 726–747. PMLR, 2021. 10
2021
-
[24]
Jiang, A
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei-Fei, A. Anandkumar, Y . Zhu, and L. Fan. VIMA: General robot manipulation with multimodal prompts. InProceedings of the International Conference on Machine Learning (ICML), pages 14975–15022, 2023
2023
-
[25]
Lynch, A
C. Lynch, A. Wahid, J. Tompson, T. Ding, J. Betker, R. Baruch, T. Armstrong, and P. Florence. Interactive language: Talking to robots in real time.IEEE Robotics and Automation Letters, pages 1–8, 2024
2024
-
[26]
R. Gong, J. Huang, Y . Zhao, H. Geng, X. Gao, Q. Wu, W. Ai, Z. Zhou, D. Terzopoulos, S.- C. Zhu, B. Jia, and S. Huang. ARNOLD: A benchmark for language-grounded task learning with continuous states in realistic 3D scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 20483–20495, 2023
2023
-
[27]
Zhang, Z
S. Zhang, Z. Xu, P. Liu, X. Yu, Y . Li, Q. Gao, Z. Fei, Z. Yin, Z. Wu, Y .-G. Jiang, and X. Qiu. VLABench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11142–11152, 2025
2025
-
[28]
James, Z
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. RLBench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[29]
Pumacay, I
W. Pumacay, I. Singh, J. Duan, R. Krishna, J. Thomason, and D. Fox. THE COLOSSEUM: A benchmark for evaluating generalization for robotic manipulation. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[30]
M. Heo, Y . Lee, D. Lee, and J. J. Lim. FurnitureBench: Reproducible real-world benchmark for long-horizon complex manipulation.International Journal of Robotics Research, 44(10– 11):1863–1891, 2025
2025
-
[31]
Shridhar, J
M. Shridhar, J. Thomason, D. Gordon, Y . Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox. ALFRED: A benchmark for interpreting grounded instructions for everyday tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[32]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart ´ın-Mart´ın, C. Wang, G. Levine, M. Lingelbach, J. Sun, M. Anvari, M. Hwang, M. Sharma, A. Aydin, D. Bansal, S. Hunter, K.-Y . Kim, A. Lou, C. R. Matthews, I. Villa-Renteria, J. H. Tang, C. Tang, F. Xia, S. Savarese, H. Gweon, K. Liu, J. Wu, and L. Fei-Fei. BEHA VIOR-1K: A benchmark for embodied ...
2023
-
[33]
A. Szot, A. Clegg, E. Undersander, E. Wijmans, Y . Zhao, J. Turner, N. Maestre, M. Mukadam, D. Chaplot, O. Maksymets, A. Gokaslan, V . V ondrus, S. Dharur, F. Meier, W. Galuba, et al. Habitat 2.0: Training home assistants to rearrange their habitat. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2021
2021
-
[34]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. J ´egou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. DINOv2: Learning robust visual features without s...
2024
-
[35]
Zheng, J
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, Y .-Q. Zhang, J. Pang, J. Liu, T. Wang, and X. Zhan. X-VLA: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. InProceedings of the International Conference on Learning Representations (ICLR), 2026. 11
2026
-
[36]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large-scale video generative pre-training for visual robot manipulation. InProceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[37]
X. Li, M. Liu, H. Zhang, C. Yu, J. Xu, H. Wu, C. Cheang, Y . Jing, W. Zhang, H. Liu, H. Li, and T. Kong. Vision-language foundation models as effective robot imitators. InProceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[38]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, X. Wang, B. Liu, J. Fu, J. Bao, D. Chen, Y . Shi, J. Yang, and B. Guo. CogACT: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation. arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
X. Chen, Y . Chen, Y . Fu, N. Gao, J. Jia, W. Jin, H. Li, Y . Mu, J. Pang, Y . Qiao, Y . Tian, B. Wang, B. Wang, F. Wang, H. Wang, T. Wang, Z. Wang, X. Wei, C. Wu, S. Yang, J. Ye, J. Yu, J. Zeng, J. Zhang, J. Zhang, S. Zhang, F. Zheng, B. Zhou, and Y . Zhu. InternVLA- M1: A spatially guided vision-language-action framework for generalist robot policy.arXi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
B. Xie, E. Zhou, F. Jia, H. Shi, H. Fan, H. Zhang, H. Li, J. Sun, J. Bin, J. Huang, K. Liu, K. Liu, K. Gu, L. Sun, M. Zhang, P. Han, R. Hao, R. Zhang, S. Huang, S. Xie, T. Wang, T. Liu, W. Tang, W. Zhu, Y . Chen, Y . Liu, Y . Zhou, Y . Liu, Y . Zhao, Y . Ma, Y . Wei, Y . Chen, Z. Chen, Z. Li, Z. Wu, Z. Zhang, Z. Liu, Z. Yan, and Z. Zhang. Dexbotic: Open-s...
-
[41]
F. Li, W. Song, H. Zhao, J. Wang, P. Ding, D. Wang, L. Zeng, and H. Li. Spatial forcing: Implicit spatial representation alignment for vision-language-action model. InProceedings of the International Conference on Learning Representations (ICLR), 2026
2026
- [42]
-
[43]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
2025
-
[44]
Cadene, S
R. Cadene, S. Alibert, F. Capuano, M. Aractingi, A. Zouitine, P. Kooijmans, J. Choghari, M. Russi, C. Pascal, S. Palma, D. Aubakirova, M. Shukor, J. Moss, A. Soare, Q. Lhoest, Q. Gallou´edec, and T. Wolf. LeRobot: An open-source library for end-to-end robot learning. InProceedings of the International Conference on Learning Representations (ICLR), 2026
2026
-
[45]
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V . My- ers, M. J. Kim, M. Du, A. Lee, K. Fang, C. Finn, and S. Levine. BridgeData V2: A dataset for robot learning at scale. InProceedings of the Conference on Robot Learning (CoRL), pages 1723–1736, 2023
2023
-
[46]
Mart ´ınez-Plumed, R
F. Mart ´ınez-Plumed, R. B. C. Prud ˆencio, A. Mart ´ınez-Us´o, and J. Hern ´andez-Orallo. Item response theory in AI: Analysing machine learning classifiers at the instance level.Artificial Intelligence, 271:18–42, 2019
2019
-
[47]
Rodriguez, J
P. Rodriguez, J. Barrow, A. Hoyle, J. P. Lalor, R. Jia, and J. Boyd-Graber. Evaluation examples are not equally informative: How should that change NLP leaderboards? InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, pages 4486–4503, 2021. 12
2021
-
[48]
D. J. Weiss and G. G. Kingsbury. Application of computerized adaptive testing to educational problems.Journal of Educational Measurement, 21(4):361–375, 1984
1984
-
[49]
Song and P
H. Song and P. Flach. Efficient and robust model benchmarks with item response theory and adaptive testing.International Journal of Interactive Multimedia and Artificial Intelligence, 6 (5):110–118, 2021
2021
-
[50]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. InProceedings of the Conference on Robot Learning (CoRL), pages 2679–2713. PMLR, 2025
2025
-
[51]
Y . Li, B. Zhang, C. Gu, Z. Ma, J. Zhang, J. Deng, X. Zhu, and L. Zhang. From imagined futures to executable actions: Mixture of latent actions for robot manipulation. InProceedings of the International Conference on Machine Learning (ICML), 2026
2026
- [52]
-
[53]
Y . Yang, S. Zeng, T. Lin, X. Chang, D. Qi, J. Xiao, H. Liu, R. Chen, Y . Chen, D. Huo, F. Xiong, X. Wei, Z. Ma, and M. Xu. ABot-M0: VLA foundation model for robotic manipulation with action manifold learning.arXiv preprint arXiv:2602.11236, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
MotuBrain: An Advanced World Action Model for Robot Control
MotuBrain Team, C. Xiang, F. Bao, H. Liu, H. Tan, H. Bi, J. Li, J. Liu, J. Pang, K. Jing, L. Liu, M. Cai, R. Cui, R. Zhao, R. Wang, S. Huang, Y . Feng, Y . Rong, Z. Wang, and J. Zhu. Mo- tuBrain: An advanced world action model for robot control.arXiv preprint arXiv:2604.27792, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Y . Yue, Y . Wang, B. Kang, Y . Han, S. Wang, S. Song, J. Feng, and G. Huang. DeeR-VLA: Dynamic inference of multimodal large language models for efficient robot execution. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[56]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. GR00T N1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [57]
-
[58]
D. Jing, G. Wang, J. Liu, W. Tang, Z. Sun, Y . Yao, Z. Wei, Y . Liu, Z. Lu, and M. Ding. Mixture of horizons in action chunking.arXiv preprint arXiv:2511.19433, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [59]
- [60]
-
[61]
R. Cai, J. Guo, X. He, P. Jin, J. Li, B. Lin, F. Liu, W. Liu, F. Ma, K. Ma, F. Qiu, H. Qu, Y . Su, Q. Sun, D. Wang, D. Wang, Y . Wang, R. Wu, D. Xiang, Y . Yang, H. Ye, Y . Zhang, and Q. Zhou. Xiaomi-Robotics-0: An open-sourced vision-language-action model with real-time execution. arXiv preprint arXiv:2602.12684, 2026
-
[62]
J. Guo, Q. Li, P. Li, Z. Chen, N. Sun, Y . Su, H. Wang, Y . Zhang, X. Li, and H. Liu. Unified 4D world action modeling from video priors with asynchronous denoising.arXiv preprint arXiv:2604.26694, 2026. 13
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[63]
block” appears in869, “cube
H. He and Thinking Machines Lab. Defeating nondeterminism in LLM inference. Thinking Machines Lab: Connectionism, 2025.https://thinkingmachines.ai/blog/ defeating-nondeterminism-in-llm-inference/. 14 LIBERO CALVIN SimplerEnv RoboCasa RoboTwin 2.0 Figure 5: Example rendered observations from the five audited benchmarks, shown only to orient readers to the ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.